
在Data Minded,我们观察到近年来dbt在我们的客户中越来越受欢迎。虽然它主要用于数据仓库(DWH)之上的数据转换,但我们也看到了将dbt与Duckdb一起使用作为Spark在数据湖之上进行数据转换的替代方案的潜力。
为什么dbt在数据管道方面胜过Spark?
十多年来,Apache Spark一直是执行数据转换的首选。然而,随着云数据仓库在过去五年中越来越受欢迎,dbt迅速获得了吸引力。事实上,Data Minded的首席执行官Kris在两年多前就写过一篇关于dbt和Spark的博客。它的标题是“为什么dbt有一天会比Spark更大”。在我看来,dbt相对于Spark的主要优势在于:
更广泛的目标受众
为了使用dbt,您主要需要了解SQL。由于SQL已经存在了40多年,许多人以前都使用过SQL,因此可以理解/编写/维护dbt代码。此外,您不仅限于数据工程师(Spark通常是这样),而且数据科学家、数据分析师和BI开发人员在维护dbt项目时也会感到舒适。
简单的执行
虽然我喜欢Spark编排我的数据转换,但我必须承认,它可能是一个复杂的野兽,有很多配置选项和陷阱。在我的团队中加入新的数据工程师时,我一次又一次地注意到了这一点。它们从一个正在工作的管道开始,对连接的顺序进行一个小的更改或更改配置设置(例如spark.sql.shuffle.dartitions、spark.sql.autoBroadcastJoinThreshold),然后管道突然失败。大多数时候,这是因为他们还不了解Spark是如何分配计算的。
Dbt极大地降低了数据工程师的复杂性,因为它将计算负担转移到了DWH(例如Snowflake、Redshift)。这意味着,大多数用户不需要了解DWH中查询的低级别执行,除非他们想优化特定查询的性能。将所有计算推送到DWH的一个缺点是,云数据仓库处理数据的费用通常比其他执行引擎更高。
大多数公司没有大数据
Spark的伟大之处在于它使您能够处理数TB的数据。它通过将计算分布在多个节点上来实现这一点,但在使用中型数据集(10–100 Gb)时,这种协调/通信方面可能会带来巨大的开销。在过去5年的数据工程师工作中,我注意到我90%的数据管道只处理中型数据集。
此外,云计算的兴起使具有256 Gb RAM的虚拟机变得更加容易获得,这就引出了一个问题:
如果我们的数据集只能放在一台机器上,我们是否需要像Spark这样的复杂分布式系统来处理我们的数据处理?
在过去的几年里,出现了许多试图填补这一空白的新技术(例如 polars, pyarrow ecosystem生态系统等)。它们通过在单个节点上运行来简化执行,但仍然需要编写Python代码。这限制了可以维护它的人数,因为我们都知道数据工程师是一种稀缺资源。所以我想知道,我们能做得更好吗?
Dbt和Duckdb前往救援
起初,我对将dbt用于数据管道持保留态度,因为它需要将我的所有数据存储在DWH中。虽然这对结构化数据来说不是什么大问题,但它不太适合半结构化数据。在过去的一年里,DuckDB,一个正在处理的OLAP数据库,得到了相当多的关注。它可以被视为相当于云数据仓库的单个节点。
当我发现由Josh Wills正在开发的dbt duckdb适配器时,我的兴奋之情与日俱增,我终于明白了模糊是怎么回事。将duckdb与dbt相结合可带来以下3个好处:
无需依赖DWH进行所有处理
云数据仓库令人印象深刻,但如果您想将其用于所有数据转换,也可能会变得非常昂贵。Duckdb在没有外部依赖的情况下独立运行,因此您可以轻松地将其嵌入任何Python或Java程序中。这使得它在许多情况下都是理想的候选者,从本地测试到处理管道中的dbt查询。
与外部存储无缝集成
Duckdb支持将数据写入外部系统,并以自己的数据库格式存储数据。它本身也支持常见的文件格式(例如CSV、Parquet)。
Duckdb的外部存储功能使得使用dbt和Duckdb将Spark中编写的数据管道无缝迁移到数据管道成为可能。这意味着您可以重写处理,同时保持作业的输入和输出相同(例如blob存储中的镶木地板文件)。
无需更改您的数据平台
在我之前的许多项目中,我遇到了一个具有类似构建块的数据平台,用于实现数据管道:
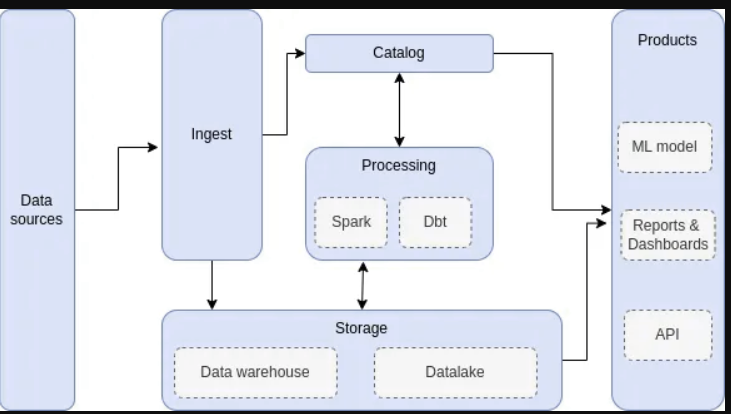
使用商品硬件获取和转换数据,然后将结果存储在数据湖中。如果有特定需要将数据保存在DWH中,您可以将结果推送到DWH,而不是数据湖(例如,允许在Tableau或PowerBi中查询…)。
有了dbt和Duckdb,您现在可以在以下场景中使用Spark作为处理引擎:
- 您处理中小型数据集:十分之一到百分之一GB的数据。
- 您的转换相对简单(例如,清除输入数据或重命名列等)。
带Duckdb的Dbt比Spark快
我想研究的最后一个方面是,与Spark相比,将DBT与Duckdb一起用于在中型数据集上执行数据转换是否更便宜。为了比较两者,我使用了TPC-DS基准测试,这是比较数据库性能的行业标准。
测试设置
- 为了生成Spark的数据和运行性能基准测试,我使用了我在讨论Spark性能改进的博客文章中详细描述的方法。TL;DR我使用Databricks工具包及其测试框架,并使用Data Minded的产品Conveyor在Kubernetes上运行Spark 3.2.1。然而,使用另一种方法在Kubernetes上运行Spark也可以获得相同的结果。
- 我想比较中型数据集的性能,所以我使用了100的比例因子来生成TPC-DS输入数据。这导致大约100Gb作为输入数据。
- 为了运行dbt基准测试,我使用了dbt1.4.0和Duckdb0.7.1基准测试。我需要重写Duckdb提供的TPC-DS查询,以便使它们与dbt一起工作,并使用S3上的parquet文件作为输入数据。由此产生的查询可以在这个git repo中找到。
- 我在所有的基准测试中都使用了来自AWS的相同m6.2xlarge实例。这些实例具有8个vcpu和32 Gb的RAM。此外,我连接了100Gb的磁盘存储,Duckdb用它来写内部数据库文件,Spark用它来存储shuffle数据。
后果
在结果中,我比较了Dbt+Duckdb与3种不同Spark设置的性能:
- Spark local:此设置在单个节点上运行Spark,因此没有单独的执行器。
- 带有1个或2个执行器的Spark:在这里,我们运行一个Spark驱动程序进程和1个或两个执行器来处理实际数据。
我只显示了TPC-DS基准测试中少数查询的查询持续时间(*)。我选择了查询40、70、81、81和64,因为它们有非常不同的查询模式;关于这方面的更多细节可以在TPC-DS的制作中找到。
| Setup | queryName | medianRuntime (s) | minRuntime (s) | maxRuntime (s) | |---------------|-----------|-------------------|----------------|----------------| | dbt-duckdb | q40 | 14 | 9 | 18 | | spark-local | q40 | 48 | 45 | 58 | | spark-1exec | q40 | 41,5 | 36 | 55 | | spark-2exec | q40 | 29 | 28 | 41 | |---------------|-----------|-------------------|----------------|----------------| | dbt-duckdb | q70 | 21 | 21 | 28 | | spark-local | q70 | 24 | 22 | 35 | | spark-1exec | q70 | 24 | 23 | 37 | | spark-2exec | q70 | 27 | 25 | 34 | |---------------|-----------|-------------------|----------------|----------------| | dbt-duckdb | q81 | 8 | 8 | 8 | | spark-local | q81 | 13 | 12 | 24 | | spark-1exec | q81 | 14 | 13 | 23 | | spark-2exec | q81 | 9 | 5 | 9 | |---------------|-----------|-------------------|----------------|----------------| | dbt-duckdb | q82 | 14 | 14 | 17 | | spark-local | q82 | 48.5 | 47 | 57 | | spark-1exec | q82 | 38 | 37 | 47 | | spark-2exec | q82 | 21 | 21 | 32 | |---------------|-----------|-------------------|----------------|----------------| | dbt-duckdb | q64 | / | / | / | | spark-local | q64 | 281 | 275 | 302 | | spark-1exec | q64 | 137 | 137 | 154 | | spark-2exec | q64 | 266 | 262 | 275 |
根据结果,有两件事很突出:
- 向Spark中添加更多的机器会带来更快的结果。这是意料之中的事,因为计算现在可以分布在多个实例上。
- 除了查询64(**)之外,Duckdb对所有查询都更快。这可以通过Spark在需要处理比1台机器的内存大得多的数据时大放异彩来解释。这就是为什么在单个节点或只有一个执行器的情况下运行Spark不是很有效的原因。另一方面,Duckdb针对处理单个节点上的数据进行了优化。
(*)我不考虑启动Kubernetes pod/节点所需的时间,而是只考虑执行查询所需的速度。与dbt相比,端到端运行带有2个执行器的Spark管道可能会有更差的性能,因为我们需要创建多个pod(提交器pod、驱动程序pod、1-2个执行器pod)。
(**)查询64是基准测试中最重的查询,因为它将两个最大的事实表连接在一起。尽管Duckdb在无法分配更多内存时会将数据刷新到磁盘,但由于内存不足,我无法成功执行查询。在尝试使用更大的实例时也发生了同样的事情。我需要更详细地调查为什么会出现这种情况。
结论
在这篇博客文章中,我从dbt相对于Spark提供的优势开始,比如更大的SQL受众和更简单的执行。这些好处,再加上大多数公司不处理大数据的事实,引发了人们对Spark是否是他们的最佳工具的质疑。
作为一种替代方案,我展示了当数据集不太大,并且工作负载与SQL兼容时,dbt与Duckdb相结合是非常好的。
最后,我通过运行TPC-DS基准测试,证明了dbt和Duckdb的价值。结果表明,除了一个查询外,带有DuckDB的dbt在所有查询上都优于Spark。
- 登录 发表评论
- 891 次浏览
最新内容
- 4 days ago
- 1 week 4 days ago
- 2 weeks 1 day ago
- 2 months ago
- 5 months 4 weeks ago
- 5 months 4 weeks ago
- 5 months 4 weeks ago
- 5 months 4 weeks ago
- 5 months 4 weeks ago
- 5 months 4 weeks ago