
快速上市的黑暗面
在今天的文章中,我将谈论影子数据团队。它们是什么,它们是如何产生的,以及它们对数据计划的影响。这是我自己的一个概念。
标签:数据工程|数据团队结构|敏捷数据洞察
成为数据驱动型公司的竞赛
在确保数据民主化和在组织中产生影响的任务中,数据领导者和高管只关心以下问题的日子已经一去不复返了:
- 他们雇佣的数据专业人员。他们应该带来足够的经验来处理当前的数据堆栈,同时也要为接下来的技术做好准备。
- 数据堆栈。它应该确保数据生命周期的所有部分都能正常工作,从接收到存储,再到服务和消费。
- 高管层的支持。他们确保有足够的资金来控制上述两种情况,并为组织中的数据转换打开大门。
有了这三个要素,过去二十年的数据团队将完全有能力获得他们需要的所有数据,对其进行处理,并使其可用于整个组织的多种潜在数据用例。
但后来发生了什么变化?
- 大数据的到来将把小而结构化的数据集转化为无法控制的大量数据,这些数据被摄入湖中。这种转变给湖泊的组织带来了多重挑战。数据仓库的数据模型和模式设计变得更加难以处理。我们甚至可以说,从那时起,数据仓库就失去了真正的用途。
- 数据源的激增。数据主要通过ETL流程从运营系统飞到操作数据存储(ODS),最终通过CDC(变更数据捕获)流程进入数据仓库。如今,除了早期的数据阶段组织之外,传统的ETL几乎没有任何用途。ELT是在湖中摄取数据的方式。除了运营系统,数据还来自第三方API,以实现数据丰富。服务器端和客户端的事件也正在使用扫雪机等工具进行收集。
- 新类型数据(如文本、图像和声音)的出现,新的可用NLP、CV和更传统的ML模型(只需简单的pip安装即可安装在笔记本电脑中),以及允许数据团队处理数据并训练访问强大CPU和GPU的模型的云提供商的出现,增强了潜在用例的增加。
数据消费者的多样化是多年来对组织数据民主化投资的结果。这也是人工智能大肆宣传的结果。数据团队现在支持企业模型中的营销、销售、财务、运营、分销、人力资源和许多其他部门。
你知道什么没有改变吗?
- 对协作数据团队的需求。数据世界中要求苛刻的转型加强了让软件工程师、数据工程师和数据科学家共同工作的需求。然而,这些数据组从未像现在这样分离。软件工程师(SWE)继续与分析周期脱节,同时产生湖中摄入的大部分数据。数据工程师成为了这个过程中的中间人,他们消耗来自SWE的数据,而SWE没有提供正确数据的动机。与业务关系密切的数据科学家被迫找到一种方法来克服以前的协作问题,并在有或没有可靠数据的情况下自行提供解决方案。
- 了解业务环境的重要性。为了提供有影响力的数据产品,所有相关团队都必须清楚地了解生成数据的源领域和业务领域的专业知识。这并没有改变。如今,如果数据专业人员希望数据产品在其组织中成功采用,他们需要进一步了解业务。
- 快速洞察。随着敏捷方法的到来和工程实践的转变,组织现在也希望能够非常快速地获得数据见解。比以前更快。然而,大多数数据团队在访问构建ML模型、报告或仪表板所需的数据方面仍然面临挑战。
积累这些问题的组织正在创造一个怪物,我称之为影子数据团队模式。
不同的数据团队成立
一般来说,建立数据实践有三种方法,它们将取决于公司数据生态系统的规模和成熟度。后者是去中心化的数据团队,是采用数据网格的第一步。
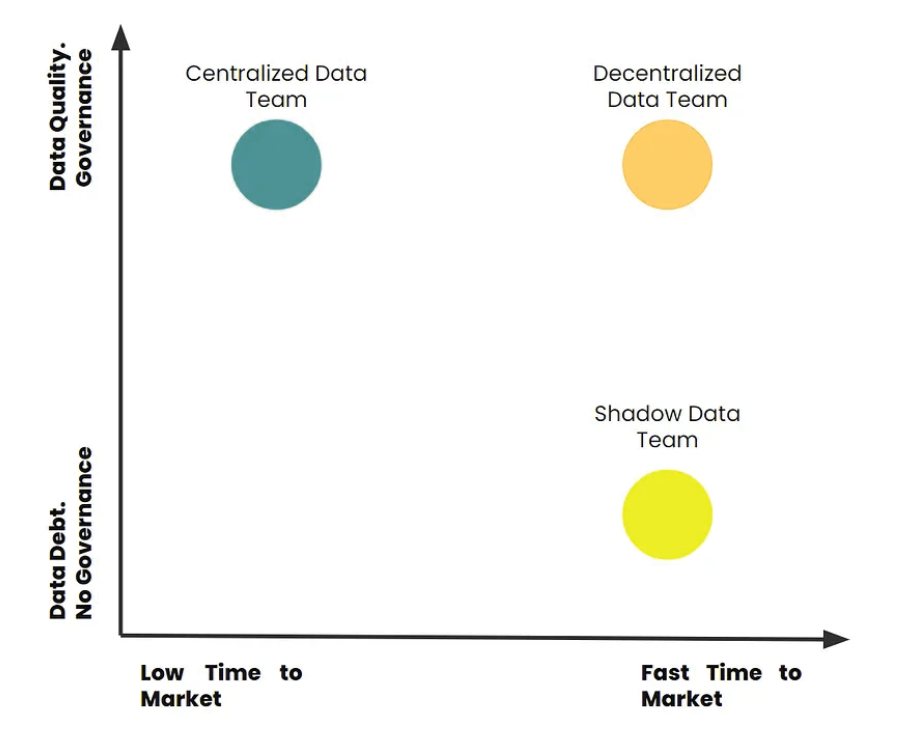
The relation between insights velocity and governance
- 集中式数据团队-我们在组织中看到的最常见的数据团队。由于治理僵化,运作自由度降低。所有数据都是集中的。在这里,团队在技术方面非常专业。所有变更都遵循特定的治理和验证流程。洞察的交付时间越来越长,但分析生命周期已在控制之中。然而,商业消费者并不满意。
- 影子数据团队-这种设置现在也很常见。这是数据科学家在数据工程工作的基础上进行数据工程的时候。或者,当组织第一轮聘用的是没有数据工程师的数据科学家时。这意味着,不会建立适当的数据基础设施。
- 去中心化数据团队-这种设置来自数据网格转型,在数据网格转型中,数据团队能够更加独立地工作,但有一个中央实体来管理治理。
在本文中,我将只介绍影子数据团队的设置。未来的文章将提供实践之间的差异以及它们之间的主要挑战。
影子数据团队。它们是什么?
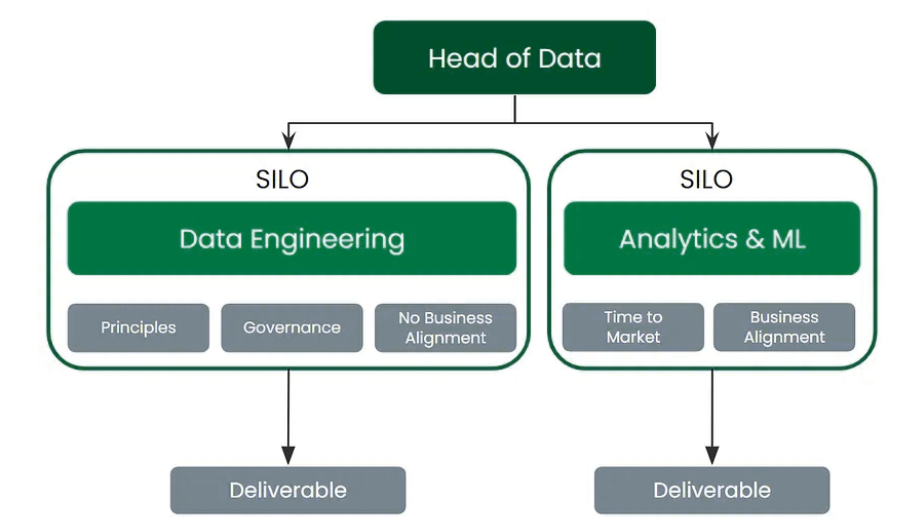
影子数据团队模型是通过创建新的团队(通常由数据科学家组成)来描述的,这些团队将数据计划直接交付到生产中,以实现更好的上市时间。
分析团队采用了新的数据处理和操作技术平台,如dbt,以“取代数据工程工作”。
业务利益相关者在这种环境中很高兴,因为计划在更短的时间内投入使用,从而产生了处理数据“容易”的错误期望。
在这种情况下建立良好的数据实践是不可能的。没有规则。在这种模式下,重要的是尽快交付。
我们如何到达这里?
