
了解数据保护法规遵从性的关键技术
数据匿名化、去识别、编辑、假名化和标记化是满足GDPR和即将出台的CPRA等数据保护法规的关键技术。但是,区分匿名化、去身份识别、编辑、假名化和标记化比看起来更复杂:有足够多的混乱和错误信息,即使是最老练的数据科学家也会上当受骗。
匿名化vs去身份识别vs编辑化vs假名化vs标记化
正确定义是做出正确决策以最有效地保护和使用数据的关键一步。我们将查看每个的定义,并给出一个正在运行的实际示例,以直观地显示每个定义的样子。
在围绕这些术语的讨论中,重新识别风险往往交织在一起。重新识别是指确定数据集中具有直接识别信息(如全名、社会保险号码)或准识别信息(例如年龄、大致地址)的个人的身份。当将准标识符组合在一起时,会导致重新识别的指数风险。在某些情况下,取消识别机构需要重新识别的能力,在这种情况下,另一层风险在于恶意方访问将直接和准标识符与它们被替换的数据链接起来的数据的可能性。
匿名
匿名意味着从数据集中删除个人可识别信息和准可识别信息(即,当与其他信息结合时,可能导致重新识别的数据;例如,年龄、大致地址等),使个人永久无法识别。参见匿名和GDPR合规性;概述以了解它如何融入GDPR。
匿名化通常是使结构化医疗数据集安全共享的首选方法。非结构化数据呢?它可以匿名吗?虽然这样做比较棘手,但答案是肯定的。以下是一封经过适当匿名处理的电子邮件示例:
“Hi [NAME],
Apologies, it had ended up in my spam!
I’m booked at [TIME] tomorrow, but [TIME] would work. I’ll send an updated invite for that time. Please let me know if that doesn’t work for you.
Thank you,
[NAME]”
去消标
去标识还需要删除个人和准标识符,但要通过一个过程将原始数据重新连接到去标识的结果。请参阅数据去标识或匿名化指南。
在实践中,去识别通常用于描述删除直接标识符(全名、地址、SSN等)的过程,有时还包括准标识符(年龄、性别等),但与匿名化相比,数据无法链接回个人的保证更少,尽管它有时也被用作一个术语,包括匿名化和假名化。
你可能会想,如果你不能保证数据是匿名的,那么去识别数据有什么意义?这取决于用例。
将上面的匿名电子邮件更改为:
“Hi [NAME_1],
Apologies, it had ended up in my spam!
I’m booked at [TIME_1] tomorrow, but [TIME_2] would work. I’ll send an updated invite for that time. Please let me know if that doesn’t work for you.
Thank you,
[NAME_2]”
现在假设一家公司决定加密与NAME_1、NAME_2、TIME_1和TIME_2相关的直接和潜在标识符,并将其单独存储,以防他们需要重新识别电子邮件(可能在法庭上使用)。这封电子邮件将不再被视为匿名,因为标识符可以链接回它。
但这并不意味着隐私受到了损害。例如,如果分析和机器学习团队使用未识别的电子邮件(而不是纯文本的原始电子邮件),他们实际上是在为用户和公司提供优质服务。可以在降低用户隐私风险的同时获得见解,并最大限度地降低将个人数据发送到组织中可能无法追踪的另一部分的安全风险。
Redaction
为了增加匿名化和去身份识别之间的混淆,“编辑”一词也经常被错误使用。根据国际隐私专业人员协会的术语表,编辑是“识别、删除或阻止正在制作的文件中的信息的做法[…]”。
Redaction在去身份识别方面扮演着一个有趣的角色。Redaction不一定涉及完全删除个人数据,而是选择性删除特别敏感的信息。一个例子是从客户服务对话中删除信用卡号码。如果电子邮件、通话记录或聊天日志因关于如何使用吸尘器的问题而泄露……这可能不会造成很大的破坏。但是,如果这些聊天日志中有信用卡号码,而且它们还没有被删除?巨额交易。
假名化
现在有一个术语经常被误解;即假名化。假名化是指用通常被表示为与原始数据链接的假数据替换某些数据(例如姓名、地址等)。这给一个术语留下了一个相当大的漏洞,这个术语意味着用与原始数据无关的虚假数据替换信息。我们将创造一个短语自然假名化,没有联系来定义这一点。
与上文所述的去身份识别相比,无关联的自然假名有许多优点。首先,数据对机器学习训练和推理变得更加友好。在下面的示例中,PII已被替换为斜体的假数据:
“Hi Kate,
Apologies, it had ended up in my spam!
I’m booked at 5pm tomorrow, but 9am would work. I’ll send an updated invite for that time. Please let me know if that doesn’t work for you.
Thank you,
Linda”
此外,无论意外留下什么个人或准身份信息,都会像大海捞针一样与虚假数据区分开来(或者更像是大海捞捞针);例如,假设在取消识别上面的电子邮件时意外遗漏了“Linda”:
“Hi [NAME_1],
Apologies, it had ended up in my spam!
I’m booked at [TIME_1] tomorrow, but [TIME_2] would work. I’ll send an updated invite for that time. Please let me know if that doesn’t work for you.
Thank you,
Linda”
在Private AI,我们花了大量时间来研究如何正确地进行自动假名处理。这里有一个提示:字典查找不起作用。为了以上下文化、非确定性的方式生成真实的单词和数字,我们不得不创建自己的转换器模型架构(一种为自然语言处理构建的机器学习模型)。仔细选择训练数据对于产生现实的替代品以及其他交易技巧至关重要。
标记化(Tokenization )也经常被称为一种假名化。
符号化(Tokenization )
最后一个经常用来具体描述替换某些数据的令牌类型的术语是令牌化。也就是说,用随机令牌替换个人数据。通常,原始数据和令牌之间会保持链接(例如,用于网站上的支付处理)。例如,令牌可以由单向函数(例如,带盐散列)生成,也可以是完全随机的数字。如果依赖加密,某些类型的标记化甚至可以是可逆的,例如,在这种情况下,只需要存储解密密钥,而不需要存储每条个人数据与其替换数据之间的链接。
让我们在运行的电子邮件示例中标记直接和准可识别信息:
“Hi 748331D230BF99D9A39ED0E6C6668CDD,
Apologies, it had ended up in my spam!
I’m booked at 3388E06178D0634FC03FFBDECCE677F8 tomorrow, but F6F7755D5141D5B7308DF2516AA9A82C would work. I’ll send an updated invite for that time. Please let me know if that doesn’t work for you.
Thank you,
CE5A40345609B81A5E7C973C1F3D93EB”
虽然标记化对支付处理特别有用,但与没有链接的自然假名相比,由于其相对缺乏相关的上下文信息,因此它不太可能成为非结构化数据保护的赢家。
把它们放在一起
尽管直接和准标识符通过匿名化、去识别、编辑、假名化和标记化以某种方式被删除,但它们在维护原始数据的上下文信息方面都非常有效。请继续关注我们关于匿名化如何被误解的下一篇文章。
同时,这里有一张方便的表格来指导您的决策:
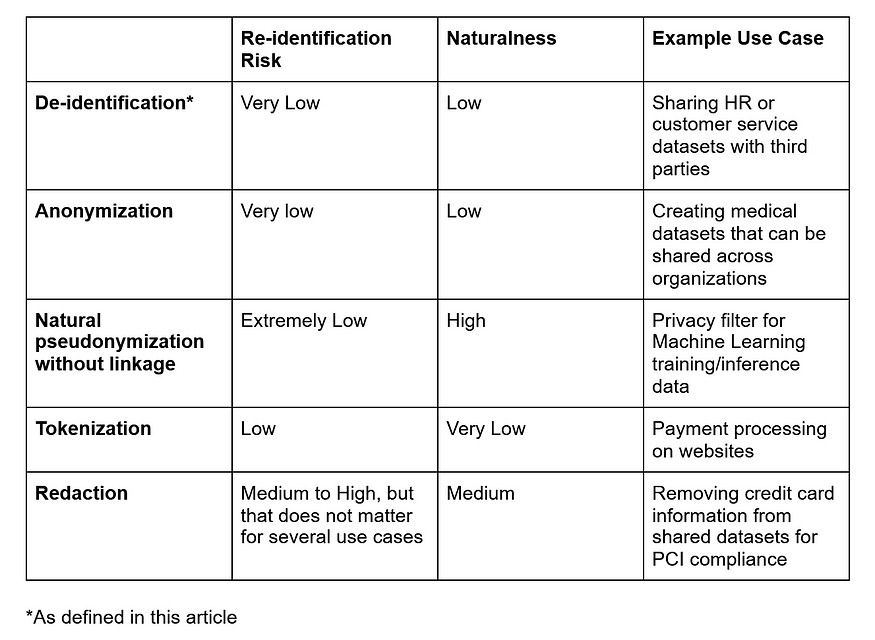
- 登录 发表评论
- 131 次浏览