
从从业者与数据社区的最终用户交谈(大量)的角度总结2023年数据基础设施

本文将仅简要总结MAD生态系统中与数据基础设施相关的“一小部分”:

2023年数据基础设施的主要变化
💀 Hadoop
虽然Hadoop生态系统的某些部分仍在使用(例如,Hive),但其使用量已经下降到足以使Hadoop不再包含在景观图中。根据最近发布的“大数据已死”的帖子,这一点得到了证实。
🛥️ Data Lakes被合并为与lakehouses相同的类别
其中包括a.o.以下工具(括号中包括成立年份和资金总额,以供参考(如适用)):
- Cloudera (2008, $1041M) — an enterprise data hub built on top of Apache Hadoop.
- Databricks (2013, $3497M) — their lakehouse platform is used for data integration and analytics services; Databricks introduced the lakehouse paradigm and are the category leader.
- Dremio (2015, $405M) — a data analytics platform that allows business users to query data from any data source, then accelerate analytical processing for BI tools, ML, and SQL clients.
- Onehouse (2021, $33M) — a cloud-native managed lakehouse service that helps to build data lakes, process data, and own data in open-source formats.
- Azure Data Lake Storage — S3-like object storage service on Azure, commonly referred to as ADLS Gen 2
- Azure HD Insight — same as above but for the Hadoop ecosystem
- GCP’s Google BigLake — allows you to create BigLake tables on Google Cloud Storage (GCS), Amazon S3, and ADLS Gen 2 over supported open file formats, such as Parquet, ORC, and Avro.
- GCP’s Google Cloud Dataproc — same as above but for the Hadoop ecosystem
- AWS Lake Formation — makes it easier to manage an S3-based data lake with integration for Glue metadata catalog, Athena query engine, etc.
- AWS’s Amazon EMR — same as above but for the Hadoop ecosystem (see the pattern between Cloud vendors?)

新的单一类别:数据质量和可观测性
数据质量类别与数据可观察性合并,表明由于其功能的重叠不断增加,有可能进行合并。此空间中的工具包括 Precisely, Talend, Collibra, Manta, Unravel Data, Great Expectations, SodaData, Anomalo, Acceldata, Monte Carlo, Bigeye, Validio, Databand, Lightup, Metaplane, Datafold, Timeseer, Sifflet, Synq.

它对买家和最终用户有何影响?这一大类甚至还不完整,因为类似的元数据平台包含在不同的类别中(数据治理和目录、数据访问),尽管它们解决了与上述工具相同的问题:收集元数据并将其用于可观察性、数据质量、发现、协作知识共享和故障排除。对于SMB中的普通数据团队来说,所有这三个类别都提供了极好的工具,可以作为堆栈的一个很好的补充,但它们通常不是不可或缺的。相比之下,同样的工具对大企业来说是至关重要的,因为它们需要它们来进行治理、更严格的控制和合规。这意味着,许多这样的公司努力成为为大企业客户服务的默认工具。但他们中有太多人在追逐大客户。蒙特卡洛(Monte Carlo)、埃塞尔达(Acceldata)和科瑞布拉(Collibra)似乎在这一领域取得了成功。其余的要么有一个既定的客户群,他们试图追加销售,要么需要想办法与中小型企业交谈,说服他们这个问题足够重要,可以支付费用。元平面是一个有趣的异类,因为它们似乎也涵盖了较小的团队,甚至为一个人的团队提供了一个免费的永久计划。
新建数据库类别
GPU、矢量和无服务器工作负载有了新的数据库类别。

Note: Even though it’s not shown in the MAD landscape, there is a renaissance of embedded databases with DuckDB for OLAP, KuzuDB for Graph, SQLite for RDBMS, Chroma for search, and RocksDB for key-value.
完全管理的数据平台
一体式平台作为一类工具出现,有望提供更全面、开箱即用的体验,作为现代数据堆栈的替代方案。其中包括
Mozart Data, Y42, FruitionData, Keboola, Nexla, 5x, Adverity, and Data Virtuality.
咨询服务日益重要
由于生态系统的不断扩大和日益复杂,“数据和人工智能咨询”服务变得如此重要,以至于它们也有了自己的分类。

2023年数据基础设施的趋势
捆绑和整合-从买方的角度来看
买家面临预算压力和更多的首席财务官监督。从业者没有选择最好的工具,而是受到管理层的激励,选择一种紧密集成的一体式产品,以更好地控制成本(一个供应商和合同需要谈判)。数据专业人员被要求用更少的资源做更多的事情。没有新员工,也没有资源来试用未经验证的工具。
捆绑和合并-从卖方的角度来看
有太多的公司拥有重叠的功能集,或者更糟糕的是,专注于狭窄类别的“单一功能”初创公司——过于狭窄,无法长期立足。这包括反向ETL、度量存储、数据目录等。虽然这些公司都希望成为一个更大的平台,但它们的利润还不够。由于他们的现金跑道通常从几个月到3年不等,他们将不得不筹集下一轮资金或通过收购找到新的“家”,以避免破产。
在光谱的另一边,Snowflake和Databricks竞争成为默认的数据和ML平台。他们积极地不断扩大产品范围,以覆盖更广泛的数据基础设施。他们都进行了几次收购(并可能继续这样做),以扩大市场份额和功能范围。卡夫卡公司Confluent也采取了类似的做法,收购了Flink背后的Immerok公司。
捆绑和合并-合并预测
以下是适合整合的工具类别:
ETL和反向ETL-与Airbyte收购Grouparoo的方式类似,Fivetran可以收购其反向ETL合作伙伴之一(Census或Hightouch)
数据质量和可观察性-朝着同一方向融合,即数据可观察器类别仍然是如此新,以至于感兴趣的买家经常难以获得组织对此类购买的认可,尤其是在经济衰退时期(当事态发展到紧要关头时,这些工具被认为是“值得拥有的”;与我互动过的用户很少积极使用、评估,甚至要求提供类似的产品或功能,尽管它们显然很重要和有用)
数据目录-参与者太多了,目前尚不清楚哪些参与者将持续存在,以及他们是否能够在不与更大的(治理/可观察性或云数据仓库)平台捆绑的情况下独立存在。
现代数据堆栈(MDS)面临压力
MDS代表的工具通常被认为是前沿的,甚至是精英主义的。为了正确地采用这些同类最佳的工具,工程师需要花费(昂贵的)时间根据公司的需求将这些工具拼接在一起。一般来说,从工程的角度来看,这提供了极大的灵活性、模块化和适应性。然而,在公司试图削减成本的时候,许多买家倾向于牺牲一些工程理想,转而选择更集成的产品。Y42和Keboola等完全管理的解决方案最近在这一类别中越来越受欢迎。
反向ETL和CDP之间的界限变得模糊
客户数据平台是一个相当新的产品类别,它聚合来自多个来源的数据,执行细分和其他分析,并将这些数据反馈给SaaS进行营销活动。反向ETL经常用于相同的目的——在使用HEX或dbt分析某些云数据仓库中的数据后,您会将其反馈给SaaS。这两类人都开始意识到,他们所做的还不够,他们需要扩大自己的范围:
反向ETL工具开始变得类似CDP,提供直接的客户数据分析,而不必依赖其他工具。
CDP开始变得更像反向ETL,与数据仓库的集成更加紧密。
这两个类别都朝着同一个方向汇聚。
数据网格、产品、合同
在许多组织中,数据堆栈看起来像MAD景观的迷你版本(一些徽标将被本土系统的名称所取代)。数据网格是处理组织复杂性的一种方法。
虽然数据结构纯粹是一个技术概念(连接数据源的单一框架,无论数据源位于何处),但数据网格同时管理着工具和团队。其核心概念是数据产品,这些产品可能是经过策划的数据资产、模型或API。每个独立的面向领域的数据团队都拥有并负责管理其数据产品,包括SLA和质量,并将这些产品作为自助服务提供给数据消费者。一些人认为,数据合同也有助于在数据生产者和消费者之间建立更好的边界,以确保数据质量。
如何不被这个庞大的生态系统淹没
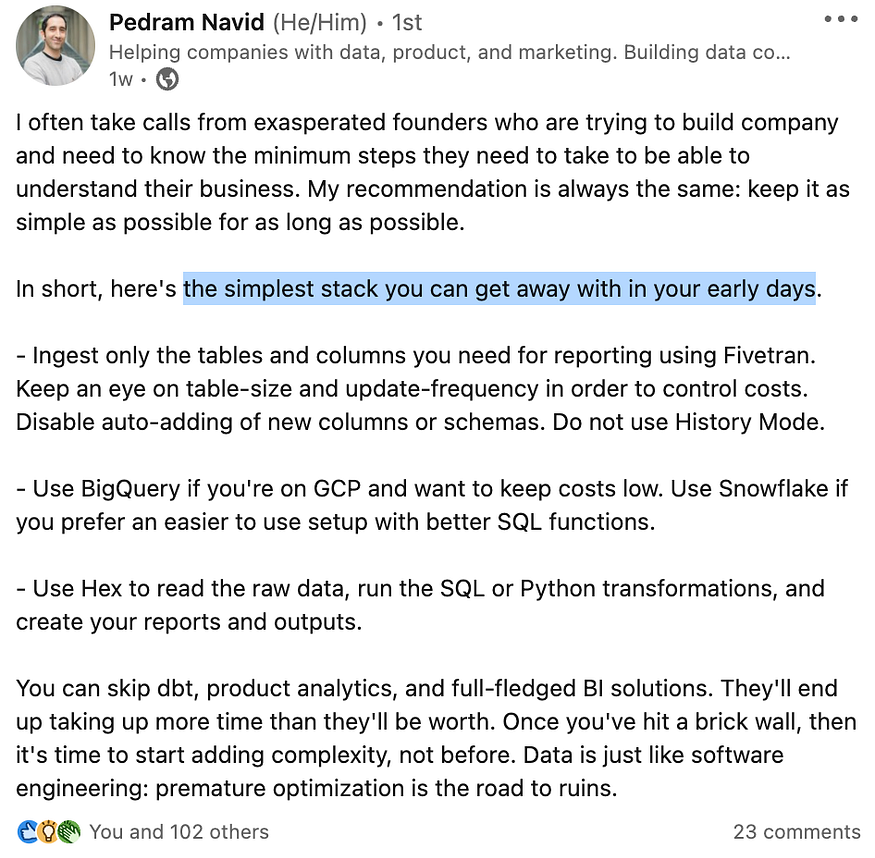
在有明确的用例之前,尽量不要采用工具。Pedram Navid在Linkedin上分享了一些很棒的建议:使用BigQuery、Fivetran和HEX从最简单的堆栈开始。通过这种方式,您将拥有一个无服务器的云数据仓库(BigQuery)、一个“刚刚好用”的现收现付数据接收工具(Fivetran),以及一个灵活的低底高顶分析和报告工具(HEX)。
最新内容
- 3 days 6 hours ago
- 1 week 4 days ago
- 2 weeks 1 day ago
- 2 months ago
- 5 months 4 weeks ago
- 5 months 4 weeks ago
- 5 months 4 weeks ago
- 5 months 4 weeks ago
- 5 months 4 weeks ago
- 5 months 4 weeks ago