
介绍
Falcon是阿布扎比技术创新研究所创建的一个新的最先进的语言模型家族,并根据Apache 2.0许可证发布。值得注意的是,Falcon-40B是第一款“真正开放”的机型,其功能可与当前的许多闭源机型相媲美。对于从业者、爱好者和行业来说,这是一个极好的消息,因为它为许多令人兴奋的用例打开了大门。
在本博客中,我们将深入研究Falcon模型:首先讨论是什么使它们独一无二,然后展示使用拥抱脸生态系统的工具在它们之上构建(推理、量化、微调等)是多么容易。
目录
- 猎鹰模型
- 演示
- 推论
- 评价
- 使用PEFT进行微调
- 结论
猎鹰模型
猎鹰家族由两个基本型号组成:猎鹰-40B和它的小兄弟猎鹰-7B。40B参数模型目前在Open LLM Leaderboard上名列前茅,而7B模型是其重量级别中最好的。
Falcon-40B需要约90GB的GPU内存——这是一个很大的数字,但仍低于Falcon表现出色的LLaMA-65B。另一方面,Falcon-7B只需要约15GB,即使在消费类硬件上也可以进行推理和微调。(在本博客的后面,我们将讨论如何利用量化使Falcon-40B即使在更便宜的GPU上也可以访问!)
TII还提供了Falcon-7B指令和Falcon-40B指令型号的指令版本。这些实验变体已经在指令和会话数据上进行了微调;因此,它们更适合于流行的助理式任务。如果你只是想快速玩模型,它们是你最好的选择。也可以根据社区构建的大量数据集构建自己的自定义指令版本。请继续阅读逐步教程!
Falcon-7B和Falcon-40B分别在1.5万亿和1万亿代币上进行了训练,符合优化推理的现代模型。Falcon模型高质量的关键因素是它们的训练数据,主要基于(>80%)RefinedWeb——一个基于CommonCrawl的新型大规模web数据集。TII没有收集分散的策划来源,而是专注于扩展和提高网络数据的质量,利用大规模的重复数据消除和严格的过滤来匹配其他语料库的质量。猎鹰模型在训练中仍然包括一些精心策划的来源(如Reddit的对话数据),但与GPT-3或PaLM等最先进的LLM相比,这一点要少得多。最棒的部分?TII公开发布了6000亿个RefinedWeb的代币摘录,供社区在自己的LLM中使用!
Falcon模型的另一个有趣的特性是它们使用了多查询注意力。普通的多头注意力方案每个头有一个查询、键和值;multiquery在所有头上共享一个键和值。
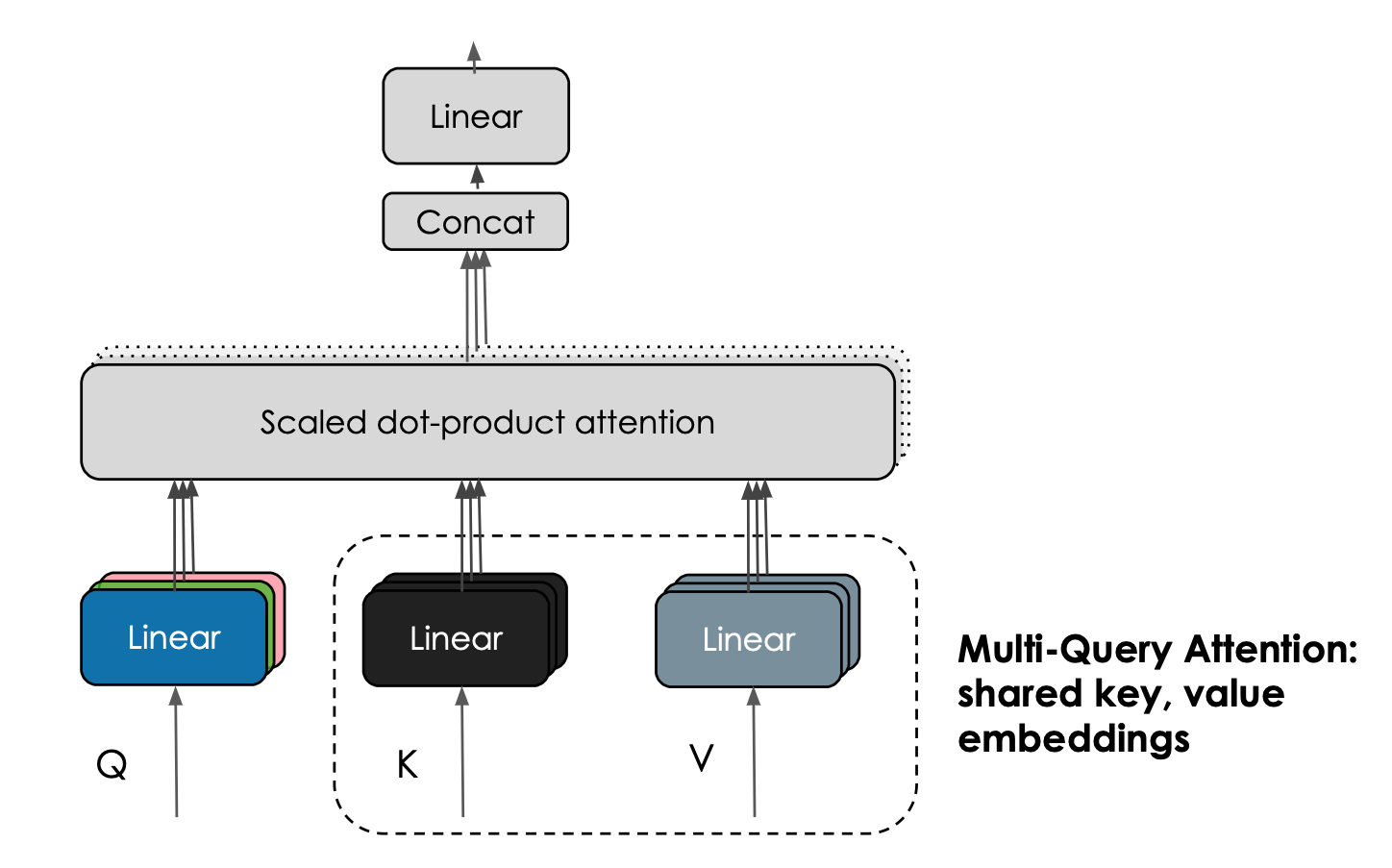
Multi-Query Attention shares keys and value embeddings across attention heads. Courtesy Harm de Vries.
这一技巧不会显著影响预训练,但它大大提高了推理的可扩展性:事实上,自回归解码过程中保持的K,V缓存现在明显更小(10-100倍,取决于架构的具体情况),降低了内存成本,并实现了新的优化,如状态性。
