
category
介绍
随着自然语言处理(NLP)世界的不断发展,大型语言模型(LLM)已成为许多应用程序的重要工具。然而,从头开始训练这些模型在计算上可能是昂贵和耗时的。这就是微调和参数有效微调(PEFT)发挥作用的地方。
微调和参数有效微调(PEFT):
微调是一个过程,包括采用预先训练好的模型并使其适应新任务。这就像取一个现有的食谱,然后根据你的个人口味进行调整。然而,微调大型语言模型可能在计算上昂贵且耗时,因为它通常涉及更新模型的所有参数。
这就是参数有效微调(PEFT)发挥作用的地方。PEFT方法的目的是只更新模型参数的一小部分,使微调过程更有效,而不影响性能。
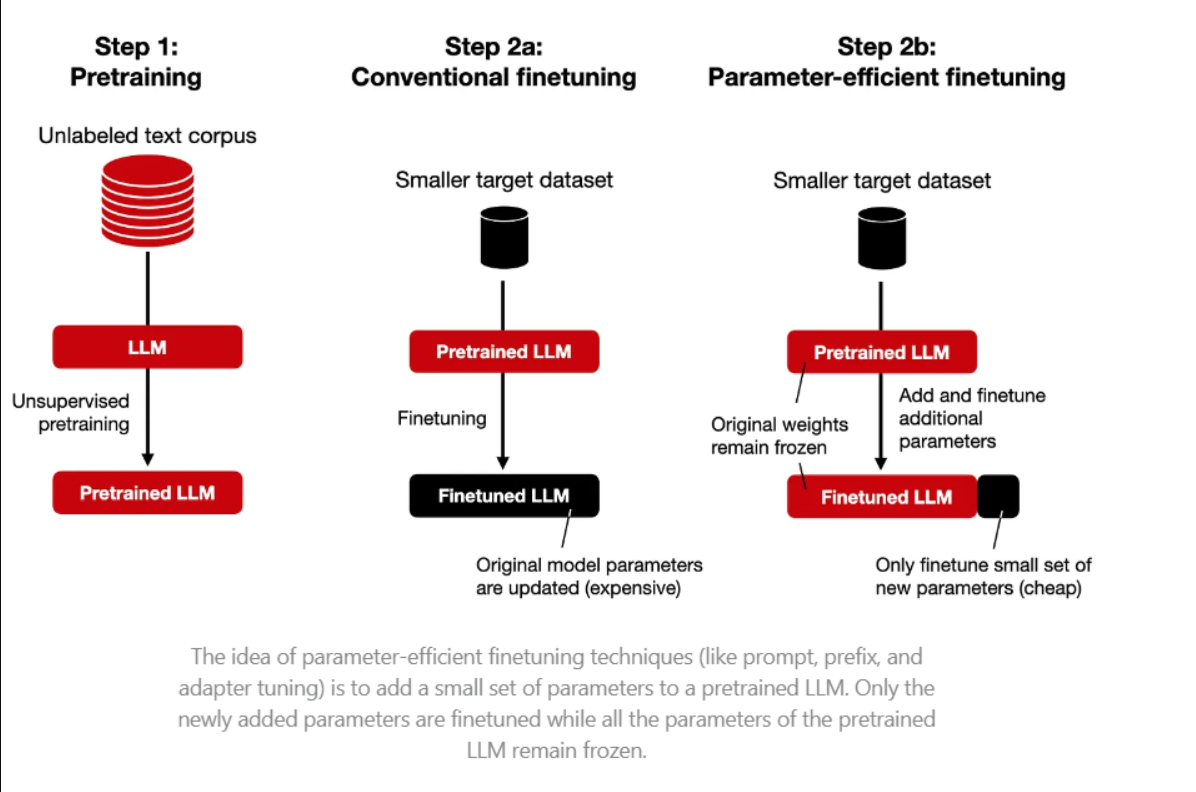
PEFT类型:
PEFT方法有几种类型,包括适配器调整、前缀调整和LoRA等。每种方法都有其独特的方法来更新模型的参数。本文将重点讨论LoRA及其量化版本QLoRA。
LoRA
传统的微调包括更新预先训练的神经网络的整个权重矩阵(W)以适应新任务。该过程在计算上可能是昂贵的,并且需要大量的可训练参数。
LoRA(低秩自适应[Low-Rank Adaptation])是一种更有效的方法,它将权重更新矩阵(ΔW)分解为两个低维矩阵(a)和(B)。这种分解减少了可训练参数的数量,使微调更加有效。
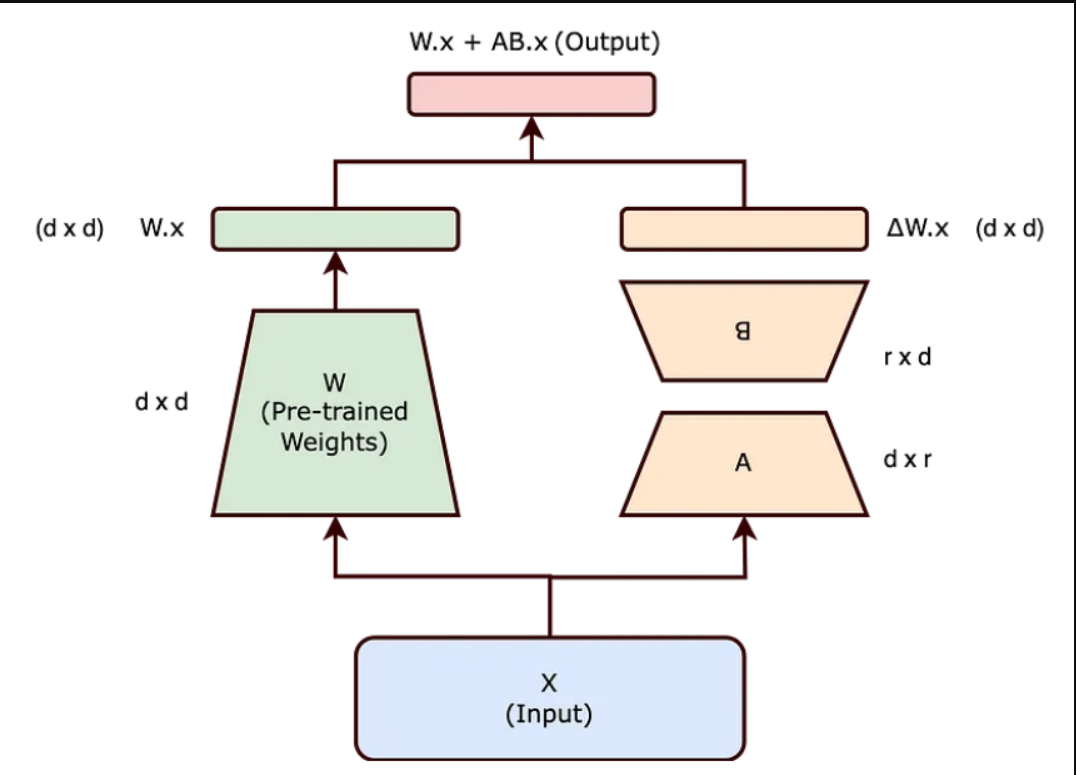
LoRA表示(ΔW)为两个较小矩阵(A)和(B)的乘积,秩较低。更新后的权重矩阵(W')变为W+BA,其中W保持冻结,A和B在训练期间更新。
LoRA方法减少了可训练参数的数量,使微调更加有效。例如,如果W是一个(d x d)矩阵,传统的微调将需要(d²)参数,但LoRA将其减少到(2dr),当(r<<d)时,该参数要小得多。
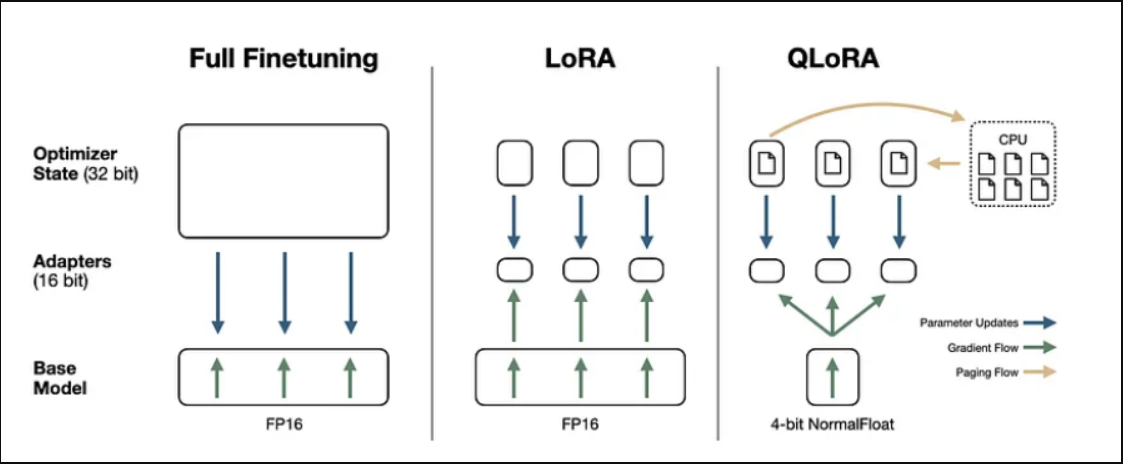
QLoRA(LoRA 2.0)
在LoRA的成功基础上,QLoRA(量化低秩自适应)将有效的微调提升到一个新的水平。传统上,模型参数以32/16位格式存储,但QLoRA将其压缩为4位格式,从而显著降低了内存需求。这一创新使大型语言模型能够在单个GPU上进行微调,从而有可能在功能较弱的硬件上部署这些模型,包括消费级GPU。
结论
LoRA和QLoRA是强大的PEFT技术,能够使LLM有效地适应特定任务或领域,同时保留原始模型的知识和能力。通过引入低秩矩阵和量化,这些技术显著降低了微调的计算和内存需求,使其更易于访问和扩展。随着LLM领域的不断发展,LoRA和QLoRA等技术将在释放这些强大模型的全部潜力方面发挥关键作用。
- 登录 发表评论
- 295 次浏览
最新内容
- 6 days 15 hours ago
- 2 weeks ago
- 2 weeks 4 days ago
- 2 months ago
- 6 months ago
- 6 months ago
- 6 months ago
- 6 months ago
- 6 months ago
- 6 months ago