
category
OpenMetadata和DataHub是目前最流行的两种开源数据编目工具。这两种工具在功能上有很大的重叠,但它们也有一些区别。在这里,我们将根据这两种工具的架构、接收方法、功能、可用集成等对其进行比较。
什么是OpenMetadata?
OpenMetadata是创建Databook以解决优步数据编目问题的团队学习的结果。OpenMetadata查看了现有的数据编目系统,发现难题中缺少的部分是统一的元数据模型。
除此之外,他们还增加了元数据的灵活性和可扩展性。尽管如此,因为它在市场上的新颖性;其可靠的数据治理引擎,以及强大的搜索引擎的支持,OpenMetadata引起了人们的极大关注。
点击此处阅读更多关于OpenMetadata的信息。
什么是DataHub?
DataHub是领英解决数据发现和编目问题的第二次尝试;他们早些时候开源了另一个工具,名为WhereHows。
在第二次迭代中,领英通过创建作为DataHub骨干的通用元数据服务,解决了拥有多种数据系统、查询语言和访问机制的问题。
点击此处了解更多关于DataHub的信息。
OpenMetadata和DataHub之间有什么区别?
让我们根据以下标准比较OpenMetadata和DataHub:
- 架构和技术堆栈
- 元数据建模和接收
- 数据治理能力
- 数据沿袭
- 数据质量和数据分析
- 上游和下游集成
我们策划了上述标准,以在这些工具之间进行比较,了解了解哪些是至关重要的,尤其是如果您要选择其中一个作为元数据管理平台,为您的组织提供特定的用例。
让我们详细考虑这些因素中的每一个,并澄清我们对它们的理解。
OpenMetadata与DataHub:架构和技术堆栈
DataHub使用Kafka介导的摄取引擎将数据存储在三个独立的层中——MySQL、Elasticsearch和neo4j,使用 Kafka stream。
这些层中的数据通过API服务层提供。除了标准REST API之外,DataHub还支持Kafka和GraphQL用于下游消费。DataHub使用带有自定义注释的Pegasus定义语言(PDL)来存储模型元数据。

High level understanding of DataHub architecture. Image source: LinkedIn Engineering
OpenMetadata使用MySQL作为数据库,将所有元数据存储在统一的元数据模型中。元数据是完全可搜索的,因为它由Elasticsearch提供支持,与DataHub相同。OpenMetadata不使用专用的图形数据库,但它使用JSON模式来存储实体关系。
使用OpenMetadata的系统和人员可以直接或通过UI调用REST API。要了解有关数据模型的更多信息,请参阅解释OpenMetadata高级设计的文档页面。
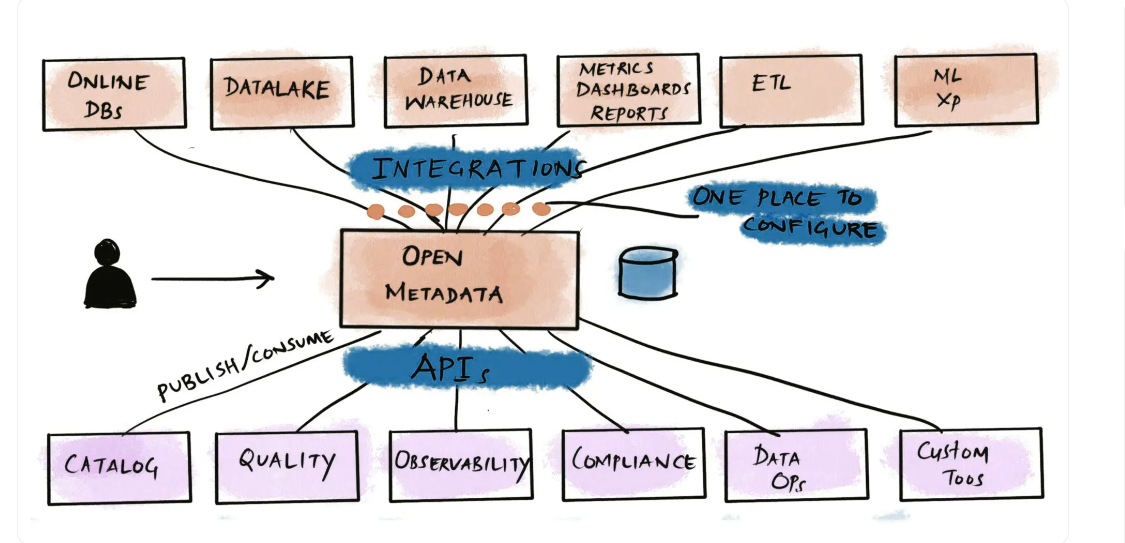
OpenMetadata与DataHub:元数据建模和接收
这两种工具的主要区别之一是,DataHub专注于基于拉和推的数据提取,而OpenMetadata显然是为基于拉的数据提取机制而设计的。
默认情况下,DataHub和OpenMetadata主要使用基于推送的提取,尽管不同之处在于DataHub使用Kafka,而OpenMetadata使用Airflow来提取数据。
DataHub中的不同服务可以从Kafka中过滤数据并提取所需内容,而OpenMetadata的Airflow将数据推送到下游应用程序的API服务器DropWizard。
这两种工具在存储元数据的方式上也有所不同。如前一节所述,DataHub使用带注释的PDL,而OpenMetadata使用带注释基于JSON模式的文档。
OpenMetadata与DataHub:数据治理功能
在今年早些时候的一次发布中,DataHub集成了他们所称的行动框架,为数据治理引擎供电。Action Framework是一个基于事件的系统,允许您出于可观察性的目的触发外部工作流。数据治理引擎会自动注释新的和已更改的实体。
OpenMetadata和DataHub都内置了基于角色的访问控制,用于管理访问和所有权。
OpenMetadata引入了一些其他概念,如重要性,以通过附加上下文提供更好的搜索和发现体验。DataHub使用一种称为Domains的结构作为常用标签和术语表术语之上的高级标签,为您提供更好的搜索体验。
OpenMetadata与DataHub:数据沿袭
随着DataHub的最新发布,它现在能够支持列级数据沿袭。OpenMetadata预计将于2022年11月中旬发布,它还承诺增强列级沿袭。
OpenMetadata的Python SDK for Lineage允许您使用用于存储沿袭数据的entityLineage架构规范从数据源实体获取自定义沿袭数据。
除了自动沿袭捕获之外,DataHub还提供了从名为“基于文件的沿袭”的数据源将沿袭数据作为文件摄取的功能。DataHub使用此处指定的基于YAML的沿袭文件格式。
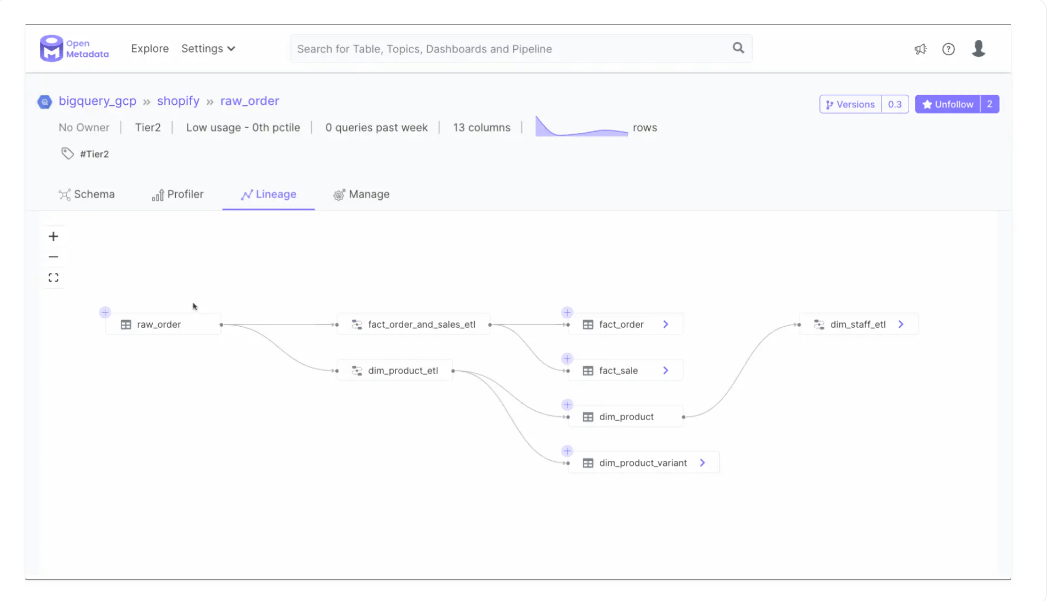
OpenMetadata与DataHub:数据质量和数据分析
尽管DataHub不久前就有一些与数据质量相关的功能的路线图项目,但它们还没有实现。然而,DataHub确实提供了与 Great Expectations和 dbt等工具的集成。您可以使用这些工具来获取元数据及其测试和验证结果。
看看这个在DataHub上运行的Great Expectations演示。
OpenMetadata对质量有不同的看法。他们已经将数据质量和分析集成到该工具中。由于有许多用于检查数据质量的开源工具,因此有许多方法可以定义测试,但OpenMetadata选择在定义测试的元数据标准方面支持Great Experiences。
如果Great Experiences已经与您的其他工作流集成,并且您更希望将其作为您的中央数据质量工具,那么您可以通过OpenMetadata的Great Experences集成实现这一点。
OpenMetadata与DataHub:上游和下游集成
DataHub和OpenMetadata都有一个基于插件的元数据摄取架构。这使它们能够与数据堆栈中的一系列工具顺利集成。
DataHub提供了一个GraphQL API、一个Open API和几个SDK,供您的应用程序或工具开发和与DataHub交互。此外,您可以使用CLI来安装所需的插件。这些与DataHub交互的各种方法允许您将数据摄入DataHub,并将数据从DataHub中取出以供进一步消费。
OpenMetadata支持50多个连接器来获取元数据,从数据库到BI工具,从消息队列到数据管道,包括其他元数据编目工具,如Apache Atlas和Amundsen。OpenMetadata目前提供两种集成-Great Experiences和Prefect。
OpenMetadata与DataHub:比较摘要
DataHub和OpenMetadata都试图解决数据编目、搜索、发现、治理和质量方面的相同问题。这两种工具都是为拥有大量数据源、团队和用例支持的大型组织解决这些问题而产生的。
尽管这些工具在发布历史和成熟度方面有点不同,但它们的功能有很大的重叠。以下是其中一些功能的快速摘要:
| Feature | OpenMetadata | DataHub |
|---|---|---|
| Search & discovery | Elasticsearch | Elasticsearch |
| Metadata backend | MySQL | MySQL |
| Metadata model specification | JSON Schema | Pegasus Definition Language (PDL) |
| Metadata extraction | Pull and push | Pull |
| Metadata ingestion | Pull | Pull |
| Data governance | RBAC, glossary, tags, importance, owners, and the capability to extend entity metadata | RBAC, tags, glossary terms, domains, and the Action Framework |
| Data lineage | Column-level (soon) | Column-level |
| Data profiling | Built-in with the possibility of using external tools | Via third-party integrations, such as dbt and Great Expectations |
| Data quality | Built-in with the possibility of using external tools like Great Expectations | Via third-party integrations, such as dbt and Great Expectations |
如果你是数据消费者或生产者,并且希望为自己的团队部署数据编目和元数据管理,同时权衡构建与购买选项,你可能想看看Atlan,这是一个为现代数据堆栈构建的第三代数据目录。
OpenMetadata与DataHub:相关资源
- Evaluating a data catalog? Here are the 5 essential features to look for in a modern data catalog
- What are the benefits of a data catalog? 5 key reasons why you need one
- Data catalogs are going through a paradigm shift! Here is everything you need to know about the Third-Generation Data Catalog.
- Learn more about Atlan: The pioneering third-generation data catalog for modern data teams.
Tags
最新内容
- 1 day 11 hours ago
- 1 week 2 days ago
- 1 week 6 days ago
- 2 months ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago