
category
倒数排名融合(RRF)是一种从多个先前排名的结果中评估搜索分数以生成统一结果集的算法。在Azure AI搜索中,只要有两个或多个查询并行执行,就会使用RRF。每个查询都会产生一个排名结果集,RRF用于将排名合并并均匀化为单个结果集,并在查询响应中返回。总是使用RRF的场景的示例包括同时执行的混合搜索和多个矢量查询。
RRF基于倒数排名的概念,倒数排名是搜索结果列表中第一个相关文档的排名的倒数。该技术的目标是考虑项目在原始排名中的位置,并赋予多个列表中排名较高的项目更高的重要性。这有助于提高最终排名的整体质量和可靠性,使其更适用于融合多个有序搜索结果的任务。
RRF排名的工作原理
RRF的工作原理是从多种方法中获取搜索结果,为结果中的每个文档分配一个倒数排名分数,然后将分数组合起来创建一个新的排名。其概念是,在多种搜索方法中出现在顶部位置的文档可能更相关,并且在组合结果中排名更高。
以下是RRF过程的简单解释:
- 从并行执行的多个查询中获得排名搜索结果。
- 为每个排名列表中的结果分配倒数排名分数。RRF为每个结果集中的每个匹配生成一个新的@search.score。对于搜索结果中的每个文档,引擎会根据其在列表中的位置分配一个倒数排名分数。得分计算为1/(rank+k),其中rank是文档在列表中的位置,k是一个常数,实验观察到,如果将其设置为60这样的小值,则表现最佳。注意,该k值是RRF算法中的常数,并且与控制最近邻居数量的k完全分离。
- 合并分数。对于每个文档,引擎将从每个搜索系统获得的倒数分数相加,生成每个文档的组合分数。
- 引擎根据综合得分对文档进行排序。由此产生的列表是融合的排名。
只有在索引中标记为可搜索的字段或查询中的searchFields才会用于评分。只有标记为可检索的字段或在查询中的select中指定的字段才会在搜索结果中返回,以及它们的搜索得分。
并行查询执行
只要有多个查询执行,就会使用RRF。以下示例说明了发生并行查询执行的查询模式:
- 一个全文查询加上一个矢量查询(简单的混合场景)等于两次查询执行。
- 一个全文查询,加上一个针对两个矢量字段的矢量查询,等于三次查询执行。
- 一个全文查询,加上针对五个矢量字段的两个矢量查询,等于11次查询执行
混合搜索结果中的分数
无论何时对结果进行排序,@search.score属性都包含用于对结果排序的值。分数是由每种方法不同的排名算法生成的。每种算法都有自己的范围和大小。
下表确定了每个匹配返回的评分属性、算法以及每个相关性排名算法的评分范围。
| Search method | Parameter | Scoring algorithm | Range |
|---|---|---|---|
| full-text search | @search.score |
BM25 algorithm | No upper limit. |
| vector search | @search.score |
HNSW algorithm, using the similarity metric specified in the HNSW configuration. | 0.333 - 1.00 (Cosine), 0 to 1 for Euclidean and DotProduct. |
| hybrid search | @search.score |
RRF algorithm | Upper limit is bounded by the number of queries being fused, with each query contributing a maximum of approximately 1 to the RRF score. For example, merging three queries would produce higher RRF scores than if only two search results are merged. |
| semantic ranking | @search.rerankerScore |
Semantic ranking | 0.00 - 4.00 |
语义排名不参与RRF。其得分(@search.rerankerScore)总是在查询响应中单独报告。语义排名可以重新排列全文和混合搜索结果,假设这些结果包括具有语义丰富内容的字段。
加权得分
从2024-05-01预览开始,您可以对矢量查询进行加权,以增加或降低它们在混合查询中的重要性。
回想一下,当为某个文档计算RRF时,搜索引擎会查看该文档显示的每个结果集的排名。假设一个文档显示在三个独立的搜索结果中,其中结果来自两个矢量查询和一个文本BM25排序查询。文档的位置因每个结果而异。
| Match found | Position in results | @search.score | weight multiplier | @search.score (weighted) |
|---|---|---|---|---|
| vector results one | position 1 | 0.8383955 | 0.5 | 0.41919775 |
| vector results two | position 5 | 0.81514114 | 2.0 | 1.63028228 |
| BM25 results | position 10 | 0.8577363 | NA | 0.8577363 |
文档在每个结果集中的位置对应于一个初始分数,将这些分数相加以创建该文档的最终RRF分数。
如果添加矢量权重,则初始分数将被细分为增加或减少分数的权重乘数。默认值为1.0,这意味着没有权重,初始分数在RRF评分中按原样使用。但是,如果添加0.5的权重,分数会降低,并且该结果在组合排名中变得不那么重要。相反,如果添加2.0的权重,则该分数将成为RRF总分数中的一个较大因素。
在本例中,@search.score(加权)值被传递给RRF排名模型。
混合查询响应中排名的结果数
默认情况下,如果不使用分页,搜索引擎会为全文搜索返回排名前50位的匹配项,为矢量搜索返回最相似的k个匹配项。在混合查询中,top决定响应中的结果数。根据默认值,将返回统一结果集中排名前50位的匹配。
通常,搜索引擎会发现比top和k更多的结果。要返回更多的结果,请使用分页参数top、skip和next。分页是确定每个逻辑页上的结果数并浏览整个负载的方式。您可以将maxTextRecallSize设置为更大的值(默认值为1000),以从混合查询的文本端返回更多结果。
默认情况下,全文搜索的最大匹配限制为1000(请参阅API响应限制)。一旦找到1000个匹配项,搜索引擎就不再寻找更多匹配项。
有关详细信息,请参阅如何使用搜索结果。
搜索评分工作流程图
下图展示了一个混合查询,该查询调用关键字和向量搜索,并通过评分配置文件和语义排名进行提升。
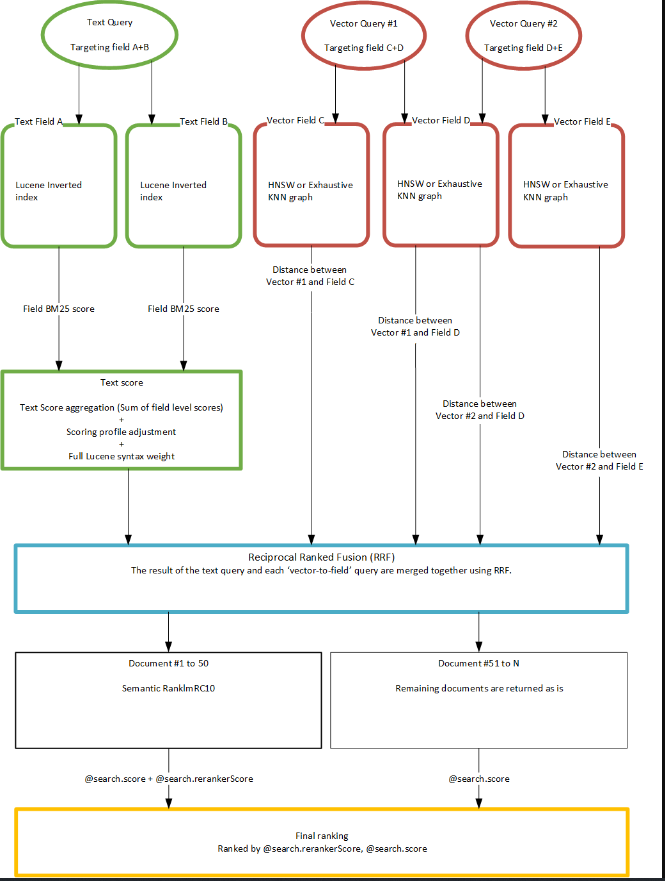
预过滤器示意图。
生成上一个工作流的查询可能如下所示:
HTTP
POST https://{{search-service-name}}.search.windows.net/indexes/{{index-name}}/docs/search?api-version=2023-11-01
Content-Type: application/json
api-key: {{admin-api-key}}
{
"queryType":"semantic",
"search":"hello world",
"searchFields":"field_a, field_b",
"vectorQueries": [
{
"kind":"vector",
"vector": [1.0, 2.0, 3.0],
"fields": "field_c, field_d"
},
{
"kind":"vector",
"vector": [4.0, 5.0, 6.0],
"fields": "field_d, field_e"
}
],
"scoringProfile":"my_scoring_profile"
}
另请参阅
- 登录 发表评论
- 258 次浏览
最新内容
- 1 week ago
- 1 week 4 days ago
- 1 month 4 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago