
Chinese, Simplified
category
卷积神经网络架构全解析:从LeNet到MobileNets的技术演进(完整版)
在计算机视觉和图像处理的快节奏领域中,图像分类始终是核心挑战:如何有效识别和分类图像。随着全球数字化和自动化进程的加速,对视觉数据理解和解析系统的需求正以前所未有的速度增长。这不仅需要识别图像,更需要精准高效的实现。传统机器学习方法常因无法处理图像数据的复杂性和高维度而力不从心,这正是卷积神经网络(CNNs)大显身手的领域。基于不同的CNN架构,我们可以训练出适应各种图像分类需求的模型。
CNN架构作为最受欢迎的深度学习框架,在图像识别领域取得了革命性突破,将精度和扩展性提升到全新高度。但并非所有CNN都生而同等有效,理解不同架构的差异是发挥其全部潜力的关键。本文将深入解析各类CNN架构,并通过Python代码实例演示如何运用CNN进行图像分类(建议在Google Colab中运行学习)。
目录
- CNN核心原理
- 架构核心组件详解
- 十大经典CNN架构演进史
- 图像分类实战:Python代码全解析
- 前沿发展与未来展望
一、CNN核心原理
1.1 网格拓扑数据处理
卷积神经网络(Convolutional Neural Networks)专为处理具有网格状拓扑结构的数据设计,这种特性使其在图像和视频处理中展现出独特优势。每个像素与其相邻像素的高度相关性,为CNN提取空间特征提供了天然优势。

1.2 局部感知与参数共享
- 局部感知野:每个神经元仅连接输入层的局部区域(典型为3×3或5×5)
- 权重共享:相同滤波器应用于所有空间位置,极大减少参数量
- 平移不变性:特征检测不受目标位置影响
二、架构核心组件详解
2.1 卷积层(Convolutional Layers)
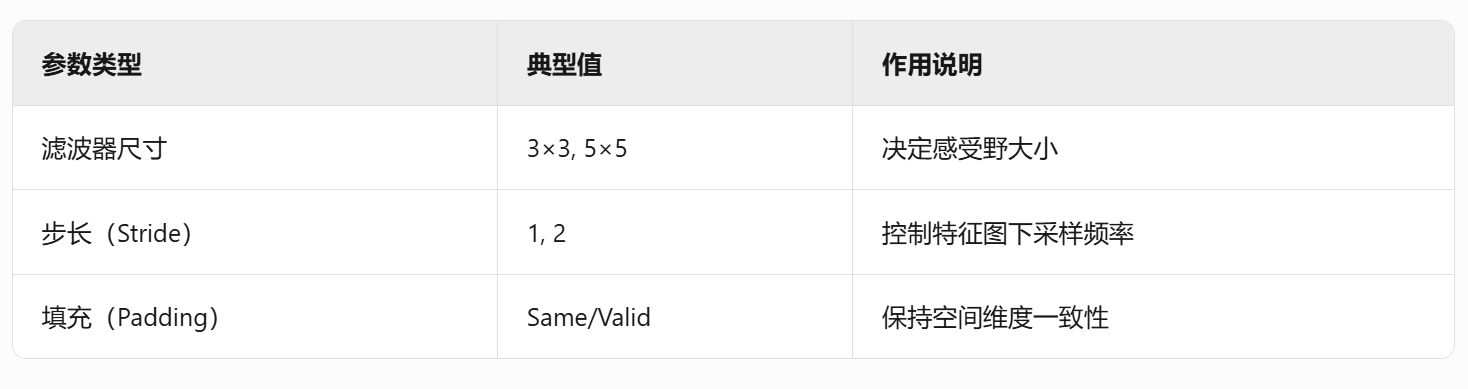
特征提取过程:
# 3×3卷积核的数学表达
output[x,y] = Σ_{i=-1}^1 Σ_{j=-1}^1 kernel[i,j] * input[x+i,y+j]2.2 池化层(Pooling Layers)
类型对比表
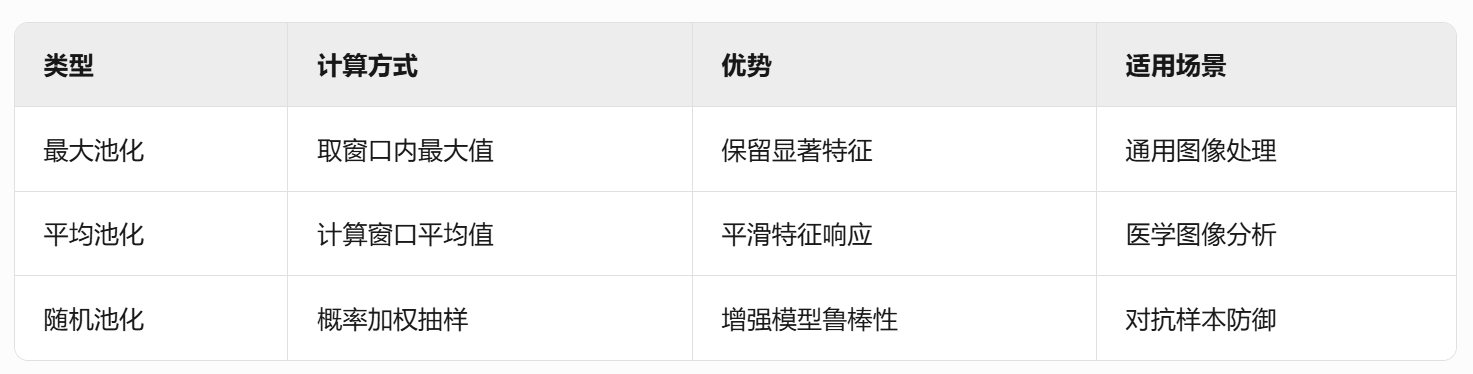
2.3 全连接层(Fully Connected Layers)
- 特征整合:将128×128×64的3D特征张量展开为1048576维向量
- 分类决策:通过Softmax函数输出类别概率分布
- 参数量示例:从4096维到1000类的全连接层含4,096,000个参数
2.4输出层
- 核心作用:将高级特征转换为可解释的输出形式
- 任务适配:
- 分类任务:使用Softmax函数生成类别概率分布
- 回归任务:使用线性激活函数输出连续值
- 重要性:直接影响模型的最终预测质量
CNN的实际应用
三、十大经典CNN架构演进史
3.1 开天辟地:LeNet-5(1998)

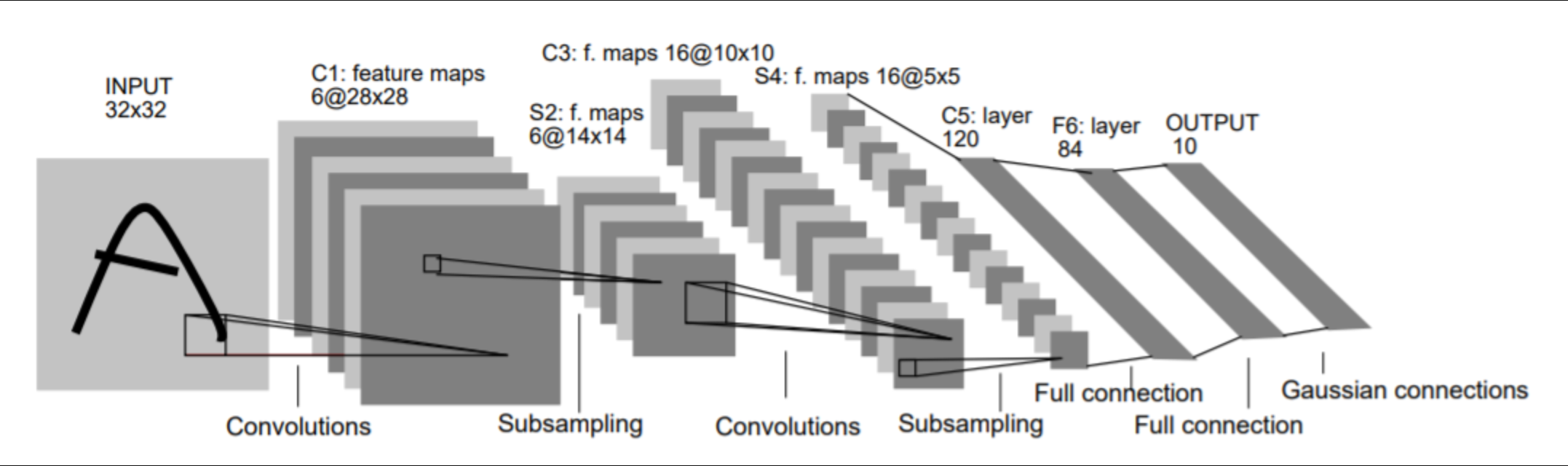
历史意义:
- 首个成功商用的CNN模型
- 美国邮政手写邮编识别准确率达98%
- 受限于当时算力,仅能处理灰度图像
3.2 深度革命:AlexNet(2012)

架构突破:
- 首次使用ReLU激活函数(训练速度提升6倍)
- 引入Dropout正则化(全连接层失活概率0.5)
- 双GPU并行训练(GTX 580 3GB显存×2)
性能对比:
3.3 深度王者:VGGNet(2014)

配置变体:
# VGG16配置示例
cfg = {
'A': [64, 'M', 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'],
'B': [64,64, 'M', 128,128, 'M', 256,256, 'M', 512,512, 'M', 512,512, 'M'],
'D': [64,64, 'M', 128,128, 'M', 256,256,256, 'M', 512,512,512, 'M', 512,512,512, 'M'] # VGG16
}3.4 ResNet:深度网络新范式
技术参数
| 参数 | 配置 |
|---|---|
| 网络深度 | 152层 |
| 训练耗时 | 32 GPU×40天 |
| 应用领域 | 图像/NLP/医疗 |
核心代码实现
def residual_block(x, filters):
shortcut = x
x = Conv2D(filters, (3,3), padding='same')(x)
x = BatchNormalization()(x)
x = ReLU()(x)
x = Conv2D(filters, (3,3), padding='same')(x)
x = BatchNormalization()(x)
x = Add()([shortcut, x])
return ReLU()(x)
3.5 MobileNets:移动端优化方案
版本对比
| 版本 | 参数量 | 推理时延 |
|---|---|---|
| V1 | 4.2M | 22ms |
| V3 | 2.9M | 15ms |
3.6 ZFNet:AlexNet的进化
关键改进点
- 首层卷积核尺寸7×7 → 提升特征捕获能力
- 可视化技术 → 支持特征图解析
- 步长优化 → 改进特征采样
3.7 GoogLeNet_DeepDream:艺术生成系统
生成流程
- 加载预训练Inception模型
- 选择混合卷积层(例:mixed4)
- 梯度上升优化
- 多尺度处理
架构对比表
四、图像分类实战:Python代码全解析
4.1 环境配置
# 推荐Google Colab环境
!pip install tensorflow==2.12.0
!nvidia-smi # 确认GPU加速可用4.2 完整代码实现
import tensorflow as tf
from tensorflow.keras.datasets import cifar10
from tensorflow.keras import Sequential, layers
# 数据加载与预处理
(X_train, y_train), (X_test, y_test) = cifar10.load_data()
X_train = X_train.astype('float32') / 255
X_test = X_test.astype('float32') / 255
y_train = tf.keras.utils.to_categorical(y_train, 10)
y_test = tf.keras.utils.to_categorical(y_test, 10)
# 构建ResNet-20简化版
def residual_block(x, filters):
shortcut = x
x = layers.Conv2D(filters, 3, padding='same')(x)
x = layers.BatchNormalization()(x)
x = layers.ReLU()(x)
x = layers.Conv2D(filters, 3, padding='same')(x)
x = layers.BatchNormalization()(x)
x = layers.Add()([shortcut, x])
return layers.ReLU()(x)
inputs = layers.Input(shape=(32, 32, 3))
x = layers.Conv2D(64, 3, padding='same')(inputs)
x = layers.BatchNormalization()(x)
x = layers.ReLU()(x)
# 堆叠残差块
for _ in range(3):
x = residual_block(x, 64)
x = layers.GlobalAveragePooling2D()(x)
outputs = layers.Dense(10, activation='softmax')(x)
model = tf.keras.Model(inputs, outputs)
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
