
category
使用3个不同框架构建的同一代理财务应用程序对代理编排进行深入比较。

我们将涵盖哪些内容
- 什么是智能体?更深入地了解我们如何定义代理,以及它们与人工智能管道和独立LLM的区别。
- 使用3个流行的代理框架构建的实践示例:LangGraph、CrewAI和OpenAI Swarm(完整代码)。
- 我们建议何时使用哪个框架。
- 接下来会发生什么:第二部分的预览,我们将探讨这些框架中的可调试性和可观察性。
介绍
由LLM驱动的自主代理经历了起起落落。从2023年AutoGPT和BabyAGI的病毒式演示到今天更精细的框架,可以自主执行端到端任务的代理LLM的概念既吸引了人们的想象力,也引起了人们的怀疑。
为什么会有新的兴趣?在过去的9个月里,LLM经历了重大升级:更长的上下文窗口、结构化的输出、更好的推理和简单的工具集成。这些进步使构建可靠的代理应用程序比以往任何时候都更加可行。
在本博客中,我们将探讨构建代理应用程序的三种流行框架:LangGraph、CrewAI和OpenAI Swarm。通过使用代理财务助理的实际例子,我们将突出每个框架的优缺点和实际用例。
什么是智能体?
代理是由大型语言模型(LLM)驱动的高级系统,可以独立地与环境交互并实时做出决策。与传统的LLM应用程序不同,其结构为刚性的预定义管道(例如,A→B→C),代理工作流引入了一种动态和自适应的方法。代理利用工具(功能或API)与环境交互,根据上下文和目标决定下一步行动。这种灵活性允许代理偏离固定序列,从而实现更自主、更高效的工作流程,以适应复杂和不断发展的任务。
然而,这种灵活性也带来了一系列挑战:
- 跨任务管理状态和内存
- 协调多个子代理及其通信模式。
- 确保工具调用可靠,并在出现复杂错误时进行处理。
- 处理大规模的推理和决策。
为什么我们需要代理框架
从零开始构建代理并非易事。LangGraph、CrewAI和OpenAI Swarm等框架简化了流程,使开发人员能够专注于他们的应用程序逻辑,而不是重新发明状态管理、编排和工具集成的轮子。
他们的核心代理框架提供
- 定义代理和工具的简单方法
- 编排机制
- 状态管理
- 支持更复杂应用程序的其他工具,如:持久层(内存)、中断等
我们将在以下部分逐一介绍这些内容
介绍智能体框架

我们选择了LangGraph、CrewAI和OpenAI Swarm,因为它们代表了智能体开发领域的最新思想流派。以下是一个快速概述:
- LangGraph:顾名思义,LangGraph认为图架构是定义和编排智能体工作流的最佳方式。与早期版本的LangChain不同,LangGraph是一个设计良好的框架,具有许多为生产构建的健壮和可定制的功能。然而,它有时比某些用例所需的更复杂,并可能产生额外的开销。
- CrewAI:相比之下,CrewAI的入门要简单得多。它具有直观的抽象,可以帮助您专注于任务设计,而不是编写复杂的编排和状态管理逻辑。然而,权衡的是,这是一个高度固执己见的框架,在未来更难定制。
- OpenAI Swarm:一个轻量级、极简主义的框架,OpenAI将其描述为“教育性”而非“生产就绪”。OpenAI Swarm几乎代表了一种“反框架”——将许多功能留给开发人员实现,或者让强大的LLM自己弄清楚。我们认为,它可能非常适合那些今天使用简单用例的人,或者那些想将灵活的智能体工作流集成到现有LLM管道中的人。
其他值得注意的框架
- LlamaIndex工作流:一个事件驱动的框架,在概念上非常适合许多智能体工作流。然而,就目前而言,我们发现开发人员仍然需要编写大量的样板代码才能使其工作
- LlamaIdex团队正在积极改进工作流框架,我们希望他们能很快创建更多的高级抽象。
- AutoGen:微软为多智能体对话编排开发的框架,AutoGen已被用于各种智能体用例。AutoGen团队从早期版本的错误和反馈中吸取教训,正在将其完全重写(从v0.2到v0.4)为事件驱动的编排框架。
建立智能体财务助理
为了对这些框架进行基准测试,我们使用每个框架构建了相同的智能体财务助理。所构建应用程序的完整代码可在此处获得:Relari智能体示例。
我们希望智能体能够处理复杂的查询,例如:
- How does Spirit Airline’s financial health compare to its competitors?
