

数据已成为数字时代企业最有价值的资产之一。随着生成和存储的数据量不断增加,组织制定明确的管理这些信息的计划至关重要。这就是数据管理路线图发挥作用的地方。数据管理路线图是一个战略计划,概述了组织将如何在指定的时间段内收集、存储、使用和保护其数据。本指南旨在帮助程序员驾驭复杂的数据管理环境,并制定路线图,帮助他们实现数据管理目标。
什么是数据管理?在构建数据平台时应该牢记什么?
数据平台的主要块包括数据接收、数据转换和数据访问。每个区块都有很多挑战和需要学习的技术。在构建数据平台时,您需要加入不仅包括开发人员,还包括开发人员和财务人员的任务。你需要公司的所有部门都参与进来,因为平台会影响公司的各个层面。
所以,让我们试着把不同的层拆开,试着看看每一层的不同方面,以及需要做什么技术和任务。
数据摄入
确定需要摄入数据湖的数据来源很重要。
内部数据
第一批数据通常是公司内部不同流程生成的数据。
标准的公司数据源是一种内部微服务。由于每个微观服务都有自己的数据(使用12因素方法),并且我们通常需要跨微观服务的报告,因此我们需要将所有数据放在一个地方进行报告分析。
每个微服务的数据可以是一个数据库(多种类型:结构化、非结构化)。数据也可以来自服务中的消息队列。所有这些数据都需要同步到你的数据湖(可能使用像debezium这样的CDC工具)。
外部数据
公司通常不仅需要来自内部来源的数据,还需要来自公司使用的外部服务的数据。这可以是crm、外部应用程序等等。
处理摄入

当然,我们可以创建自己的数据管道来获取所有这些数据,但今天有很多工具可以为我们做到这一点。
其中的一小部分是:upsolver、keboola、fiftran、stitch、rivery和其他。一些开放的来源是空气细胞、海底生物和其他。
真相的来源
今天,除了数据湖,我们还有一个数据仓库(BigQuery、Databricks、Snowflake…)。在我看来,数据仓库不是数据湖,您应该将所有数据保存到数据湖(不可变文件)中作为真理的来源,并将数据仓库用于所有其他层。因此,请确保您的接收工具知道如何保存到s3以及同步到您的数据仓库。
文件中的真实性来源背后的原因是数据仓库本质上是可变的存储。这导致了数据发生变化的问题领域,我们无法恢复到原始数据。
数据湖问题
在构建数据湖时,您需要考虑一些问题:
桶与文件夹
- 桶和对象是主要资源
- AmazonS3有一个扁平的结构,而不是像您在文件系统中看到的那样的层次结构
- 您的帐户中最多有100个存储桶
- 在分区内所有AWS区域的所有AWS帐户中,每个bucket名称必须是唯一的
- Buckets-权限、生命周期…
数据存储结构注意事项
- 安全性(每个铲斗)
- 数据传输速率
- 分区
- 制作数据的多个副本(非结构化->暂存->数据库)
- 保留策略(法规遵从性、成本)
- 可读文件格式
- 合并小文件
- 数据治理和访问控制
数据建模
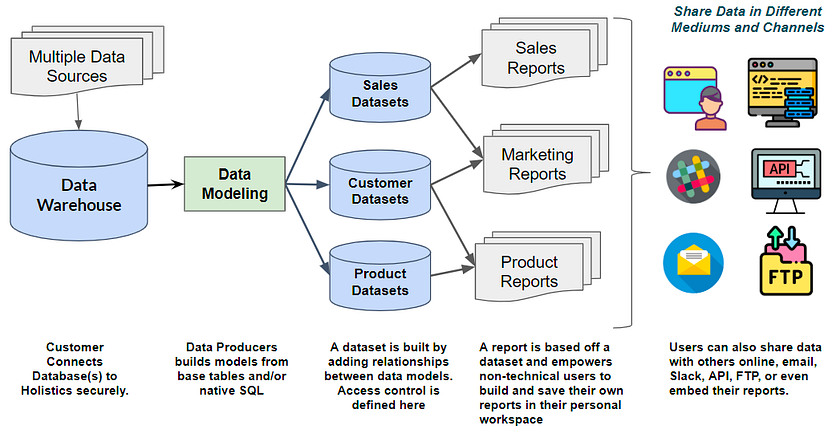
一旦您的数据进入数据仓库,您就需要设置青铜、白银和黄金层。需要通过为表和列创建标准命名约定来管理数据。列可能需要转换为正确的格式。
数据建模的最佳工具是dbt。要为您的数据设置dbt项目,请参阅dbt-项目结构、dbt-数据库模式。
数据建模模式
我们不会讨论所有不同的建模模式,只会提到一些,这样您就可以开始阅读并深入了解它们。
星形模式

来自维基百科:
星型模式是最简单的数据集市模式,也是最广泛用于开发数据仓库和维度数据集市的方法。星形模式由一个或多个引用任意数量维度表的事实表组成。星形模式是雪花模式的一个重要特例,对于处理更简单的查询更有效。
缓慢变化的维度
缓慢变化维度(SCD)是一种在数据仓库中存储和管理当前和历史数据的维度。它被认为是跟踪维度记录历史的最关键的ETL任务之一。
SCD有三种类型,您应该选择最适合您需求的一种。
类型1 SCD-覆盖

在类型1 SCD中,新数据覆盖现有数据。因此,现有数据丢失,因为它没有存储在其他任何地方。这是您创建的标注的默认类型。创建类型1 SCD不需要指定任何附加信息。
类型2 SCD-创建另一个维度记录
类型2 SCD保留值的完整历史记录。当选定属性的值更改时,当前记录将关闭。将使用更改后的数据值创建一个新记录,该新记录将成为当前记录。每个记录都包含有效时间和过期时间,以标识记录处于活动状态的时间段。
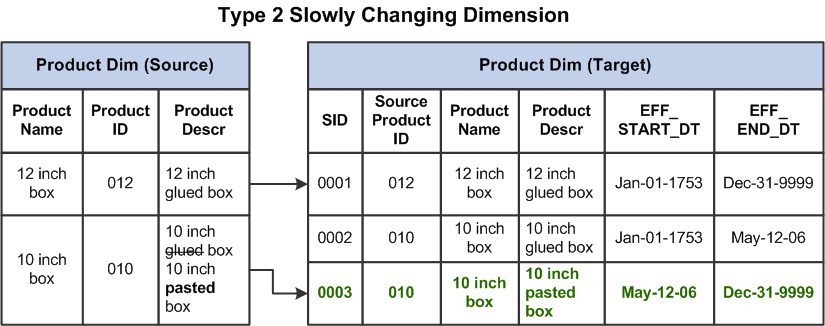
类型3 SCD-创建当前值字段
类型3 SCD为某些选定级别属性存储两个版本的值。每条记录都存储选定属性的上一个值和当前值。当任何选定属性的值发生更改时,当前值将存储为旧值,新值将变为当前值。
数据质量
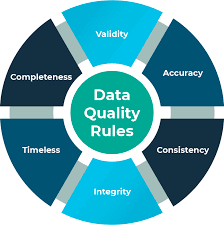
将数据带到仓库后,您需要验证数据本身。数据的验证包括确保您的数据按时到达,完整准确,并与所有其他数据输入一致。
有多种工具可以帮助您提高数据质量。
你可以从aws-Deequ开始,使用 great expectations,甚至使用机器学习来检查与Monte Carlo等工具的差异。
数据分析

一旦您拥有了所有数据,并且验证了质量,您现在需要一个工具来帮助您创建仪表板和数据分析。有多家供应商将为您提供帮助。
数据治理
一旦你开始,需要解决的一个问题是谁能看到什么数据。你需要将敏感数据限制在需要访问的人身上的工具。有些数据仓库支持acl功能(如雪花和bigquery),有些则不支持。
数据目录
数据目录是一组元数据,与数据管理和搜索工具相结合,帮助分析师和其他数据用户找到他们需要的数据,作为可用数据的清单,并提供信息来评估数据是否适合预期用途。
数据目录非常重要,它们所提供的特征集差异很大。考虑到您有多个数据源和管道,所有这些都应该进入目录。
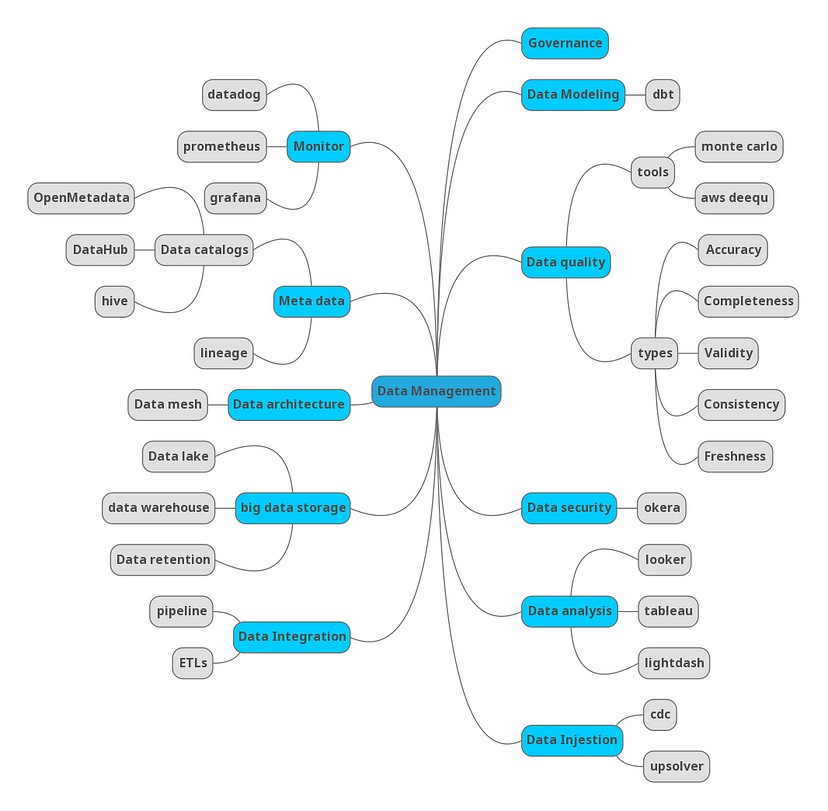
总结
以下是作为数据平台之旅的一部分所需技术的思维导图。
参考文献
演示文稿的幻灯片可以在数据管理演示文稿中找到。
最新内容
- 5 days 14 hours ago
- 1 week 6 days ago
- 2 weeks 3 days ago
- 2 months ago
- 5 months 4 weeks ago
- 5 months 4 weeks ago
- 5 months 4 weeks ago
- 5 months 4 weeks ago
- 5 months 4 weeks ago
- 5 months 4 weeks ago