| Model | License | Commercial use? | Pretraining length [tokens] | Pretraining compute [PF-days] | Leaderboard score | K,V-cache size for a 2.048 context |
|---|---|---|---|---|---|---|
| StableLM-Alpha-7B | CC-BY-SA-4.0 | ✅ | 1,500B | 700 | 38.3* | 800MB |
| LLaMA-7B | LLaMA license | ❌ | 1,000B | 500 | 47.6 | 1,100MB |
| MPT-7B | Apache 2.0 | ✅ | 1,000B | 500 | 48.6 | 1,100MB |
| Falcon-7B | Apache 2.0 | ✅ | 1,500B | 700 | 48.8 | 20MB |
| LLaMA-33B | LLaMA license | ❌ | 1,500B | 3200 | 56.9 | 3,300MB |
| LLaMA-65B | LLaMA license | ❌ | 1,500B | 6300 | 58.3 | 5,400MB |
| Falcon-40B | Apache 2.0 | ✅ | 1,000B | 2800 | 60.4 | 240MB |
*score from the base version not available, we report the tuned version instead.
Demo
你可以在这个空间或下面嵌入的操场上轻松尝试大猎鹰模型(400亿参数!):
聊天机器人
Click on any example and press Enter in the input textbox!
Parameters▼
Instructions▼
HuggingFaceH4/falcon-chat-demo-for-blogbuilt with Gradio.Hosted on  Spaces
Spaces
在引擎盖下,这个游乐场使用了Hugging Face的文本生成推理,这是一个可扩展的Rust、Python和gRPC服务器,用于快速高效的文本生成。正是这项技术为HuggingChat提供了动力。
我们还构建了7B指令模型的Core ML版本,这就是它在M1 MacBook Pro上的运行方式:
视频展示了一个轻量级应用程序,它利用Swift库来完成繁重的任务:模型加载、标记化、输入准备、生成和解码。我们正忙于构建这个库,以使开发人员能够在所有类型的应用程序中集成强大的LLM,而无需重新发明轮子。它仍然有点粗糙,但我们迫不及待地想与您分享。同时,您可以从回购中下载Core ML权重,并亲自探索它们!
推论
您可以使用熟悉的transformers API在自己的硬件上运行模型,但需要注意以下几个细节:
- 模型是使用bfloat16数据类型训练的,因此我们建议您使用相同的数据类型。这需要CUDA的最新版本,并且在现代卡上效果最好。您也可以尝试使用float16运行推理,但请记住,模型是使用bfloat16评估的。
- 您需要允许远程代码执行。这是因为模型使用了一种新的架构,该架构还不是转换器的一部分——相反,所需的代码由模型作者在repo中提供。具体来说,如果允许远程执行(例如使用falcon-7b-instruction),将使用这些文件的代码:configuration_RW.py,modelling_RW.py。
考虑到这些因素,您可以使用transformers管道API加载7B指令模型,如下所示:
from transformers import AutoTokenizer
import transformers
import torch
model = "tiiuae/falcon-7b-instruct"
tokenizer = AutoTokenizer.from_pretrained(model)
pipeline = transformers.pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
torch_dtype=torch.bfloat16,
trust_remote_code=True,
device_map="auto",
)然后,您可以使用以下代码运行文本生成:
sequences = pipeline(
"Write a poem about Valencia.",
max_length=200,
do_sample=True,
top_k=10,
num_return_sequences=1,
eos_token_id=tokenizer.eos_token_id,
)
for seq in sequences:
print(f"Result: {seq['generated_text']}")你可能会得到以下内容:
Valencia, city of the sun
The city that glitters like a star
A city of a thousand colors
Where the night is illuminated by stars
Valencia, the city of my heart
Where the past is kept in a golden chest猎鹰40B的推论
运行40B型号具有挑战性,因为它的尺寸:它不适合一个具有80GB RAM的A100。以8位模式加载,可以在大约45 GB的RAM中运行,这适合A6000(48 GB),但不适合40 GB版本的A100。你会这样做:
from transformers import AutoTokenizer, AutoModelForCausalLM
import transformers
import torch
model_id = "tiiuae/falcon-40b-instruct"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype=torch.bfloat16,
trust_remote_code=True,
load_in_8bit=True,
device_map="auto",
)
pipeline = transformers.pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
)但是,请注意,混合8位推理将使用torch.foat16而不是torch.bfloat16,因此请确保彻底测试结果。
如果安装了多个板卡并加速,则可以利用device_map=“auto”自动将模型层分布在不同的板卡上。如果需要,它甚至可以将一些层卸载到CPU,但这会影响推理速度。
还有可能使用最新版本的bitsandbytes、transformer和accelerate来使用4位加载。在这种情况下,40B型号需要大约27 GB的RAM才能运行。不幸的是,这比3090或4090等卡的可用内存略多,但足以在30或40 GB的卡上运行。
文本生成推理
文本生成推理是Hugging Face开发的一个可用于生产的推理容器,用于轻松部署大型语言模型。
其主要特点是:
- 连续批处理
- 使用服务器发送事件(SSE)的令牌流
- 张量并行性在多个GPU上实现更快的推理
- 使用自定义CUDA内核优化变压器代码
- 使用普罗米修斯和开放遥测进行生产准备日志记录、监测和跟踪
自v0.8.2以来,文本生成推理原生支持Falcon 7b和40b型号,而不依赖于Transformers的“信任远程代码”功能,从而实现气密部署和安全审计。此外,Falcon实现包括自定义CUDA内核,以显著降低端到端延迟。
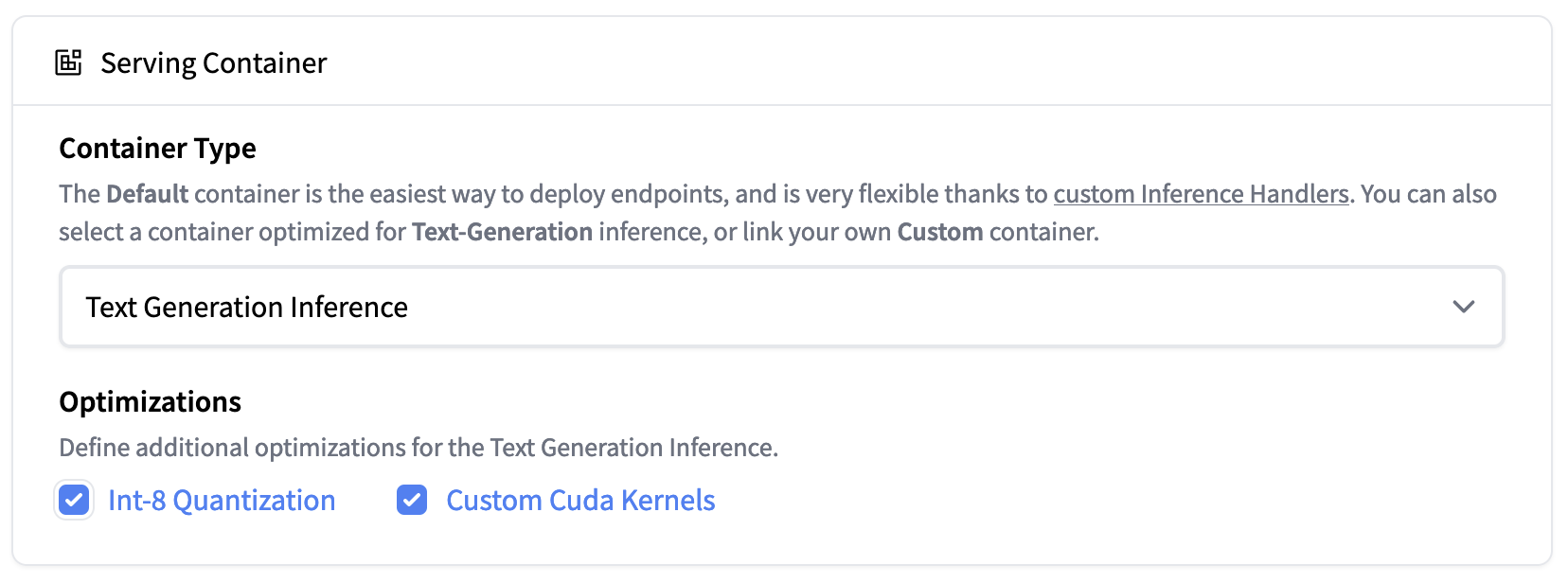 |
|---|
| Inference Endpoints now support Text Generation Inference. Deploy the Falcon 40B Instruct model easily on 1xA100 with Int-8 quantization |
文本生成推理现在集成在拥抱脸的推理端点中。要部署Falcon模型,请转到模型页面,然后单击deploy->InferenceEndpoints小部件。
对于7B型号,我们建议您选择“GPU[介质]-1x Nvidia A10G”。
对于40B型号,您需要在“GPU[xlarge]-1x Nvidia A100”上部署并激活量化:高级配置->服务容器->Int-8量化。注意:您可能需要通过电子邮件向请求配额升级api-enterprise@huggingface.co
评价
猎鹰模型有多好?Falcon作者的深入评估将很快发布,因此在此期间,我们通过开放LLM基准运行了基础模型和指导模型。该基准衡量LLM的推理能力及其在以下领域提供真实答案的能力:
- AI2推理挑战(ARC):小学多项选择科学问题。
- HellaSwag:围绕日常事件的常识推理。
- MMLU:57门科目的多项选择题(专业和学术)。
- TruthfulQA:测试模型从一组不正确的陈述中分离事实的能力。
结果表明,40B基础和指导模型非常强大,目前在LLM排行榜上分别排名第一和第二🏆!
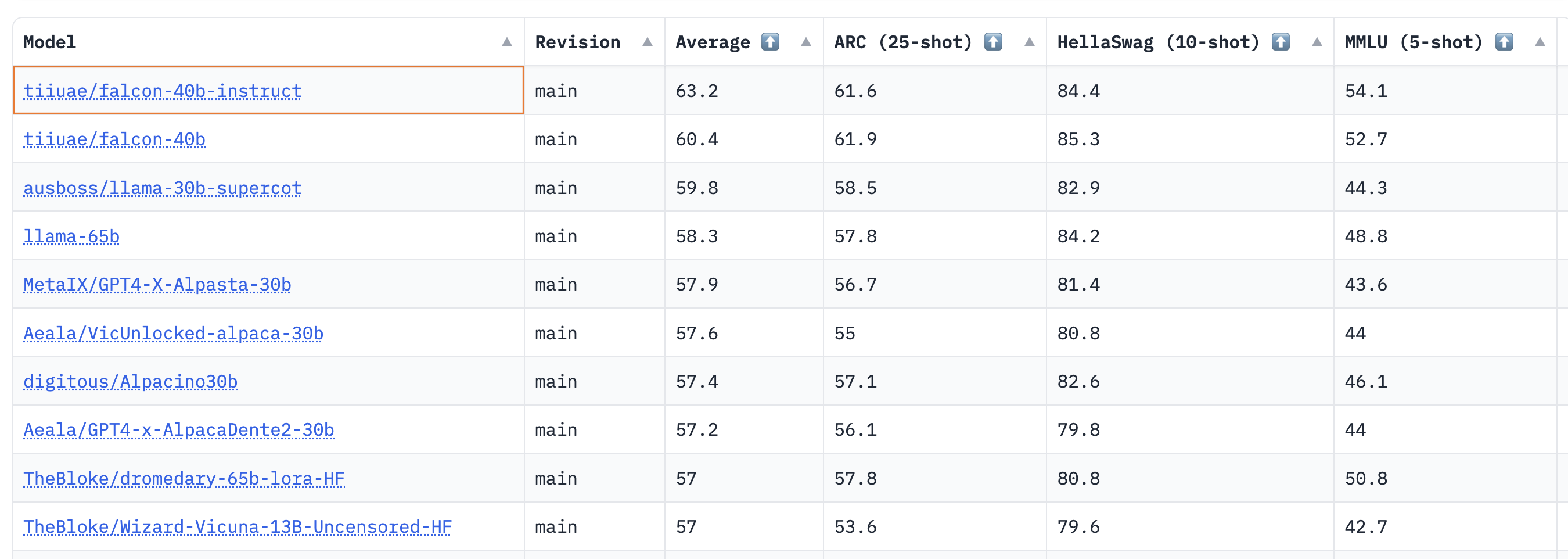
正如Thomas Wolf所指出的,这里一个令人惊讶的见解是,40B模型的预训练时间大约是LLaMa 65B所需计算量的一半(2800天对6300 PB),这表明我们还没有完全达到LLM预训练的“最佳”极限。
对于7B模型,我们看到基本模型比llama-7B更好,并超越了MosaicML的mpt-7B,成为目前该规模下最好的预训练LLM。排行榜上的热门模特入围名单如下:
| Model | Type | Average leaderboard score |
|---|---|---|
| tiiuae/falcon-40b-instruct | instruct | 63.2 |
| tiiuae/falcon-40b | base | 60.4 |
| llama-65b | base | 58.3 |
| TheBloke/dromedary-65b-lora-HF | instruct | 57 |
| stable-vicuna-13b | rlhf | 52.4 |
| llama-13b | base | 51.8 |
| TheBloke/wizardLM-7B-HF | instruct | 50.1 |
| tiiuae/falcon-7b | base | 48.8 |
| mosaicml/mpt-7b | base | 48.6 |
| tiiuae/falcon-7b-instruct | instruct | 48.4 |
| llama-7b | base | 47.6 |
尽管开放式LLM排行榜没有衡量聊天能力(其中人类评估是黄金标准),但猎鹰模型的这些初步结果非常令人鼓舞!
现在让我们来看看你如何微调自己的猎鹰模型——也许你的一个最终会登上排行榜的榜首🤗.
使用PEFT进行微调
训练10B+大小的模型在技术和计算上可能具有挑战性。在本节中,我们将介绍拥抱脸生态系统中可用的工具,这些工具可以在简单的硬件上有效地训练超大型号,并展示如何在单个NVIDIA T4(16GB-谷歌Colab)上微调Falcon-7b。
让我们看看如何在Guanaco数据集上训练Falcon,Guanaco是由大约10000个对话组成的开放助手数据集的高质量子集。有了PEFT库,我们可以使用最近的QLoRA方法来微调放置在冻结4位模型顶部的适配器。您可以在这篇博客文章中了解更多关于4位量化模型集成的信息。
因为当使用低秩适配器(LoRA)时,只有一小部分模型是可训练的,所以学习参数的数量和训练工件的大小都大大减少了。如下面的屏幕截图所示,保存的7B参数模型只有65MB(float16中为15GB)。
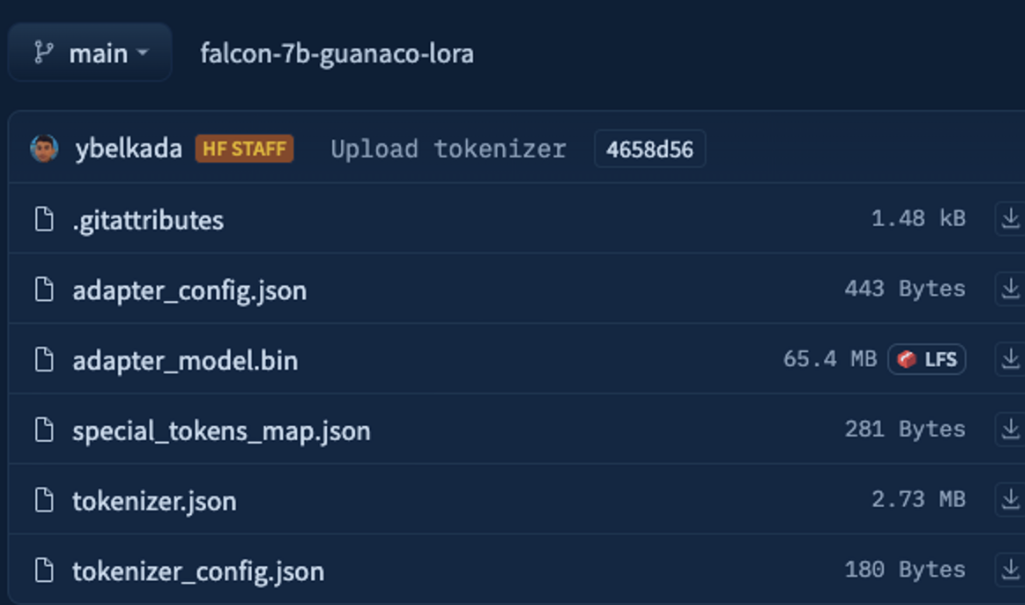
最终存储库只有65MB的重量,而原始模型的一半精度约为15GB
更具体地说,在选择了要适应的目标模块(在实践中是注意力模块的查询/关键层)之后,将小的可训练线性层附着在这些模块附近,如下所示)。然后将适配器产生的隐藏状态添加到原始状态,以获得最终的隐藏状态。

The output activations original (frozen) pretrained weights (left) are augmented by a low rank adapter comprised of weight matrices A and B (right).
一旦经过训练,就不需要保存整个模型,因为基本模型一直处于冻结状态。此外,只要这些模块的输出隐藏状态被转换为与适配器相同的数据类型,就可以将模型保持在任何任意的数据类型(int8、fp4、fp16等)中——对于返回隐藏状态的位和字节模块(Linear8bitLt和Linear4bit)来说就是这样,它们的数据类型与原始未量化模块相同。
我们在Guanaco数据集上对Falcon模型的两个变体(7B和40B)进行了微调。我们在单个NVIDIA-T4 16GB上对7B型号进行了微调,在单个NVID IA A100 80GB上对40B型号进行了调整。我们使用了4位量化的基本模型和QLoRA方法,以及TRL库中最近的SFTTrainer。
这里提供了使用PEFT复制我们实验的完整脚本,但只需要几行代码即可快速运行SFTTrainer(为了简单起见,不需要PEFT):
from datasets import load_dataset
from trl import SFTTrainer
from transformers import AutoTokenizer, AutoModelForCausalLM
dataset = load_dataset("imdb", split="train")
model_id = "tiiuae/falcon-7b"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(model_id, trust_remote_code=True)
trainer = SFTTrainer(
model,
tokenizer=tokenizer
train_dataset=dataset,
dataset_text_field="text",
max_seq_length=512,
)
trainer.train()查看原始的qlora存储库,了解有关评估经过训练的模型的更多详细信息。
微调资源
- Colab notebook to fine-tune Falcon-7B on Guanaco dataset using 4bit and PEFT
- Training code
- 40B model adapters (logs)
-
7B model adapters (logs)
结论
Falcon是一个令人兴奋的新的大型语言模型,可以用于商业应用。在这篇博客文章中,我们展示了它的功能,如何在自己的环境中运行它,以及如何在拥抱脸生态系统中轻松微调自定义数据。我们很高兴看到社区将用它来建设什么!
最新内容
- 5 days 18 hours ago
- 1 week 6 days ago
- 2 weeks 3 days ago
- 2 months ago
- 5 months 4 weeks ago
- 5 months 4 weeks ago
- 5 months 4 weeks ago
- 5 months 4 weeks ago
- 5 months 4 weeks ago
- 5 months 4 weeks ago