- 对新数据功能或产品的业务请求。
- 数据科学家开始探索这个请求,并发现他们需要的数据要么不可用,要么在预期的结构或模式中不可用。
- 数据科学家要求为数据工程师提供新的数据管道
- 数据工程师有大量的请求,需要数周到数月的时间才能解决这个请求。
- 数据科学家面临着交付新数据功能/产品的压力。
- 数据科学家决定不等待并直接访问源系统和第一方数据库,从而创建一个没有生产标准、CI/CD最佳实践和明确所有权的SQL或dbt管道。
- 数据科学家已经习惯了这个过程,因为它提供了更大的自主权,并最终在组织中产生了大量的数据债务。
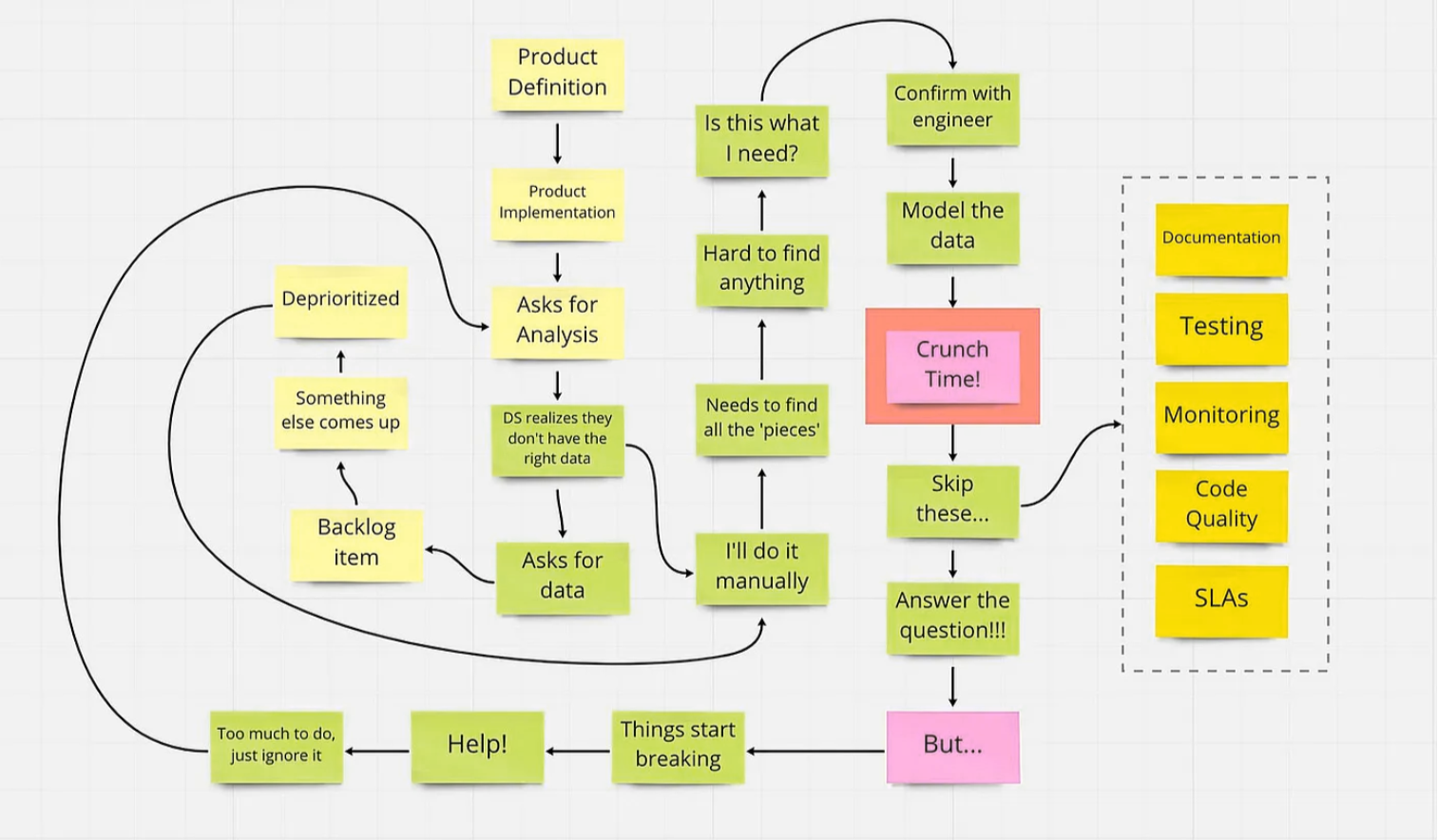
后果是什么?
在这种情况下,快速上市的成本是数据债务。这种债务表现得较晚,规模较大,产生以下影响:
- 数据不一致且不可靠
- 维护成本高
- 数据问题疑难解答变得困难
- 很难让人们对生成的数据负责。
- 不可靠的机器学习模型
- 与未维护的管道、表和重复数据相关的额外成本
- 湖泊和数据仓库的导航变得更加复杂
在这种情况下,数据工程团队会失去可信度,因为组织将看到没有他们的结果。当这些负面影响还不可见时,就很难长期证明这些负面影响。
几年后,当附带损害开始出现时,进行逆转变得非常复杂。
即使数据主管想要实施重大变革,业务在灵活性和速度方面已经受益,他们也不愿意失去这些。
接下来会发生什么?
如果你一直在阅读这份出版物,你会注意到我一直在强调我们在数据行业面临的问题,主要是因为我们一直从纯粹的技术角度处理数据。
我的目标是提高人们对这些问题的认识,让人们了解我的例子,因为它们是真实的故事。
因此,在接下来的几周里,我将分享更多关于
- 数据债务的增加
- 为什么数据仓库是组织中最重要的数据资产
之后,我将开始最后介绍数据网格。