
category
为什么选择KServe?
KServe是Kubernetes上的标准模型推理平台,专为高度可扩展的用例而构建。
提供跨ML框架的高性能、标准化推理协议。
支持现代无服务器推理工作负载与自动缩放,包括缩放到零GPU。
使用ModelMesh提供高可扩展性、密度封装和智能路由
简单可插拔的生产服务,用于生产ML服务,包括预测、前/后处理、监控和解释。
高级部署,包括金丝雀的推出、实验、组合和transformers。
KServe Components
模特服务
通过常见的ML框架Scikit-Learn、XGBoost、Tensorflow、PyTorch以及可插入的自定义模型运行时,为CPU/GPU上的模型推理提供无服务器部署。
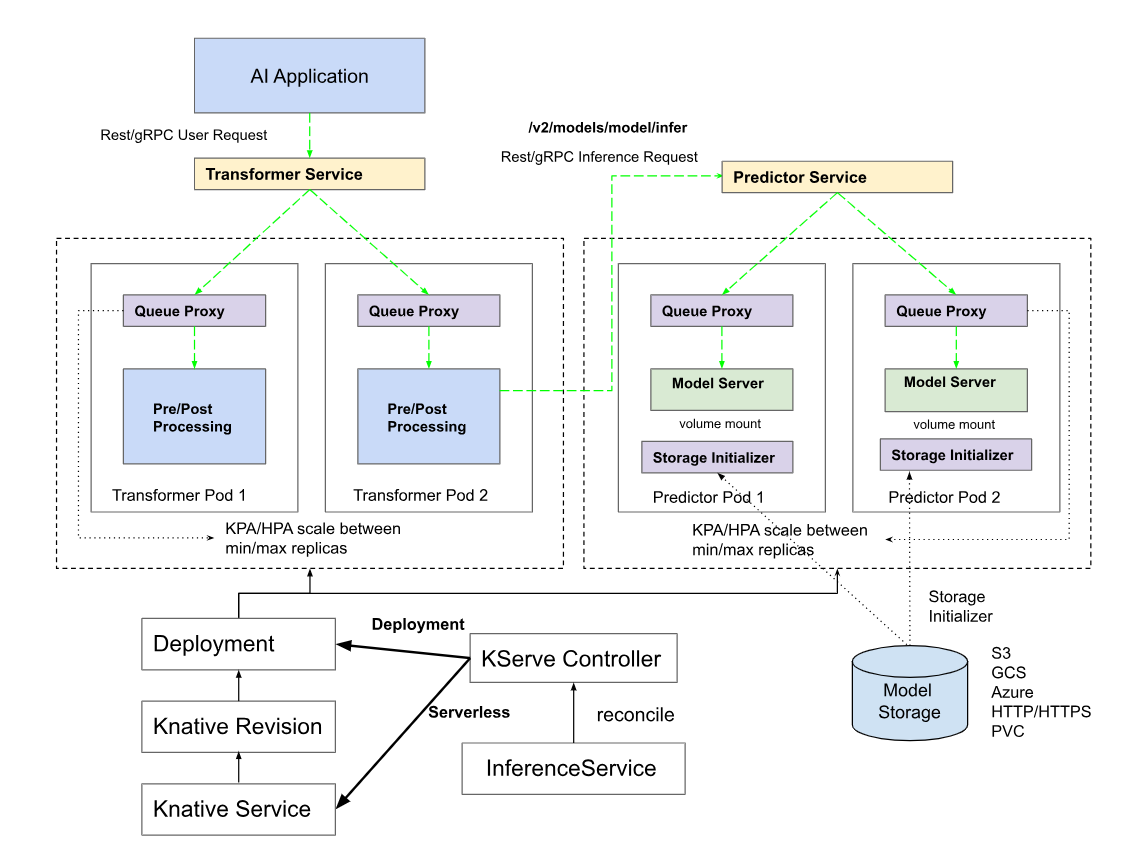
KServe提供了一个简单的Kubernetes CRD,可以将单个或多个经过训练的模型部署到模型服务运行时,如TFServing、TorchServe、Triton推理服务器。此外,ModelServer是在KServe中使用预测v1协议实现的Python模型服务运行时,MLServer使用REST和gRPC实现预测v2协议。这些模型服务运行时能够提供开箱即用的模型服务,但您也可以选择为更复杂的用例构建自己的模型服务器。KServe提供了基本的API基元,使您可以轻松地构建自定义模型服务运行时,您可以使用BentML等其他工具来构建您的自定义模型服务映像。
使用推理服务部署模型后,您将获得KServe提供的以下所有无服务器功能。
- 缩放到零和从零缩放
- 基于请求的CPU/GPU自动缩放
- 修订管理
- 优化的容器
- 批处理
- 请求/响应日志记录
- 流量管理
- AuthN/AuthZ的安全性
- 分布式跟踪
- 开箱即用的指标
- 入口/出口控制
下表列出了KServe支持的每个模型服务运行时。HTTP和gRPC列指示服务运行时支持的预测协议版本。KServe预测协议被记为“v1”或“v2”。一些服务运行时也支持它们自己的预测协议,这些协议用*表示。默认的服务运行时版本列定义了服务运行时的源和版本——MLServer、KServe或它自己的。这些版本也可以在运行时kustomization YAML中找到。所有为运行时服务的KServe本机模型都使用当前的KServe发布版本(v0.12)。支持的框架版本列列出了支持的模型的主要版本。这些也可以在相应的运行时YAML中supportedModelFormats字段下找到。对于使用KServe服务运行时的模型框架,可以在KServe/python中找到特定的默认版本。在给定的服务运行时目录中,pyproject.toml文件包含所使用的确切模型框架版本。例如,在kserve/python/lgbserver中,pyproject.toml文件将模型框架版本设置为3.3.2,lightgbm~=3.3.2。
MODELMESH
ModelMesh是为高规模、高密度和频繁变化的模型用例而设计的。ModelMesh智能地将人工智能模型加载到内存中或从内存中卸载人工智能模型,以在对用户的响应能力和计算足迹之间实现智能权衡。
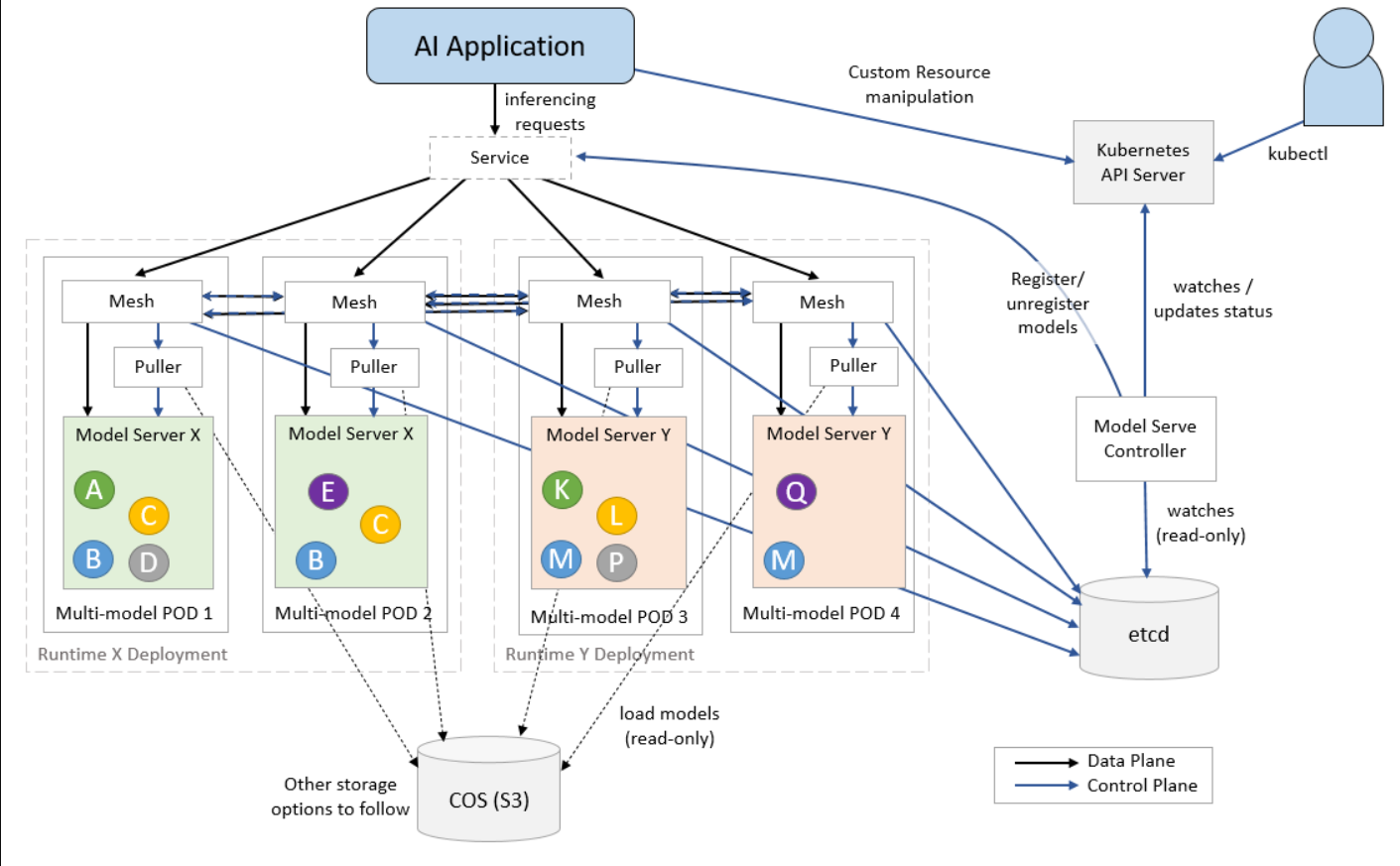
随着机器学习方法在组织中越来越广泛地采用,有一种趋势是部署大量模型。例如,新闻分类服务可以为每个新闻类别训练定制模型。组织希望训练大量模型的另一个重要原因是保护数据隐私,因为隔离每个用户的数据并单独训练模型更安全。虽然通过为每个用例构建模型可以获得更好的推理准确性和数据隐私,但在Kubernetes集群上部署数千到数十万个模型更具挑战性。此外,服务于神经网络模型的用例越来越多。为了实现合理的延迟,这些模型在GPU上得到更好的服务。然而,由于GPU是昂贵的资源,因此为许多基于GPU的模型提供服务是昂贵的。
KServe的原始设计为每个推理服务部署一个模型。但是,当处理大量模型时,它的“一个模型,一个服务器”范式给Kubernetes集群带来了挑战。为了扩大模型的数量,我们必须扩大推理服务的数量,这可以迅速挑战集群的极限。
多模式服务旨在解决KServe将遇到的三种限制:
- 计算资源限制
- 最大吊舱限制
- 最大IP地址限制。
计算资源限制¶
每个推理服务都有一个资源开销,因为每个pod中都注入了sidecar。这通常会为每个推理服务副本添加大约0.5个CPU和0.5G内存资源。例如,如果我们部署10个模型,每个模型有2个副本,那么资源开销是10*2*0.5=10个CPU和10*2*0.5=10 GB内存。每个模型的资源开销是1CPU和1GB内存。使用当前方法部署许多模型将很快耗尽集群的计算资源。使用多模型服务,这些模型可以加载到一个推理服务中,那么每个模型的平均开销是0.1CPU和0.1GB内存。对于基于GPU的模型,所需的GPU数量随着模型数量的增长而线性增长,这是不划算的。如果多个模型可以加载到一个启用GPU的模型服务器(如TritonServer)中,那么我们在集群中需要的GPU要少得多。
最大吊舱限制¶
Kubelet具有每个节点的最大pod数量,默认限制设置为110。根据Kubernetes的最佳实践,一个节点运行的pod不应超过100个。有了这个限制,一个具有默认pod限制的典型50节点集群最多可以运行1000个模型,假设每个推理服务平均有4个pod(两个转换器副本和两个预测副本)。
最大IP地址限制。¶
Kubernetes集群也有每个集群的IP地址限制。推理服务中的每个pod都需要一个独立的IP。例如,假设每个推理服务平均有4个pod(两个转换器副本和两个预测器副本),则具有4096个IP地址的集群最多可以部署1024个模型。
使用ModelMesh进行多模型服务的好处¶
使用ModelMesh的多模型服务解决了上述三个限制。它降低了每个模型的平均资源开销,因此模型部署变得更具成本效益。并且可以部署在集群中的模型数量将不再受到最大pod限制和最大IP地址限制的限制。
点击此处了解有关ModelMesh的更多信息。
模型可解释性
提供ML模型检查和解释,KServe集成了Alibi、AI Explainability 360和Captum,以帮助解释预测并衡量这些预测的可信度。
提供ML模型检查和解释,KServe集成了Alibi、AI Explainability 360和Captum,以帮助解释预测并衡量这些预测的可信度。
模型的可解释性回答了一个问题:“为什么我的模型会对给定的实例做出这样的预测”。KServe与Alibi Explainer集成,后者通过为给定实例生成许多外观相似的实例并发送到模型服务器以生成解释来实现黑匣子算法。
此外,KServe还集成了人工智能解释360(AIX360)工具包,这是LF人工智能基金会的孵化项目,是一个开源库,支持数据集和机器学习模型的可解释性和可解释性。AI可解释性360 Python包包括一套全面的算法,涵盖了不同的解释维度以及代理可解释性指标。除了原生算法外,AIX360还提供LIME和Shap的算法。
| Explainer | Examples |
|---|---|
| Deploy Alibi Image Explainer | Imagenet Explainer |
| Deploy Alibi Income Explainer | Income Explainer |
| Deploy Alibi Text Explainer | Alibi Text Explainer |
MODEL MONITORING
支持有效载荷日志记录、异常值、对抗性和漂移检测,KServe集成了Alibi检测、AI Fairness 360、对抗性鲁棒工具箱(ART),以帮助监控生产中的ML模型。
为了信任模型预测并可靠地对其采取行动,通过各种不同类型的检测器来监控传入请求的分布是至关重要的。KServe将Alibi Detect与以下组件集成在一起:
漂移检测器检查传入请求的分布何时偏离诸如训练数据的参考分布的参考分布。
异常值检测器标记不遵循训练分布的单个实例。
所使用的体系结构如下所示,并将KServe中可用的有效载荷日志记录与KNive中这些有效载荷的异步处理联系起来,以检测异常值。
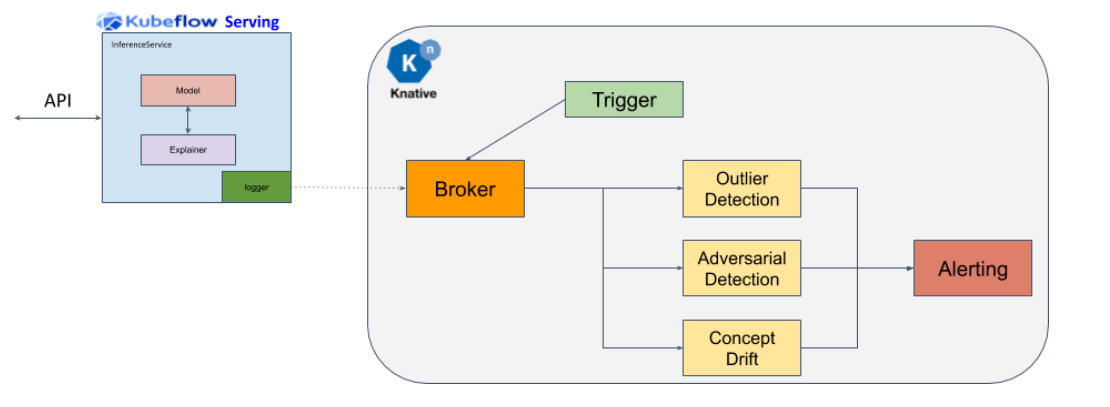
CIFAR10异常值检测器¶
CIFAR10异常值检测器。运行笔记本演示进行测试。
笔记本需要KNative Eventing>=0.18。
CIFAR10漂移探测器¶
CIFAR10漂移探测器。运行笔记本演示进行测试。
笔记本需要KNative Eventing>=0.18。
高级部署
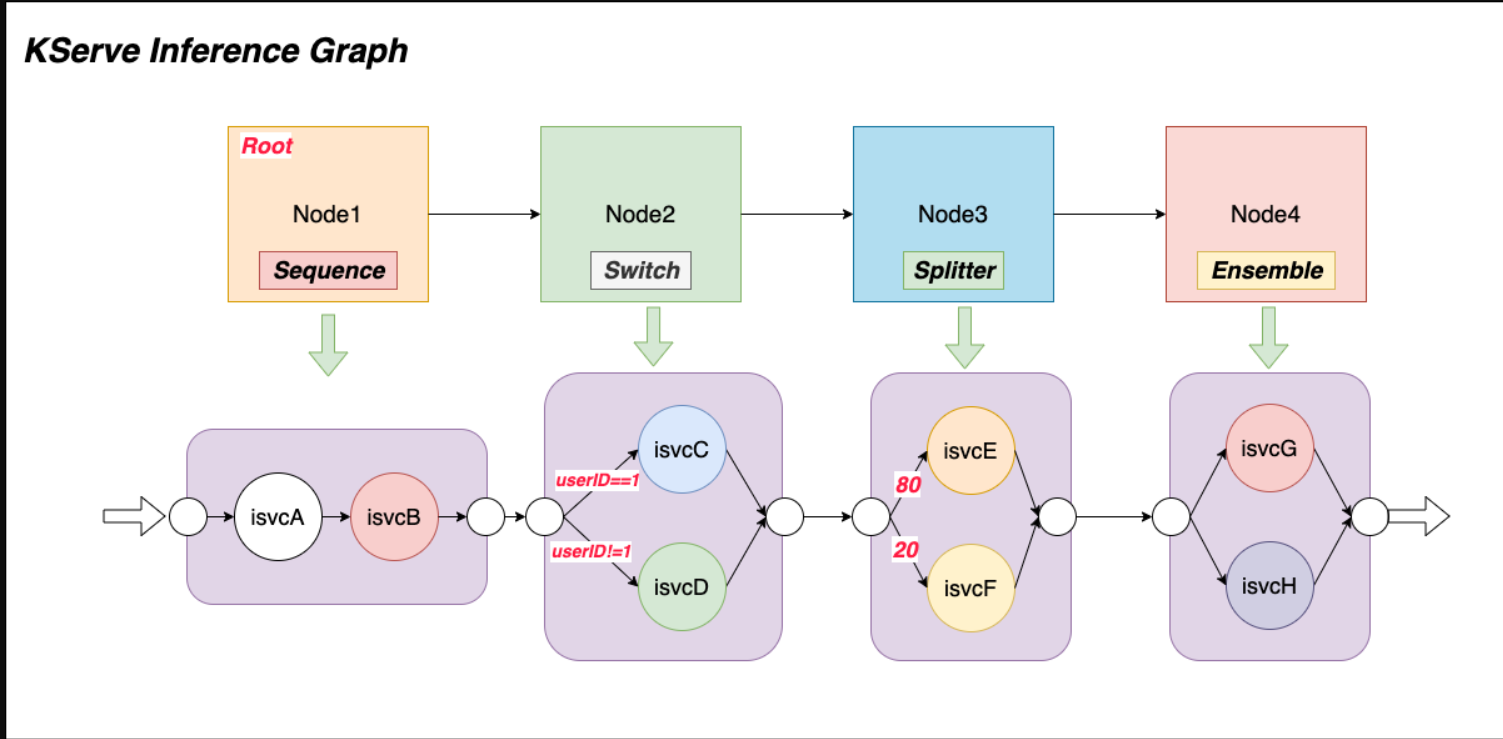
KServe推理图支持四种类型的路由节点:Sequence、Switch、Ensemble和Splitter。
动机¶
ML推理系统越来越大、越来越复杂,它们通常由许多模型组成来进行单个预测。一些常见的用例是图像分类和自然语言处理管道。例如,人脸识别流水线可能需要首先定位图像中的人脸,然后计算人脸的特征以匹配数据库中的记录。NLP管道需要首先运行文档分类,然后根据之前的分类结果在下游执行命名实体检测。
KServe在构建分布式推理图方面具有独特的优势:自动缩放图路由器、与单个推理服务的本地集成,以及用于链接模型的标准推理协议。KServe利用这些优势构建推理图,并使用户能够以声明性和可扩展的方式将复杂的ML推理管道部署到生产中。
概念¶

- 推理图:由路由节点列表组成,其中每个节点由一组路由步骤组成。每个步骤都可以路由到推理服务或图上定义的另一个节点,这使得推理图具有高度可组合性。图形路由器部署在HTTP端点后面,可以根据请求量进行动态缩放。推理图支持四种不同类型的路由节点:序列、交换机、集成和拆分器。
- 序列节点:允许用户使用推理服务或节点定义多个步骤作为序列中的路由目标。步骤按顺序执行,上一步骤的请求/响应可以作为基于配置的输入传递到下一步骤。
- 切换节点:使用户可以定义路由条件,并在匹配条件时选择要执行的步骤。一旦找到与条件匹配的第一个步骤,就会返回响应。如果没有匹配的条件,图形将返回原始请求。
- 集合节点:模型集合需要分别对每个模型进行评分,然后将结果组合成单个预测响应。然后可以使用不同的组合方法来生成最终结果。例如,多个分类树通常使用“多数投票”方法进行组合。多元回归树经常使用各种平均技术进行组合。
- 拆分器节点:允许用户使用加权分布将流量拆分到多个目标。
- 登录 发表评论
- 192 次浏览
Tags
最新内容
- 6 days 16 hours ago
- 2 weeks ago
- 2 weeks 4 days ago
- 2 months ago
- 6 months ago
- 6 months ago
- 6 months ago
- 6 months ago
- 6 months ago
- 6 months ago