# 训练配置
history = model.fit(X_train, y_train,
batch_size=128,
epochs=50,
validation_split=0.2,
callbacks=[tf.keras.callbacks.EarlyStopping(patience=3)])4.3 性能优化技巧
- 混合精度训练:
policy = tf.keras.mixed_precision.Policy('mixed_float16')
tf.keras.mixed_precision.set_global_policy(policy)- 数据增强:
data_aug = Sequential([
layers.RandomFlip("horizontal"),
layers.RandomRotation(0.1),
layers.RandomZoom(0.2),
layers.RandomContrast(0.3)
])五、前沿发展与未来展望
5.1 神经架构搜索(NAS)
# AutoKeras示例
import autokeras as ak
clf = ak.ImageClassifier(max_trials=10)
clf.fit(X_train, y_train, epochs=50)
best_model = clf.export_model()5.2 视觉Transformer
Swin Transformer块结构: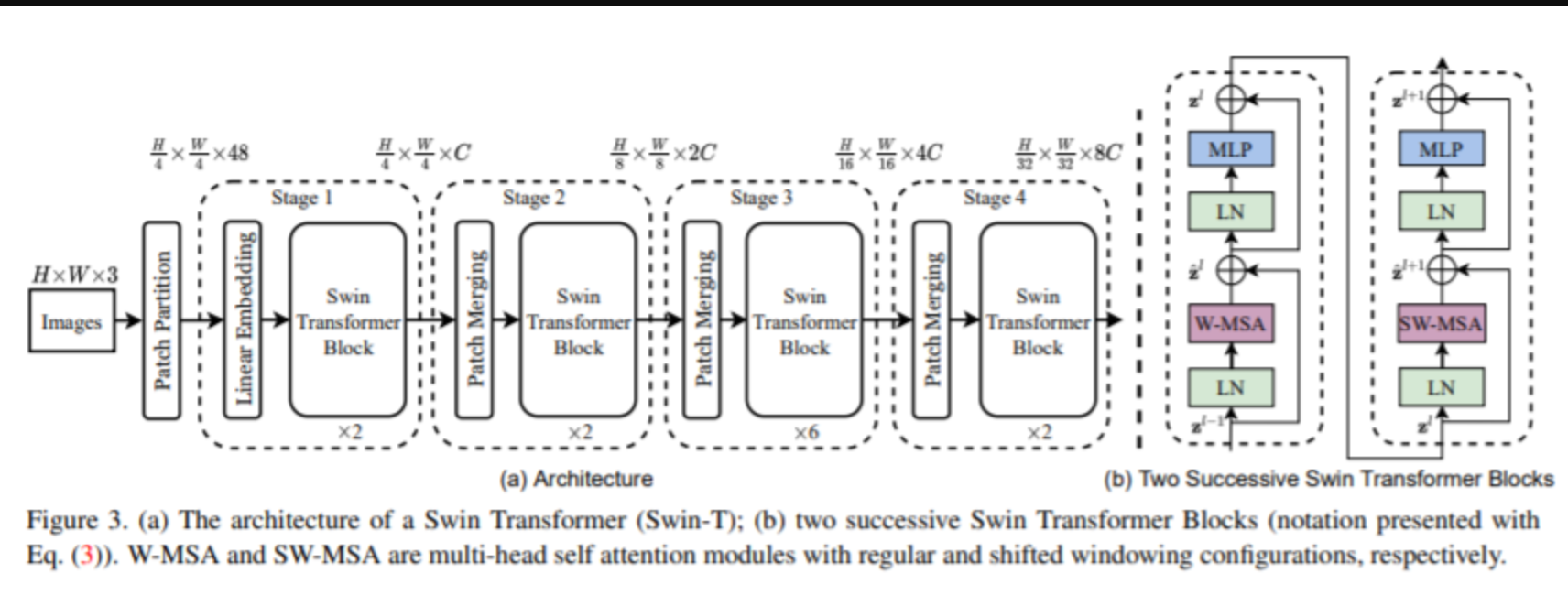
5.3 轻量化技术
MobileNetV3参数对比:
延伸阅读:
- 最新进展:Vision Transformer在ImageNet上的准确率已达90.4%(2023)
- 工业应用:特斯拉FSD芯片采用定制化CNN加速器
- 开源工具:MMClassification(OpenMMLab图像分类工具包)
通过系统掌握CNN架构的演进规律和技术细节,开发者可以更高效地设计适应特定场景的视觉模型。建议在Google Colab中运行本文代码示例,亲身体验不同架构的性能差异。
- 登录 发表评论
- 101 次浏览
发布日期
星期日, 五月 25, 2025 - 16:30
最后修改
星期日, 五月 25, 2025 - 17:12
Article
最新内容
- 1 week ago
- 2 weeks 1 day ago
- 2 weeks 5 days ago
- 2 months 1 week ago
- 6 months ago
- 6 months ago
- 6 months ago
- 6 months ago
- 6 months ago
- 6 months ago