
category
生成式人工智能在人工智能领域开辟了许多潜力。我们看到了许多用途,包括文本生成、代码生成、摘要、翻译、聊天机器人等。一个正在发展的领域是使用自然语言处理(NLP)来解锁通过直观的SQL查询访问数据的新机会。业务用户和数据分析师可以用通俗易懂的语言提出与数据和见解相关的问题,而不是处理复杂的技术代码。主要目标是从自然语言文本自动生成SQL查询。为此,文本输入被转换为结构化表示,并从该表示中创建可用于访问数据库的SQL查询。
在这篇文章中,我们介绍了文本到SQL(Text2SQL),并探讨了用例、挑战、设计模式和最佳实践。具体而言,我们讨论以下内容:
- 为什么我们需要Text2SQL
- 文本到SQL的关键组件
- 自然语言或文本到SQL的提示工程注意事项
- 优化和最佳实践
- 体系结构模式
为什么我们需要Text2SQL?
如今,传统的数据分析、数据仓库和数据库中有大量数据,对于大多数组织成员来说,这些数据可能不容易查询或理解。Text2SQL的主要目标是使非技术用户更容易访问查询数据库,他们可以用自然语言提供查询。
NLP SQL使业务用户能够通过用自然语言键入或说出问题来分析数据并获得答案,例如:
- “显示上个月每种产品的总销售额”
- “哪些产品产生了更多的收入?”
- “每个地区的客户比例是多少?”
Amazon Bedrock是一项完全管理的服务,通过单一的API提供高性能基础模型(FM)的选择,使其能够轻松构建和扩展第二代人工智能应用程序。可以利用它根据与上面列出的问题类似的问题生成SQL查询,查询组织结构化数据,并从查询响应数据生成自然语言响应。
文本到SQL的关键组件
文本到SQL系统涉及将自然语言查询转换为可运行SQL的几个阶段:
- 自然语言处理:
- 分析用户的输入查询
- 提取关键要素和意图
- 转换为结构化格式
- SQL生成:
- 将提取的详细信息映射到SQL语法中
- 生成有效的SQL查询
- 数据库查询:
- 在数据库上运行AI生成的SQL查询
- 检索结果
- 将结果返回给用户
大型语言模型(LLM)的一个显著功能是生成代码,包括用于数据库的结构化查询语言(SQL)。可以利用这些LLM来理解自然语言问题,并生成相应的SQL查询作为输出。随着更多数据的提供,LLM将通过采用情境学习和微调设置而受益。
下图说明了基本的Text2SQL流。

文本2 SQL高级流程
从自然语言到SQL的快速工程考虑
当使用LLM将自然语言转换为SQL查询时,提示至关重要,提示工程有几个重要考虑因素。
有效的提示工程是开发SQL系统自然语言的关键。清晰、直接的提示为语言模型提供了更好的说明。提供用户请求SQL查询的上下文以及相关的数据库模式详细信息,使模型能够准确地翻译意图。包括一些带注释的自然语言提示和相应的SQL查询示例,有助于指导模型生成符合语法的输出。此外,结合检索增强生成(RAG),模型在处理过程中检索类似的示例,进一步提高了映射精度。设计良好的提示,为模型提供足够的指令、上下文、示例和检索增强,对于将自然语言可靠地翻译成SQL查询至关重要。
以下是白皮书《增强大型语言模型的少量文本到SQL的能力:提示设计策略研究》中数据库代码表示的基线提示示例。
/* Given the following database schema : */
CREATE TABLE IF NOT EXISTS " gymnast " (
" Gymnast_ID " int ,
" Floor_Exercise_Points " real ,
" Pommel_Horse_Points " real ,
" Rings_Points " real ,
" Vault_Points " real ,
" Parallel_Bars_Points " real ,
" Horizontal_Bar_Points " real ,
" Total_Points " real ,
PRIMARY KEY ( " Gymnast_ID " ) ,
FOREIGN KEY ( " Gymnast_ID " ) REFERENCES " people " ( " People_ID " )
) ;
CREATE TABLE IF NOT EXISTS " people " (
" People_ID " int ,
" Name " text ,
" Age " real ,
" Height " real ,
" Hometown " text ,
PRIMARY KEY ( " People_ID " )
) ;
/* Answer the following : Return the total points of the gymnast with the lowest age .
*/
select t1 . total_points from gymnast as t1 join people as t2 on t1 . gymnast_id = t2 .
people_id order by t2 . age asc limit 1如本例所示,基于提示的少镜头学习在提示本身中为模型提供了一些带注释的示例。这演示了模型的自然语言和SQL之间的目标映射。通常,提示将包含大约2-3对,显示自然语言查询和等效的SQL语句。这几个例子指导模型从自然语言生成符合语法的SQL查询,而不需要大量的训练数据。
微调与快速工程
在为SQL系统构建自然语言时,我们经常讨论微调模型是否是正确的技术,或者有效的提示工程是否是可行的方法。这两种方法都可以根据正确的要求进行考虑和选择:
- 微调——基线模型在大型通用文本语料库上进行预训练,然后可以使用基于指令的微调,该微调使用标记的示例来提高预训练的基础模型在文本SQL上的性能。这将使模型适应目标任务。微调直接在最终任务上训练模型,但需要许多文本SQL示例。您可以使用基于LLM的监督微调来提高文本到SQL的效率。为此,您可以使用Spider、WikiSQL、CHASE、BIRD-SQL或CoSQL等多个数据集。
- 提示工程——该模型经过训练,可以完成旨在提示目标SQL语法的提示。当使用LLM从自然语言生成SQL时,在提示中提供清晰的指令对于控制模型的输出非常重要。在提示中注释不同的组件,如指向列、模式,然后指示创建哪种类型的SQL。这些指令就像告诉模型如何格式化SQL输出的指令。以下提示显示了一个示例,您可以在其中指向表列并指示创建MySQL查询:
Table offices, columns = [OfficeId, OfficeName]
Table employees, columns = [OfficeId, EmployeeId,EmployeeName]
Create a MySQL query for all employees in the Machine Learning Department
文本到SQL模型的一种有效方法是首先从基线LLM开始,而不进行任何特定任务的微调。然后,可以使用精心设计的提示来调整和驱动基础模型来处理文本到SQL的映射。这种快速工程允许您开发功能,而无需进行微调。如果基础模型上的提示工程没有达到足够的准确性,那么可以在进一步的提示工程中探索对一小部分文本SQL示例的微调。
如果仅对原始预训练模型进行即时工程不符合要求,则可能需要微调和即时工程的结合。然而,最好在最初尝试不进行微调的快速工程,因为这允许在不收集数据的情况下进行快速迭代。如果这不能提供足够的性能,那么在快速工程的同时进行微调是可行的下一步。这种整体方法最大限度地提高了效率,同时如果纯粹基于提示的方法不足,仍允许进行定制。
优化和最佳实践
优化和最佳实践对于提高效率、确保资源得到最佳利用以及以最佳方式取得正确结果至关重要。这些技术有助于提高性能、控制成本并实现更好的质量结果。
在使用LLM开发文本到SQL系统时,优化技术可以提高性能和效率。以下是需要考虑的一些关键领域:
- 缓存——为了改善延迟、成本控制和标准化,您可以将解析的SQL和识别的查询提示从文本缓存到SQL LLM。这避免了重新处理重复的查询。
- 监控——应收集有关查询解析、提示识别、SQL生成和SQL结果的日志和指标,以监控SQL LLM系统的文本。这为优化示例更新提示或使用更新的数据集重新进行微调提供了可见性。
- 物化视图与表——物化视图可以简化SQL生成,提高常见文本到SQL查询的性能。直接查询表可能会导致复杂的SQL,也会导致性能问题,包括不断创建索引等性能技术。此外,当同一表同时用于应用程序的其他区域时,您可以避免性能问题。
- 刷新数据——物化视图需要按计划刷新,以保持文本到SQL查询的数据最新。您可以使用批处理或增量刷新方法来平衡开销。
- 中央数据目录——创建集中式数据目录为组织的数据源提供了一个单一的窗格视图,并将帮助LLM选择适当的表和模式,以提供更准确的响应。从中央数据目录创建的向量嵌入可以与生成相关和精确SQL响应所需的信息一起提供给LLM。
通过应用缓存、监控、物化视图、定时刷新和中央目录等优化最佳实践,您可以使用LLM显著提高文本到SQL系统的性能和效率。
体系结构模式
让我们来看看可以为文本到SQL工作流实现的一些架构模式。
提示工程
下图说明了使用提示工程使用LLM生成查询的架构。
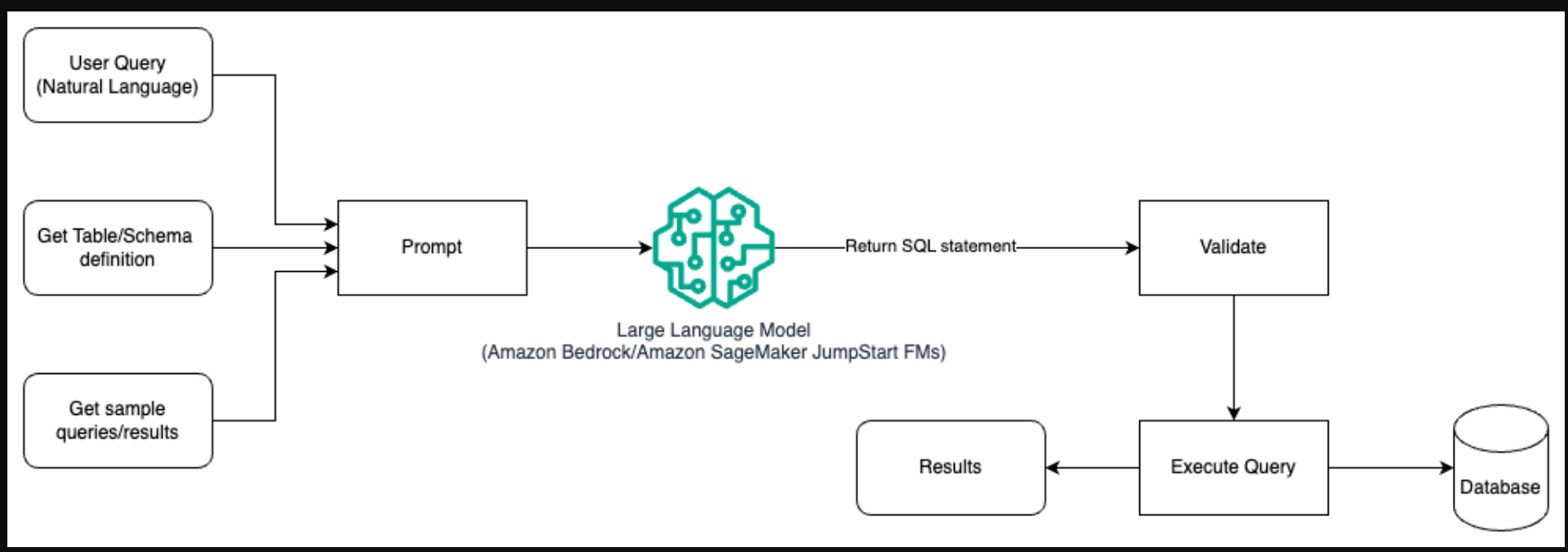
在这种模式中,用户创建了一个基于提示的少镜头学习,在提示本身为模型提供带注释的示例,其中包括表和模式的详细信息以及一些示例查询及其结果。LLM使用提供的提示返回AI生成的SQL,该SQL经过验证并在数据库中运行以获得结果。这是开始使用即时工程的最简单模式。为此,您可以使用Amazon Bedrock,这是一种完全管理的服务,通过单个API提供来自领先人工智能公司的高性能基础模型(FM)的选择,以及构建具有安全性、隐私性和负责任的人工智能生成应用程序所需的广泛功能,或JumpStart基础模型,为内容编写、代码生成、问答、文案、摘要、分类、信息检索等用例提供最先进的基础模型
快速工程和微调
下图说明了使用快速工程和微调使用LLM生成查询的架构。
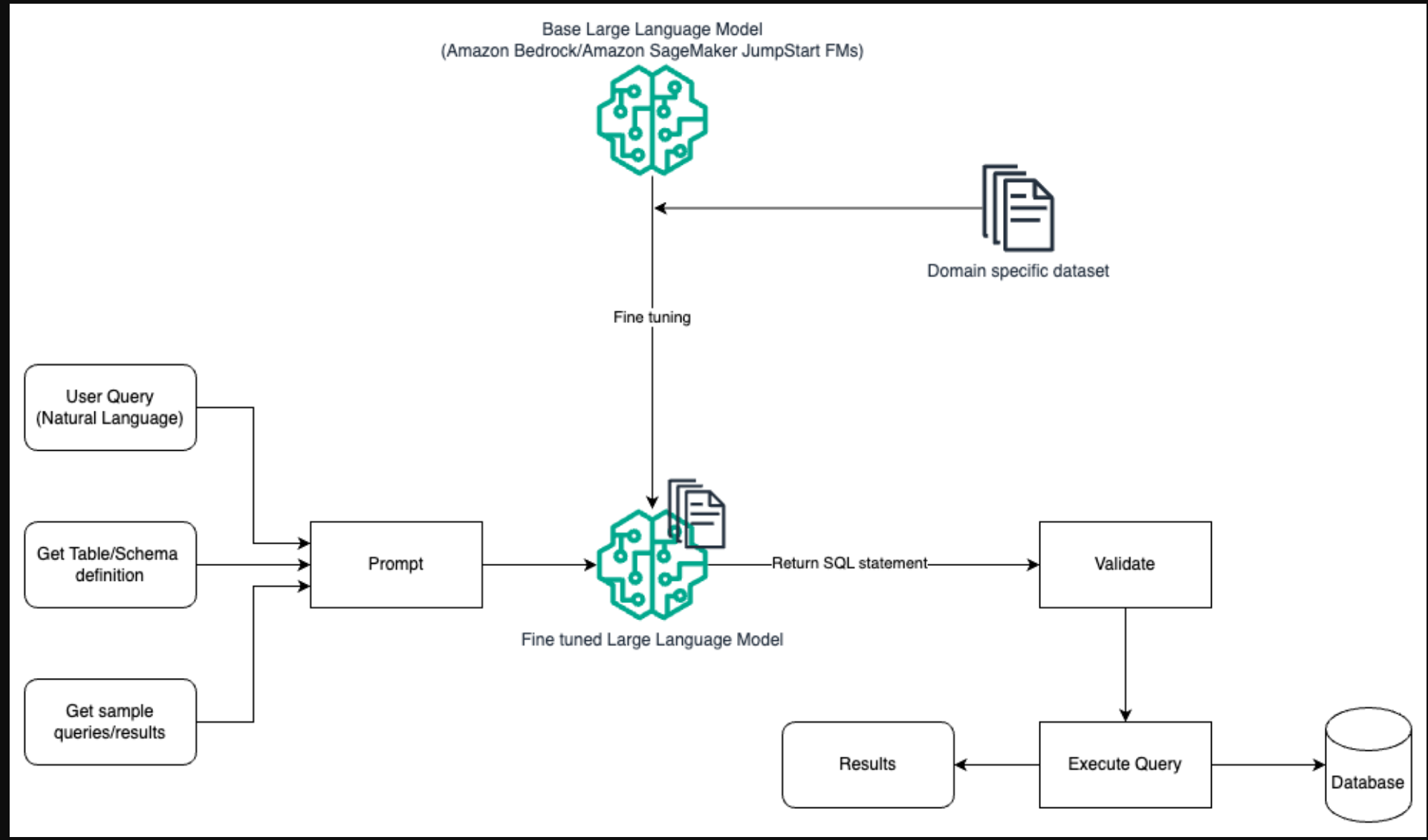
此流程与之前的模式类似,后者主要依赖于快速工程,但对特定领域的数据集进行了额外的微调。微调后的LLM用于生成具有最小提示上下文值的SQL查询。为此,您可以使用SageMaker JumpStart在特定于域的数据集上微调LLM,就像在Amazon SageMaker上训练和部署任何模型一样。
快速工程和RAG
下图说明了使用提示工程和RAG使用LLM生成查询的架构。
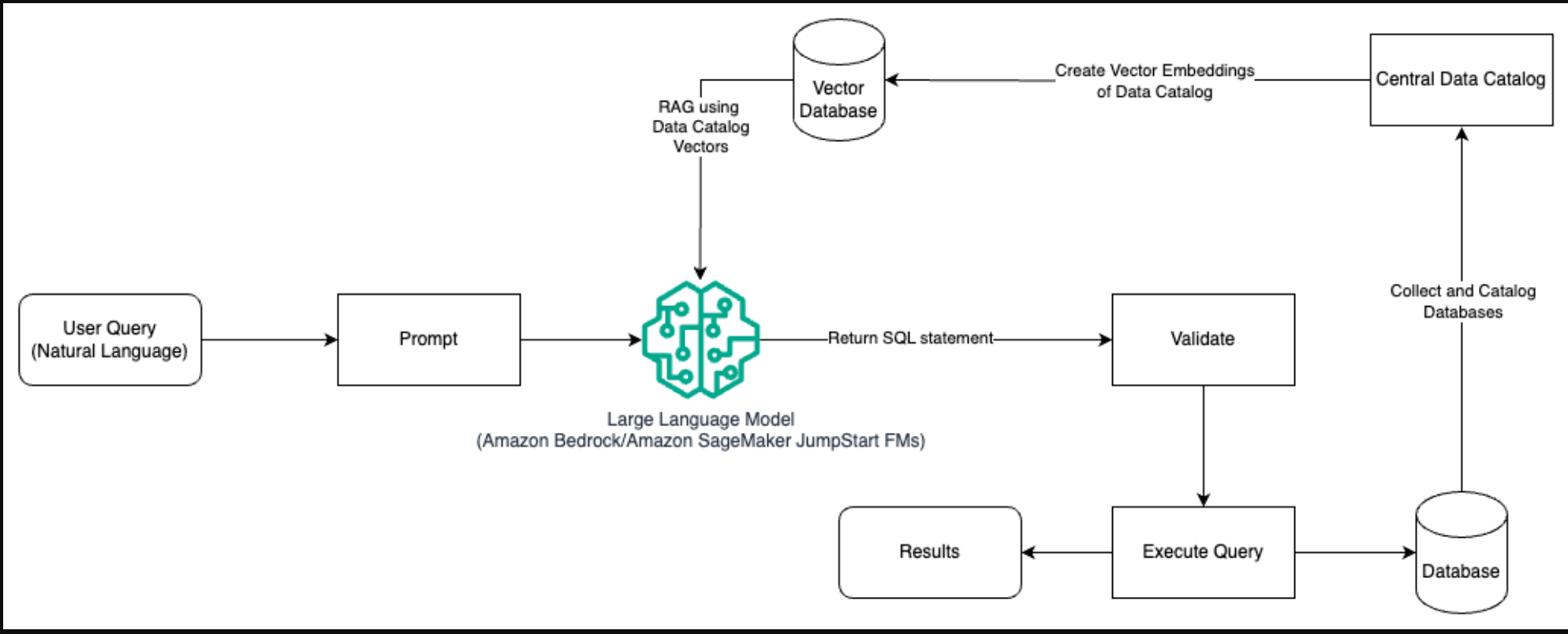
在这种模式中,我们使用检索增强生成,使用矢量嵌入存储,如Amazon Titan Embeddeds或Cohere Embed,从组织内数据库的中央数据目录(如AWS Glue data catalog)存储在Amazon Bedrock上。向量嵌入存储在向量数据库中,如亚马逊OpenSearch无服务器的向量引擎、带有pgvector扩展的PostgreSQL的亚马逊关系数据库服务(亚马逊RDS)或亚马逊Kendra。LLM在创建SQL查询时使用向量嵌入更快地从表中选择正确的数据库、表和列。当LLM需要检索的数据和相关信息存储在多个单独的数据库系统中,并且LLM需要能够从所有这些不同的系统中搜索或查询数据时,使用RAG是有帮助的。这就是向LLM提供集中式或统一数据目录的矢量嵌入,从而使LLM返回更准确和全面的信息的地方。
结论
在这篇文章中,我们讨论了如何使用自然语言到SQL生成从企业数据中生成价值。我们研究了关键组件、优化和最佳实践。我们还学习了从基本的即时工程到微调和RAG的架构模式。要了解更多信息,请参阅Amazon Bedrock,使用基础模型轻松构建和扩展生成式AI应用程序
- 登录 发表评论
- 129 次浏览
最新内容
- 1 week 5 days ago
- 2 weeks 6 days ago
- 3 weeks 3 days ago
- 2 months 1 week ago
- 6 months ago
- 6 months ago
- 6 months ago
- 6 months ago
- 6 months ago
- 6 months ago