
|
Environment: PoC or pilot |
Technologies: Modernization; SaaS; Serverless |
Workload: Open-source |
|
AWS services: Amazon OpenSearch Service; AWS Lambda; Amazon S3; Amazon API Gateway |
总结
Amazon OpenSearch服务是一种托管服务,它可以方便地部署、操作和扩展Elasticsearch,这是一种流行的开源搜索和分析引擎。Amazon OpenSearch服务提供免费文本搜索,以及对日志和指标等流数据的近实时接收和仪表板。
软件即服务(SaaS)提供商经常使用Amazon OpenSearch服务来解决广泛的用例,例如以可扩展和安全的方式获取客户洞察,同时减少复杂性和停机时间。
在多租户环境中使用Amazon OpenSearch服务会带来一系列影响SaaS解决方案的分区、隔离、部署和管理的注意事项。SaaS提供商必须考虑如何在不断变化的工作负载下有效地扩展其Elasticsearch集群。他们还需要考虑分层和有噪声的邻居条件如何影响分区模型。
此模式检查用于使用Elasticsearch构造表示和隔离租户数据的模型。此外,该模式以一个简单的无服务器参考架构为例,演示在多租户环境中使用AmazonOpenSearch服务进行索引和搜索。它实现了池数据分区模型,该模型在所有租户之间共享相同的索引,同时保持租户的数据隔离。此模式使用以下Amazon Web Services(AWS)服务:Amazon API Gateway、AWS Lambda、Amazon Simple Storage Service(Amazon S3)和Amazon OpenSearch Service。
有关池模型和其他数据分区模型的更多信息,请参阅附加信息部分。
先决条件和限制
先决条件
- 活跃的AWS帐户
- AWS命令行界面(AWS CLI)2.x版,在macOS、Linux或Windows上安装和配置
- Python版本3.7
- pip3–Python源代码以.zip文件的形式提供,将部署在Lambda函数中。如果您想在本地使用代码或自定义代码,请按照以下步骤开发和重新编译源代码:
- 通过在与Python脚本相同的目录中运行以下命令生成requirements.txt文件:pip3 freeze>requirements.txt
- 安装依赖项:pip3 Install-r requirements.txt
局限性
- 此代码在Python中运行,目前不支持其他编程语言。
- 示例应用程序不包括AWS跨区域或灾难恢复(DR)支持。
- 此模式仅用于演示目的。它不打算在生产环境中使用。
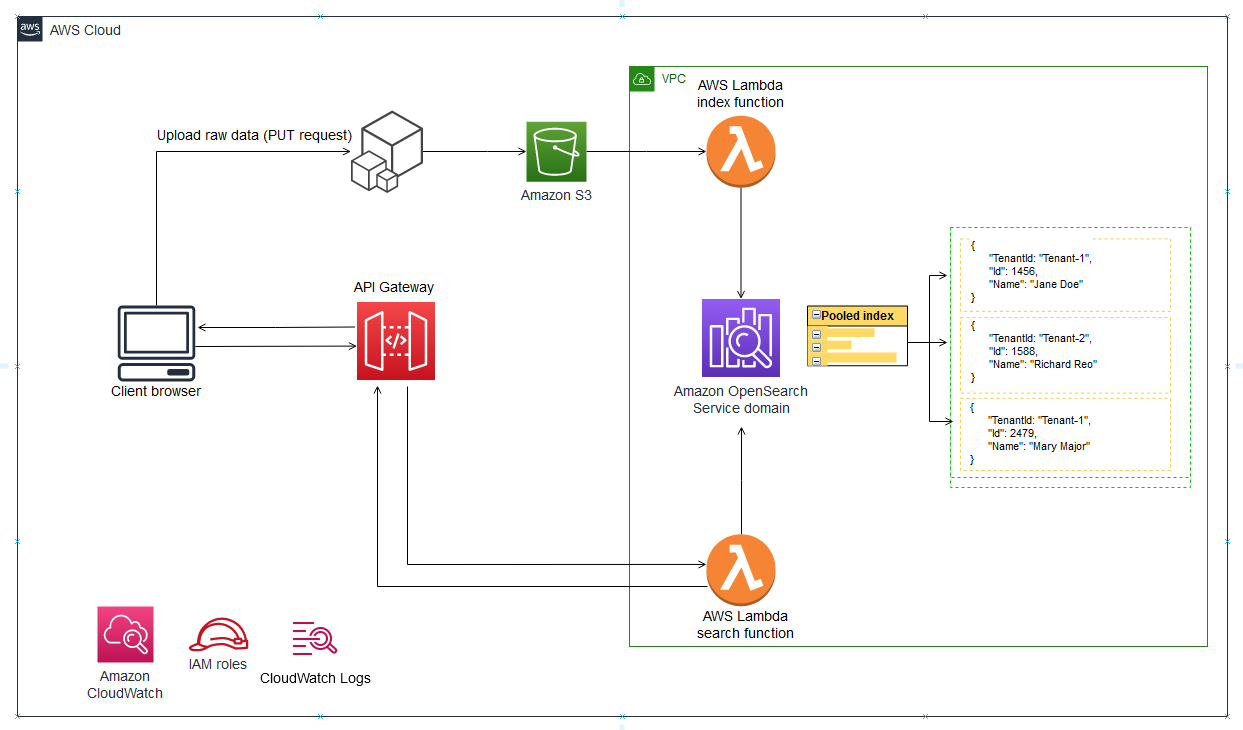
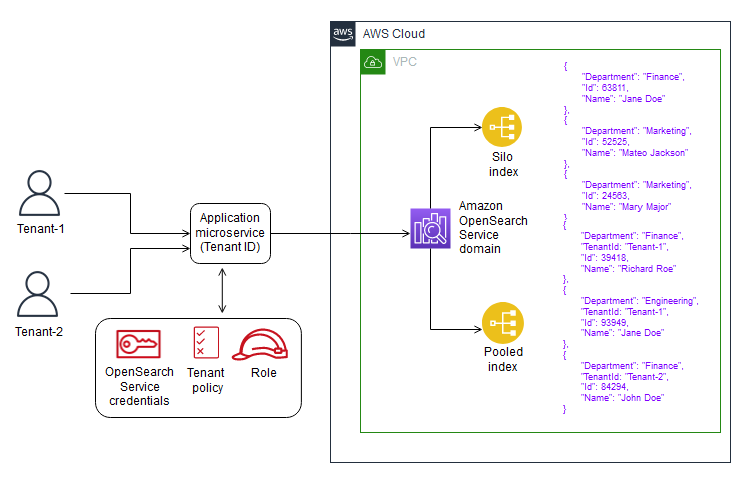
架构
下图说明了此模式的高级架构。该体系结构包括以下内容:
- AWS Lambda对内容进行索引和查询
- Amazon OpenSearch服务执行搜索
- Amazon API网关提供与用户的API交互
- Amazon S3存储原始(非索引)数据
- Amazon CloudWatch监控日志
- AWS身份和访问管理(IAM),用于创建租户角色和策略
自动化和规模
- 为了简单起见,该模式使用AWS CLI来提供基础结构并部署示例代码。您可以创建AWS CloudFormation模板或AWS Cloud Development Kit(AWS CDK)脚本来自动执行该模式。
工具
AWS服务
- AWS CLI–AWS命令行界面(AWS CLI)是通过在命令行shell中使用命令来管理AWS服务和资源的统一工具。
- AWS Lambda–AWS Lambda是一种计算服务,它允许您在无需配置或管理服务器的情况下运行代码。Lambda只在需要时运行您的代码,并自动扩展,从每天几次请求到每秒数千次。
- Amazon API网关–Amazon API网关是一种AWS服务,用于创建、发布、维护、监控和保护任何规模的REST、HTTP和WebSocket API。
- Amazon S3–Amazon Simple Storage Service(Amazon S3)是一种对象存储服务,它允许您在任何时间、从web上的任何位置存储和检索任意数量的信息。
- Amazon OpenSearch服务–Amazon OpenSearch服务是一项完全管理的服务,可让您轻松部署、安全并以经济高效的方式大规模运行Elasticsearch。
代码
附件提供了此模式的示例文件。其中包括:
- index_lambda_package.zip–使用池模型为Amazon OpenSearch服务中的数据编制索引的lambda函数。
- search_lambda_package.zip–用于在Amazon OpenSearch Service中搜索数据的lambda函数。
- Tenant-1数据–Tenant-1的原始(非索引)数据示例。
- 租户2-data–租户2的原始(非索引)数据示例。
重要提示:此模式中的故事包括为Unix、Linux和macOS格式化的CLI命令示例。对于Windows,将每行末尾的反斜杠(\)Unix连续字符替换为插入符号(^)。
史诗
Create and configure an S3 bucket
| Task | Description | Skills required |
|---|---|---|
|
Create an S3 bucket. |
Create an S3 bucket in your AWS Region. This bucket will hold the non-indexed tenant data for the sample application. Make sure that the S3 bucket's name is globally unique, because the namespace is shared by all AWS accounts. To create an S3 bucket, you can use the AWS CLI create-bucket command as follows: where |
Cloud architect, Cloud administrator |
Create and configure an Elasticsearch cluster
| Task | Description | Skills required |
|---|---|---|
|
Create an Amazon OpenSearch Service domain. |
Run the AWS CLI create-elasticsearch-domain command to create an Amazon OpenSearch Service domain: The instance count is set to 1 because the domain is for testing purposes. You need to enable fine-grained access control by using the This command creates a master user name ( Because the domain is part of a virtual private cloud (VPC), you have to make sure that you can reach the Elasticsearch instance by specifying the access policy to use. For more information, see Launching your Amazon OpenSearch Service domains using a VPC in the AWS documentation. |
Cloud architect, Cloud administrator |
|
Set up a bastion host. |
Set up a Amazon Elastic Compute Cloud (Amazon EC2) Windows instance as a bastion host to access the Kibana console. The Elasticsearch security group must allow traffic from the Amazon EC2 security group. For instructions, see the blog post Controlling Network Access to EC2 Instances Using a Bastion Server. When the bastion host has been set up, and you have the security group that is associated with the instance available, use the AWS CLI authorize-security-group-ingress command to add permission to the Elasticsearch security group to allow port 443 from the Amazon EC2 (bastion host) security group. |
Cloud architect, Cloud administrator |
Create and configure the Lambda index function
| Task | Description | Skills required |
|---|---|---|
|
Create the Lambda execution role. |
Run the AWS CLI create-role command to grant the Lambda index function access to AWS services and resources: where |
Cloud architect, Cloud administrator |
|
Attach managed policies to the Lambda role. |
Run the AWS CLI attach-role-policy command to attach managed policies to the role created in the previous step. These two policies give the role permissions to create an elastic network interface and to write logs to CloudWatch Logs. |
Cloud architect, Cloud administrator |
|
Create a policy to give the Lambda index function permission to read the S3 objects. |
Run the AWS CLI create-policy command to to give the Lambda index function The file |
Cloud architect, Cloud administrator |
|
Attach the Amazon S3 permission policy to the Lambda execution role. |
Run the AWS CLI attach-role-policy command to attach the Amazon S3 permission policy you created in the previous step to the Lambda execution role: where |
Cloud architect, Cloud administrator |
|
Create the Lambda index function. |
Run the AWS CLI create-function command to create the Lambda index function, which will access Amazon OpenSearch Service: |
Cloud architect, Cloud administrator |
|
Allow Amazon S3 to call the Lambda index function. |
Run the AWS CLI add-permission command to give Amazon S3 the permission to call the Lambda index function: |
Cloud architect, Cloud administrator |
|
Add a Lambda trigger for the Amazon S3 event. |
Run the AWS CLI put-bucket-notification-configuration command to send notifications to the Lambda index function when the Amazon S3 The file |
Cloud architect, Cloud administrator |
Create and configure the Lambda search function
| Task | Description | Skills required |
|---|---|---|
|
Create the Lambda execution role. |
Run the AWS CLI create-role command to grant the Lambda search function access to AWS services and resources: where |
Cloud architect, Cloud administrator |
|
Attach managed policies to the Lambda role. |
Run the AWS CLI attach-role-policy command to attach managed policies to the role created in the previous step. These two policies give the role permissions to create an elastic network interface and to write logs to CloudWatch Logs. |
Cloud architect, Cloud administrator |
|
Create the Lambda search function. |
Run the AWS CLI create-function command to create the Lambda search function, which will access Amazon OpenSearch Service: |
Cloud architect, Cloud administrator |
Create and configure tenant roles
| Task | Description | Skills required |
|---|---|---|
|
Create tenant IAM roles. |
Run the AWS CLI create-role command to create two tenant roles that will be used to test the search functionality: The file |
Cloud architect, Cloud administrator |
|
Create a tenant IAM policy. |
Run the AWS CLI create-policy command to create a tenant policy that grants access to Elasticsearch operations: The file |
Cloud architect, Cloud administrator |
|
Attach the tenant IAM policy to the tenant roles. |
Run the AWS CLI attach-role-policy command to attach the tenant IAM policy to the two tenant roles you created in the earlier step: The policy ARN is from the output of the previous step. |
Cloud architect, Cloud administrator |
|
Create an IAM policy to give Lambda permissions to assume role. |
Run the AWS CLI create-policy command to create a policy for Lambda to assume the tenant role: The file For |
Cloud architect, Cloud administrator |
|
Create an IAM policy to give the Lambda index role permission to access Amazon S3. |
Run the AWS CLI create-policy command to give the Lambda index role permission to access the objects in the S3 bucket: The file |
Cloud architect, Cloud administrator |
|
Attach the policy to the Lambda execution role. |
Run the AWS CLI attach-role-policy command to attach the policy created in the previous step to the Lambda index and search execution roles you created earlier: The policy ARN is from the output of the previous step. |
Cloud architect, Cloud administrator |
Create and configure a search API
| Task | Description | Skills required |
|---|---|---|
|
Create a REST API in API Gateway. |
Run the CLI create-rest-api command to create a REST API resource: For the endpoint configuration type, you can specify Note the value of the |
Cloud architect, Cloud administrator |
|
Create a resource for the search API. |
The search API resource starts the Lambda search function with the resource name
|
Cloud architect, Cloud administrator |
|
Create a GET method for the search API. |
Run the AWS CLI put-method command to create a For |
Cloud architect, Cloud administrator |
|
Create a method response for the search API. |
Run the AWS CLI put-method-response command to add a method response for the search API: For |
Cloud architect, Cloud administrator |
|
Set up a proxy Lambda integration for the search API. |
Run the AWS CLI command put-integration command to set up an integration with the Lambda search function: For |
Cloud architect, Cloud administrator |
|
Grant API Gateway permission to call the Lambda search function. |
Run the AWS CLI add-permission command to give API Gateway permission to use the search function: Change the |
Cloud architect, Cloud administrator |
|
Deploy the search API. |
Run the AWS CLI create-deployment command to create a stage resource named If you update the API, you can use the same CLI command to redeploy it to the same stage. |
Cloud architect, Cloud administrator |
Create and configure Kibana roles
| Task | Description | Skills required |
|---|---|---|
|
Log in to the Kibana console. |
|
Cloud architect, Cloud administrator |
|
Create and configure Kibana roles. |
To provide data isolation and to make sure that one tenant cannot retrieve the data of another tenant, you need to use document security, which allows tenants to access only documents that contain their tenant ID.
|
Cloud architect, Cloud administrator |
|
Map users to roles. |
We recommend that you automate the creation of the tenant and Kibana roles at the time of tenant onboarding. |
Cloud architect, Cloud administrator |
|
Create the tenant-data index. |
In the navigation pane, under Management, choose Dev Tools, and then run the following command. This command creates the |
Cloud architect, Cloud administrator |
Create VPC endpoints for Amazon S3 and AWS STS
| Task | Description | Skills required |
|---|---|---|
|
Create a VPC endpoint for Amazon S3. |
Run the AWS CLI create-vpc-endpoint command to create a VPC endpoint for Amazon S3. The endpoint enables the Lambda index function in the VPC to access the Amazon S3 service. For |
Cloud architect, Cloud administrator |
|
Create a VPC endpoint for AWS STS. |
Run the AWS CLI create-vpc-endpoint command to create a VPC endpoint for AWS Security Token Service (AWS STS). The endpoint enables the Lambda index and search functions in the VPC to access the AWS STS service. The functions use AWS STS when they assume the IAM role. For |
Cloud architect, Cloud administrator |
Test multi-tenancy and data isolation
| Task | Description | Skills required |
|---|---|---|
|
Update the Python files for the index and search functions. |
You can get the Elasticsearch endpoint from the Overview tab of the Amazon OpenSearch Service console. It has the format |
Cloud architect, App developer |
|
Update the Lambda code. |
Use the AWS CLI update-function-code command to update the Lambda code with the changes you made to the Python files: |
Cloud architect, App developer |
|
Upload raw data to the S3 bucket. |
Use the AWS CLI cp command to upload data for the Tenant-1 and Tenant-2 objects to the The S3 bucket is set up to run the Lambda index function whenever data is uploaded so that the document is indexed in Elasticsearch. |
Cloud architect, Cloud administrator |
|
Search data from the Kibana console. |
On the Kibana console, run the following query: This query displays all the documents indexed in Elasticsearch. In this case, you should see two, separate documents for Tenant-1 and Tenant-2. |
Cloud architect, Cloud administrator |
|
Test the search API from API Gateway. |
For screen illustrations, see the Additional information section. |
Cloud architect, App developer |
相关资源
其他信息
数据分区模型
在多租户系统中有三种常见的数据分区模型:筒仓、池和混合。您选择的模型取决于环境的合规性、噪声邻居、操作和隔离需求。
筒仓模型
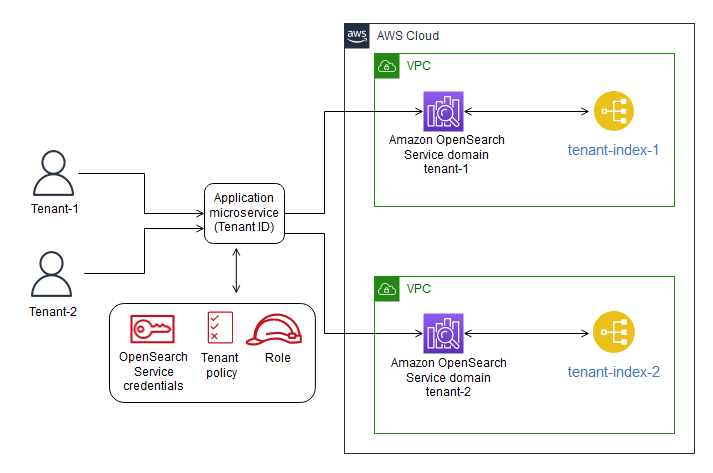
在思洛存储器模型中,每个租户的数据都存储在不同的存储区域中,其中没有租户数据的混合。您可以使用两种方法来实现AmazonOpenSearchService的筒仓模型:每个租户的域和每个租户的索引。
- 每个租户的域–您可以为每个租户使用单独的Amazon OpenSearch服务域(与Elasticsearch集群同义)。将每个租户放置在其自己的域中提供了将数据置于独立构造中的所有好处。然而,这种方法带来了管理和敏捷性方面的挑战。它的分布性使其更难汇总和评估租户的运营状况和活动。这是一个成本高昂的选项,要求每个Amazon OpenSearch服务域至少有三个主节点和两个数据节点用于生产工作负载。
- 每个租户的索引–您可以将租户数据放在Amazon OpenSearch服务集群中的单独索引中。使用这种方法,您可以在创建和命名索引时使用租户标识符,方法是将租户标识符预先挂接到索引名称。每租户索引方法可以帮助您实现筒仓目标,而无需为每个租户引入完全独立的集群。但是,如果索引数量增加,可能会遇到内存压力,因为这种方法需要更多的碎片,而主节点必须处理更多的分配和重新平衡。
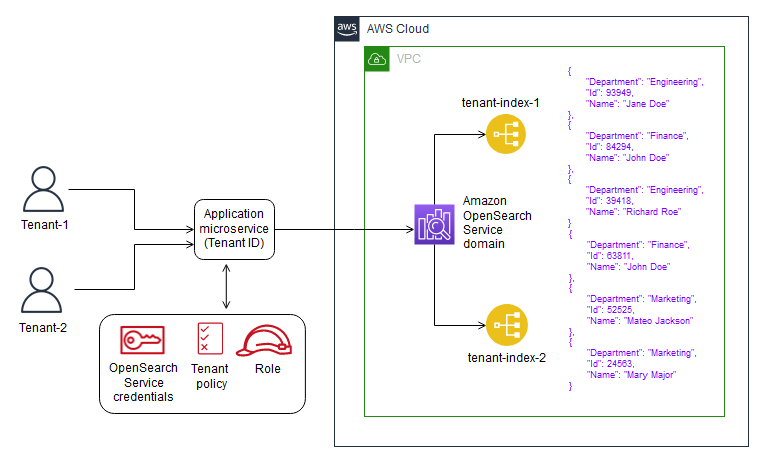
- 筒仓模型中的隔离–在筒仓模型中,您使用IAM策略隔离保存每个租户数据的域或索引。这些策略阻止一个租户访问另一个租户的数据。要实现思洛存储器隔离模型,可以创建基于资源的策略,以控制对租户资源的访问。这通常是一个域访问策略,指定主体可以对域的子资源执行哪些操作,包括Elasticsearch索引和API。使用基于IAM身份的策略,您可以在Amazon OpenSearch Service中指定域、索引或API上允许或拒绝的操作。IAM策略的Action元素描述策略允许或拒绝的特定操作,Principal元素指定受影响的帐户、用户或角色。
以下示例策略仅授予Tenant-1对Tenant-1域上的子资源的完全访问权(由es:*指定)。Resource元素中的尾随/*表示此策略适用于域的子资源,而不是域本身。当此策略生效时,租户不允许创建新域或修改现有域上的设置。
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"AWS": "arn:aws:iam::aws-account-id:user/Tenant-1"
},
"Action": "es:*",
"Resource": "arn:aws:es:Region:account-id:domain/tenant-1/*"
}
]
}
要实现每个索引的租户筒仓模型,您需要修改此示例策略,通过指定索引名称将租户1进一步限制为指定的索引。以下示例策略将Tenant-1限制为Tenant-index-1索引。
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"AWS": "arn:aws:iam::123456789012:user/Tenant-1"
},
"Action": "es:*",
"Resource": "arn:aws:es:Region:account-id:domain/test-domain/tenant-index-1/*"
}
]
}
水池模型
在池模型中,所有租户数据都存储在同一域内的索引中。租户标识符包含在数据(文档)中并用作分区键,因此您可以确定哪些数据属于哪个租户。该模型减少了管理开销。与管理多个索引相比,操作和管理合并索引更容易、更高效。但是,由于租户数据混合在同一索引中,因此您将失去思洛存储器模型提供的自然租户隔离。由于噪声邻居效应,这种方法也可能降低性能。
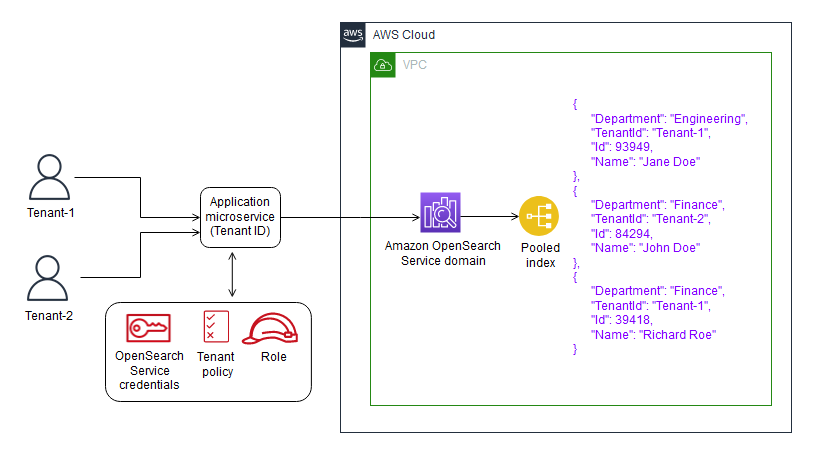
池模型中的租户隔离–通常,在池模型中实现租户隔离很困难。与思洛存储器模型一起使用的IAM机制不允许您根据文档中存储的租户ID描述隔离。
另一种方法是使用Open Distro for Elasticsearch提供的细粒度访问控制(FGAC)支持。FGAC允许您控制索引、文档或字段级别的权限。对于每个请求,FGAC都会评估用户凭据,并对用户进行身份验证或拒绝访问。如果FGAC验证了用户,它将获取映射到该用户的所有角色,并使用完整的权限集来确定如何处理请求。
为了在池模型中实现所需的隔离,可以使用文档级安全性,这允许您将角色限制为索引中的文档子集。以下示例角色将查询限制为Tenant-1。通过将此角色应用于租户1,您可以实现必要的隔离。
{
"bool": {
"must": {
"match": {
"tenantId": "Tenant-1"
}
}
}
}
混合型
混合模型在同一环境中使用筒仓和池模型的组合,为每个租户层(如免费层、标准层和高级层)提供独特的体验。每个层都遵循池模型中使用的相同安全配置文件。
混合模型中的租户隔离–在混合模型中,您遵循与池模型中相同的安全配置文件,其中在文档级别使用FGAC安全模型提供租户隔离。尽管该策略简化了集群管理并提供了灵活性,但它使体系结构的其他方面变得复杂。例如,您的代码需要额外的复杂性来确定哪个模型与每个租户相关联。您还必须确保单个租户查询不会使整个域饱和,并降低其他租户的体验。
在API网关中测试
租户1查询的测试窗口
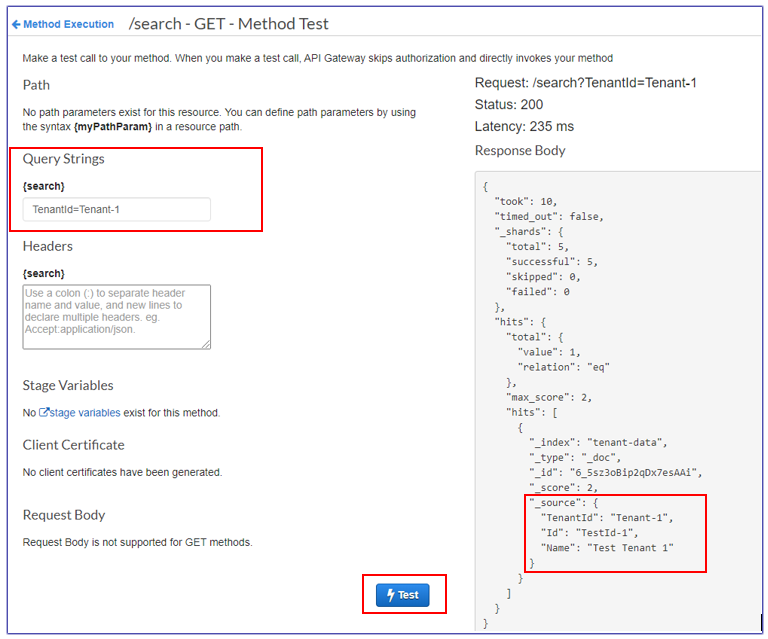
租户2查询的测试窗口

附件
要访问与此文档相关的其他内容,请解压缩以下文件:attachment.zip
Tags
最新内容
- 2 days 19 hours ago
- 6 days 19 hours ago
- 1 month 3 weeks ago
- 5 months 2 weeks ago
- 5 months 2 weeks ago
- 5 months 2 weeks ago
- 5 months 2 weeks ago
- 5 months 2 weeks ago
- 5 months 2 weeks ago
- 5 months 2 weeks ago