
大型语言模型(LLM)是使用深度学习算法处理和理解自然语言的基础机器学习模型。这些模型在大量文本数据上进行训练,以学习语言中的模式和实体关系。LLM可以执行多种类型的语言任务,如翻译语言、分析情感、聊天机器人对话等。他们可以理解复杂的文本数据,识别实体及其之间的关系,并生成连贯且语法准确的新文本。
学习目标
- 理解大型语言模型(LLM)的概念及其在自然语言处理中的重要性。
- 了解不同类型的流行LLM,如BERT、GPT-3和T5。
- 讨论开源LLM的应用程序和用例。
- LLM的拥抱脸API。
- 探讨LLM的未来影响,包括其对就业市场、沟通和整个社会的潜在影响。
这篇文章是作为数据科学博客的一部分发表的。
目录
- 什么是大型语言模型?
- 通用架构
- LLM示例
- 开源大型语言模型
- Bloom架构
- 拥抱面部API
- 示例1:句子完成
- 示例2:问答
- 示例3:总结
- LLM的未来影响
- 结论
- 常见问题解答
什么是大型语言模型?
大型语言模型是一种高级类型的语言模型,使用深度学习技术对大量文本数据进行训练。这些模型能够生成类似人类的文本并执行各种自然语言处理任务。
相反,语言模型的定义是指基于对文本语料库的分析,为单词序列分配概率的概念。语言模型可以具有不同的复杂性,从简单的n-gram模型到更复杂的神经网络模型。然而,“大型语言模型”一词通常指的是使用深度学习技术并具有大量参数的模型,参数范围从数百万到数十亿不等。这些模型可以捕捉语言中的复杂模式,并生成通常与人类书写的文本无法区分的文本。
通用架构
大型语言模型的架构主要由多层神经网络组成,如递归层、前馈层、嵌入层和注意力层。这些层一起工作来处理输入文本并生成输出预测。
- 嵌入层将输入文本中的每个单词转换为高维向量表示。这些嵌入捕获有关单词的语义和句法信息,并帮助模型理解上下文。
- 大型语言模型的前馈层具有多个完全连接的层,这些层将非线性变换应用于输入嵌入。这些层帮助模型从输入文本中学习更高层次的抽象。
- LLM的递归层被设计为按顺序解释来自输入文本的信息。这些层保持一个隐藏状态,该状态在每个时间步长都会更新,从而使模型能够捕获句子中单词之间的依赖关系。
- 注意力机制是LLM的另一个重要部分,它允许模型选择性地关注输入文本的不同部分。这种机制有助于模型关注输入文本最相关的部分,并生成更准确的预测。
LLM示例
让我们来看看一些流行的大型语言模型:
- GPT-3(Generative Pre-trained Transformer 3)–这是OpenAI开发的最大的大型语言模型之一。它有1750亿个参数,可以执行许多任务,包括文本生成、翻译和摘要。
- BERT(Bidirectional Encoder Representations from Transformers)-由谷歌开发,BERT是另一种流行的LLM,它是在大量文本数据的语料库上训练的。它可以理解句子的上下文,并对问题做出有意义的回答。
- XLNet——这个由卡内基梅隆大学和谷歌开发的LLM使用了一种新的语言建模方法,称为“置换语言建模”。它在语言任务方面取得了最先进的性能,包括语言生成和问答。
- T5(Text-to-Text Transfer Transformer))–T5由谷歌开发,接受过各种语言任务的培训,可以执行文本到文本的转换,如将文本翻译成另一种语言、创建摘要和回答问题。
- RoBERTa(Robustly Optimized BERT Pretraining Approach)-由Facebook AI Research开发,RoBERTa是一个改进的BERT版本,在多种语言任务上表现更好。
开源大型语言模型
开源LLM的出现彻底改变了自然语言处理领域,使研究人员、开发人员和企业更容易构建应用程序,利用这些模型的力量免费大规模构建产品。布鲁姆就是这样一个例子。这是第一个多语言大型语言模型(LLM),由有史以来参与单个研究项目的人工智能研究人员进行的最大规模的合作,以完全透明的方式进行训练。
凭借1760亿个参数(比OpenAI的GPT-3大),BLOOM可以用46种自然语言和13种编程语言生成文本。它基于1.6TB的文本数据进行训练,是莎士比亚全集的320倍。
Bloom架构
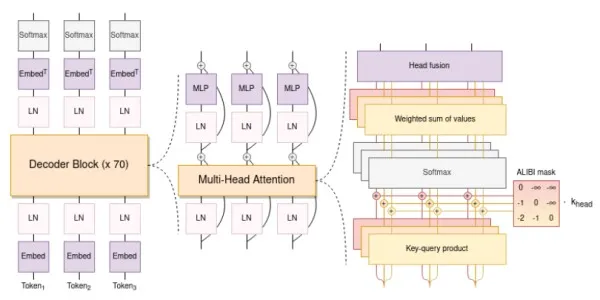
BLOOM的架构与GPT3(下一个令牌预测的自回归模型)有相似之处,但已经用46种不同的语言和13种编程语言进行了训练。它由一个只有解码器的架构组成,该架构具有多个嵌入层和多头注意力层。
Bloom的架构适用于多种语言的培训,并允许用户用不同的语言翻译和谈论某个主题。我们将在下面的代码中查看这些示例。
其他LLM
我们可以通过拥抱脸来利用连接到许多广泛可用的LLM的预训练模型的API。
Hugging Face API
让我们看看Hugging Face API如何帮助使用Bloom、Robertabase等LLM生成文本。首先,我们需要注册Hugging Face并复制令牌以进行API访问。注册后,将鼠标悬停在右上角的配置文件图标上,单击设置,然后单击访问令牌。
Example 1: Sentence Completion
让我们看看如何使用Bloom来完成句子。下面的代码使用API的拥抱脸标记发送带有输入文本和适当参数的API调用,以获得最佳响应。
import requests
from pprint import pprint
API_URL = 'https://api-inference.huggingface.co/models/bigscience/bloomz'
headers = {'Authorization': 'Entertheaccesskeyhere'}
# The Entertheaccesskeyhere is just a placeholder, which can be changed according to the user's access key
def query(payload):
response = requests.post(API_URL, headers=headers, json=payload)
return response.json()
params = {'max_length': 200, 'top_k': 10, 'temperature': 2.5}
output = query({
'inputs': 'Sherlock Holmes is a',
'parameters': params,
})
pprint(output)可以修改温度和top_k值以获得更大或更小的段落,同时保持生成的文本与原始输入文本的相关性。我们从代码中得到以下输出:
[{'generated_text': 'Sherlock Holmes is a private investigator whose cases '
'have inspired several film productions'}]Let’s look at some more examples using other LLMs.
Example 2: Question Answers
我们可以使用Roberta-base模型的API,它可以作为参考和答复的来源。让我们更改有效载荷以提供有关我自己的一些信息,并让模型根据这些信息回答问题。
API_URL = 'https://api-inference.huggingface.co/models/deepset/roberta-base-squad2'
headers = {'Authorization': 'Entertheaccesskeyhere'}
def query(payload):
response = requests.post(API_URL, headers=headers, json=payload)
return response.json()
params = {'max_length': 200, 'top_k': 10, 'temperature': 2.5}
output = query({
'inputs': {
"question": "What's my profession?",
"context": "My name is Suvojit and I am a Senior Data Scientist"
},
'parameters': params
})
pprint(output)The code prints the below output correctly to the question – What is my profession?:
{'answer': 'Senior Data Scientist',
'end': 51,
'score': 0.7751647233963013,
'start': 30}Example 3: Summarization
我们可以使用大型语言模型进行总结。让我们总结一篇使用Bart-Larget-CNN模型描述大型语言模型的长文。我们修改了API URL并添加了以下输入文本:
API_URL = "https://api-inference.huggingface.co/models/facebook/bart-large-cnn"
headers = {'Authorization': 'Entertheaccesskeyhere'}
def query(payload):
response = requests.post(API_URL, headers=headers, json=payload)
return response.json()
params = {'do_sample': False}
full_text = '''AI applications are summarizing articles, writing stories and
engaging in long conversations — and large language models are doing
the heavy lifting.
A large language model, or LLM, is a deep learning model that can
understand, learn, summarize, translate, predict, and generate text and other
content based on knowledge gained from massive datasets.
Large language models - successful applications of
transformer models. They aren’t just for teaching AIs human languages,
but for understanding proteins, writing software code, and much, much more.
In addition to accelerating natural language processing applications —
like translation, chatbots, and AI assistants — large language models are
used in healthcare, software development, and use cases in many other fields.'''
output = query({
'inputs': full_text,
'parameters': params
})
pprint(output)输出将打印有关LLM的摘要文本:
[{'summary_text': 'Large language models - most successful '
'applications of transformer models. They aren’t just for '
'teaching AIs human languages, but for understanding '
'proteins, writing software code, and much, much more. They '
'are used in healthcare, software development and use cases '
'in many other fields.'}]
这些是将Hugging Face API用于常见大型语言模型的一些示例。
LLM的未来影响
近年来,人们对GPT-3等大型语言模型(LLM)和ChatGPT等聊天机器人产生了特别的兴趣,它们可以生成与人类编写的自然语言文本几乎没有区别的自然语言文字。尽管LLM在人工智能领域取得了突破,但人们担心它们对就业市场、通信和社会的影响。
LLM的一个主要担忧是它们有可能扰乱就业市场。随着时间的推移,大型语言模型将能够通过替换人类来执行任务,如法律文件和草案、客户支持聊天机器人、撰写新闻博客等。这可能会导致那些工作很容易自动化的人失业。
然而,需要注意的是,LLM并不能取代人类工人。它们只是一种工具,可以帮助人们在工作中提高生产力和效率。虽然一些工作可能是自动化的,但由于LLM提高了效率和生产力,也将创造新的工作岗位。例如,企业可能能够创建以前开发起来过于耗时或昂贵的新产品或服务。
LLM有可能以多种方式影响社会。例如,LLM可以用于创建个性化的教育或医疗保健计划,从而获得更好的患者和学生结果。LLM可以通过分析大量数据和产生见解来帮助企业和政府做出更好的决策。
结论
大型语言模型(LLM)彻底改变了自然语言处理领域,在文本生成和理解方面取得了新的进步。LLM可以从大数据中学习,了解其上下文和实体,并回答用户查询。这使它们成为在几个行业的各种任务中经常使用的一个很好的替代品。然而,人们对与这些模型相关的伦理影响和潜在偏见感到担忧。以批判的眼光对待LLM并评估其对社会的影响是很重要的。通过仔细使用和持续开发,LLM有可能在许多领域带来积极的变化,但我们应该意识到它们的局限性和道德影响。
主要收获:
- 大型语言模型(LLM)可以理解复杂的句子,理解实体和用户意图之间的关系,并生成连贯且语法正确的新文本
- 本文探讨了一些LLM的架构,包括嵌入层、前馈层、递归层和注意力层。
- 本文讨论了一些流行的LLM,如BERT、BERT、Bloom和GPT3,以及开源LLM的可用性。
- 拥抱脸API有助于用户使用LLM生成文本,如Bart大型CNN、Roberta、Bloom和Bart大型有线电视新闻网。
- LLM有望在未来彻底改变就业市场、通信和社会的某些领域。
常见问题解答
Q1.顶级的大型语言模型是什么?
答:顶级的大型语言模型包括GPT-3、GPT-2、BERT、T5和RoBERTa。这些模型能够生成高度逼真和连贯的文本,并执行各种自然语言处理任务,如语言翻译、文本摘要和问答。
Q2.为什么要使用大型语言模型?
答:之所以使用大型语言模型,是因为它们可以生成类似人类的文本,执行各种自然语言处理任务,并有可能彻底改变许多行业。它们可以提高语言翻译的准确性,帮助内容创建,改善搜索引擎结果,并增强虚拟助理的能力。大型语言模型对科学研究也很有价值,例如分析医学、社会学和语言学等领域的大量文本数据。
Q3.人工智能中的LLM是什么?
人工智能中的LLM指的是人工智能的语言模型,这些模型旨在使用自然语言处理技术理解和生成类似人类的文本。
Q4.NLP中的LLM是什么?
NLP中的LLM代表自然语言处理中的语言模型。这些模型支持与语言相关的任务,如文本分类、情感分析和机器翻译。
问题5.LLM模型的完整形式是什么?
答:LLM模型的完整形式是“大型语言模型”。这些模型是在大量文本数据上训练的,可以生成连贯且与上下文相关的文本。
问题6.NLP和LLM之间的区别是什么?
自然语言处理是人工智能的一个领域,专注于理解和处理人类语言。另一方面,LLM是NLP中使用的特定模型,由于其庞大的规模和生成文本的能力,它们擅长于语言相关的任务。
最新内容
- 5 days 18 hours ago
- 1 week 6 days ago
- 2 weeks 3 days ago
- 2 months ago
- 5 months 4 weeks ago
- 5 months 4 weeks ago
- 5 months 4 weeks ago
- 5 months 4 weeks ago
- 5 months 4 weeks ago
- 5 months 4 weeks ago