- What is Apple’s best performing product line from the financial perspective? And what are they marketing on their website?
- Find me some consumer stocks that are below $5bn in market cap that has a revenue growth over 20% YoY
Here’s an example snippet of the comprehensive response we’d like to see from assistant:

To accomplish these, we provide the agent system access to a financial database through the FMP API and internet access to research internet content.
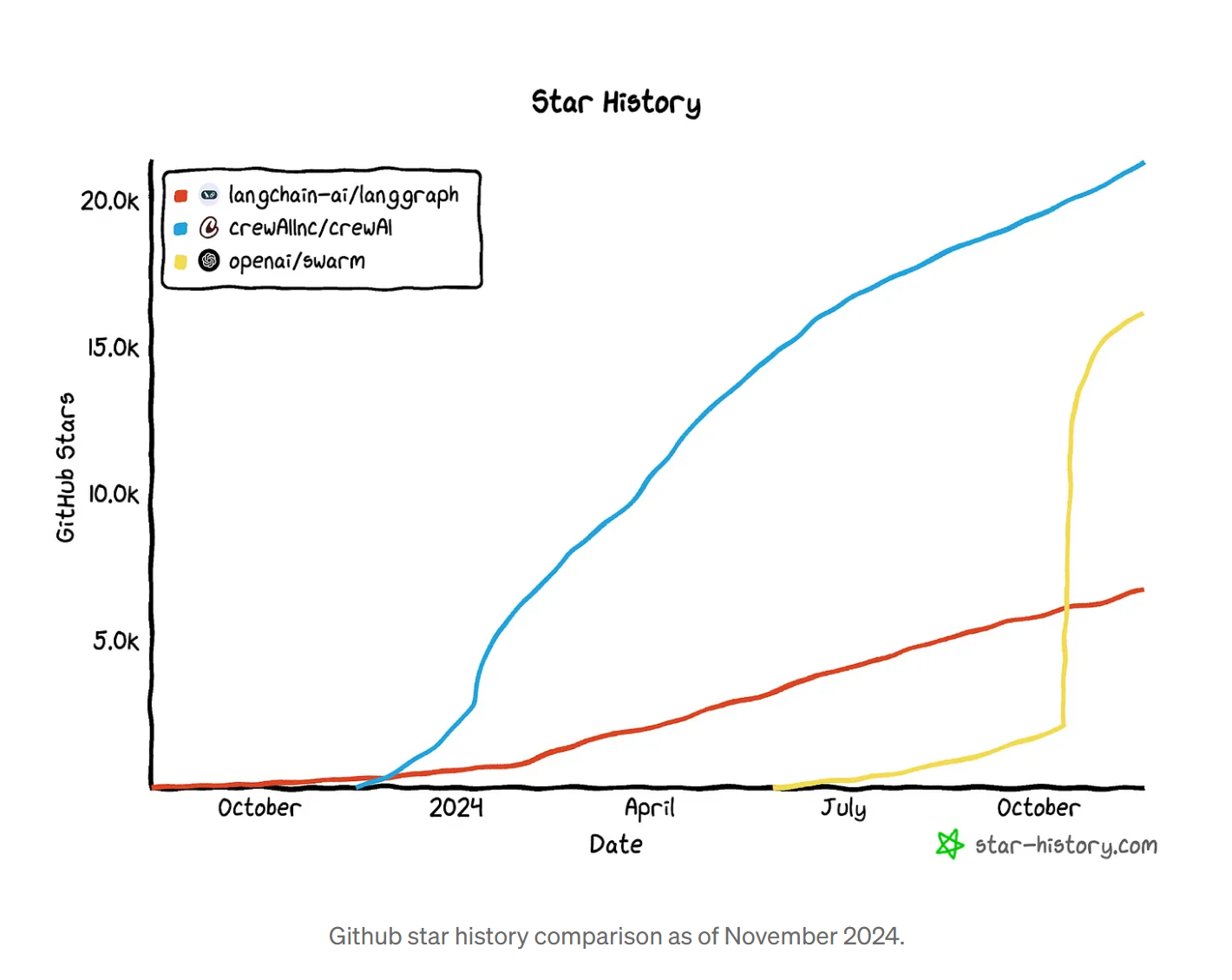
When building an agentic AI application, one of the first choices we need to take is the architecture. There are several architectures and each of them has their pros and cons. In the image below there are some popular architecture summarized by LangGraph (You can read more about the architectural choices here: multi-agent architecture).

We picked the Supervisor architecture for this application for educational purposes. So we will be creating a Supervisor Agent whose task is to decide which sub-agent to delegate the task, and three sub-agents with tool access: a financial data agent, a web research agent, and a summarizing agent.

Let’s explore how each framework approaches agent creation, tool integration, orchestration, memory, and human-in-the-loop interaction.
1. Defining Agents and Tools
We first look at how we define a regular agent like Financial Data Agent, Web Research Agent and Output Summarizing Agent and declare its associated tools in each framework. The Supervisor Agent is a special agent that plays the orchestration role so we will cover in the Orchestration section.
LangGraph
The easiest way to create a simple tool-calling agent is to use the prebuilt create_react_agent function as below, where we can provide the tools and prompts we want this agent to operate with.
from langgraph.prebuilt import create_react_agent
from langchain_openai import ChatOpenAI
from langchain_core.tools import tool
# Below is one example of a tool definition
@tool
def get_stock_price(symbol: str) -> dict:
"""Fetch the current stock price for a given symbol.
Args:
symbol (str): The stock ticker symbol (e.g., "AAPL" for Apple Inc.).
Returns:
dict: A dictionary containing the stock price or an error message.
"""
base_url = "https://financialmodelingprep.com/api/v3/quote-short"
params = {"symbol": symbol, "apikey": os.getenv("FMP_API_KEY")}
response = requests.get(base_url, params=params)
if response.status_code == 200:
data = response.json()
if data:
return {"price": data[0]["price"]}
return {"error": "Unable to fetch stock price."}
# Below is one example of a simple react agent
financial_data_agent = create_react_agent(
ChatOpenAI(model="gpt-4o-mini"),
tools=[get_stock_price, get_company_profile, ...],
state_modifier="You are a financial data agent responsible for retrieving financial data using the provided API tools ...",
)In LangGraph, everything is structured as a graph. The utility function create_react_agent creates a simple executable graph that contains the agent node and the tool node.

The agent acts as the decision maker and dynamically determines which tools to call and assesses whether it has sufficient information to transition to the __end__ state.
In the graphs, solid lines represent deterministic edges (the Tool node must always return to the agent), whereas dashed lines represent conditional edges where the LLM-powered agent is making the decisions on where to go next.
Nodes and edges are foundational building blocks of the graph. We will see later in the orchestration section that this graph can be represented as a node in a larger, more complex graph.
CrewAI
CrewAI’s agent definition centers around the relationship between agents and tasks (what the agent is supposed to accomplish).
With each agent, we must define its role, goal, and backstory, and specify the tools it has access to.
from crewai import Agent, Task
financial_data_agent = Agent(
role="Financial Data Agent",
goal="Retrieve comprehensive financial data using FMP API that provide the data needed to answer the user's query",
backstory="""You're a seasoned financial data gatherer with extensive experience in
gathering financial information. Known for your precision
and ability to find the most relevant financial data points using
FMP API that provides financial data on public companies in the US""",
tools=[
StockPriceTool(),
CompanyProfileTool(),
...
]
)Then we have to create the task that requires the agent to execute. The Task must contain the description and the expected_output.
gather_financial_data = Task(
description=("Conduct thorough financial research to gather relevant financial data that can help "
"answer the user query: {query}. Use the available financial tools to fetch accurate "
"and up-to-date information. Focus on finding relevant stock prices, company profiles, "
"financial ratios, and other pertinent financial metrics that answer the user's query: {query}."),
expected_output="A comprehensive set of financial data points that directly address the query: {query}.",
agent=financial_data_agent,
)
This structured approach to building prompts for LLMs provides a clear and consistent framework, ensuring that agents and tasks are well-defined. While this method helps maintain focus and coherence, it can sometimes feel rigid or repetitive, particularly when repeatedly defining roles, goals, backstories, and task descriptions.
Tools can be integrated using the @tool decorator, similar to the approach in LangGraph. It is worth mentioning that alternatively, we could extend the BaseTool class, which would be a more robust method for enforcing tool input schemas, thanks to the use of Pydantic models (this approach is also supported by LangGraph).
class StockPriceInput(BaseModel):
"""Input schema for stock price queries."""
symbol: str = Field(..., description="The stock ticker symbol")
class StockPriceTool(BaseTool):
name: str = "Get Stock Price"
description: str = "Fetch the current stock price for a given symbol"
args_schema: Type[BaseModel] = StockPriceInput
def _run(self, symbol: str) -> dict:
# Use FMP API to fetch the stock price of the given symbol
OpenAI Swarm
Swarm takes a different approach: instead of explicitly defining the reasoning flow in code, OpenAI proposes to structure the flow in system prompts as “Routines” (in instructions), predefined sets of steps or instructions that an agent follows to accomplish a task. This is understandable coming from OpenAI as they would prefer developers to lean more on the models ability of following instructions rather than defining sets of custom logic in code. We find this approach to be simple and effective when working with a stronger LLM that's capable of keeping track of an reasoning over the Routines.
For tools, we can just bring in directly as tools.
from swarm import Agent
financial_data_agent = Agent(
name="Financial Data Agent",
instructions="""You are a financial data specialist responsible for retrieving financial data using the provided API tools.
Your tasks:
Step 1. Given a user query, use the appropriate tool to fetch relevant financial data
Step 2. Read the data and make sure they can answer the user query. If not, modify the tool input or use different tools to get more information.
Step 3. Once you have gathered enough information, return only the raw data obtained from the tool. Do not add commentary or explanations""",
functions=[
get_stock_price,
get_company_profile,
...
]
)
2.编排
我们现在来看看每个框架的核心部分,看看它们是如何将多个子代理结合在一起的
LangGraph
langgraph的核心是基于图的编排。我们首先创建监督代理,它充当路由器,其唯一任务是分析情况并决定下一步呼叫哪个代理。执行代理本身只能将结果传达给监督代理。
LangGraph需要明确定义状态。AgentState类有助于定义不同代理之间的通用状态模式。
class AgentState(TypedDict):
messages: Annotated[Sequence[BaseMessage], operator.add]
next: str
For each agent, we interact with the state by wrapping it in a node that converts the agent output into the consistent message schema.
async def financial_data_node(state):
result = await financial_data_agent.ainvoke(state)
return {
"messages": [
AIMessage(
content=result["messages"][-1].content, name="Financial_Data_Agent"
)
]
}
We are now ready to define the agent itself.
class RouteResponse(BaseModel):
next: Literal[OPTIONS]
def supervisor_agent(state):
prompt = ChatPromptTemplate.from_messages([
("system", ORCHESTRATOR_SYSTEM_PROMPT),
MessagesPlaceholder(variable_name="messages"),
(
"system",
"Given the conversation above, who should act next?"
" Or should we FINISH? Select one of: {options}",
),
]).partial(options=str(OPTIONS), members=", ".join(MEMBERS))
supervisor_chain = prompt | LLM.with_structured_output(RouteResponse)
return supervisor_chain.invoke(state)
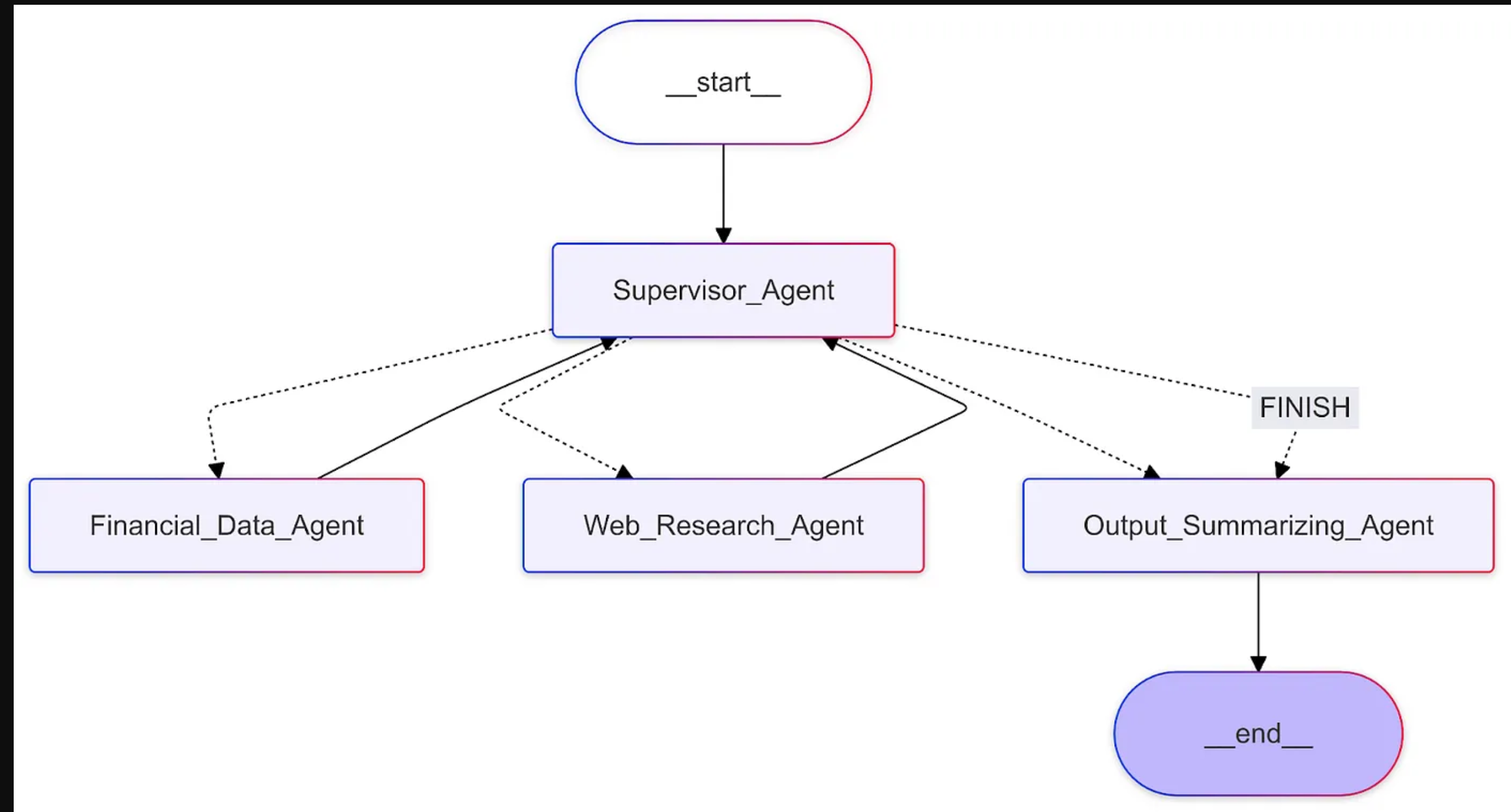
在定义了监督代理之后,我们通过将每个代理添加为节点并将所有执行逻辑添加为边,将代理工作流定义为图。
在定义边时,我们有两种可能性:规则边或条件边。当我们想要确定性过渡时,使用规则边。例如,财务数据代理应始终将结果返回给Supervisor_Agent,以决定下一步行动。
当我们希望LLM选择要采取的路径时,会使用条件边(例如,主管代理决定是否有足够的数据发送给输出求和代理,或者返回数据和Web代理以获取更多信息)。
from langgraph.graph import END, START, StateGraph
def build_workflow() -> StateGraph:
"""Construct the state graph for the workflow."""
workflow = StateGraph(AgentState)
workflow.add_node("Supervisor_Agent", supervisor_agent)
workflow.add_node("Financial_Data_Agent", financial_data_node)
workflow.add_node("Web_Research_Agent", web_research_node)
workflow.add_node("Output_Summarizing_Agent", output_summarizing_node)
workflow.add_edge("Financial_Data_Agent", "Supervisor_Agent")
workflow.add_edge("Web_Research_Agent", "Supervisor_Agent")
conditional_map = {
"Financial_Data_Agent": "Financial_Data_Agent",
"Web_Research_Agent": "Web_Research_Agent",
"Output_Summarizing_Agent": "Output_Summarizing_Agent",
"FINISH": "Output_Summarizing_Agent",
}
workflow.add_conditional_edges(
"Supervisor_Agent", lambda x: x["next"], conditional_map
)
workflow.add_edge("Output_Summarizing_Agent", END)
workflow.add_edge(START, "Supervisor_Agent")
return workflow
Here is the resulting graph.
CrewAI
In contrast to LangGraph, CrewAI abstracts away most of the orchestration tasks.
supervisor_agent = Agent(
role="Financial Assistant Manager",
goal="Leverage the skills of your coworkers to answer the user's query: {query}.",
backstory="""You are a manager who oversees the workflow of the financial assistant,
skilled in overseeing complex workers with different skills and ensuring that you can answer the user's query with the help of the coworkers.
You always try to gather data using the financial data agent and / or web scraping agent first.
After gathering the data, you must delegate to the output summarizing agent to create a comprehensive report instead of answering the user's query directly.""",
verbose=True,
llm=ChatOpenAI(model="gpt-4o", temperature=0.5),
allow_delegation=True,
)
与Langgraph类似,我们首先创建监督代理。请注意allow_remission标志,它允许代理将任务传递给其他代理。
接下来,我们使用船员将特工召集在一起。在此选择Process.hierarchical以允许主管代理委派任务非常重要。在幕后,监督代理接收用户查询并将其转换为任务,然后找到相关代理来执行这些任务。另一种选择是,如果我们想创建一个更具确定性的流程,其中任务将按顺序执行,则不使用管理器代理,而是执行Process.sequential。
finance_crew = Crew(
agents=[
financial_data_agent,
web_scraping_agent,
output_summarizing_agent
],
tasks=[
gather_financial_data,
gather_website_information,
summarize_findings
],
process=Process.hierarchical,
manager_agent=supervisor_agent,
)
OpenAI Swarm
Swarm orchestration uses a very simple strategy — handoffs. The core idea is to create a transfer function where it uses another agent as a tool.
This is undoubtedly the cleanest approach. The relationships are implicit in the transfer functions.
def transfer_to_summarizer():
return summarizing_agent
def transfer_to_web_researcher():
return web_researcher_agent
def transfer_to_financial_data_agent():
return financial_data_agent
supervisor_agent = Agent(
name="Supervisor",
instructions="""You are a supervisor agent responsible for coordinating the Financial Data Agent, Web Researcher Agent, and Summarizing Agent.
Your tasks:
1. Given a user query, determine which agent to delegate the task to based on the user's query
2. If the user's query requires financial data, delegate to the Financial Data Agent
3. If the user's query requires web research, delegate to the Web Researcher Agent
4. If there's enough information already available to answer the user's query, delegate to the Summarizing Agent for final output.
Never summarize the data yourself. Always delegate to the Summarizing Agent to provide the final output.
""",
functions=[ # Agent as a tool
transfer_to_financial_data_agent,
transfer_to_web_researcher,
transfer_to_summarizer
]
)
这种方法的一个缺点是,随着应用程序的增长,代理之间的依赖关系更难跟踪。
3.记忆
内存是有状态代理系统的关键组件。我们可以区分两层记忆:
短期记忆允许代理保持多回合/多步骤执行,
长期记忆允许代理在会话中学习和记住偏好。
这个主题可能会变得非常复杂,但让我们来看看每个框架中可用的最简单的内存编排。
from langgraph.checkpoint.memory import MemorySaver
def build_app():
"""Build and compile the workflow."""
memory = MemorySaver()
workflow = build_workflow()
return workflow.compile(checkpointer=memory)
To associate an agent execution with a memory thread, pass a configuration with a thread_id. This tells the agent which thread's memory checkpointer to use. For example:
config = {"configurable": {"thread_id": "1"}}
app = build_app()
await run(app, input, config)
To save cross-thread memory, LangGraph allows us to save memory to a JSON Document Storage.
from langgraph.store.memory import InMemoryStore
store = InMemoryStore() # Can be a DB-backed store in production use
user_id = "user_0"
store.put(
user_id,
"current_portfolio",
{
"portfolio": ["TSLA", "AAPL", "GOOG"],
}
)
CrewAI
Not surprisingly, CrewAI takes a simpler, but more rigid approach. All that’s required on the developer side is to set memory to true.
finance_crew = Crew(
agents=[financial_data_agent, web_researcher_agent, summarizing_agent],
tasks=[gather_financial_data, gather_website_information, summarize_findings],
process=Process.hierarchical,
manager_agent=supervisor_agent,
memory=True, # creates memory databases in "CREWAI_STORAGE_DIR" folder
verbose=True, # necessary for memory
)
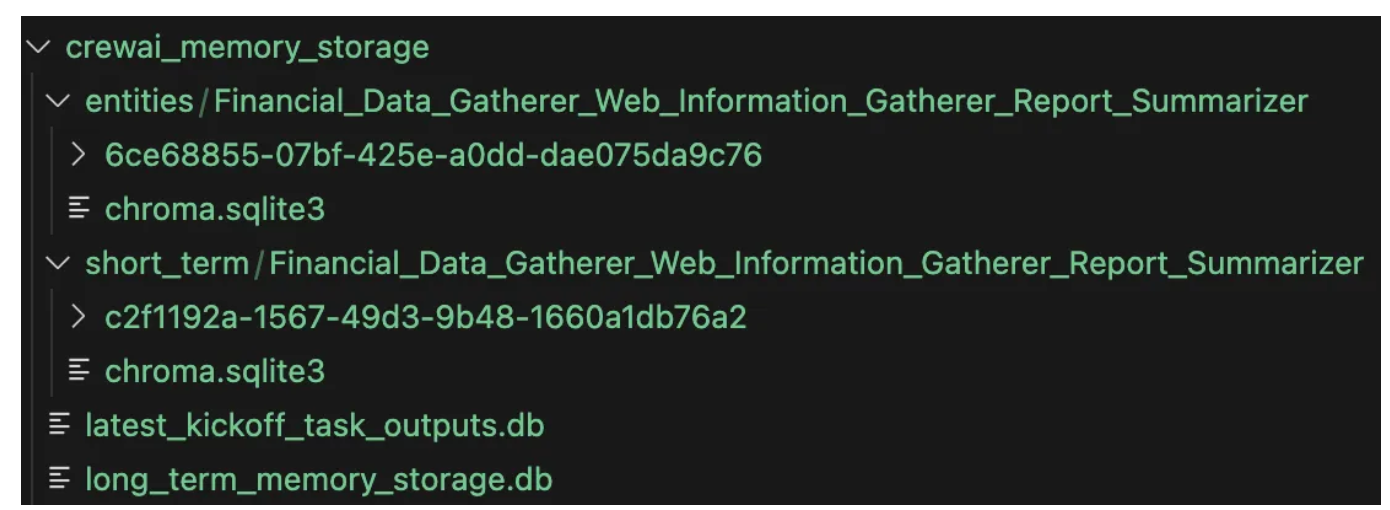
What it does behind the scene is very complex, as it creates a few different memory storage:
- Short-term memory: it creates a ChromaDB vectorstore with OpenAI Embeddings that stores the agent execution history.
- Most recent memory: SQLite3 db to store the most recent task execution results.
- Long-term memory: SQLite3 db to store task results, note that the task description has to match exactly (fairly strict) for a long term memory to be retrieved
- Entity memory: extracts key entities and stores the entity relationship into another ChromaDB vectorstore.
OpenAI Swarm
Swarm使用简单的无状态设计,没有任何内置内存功能。关于OpenAI如何看待内存的一个参考可以在其有状态助手API中看到。每个对话都有一个用于短期记忆的thread_id,而每个助手都有一个子助手_id,可以与长期记忆相关联。
也可以集成第三方存储层提供商,如mem0,或实现我们自己的短期和长期。
4.Human In Loop
尽管我们希望代理是自主的,但许多代理都是为与人类交互而设计的。
例如,客户支持代理可以在整个执行链中向用户询问信息。人类还可以充当审计员或向导,以实现更无缝的人机协作
LangGraph
LangGraph允许我们在图中设置断点,如下所示,如果我们想在汇总器构建最终输出之前添加一个人工检查点。
workflow.compile(checkpointer=checkpointer, interrupt_before=["Output_Summarizing_Agent"])
The Graph will then execute until the break point is reached. We can then implement a step to get the user input before proceeding with the graph.
# Run the graph until the first interruption
for event in graph.stream(initial_input, thread, stream_mode="values"):
print(event)
try:
user_approval = input("Do you want to go to Output Summarizer? (yes/no): ")
except:
user_approval = "yes"
if user_approval.lower() == "yes":
# If approved, continue the graph execution
for event in graph.stream(None, thread, stream_mode="values"):
print(event)
else:
print("Operation canceled by user.")
CrewAI
CrewAI allows humans to provide feedback to an agent by just setting human_input=True flag in the agent initialization.


The agent will then pause after executing and ask the user to input natural language feedback on its actions and results (see below).
However, it doesn’t support more custom human-in-the-loop interactions.
OpenAI Swarm
Swarm doesn’t have any built-in human-in-the-loop functions. However, the simplest way to add human input in the middle of the execution is to add human as a Tool or as an agent that the AI agents can transfer to.
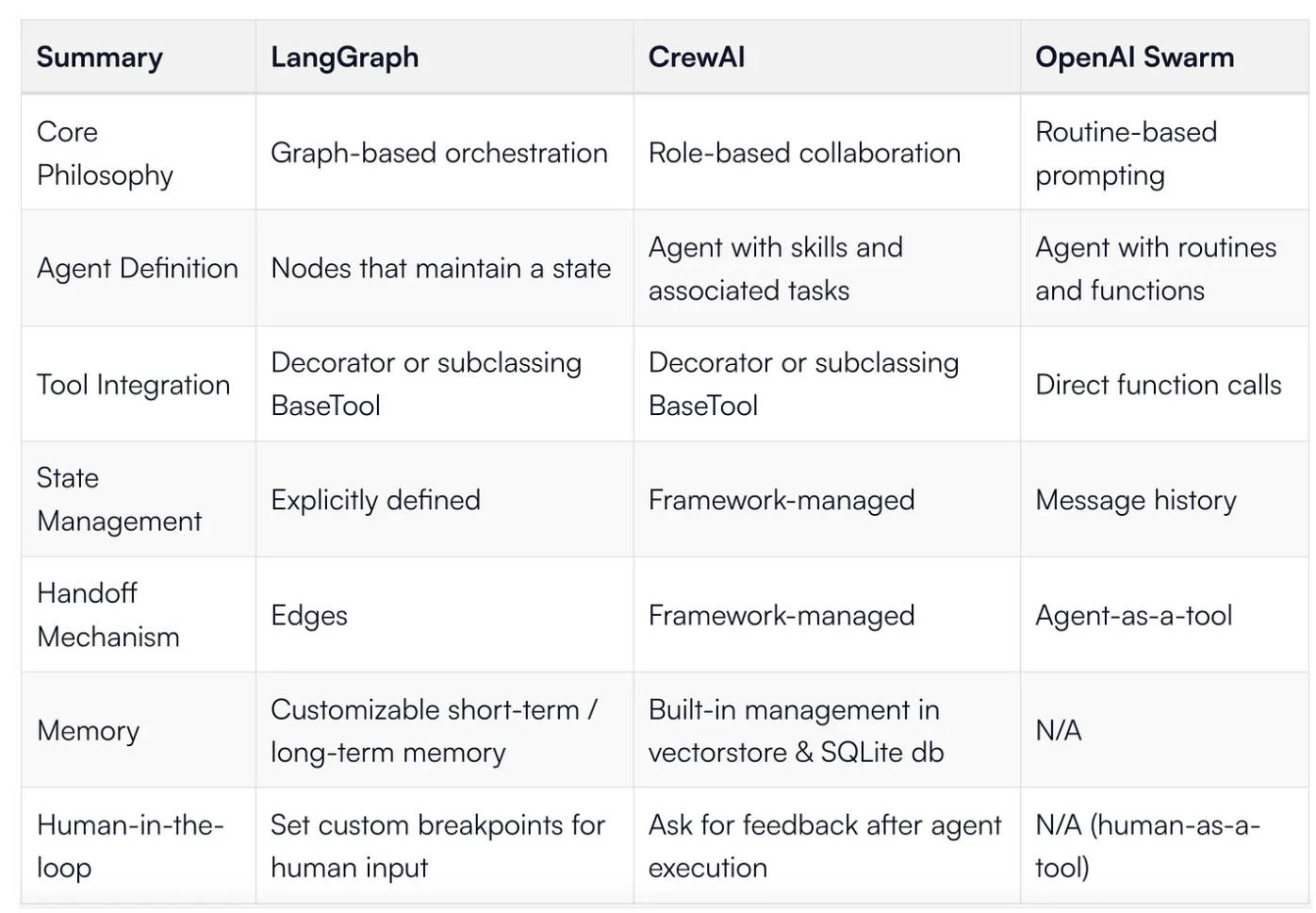
Summary of feature differences
To summarize our findings building the same application across the three frameworks.
We summarized our recommendation in the flowchart to help you navigate your decision on which framework to start with.

接下来是什么?
这个博客专注于构建代理的第一个版本。这些代理绝不是高效或可靠的。
下一篇博客将专注于改进和迭代这些代理(通常是人工智能系统生产的大部分工作)。
- 定义成功标准和指标
- 使用不同框架构建的代理的基准性能
- 深入了解质量和可靠性
- 对提示、工具、推理、架构进行有针对性的改进
我们将使用Relari正在开发的一些最新的代理评估、模拟和可观察性工具,深入研究如何将这些代理转化为生产就绪系统。
- 登录 发表评论
- 248 次浏览
最新内容
- 1 week 5 days ago
- 2 weeks 6 days ago
- 3 weeks 3 days ago
- 2 months 1 week ago
- 6 months ago
- 6 months ago
- 6 months ago
- 6 months ago
- 6 months ago
- 6 months ago