
无缝、可扩展且安全:自动化PII检测可改进数据治理
管理敏感数据是现代数据治理的核心。无论你是在处理GDPR和CCPA的复杂问题,还是在负责任地向他人授予数据访问权限的问题上,制定一个标记敏感数据的策略至关重要。
DataHub流行的Business Glossary是一种强大的方法,可以对PII和合规类型进行建模,并在数据堆栈中对数据实体进行分类。除了手动分配这些分类外,DataHub现在还可以在接收时自动对敏感数据或PII进行分类和标记,使数据发现和访问无缝、可扩展且安全。
DataHub中的PII分类是什么样子的
DataHub的自动PII分类在摄取过程中识别敏感列和包含这些列的表,因此这些列会自动与预定义的PII相关词汇表术语相关联。
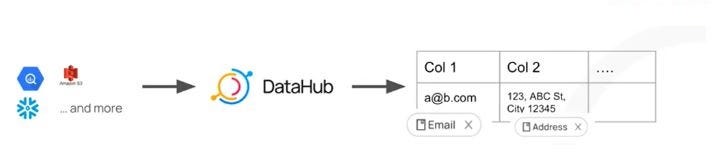
目前,DataHub的自动PII检测可以检测信息类型,包括全名、性别、全名、电子邮件电话、街道地址、信用卡号码、SSN(社会安全号码)、驾照号码、IBAN(国际银行账号)、银行SWIFT代码和IP地址。
TLDR:DataHub的自动PII分类如何工作
TLDR版本
简单地说,这个选择加入功能在列级别分析元数据,为每一列标记一个与PII相关的词汇表术语(信息类型)。
在摄入时,DataHub PII检测模块通过以下方式分析每一列是否存在信息类型
- 检查是否存在某些因素(称为预测因素)
- 为每个预测因子分配可配置的权重,
- 计算信息类型的存在的总体置信水平/得分,和
- 建议将相关的信息类型作为该列的词汇表术语——如果分数超过了您设置的置信度阈值。
作为DataHub管理员,您可以完全控制
- 启用PII分类功能
- 决定要处理的信息类型,以及
- 为信息类型的自动分类设置置信度阈值
查看本视频中DataHub的PII分类:
详细了解DataHub的PII分类工作流程
DataHub的分类器实现使用独立库来预测PII信息类型。它使用以下因素(称为预测因素)来提出适用于每列的信息类型
- 名称
- 描述
- 资料型态
- 价值
每个预测因子的存在是使用简单的基于规则的匹配和像Spacy这样的库(或其他常见的ML库)来检测的,并且为每个预测因素的存在分配置信度分数。
然后,该模块使用这些不同置信度得分的可定制加权组合来计算总体水平,该总体水平确定所提出的信息类型是否适用于该列。您可以配置每个预测因子的权重,以控制其对最终值的影响。
将得到的分数与可配置的阈值(默认配置使用0.7的阈值)进行比较,以确定信息项是否应应用于列。
配置分类信息类型
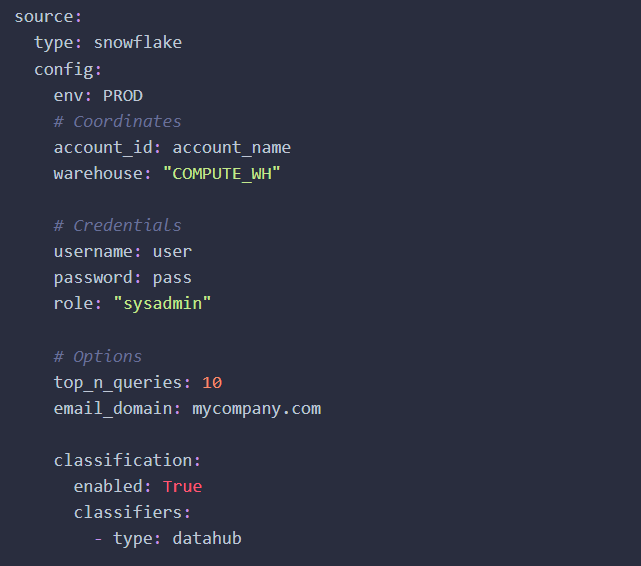
作为一名DataHub管理员,您可以自定义您的YAML配方,以配置在摄入过程中如何自动分类每种信息类型
您所需要做的就是在应用于您的用例时配置以下参数:
- 预测因子权重-在信息类型分类得分的最终计算中使用的每个预测因子的权重
- Name-要与列名匹配的正则表达式列表
- 描述-要与列描述匹配的正则表达式列表
- Datatype-要与列数据类型匹配的数据类型
- 预测类型-正则表达式或库
- regex-要与列值匹配的regex列表
- library-用于计算列值的库名称
以下是一个示例:

使用DataHub的PII分类模块
要使用分类,您所需要做的就是将分类部分添加到配方中并启用它。
以下是一个示例,说明如何根据您设置的标准和置信度阈值自定义和配置“电子邮件”信息类型的自动分类配方。
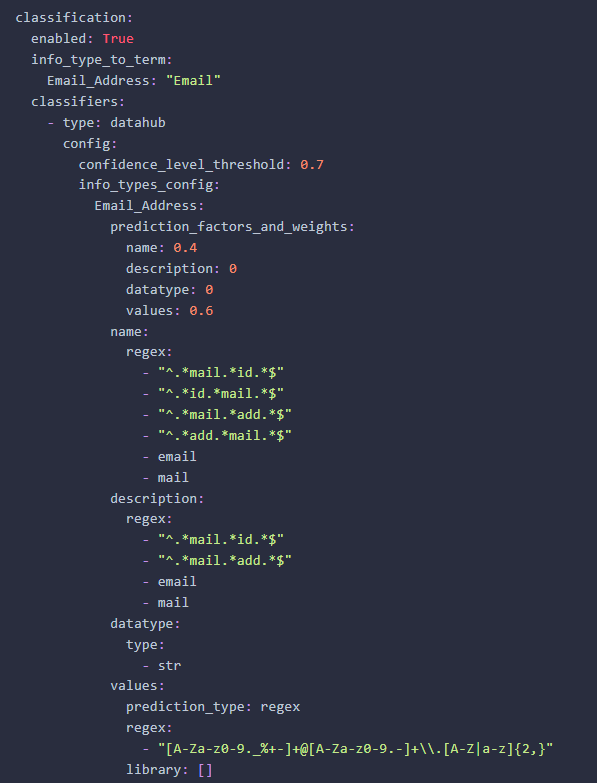
要了解如何对信息类型使用更高级的配置,请查看我们的分类功能指南。
接下来是什么?
DataHub的PII分类功能目前可用于Snowflake;我们很高兴能够将其扩展到其他基于SQL的源代码中,并渴望得到社区关于如何改进集成体验的反馈。
我们正在寻找贡献者-加入DataHub社区,实现这一目标!
最新内容
- 1 day 13 hours ago
- 1 week 2 days ago
- 1 week 6 days ago
- 2 months ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago