
category
记忆:连贯、长寿命LLM智能体的关键
大型语言模型(LLM)以流畅的文本生成给我们留下了深刻的印象,但它们传统上作为无状态系统运行。一旦交互结束,模型就会忘记一切,除非再次明确提供。这种记忆的缺乏限制了人工智能智能体维持上下文、从经验中学习或长时间适应的能力。
如果我们想要真正连贯、长寿命的人工智能智能体——能够进行数周有意义的对话、记住偏好或不断学习新事实的智能体——我们必须赋予它们记忆的能力。内存已成为构建更自主和自适应的LLM智能体的关键组成部分。
为什么内存对基于LLM的智能体很重要
内存使AI智能体能够在固定的上下文窗口之外保留和调用信息。没有记忆,即使是最好的LLM也难以进行长对话或多会话一致性。
仅仅增加上下文长度是不够的:历史增长速度超过任何限制,模型会丢失隐藏在无关数据下的关键事实。智能智能体必须保留重要的细节,抽象或丢弃不相关的细节,就像人类一样。
记忆还可以让AI智能体学习和适应,回忆用户偏好,避免重复错误,并随着时间的推移进行推理。这对于创建感觉连续和连贯的人工智能系统至关重要。
最新技术:LLM智能体的内存架构
Mem0:会话智能体的动态记忆
Mem0为LLM添加了一个自我改进的外部存储器。它从正在进行的对话中提取关键事实,并将其存储在记忆库中。Mem0没有将整个对话传递给模型,而是选择重要信息并根据需要更新内存。
Mem0显示了强劲的结果:
- 与完整历史记录方法相比,延迟减少了91%。
- 使用的代币减少了90%。
- 在长上下文查询基准测试中,准确率提高了26%。
- 变体Mem0g构建了一个知识图,用于对实体、关系和时间进行结构化推理。它以稍高的复杂性为代价实现了多跳和时态查询。
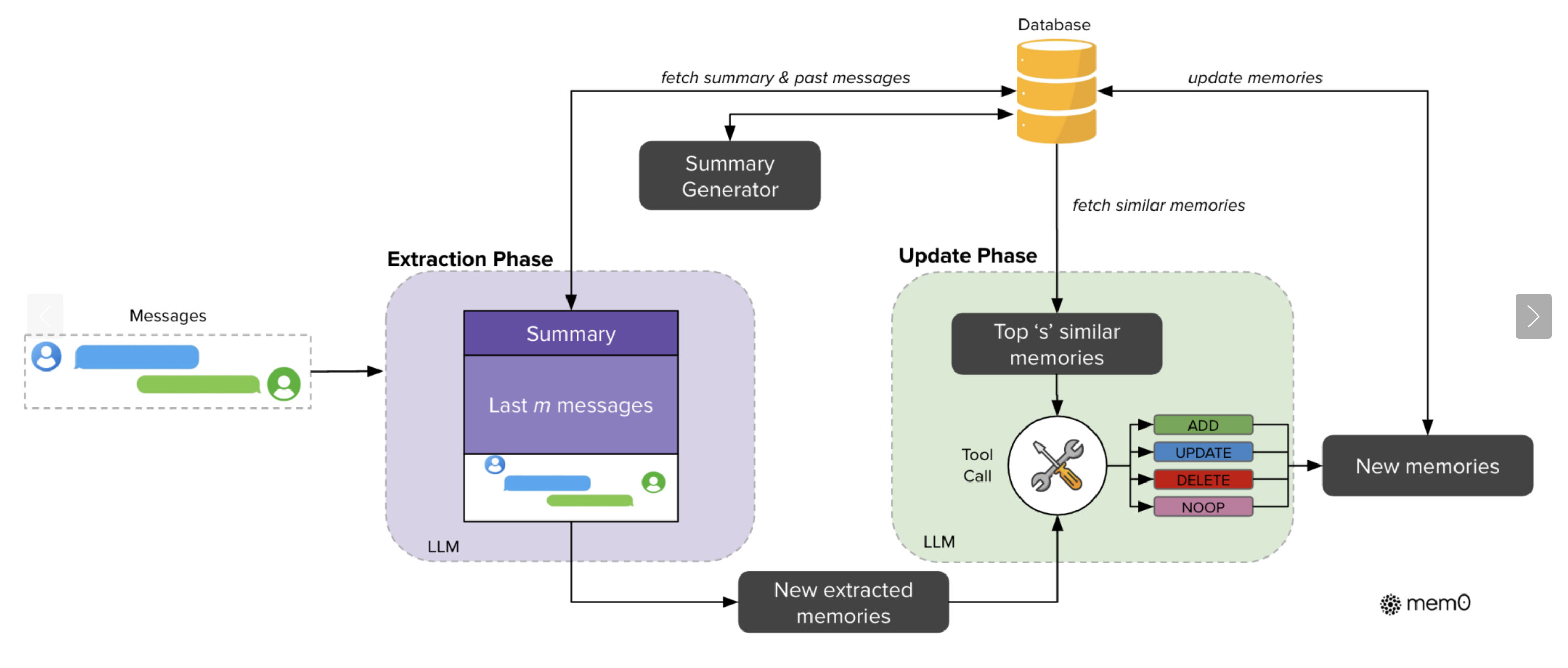
图改编自:“Mem0:LLM中高效长期记忆的显式存储模块”
Graphiti:动态知识图内存
Zep AI的Graphiti专注于企业和实时智能体用例。它从持续的交互和数据源中维护一个实时的、时间感知的知识图。功能包括:
- 事实的时间戳和版本控制。
- 混合搜索:嵌入+关键字+图遍历。
- 亚秒级检索延迟。
- LongMemEval基准测试的准确率提高了18.5%,响应延迟降低了90%。
Graphiti非常适合企业人工智能智能体,这些智能体必须跟踪会话中不断变化的事实(例如客户工单、系统更新)和原因。
M+:模型内部的潜在长期记忆
M+扩展了MemoryLLM框架。它将信息压缩为潜在向量,并训练一个联合训练的检索器在生成过程中查询它们。
主要成就:
- 从20k扩展到160k+令牌内存。
- 匹配或超过长上下文基线模型。
- 保持与标准LLM类似的GPU成本。
- 权衡:内存不是人类可读的(与Mem0/Graphiti不同),需要自定义重新训练。
认知记忆:受人类系统的启发
他们提出了LLM中的认知记忆,建模:
- 感官记忆:原始标记输入。
- 短期记忆:最近的对话背景。
- 长期记忆:外部数据库、知识图谱或微调更新。
这种分层设计提供了鲁棒性:
- 短期内存可防止溢出。
- 长期记忆可以实现持久的个性化。
- 组合系统提供了更好的泛化和上下文跟踪。
情景记忆:构建经验
作者认为,情景记忆是缺失的成分:
- 智能体将交互划分为事件(特定任务、会话或体验)。
- 存储丰富的上下文快照:内容、时间、地点和结果。
- 使智能体能够明确地回忆过去的事件并跨时间推理。
- 支持单次学习:从罕见或一次性事件中学习。
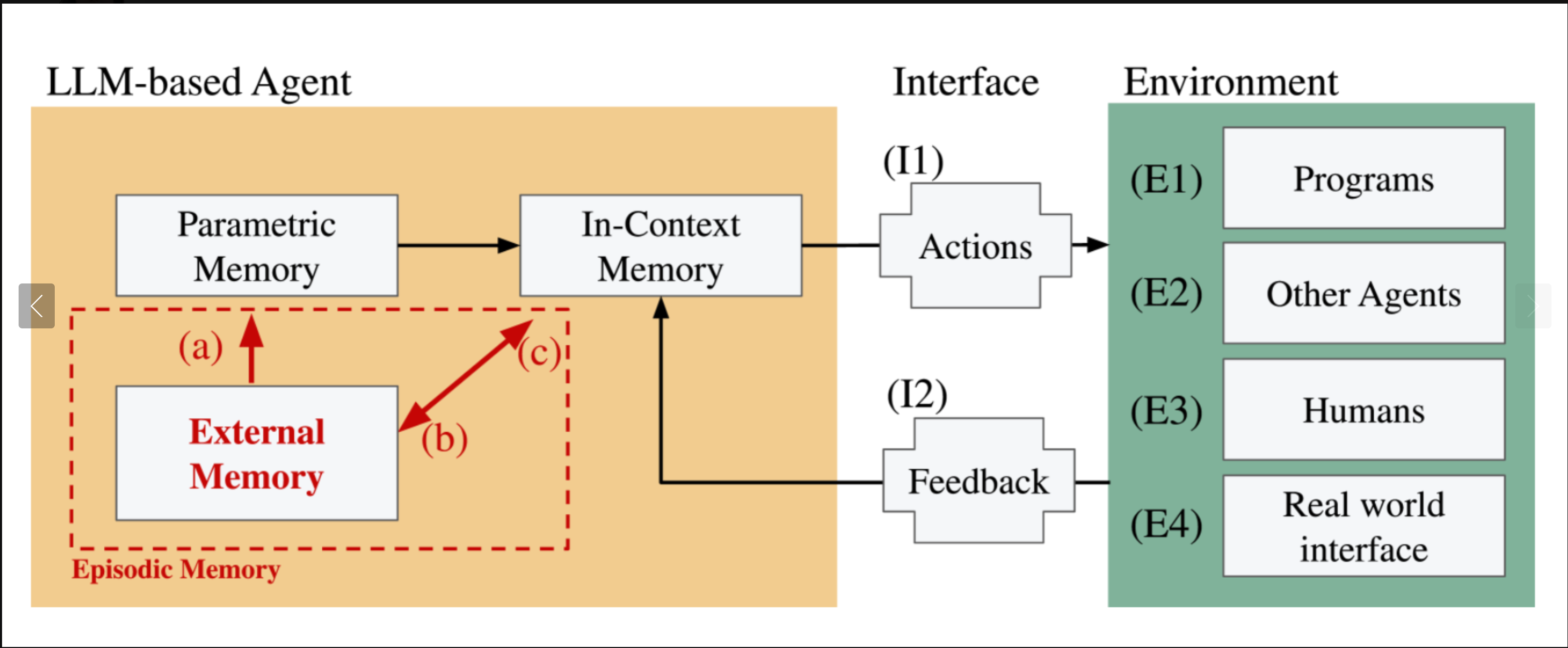
图改编自:“情景记忆是长期LLM智能体缺失的部分”
LongMemEval:内存系统基准测试
LongMemEval是衡量五种技能的长期记忆的基准:
- 信息提取。
- 多会话推理。
- 时间推理。
- 知识更新。
- 弃权(在适当的时候说“我不知道”)。
在没有专门记忆的长期测试中,大多数模型的准确率下降了约30%。Zep的Graphiti和Mem0通过将外部存储器与结构化存储相结合显示出了强大的效果。
Takeaways for AI Researchers and Developers
| System | Memory Type | Strengths | Trade-offs |
|---|---|---|---|
| Mem0 | External vector memory | High speed, low cost, conversational personalization | Needs good fact extraction |
| Mem0g | Knowledge graph | Structured, multi-hop reasoning | Modestly higher latency |
| Graphiti | Temporal knowledge graph | Dynamic enterprise data, version tracking | Graph DB operational overhead |
| M+ | Latent in-model memory | Huge context length extension, seamless recall | Not human readable, custom retraining |
| Cognitive Memory | Layered design | Robustness across time-scales | System integration complexity |
| Episodic Memory | Structured experience logs | Lifelong learning, explicit recall | Adds storage and retrieval steps |
实用技巧
1.组合存储层没有一种单一的存储机制可以满足所有需求。
使用分层内存设计您的代理:
短期记忆(上下文窗口、滚动对话缓冲区)用于即时连贯。
用于中期语义回忆的向量记忆(例如,基于嵌入的检索)。
用于长期、关系知识和时间推理的结构化记忆(例如,通过Graphiti或Mem0g的知识图)。这种“混合内存堆栈”允许智能体平衡快速访问、可扩展性和推理能力。
2.定期总结或整合知识。长时间运行的Agent会积累大量内存。
引入反思或巩固步骤:
将长对话或复杂的会话总结成简洁的记忆条目(就像Mem0一样)。
合并冗余信息并删除陈旧或过时的事实(通过Graphiti进行时间跟踪会有所帮助)。这最大限度地减少了内存膨胀,防止了信息漂移。
3.使用基准测试来指导开发使用LongMemEval等基准测试来评估您的内存系统,
LongMemEval测试五个关键领域:
- 信息提取
- 多会话推理
- 时间推理
- 知识更新
- 弃权(知道智能体何时应该说“我不知道”)定期的基准测试有助于捕捉边缘案例,验证改进,并系统地减少遗忘。
4.内置的反思机制应设计为定期“暂停和反思”:
在每个会话之后,让智能体总结发生了什么,并将其存储为一个情节(情节记忆设计)。
反射可以防止上下文窗口过度填充,并创建与特定任务或对话相关的结构化记忆。
这一策略在研究中表现出了显著的性能提升,并反映了人类在事件发生后如何巩固记忆。
这些实践共同构成了创建记忆增强人工智能智能体的基础,这些智能体可以在不同的任务和时间尺度上可靠、连续地运行。
结论
内存不再是下一代人工智能智能体的可选配置——它是自主性的关键。从Mem0和Graphiti,到M+、认知框架和情景记忆,该领域已经超越了聊天机器人,转向了能够持久、适应和学习的智能体。
作为人工智能科学家和开发人员,我们现在有了开始构建智能体的工具,这些智能体不仅会做出反应,还会记住。
人工智能的未来不是无状态的。这是记忆增强的人工智能。
参考文献
- Mem0: An Explicit Memory Module for Efficient Long-Term Memory in LLMs
- Mem.ai Research
- Graphiti: Knowledge Graph Memory Layer for LLM Agents
- Graphiti (Zep AI) on GitHub
- M+: Latent Long-Term Memory for Language Models
- Episodic Memory is the Missing Piece for Long-Term LLM Agents
- Exploring Memory-Augmented Language Models: Special Token and Attention-based Approaches
- LongMemEval: Evaluating Long-Term Memory Abilities of LLM Agents
- 登录 发表评论
- 199 次浏览
最新内容
- 6 days 23 hours ago
- 1 week 3 days ago
- 1 month 4 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago