
使用 Amazon DynamoDB
Regis Gimenis 和 Camilo Gonzalez,Amazon Web Services(AWS)
2020 年 10 月(文档历史记录)
NoSQL 数据库为构建现代应用程序提供了灵活的架构。它们因其易于开发、功能和大规模性能而广受认可。Amazon DynamoDB 提供快速而可预测的性能,能够实现无缝扩展(AWS) Cloud。DynamoDB 是一项完全托管的数据库服务,您可以用它免除操作和扩展分布式数据库的管理工作负担,因而无需担心硬件预置、设置和配置、复制、软件修补或集群扩展等问题。
NoSQL 架构设计需要一种与传统关系数据库管理系统 (RDBMS) 设计不同的方法。RDBMS 数据模型侧重于数据的结构及其与其他数据的关系。NoSQL 数据建模侧重于访问模式或应用程序将如何使用数据,因此它以支持简单查询操作的方式存储数据。对于像 Microsoft SQL Server 或 IBM Db2 这样的 RDBMS,你可以在不考虑访问模式的情况下创建标准化数据模型,然后将其扩展以支持以后的模式和查询。
本指南介绍了使用 DynamoDB 的数据建模流程,该过程提供了功能要求、性能和有效成本。该指南适用于计划使用 DynamoDB 作为正在运行的应用程序的操作数据库的数据库工程师AWS.AWS 专业服务已使用推荐流程来帮助企业公司针对不同的用例和工作负载进行 DynamoDB 数据建模。
数据建模流程
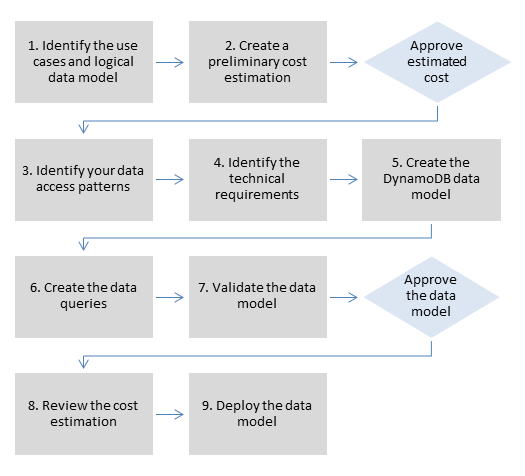
我们建议在使用 Amazon DynamoDB 建模数据时采用以下流程。详细讨论了这些步骤本指南后面的部分.
RACI 矩阵
一些组织使用责任分配矩阵(也称为RACI 矩阵)来描述一个特定项目或业务流程中涉及的各种角色。本指南提供了一个建议的 RACI 矩阵,可以帮助您的组织为 DynamoDB 数据建模过程确定合适的人员和正确的责任。对于该过程中的每个步骤,它列出了利益相关者及其参与程度:
-
R— 负责完成该步骤
-
一个— 负责批准和签署工作
-
C— 咨询以提供任务的意见
-
I— 了解了进展情况,但不直接参与任务
根据组织和项目团队的结构,以下 RACI 矩阵中的角色可以由同一个利益相关者履行。在某些情况下,利益攸关方对具体步骤负责和问责。例如,数据库工程师可以负责创建和批准数据模型,因为这是他们的域区。
| 处理步骤 | 商业用户 | 商业分析师 | 解决方案师 | 数据库工师 | 程序开发者 | DevOps 工程师 |
|---|---|---|---|---|---|---|
|
1. 确定使用案例和逻辑数据模型 |
C |
R/ |
I |
R |
|
|
|
2. 创建初步成本估算 |
C |
A |
I |
R |
|
|
|
3. 确定数据访问模式 |
C |
A |
I |
R |
|
|
|
4. 确定技术要求 |
C |
C |
A |
R |
|
|
|
5. 创建 DynamoDB 数据模型 |
I |
I |
I |
R/ |
|
|
|
6. 创建数据查询 |
I |
I |
I |
R/ |
R |
|
|
7. 验证数据模型 |
A |
R |
I |
C |
|
|
|
8. 查看成本估算 |
C |
A |
I |
R |
|
|
|
9. 部署 DynamoDB 数据模型 |
I |
I |
C |
C |
|
R/ |
数据建模流程步骤
本节详细介绍了 Amazon DynamoDB 推荐的数据建模流程的每个步骤。
主题
- 第 1 步 确定使用案例和逻辑数据模型
- 第 2 步 创建初步成本估算
- 第 3 步 确定数据访问模式
- 第 4 步 确定技术要求
- 第 5 步 创建 DynamoDB 数据模型
- 第 6 步 创建数据查询
- 第 7 步 验证数据模型
- 第 8 步 查看成本估算
- 第 9 步 部署数据模型
第 1 步 确定使用案例和逻辑数据模型
目标
-
收集需要 NoSQL 数据库的业务需求和使用案例。
-
使用实体关系 (ER) 图定义逻辑数据模型。
过程
-
业务分析师访谈业务用户,以确定使用案例和预期结果。
-
数据库工程师创建概念性数据模型。
-
数据库工程师创建逻辑数据模型。
-
数据库工程师收集有关项目大小、数据量和预期读取和写入吞吐量的信息。
工具和资源
RACI
| 商业用户 | 商业分析师 | 解决方案构 | 数据库技术 | 应用程序 | DevOps 工程师 |
|---|---|---|---|---|---|
|
C |
R/ |
I |
R |
|
|
输出
-
记录的使用案例和业务要求
-
逻辑数据模型(ER 图)
第 2 步 创建初步成本估算
目标
-
为 DynamoDB 制定初步成本估算。
过程
-
数据库工程师使用可用信息和在DynamoDB 定价页面.
-
业务分析师审查并批准或拒绝初步成本估算。
工具和资源
RACI
| 商业用户 | 商业分析师 | 解决方案构 | 数据库技术 | 应用程序 | DevOps 工程师 |
|---|---|---|---|---|---|
|
C |
A |
I |
R |
|
|
输出
-
初步估算
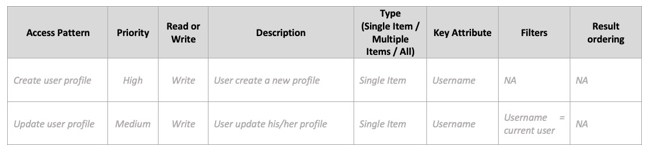
第 3 步 确定数据访问模式
访问模式或查询模式定义了用户和系统如何访问数据以满足业务需求。
目标
-
记录数据访问模式。
过程
-
数据库工程师和业务分析师访谈最终用户,以确定如何使用数据访问模式矩阵模板查询数据。
-
对于新应用程序,他们会查看有关活动和目标的用户案例。他们记录使用案例并分析使用案例需要的访问模式。
-
对于现有应用程序,他们分析查询日志以了解人们目前使用该系统的方式并确定密钥访问模式。
-
-
数据库工程师确定访问模式的以下属性:
-
数据大小: 了解一次存储和请求的数据量有助于确定对数据进行分区的最有效方法(请参阅博客帖子)。
-
数据形状: NoSQL 数据库不会在处理查询时重塑数据(如 RDBMS 系统所做的一样),而是整理数据以便数据在数据库中的形状与查询内容对应。这是加快速度并增强可扩展性的一个关键因素。
-
数据速度: DynamoDB 通过增加可用于处理查询的物理分区的数量并通过跨这些分区有效分发数据来进行扩展。预先了解峰值查询负载可能有助于确定数据分区方式,从而最高效地使用 I/O 容量。
-
-
企业用户优先考虑访问或查询模式。
-
优先级查询通常是最常用或最相关的查询。确定需要较低响应延迟的查询也很重要。
-
工具和资源
-
访问模式矩阵(请参阅模板)
-
选择正确的 DynamoDB 分区键(AWS 数据库博客)
-
面向 DynamoDB 的 NoSQL 设计(DynamoDB 文档)
RACI
| 商业用户 | 商业分析师 | 解决方案构 | 数据库技术 | 应用程序 | DevOps 工程师 |
|---|---|---|---|---|---|
|
C |
A |
I |
R |
|
|
输出
-
数据访问模式矩阵
示例
第 4 步 确定技术要求
目标
-
收集 DynamoDB 数据库的技术要求。
过程
-
业务分析师采访了业务用户和 DevOps 团队,通过使用评估调查表收集技术要求。
工具和资源
-
技术需求评估(请参阅调查表样本)
RACI
| 商业用户 | 商业分析师 | 解决方案构 | 数据库技术 | 应用程序 | DevOps 工程师 |
|---|---|---|---|---|---|
|
C |
C |
A |
R |
|
|
输出
-
技术要求文档
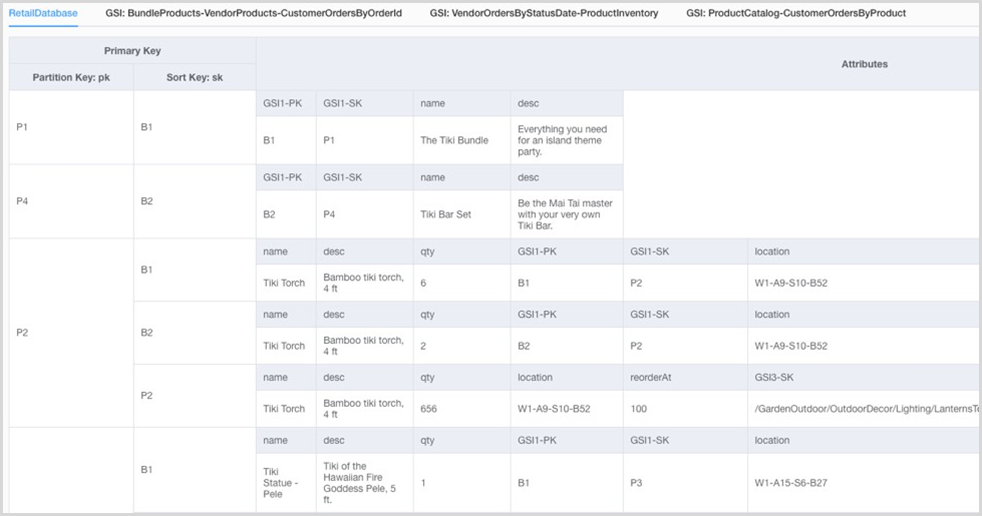
第 5 步 创建 DynamoDB 数据模型
目标
-
创建 DynamoDB 数据模型。
过程
-
数据库工程师确定每个使用案例需要多少个表。我们建议在 DynamoDB 应用程序中保留尽可能少的表。
-
根据最常见的访问模式,确定可以是两种类型之一的主键:带有标识数据的简单分区键的主键,或者是带分区键和排序键的主键。排序键是用于对数据进行分组和组织的辅助键,因此可以在分区内有效地查询数据。可以使用排序键定义可在任何层次结构级别查询的层次关系(请参阅博客帖子)。
-
分区键设计
-
定义分区键并评估其分布情况。
-
确定需要写入分片以均匀分配工作负载。
-
-
排序键设计
-
确定排序键。
-
确定是否需要复合排序键。
-
确定版本控制的需求。
-
-
-
根据访问模式,确定二级索引以满足查询要求。
-
数据库工程师决定数据是否将包括大型项目。如果是这样,他们设计解决方案通过使用压缩或存储数据在 Amazon Simple Storage Service (Amazon S3) 中。
-
数据库工程师决定是否需要时间序列数据。如果是这样,他们会使用时间序列设计模式对数据进行建模。
-
数据库工程师确定 ER 模型是否包括多对多关系。如果是这样,他们使用邻接列表设计模式对数据进行建模。
工具和资源
-
适用于 Amazon DynamoDB 的 NoSQL Workbench— 提供数据建模、数据可视化和查询开发/测试功能,可帮助您设计 DynamoDB 数据库
-
面向 DynamoDB 的 NoSQL 设计(DynamoDB 文档)
-
选择正确的 DynamoDB 分区键(AWS 数据库博客)
-
DynamoDB 中使用二级索引的最佳实践(DynamoDB 文档)
-
如何设计 Amazon DynamoDB 全局二级索引(AWS 数据库博客)
RACI
| 商业用户 | 商业分析师 | 解决方案构 | 数据库技术 | 应用程序 | DevOps 工程师 |
|---|---|---|---|---|---|
|
I |
I |
I |
R/ |
|
|
输出
-
满足您的访问模式和要求的 DynamoDB 表架构
示例
第 6 步 创建数据查询
目标
-
创建主要查询以验证数据模型。
过程
-
数据库 DynamoDB 序在AWS区域或计算机上(DynamoDB 本地)。
-
数据库工程师将示例数据添加到 DynamoDB 表中。
-
数据库工程师使用适用于 Amazon DynamoDB 的 NoSQL 工作台或AWS适用于 Java 或 Python 的 SDK 来构建示例查询(请参阅博客帖子)。
方面就像 DynamoDB 表的视图。
-
数据库工程师和云开发人员使用AWS Command Line Interface(AWS CLI) 或AWS首选语言的 SDK。
工具和资源
-
活跃AWS账户,以获得对 DynamoDB 控制台的访问权限
-
DynamoDB Local(可选),如果您想在不访问 DynamoDB Web 服务的情况下在计算机上构建数据库
-
适用于 Amazon DynamoDB 的 NoSQL Workbench(AWS 新闻博客)
-
AWS开发工具包用你选择的语言
RACI
| 商业用户 | 商业分析师 | 解决方案构 | 数据库技术 | 应用程序 | DevOps 工程师 |
|---|---|---|---|---|---|
|
I |
I |
I |
R/ |
R |
|
输出
-
查询 DynamoDB 表的代码
示例
第 7 步 验证数据模型
目标
-
确保数据模型符合您的要求。
过程
-
数据库工程序将使用示例数据填充 DynamoDB 表。
-
数据库工程师运行代码来查询 DynamoDB 表。
-
数据库工程师收集查询结果。
-
数据库工程师收集查询执行指标。
-
企业用户验证查询结果是否满足业务需求。
-
业务分析师验证了技术要求。
工具和资源
-
活跃AWS账户,以获得对 DynamoDB 控制台的访问权限
-
DynamoDB Local(可选),如果您想在不访问 DynamoDB Web 服务的情况下在计算机上构建数据库
-
AWS开发工具包用你选择的语言
RACI
| 商业用户 | 商业分析师 | 解决方案构 | 数据库技术 | 应用程序 | DevOps 工程师 |
|---|---|---|---|---|---|
|
A |
R |
I |
C |
|
|
输出
-
批准的数据模型
第 8 步 查看成本估算
目标
-
定义容量模型并估计 DynamoDB 成本,以便从步骤 2.
过程
-
数据库工程师确定了估计数据量。
-
数据库工程师确定了数据传输要求。
-
数据库工程师定义了所需的读取和写入容量单位。
-
业务分析师决定按需和预配置容量模型.
-
数据库工程师确定需要DynamoDB Auto Scaling.
-
数据库工程师在简单月度计算器工具中输入参数。
工具和资源
RACI
| 商业用户 | 商业分析师 | 解决方案构 | 数据库技术 | 应用程序 | DevOps 工程师 |
|---|---|---|---|---|---|
|
C |
A |
I |
R |
|
|
输出
-
容量模型
-
修订费用估算
第 9 步 部署数据模型
目标
-
将 DynamoDB 表部署到AWS区域。
过程
-
DevOps 架构师创建AWS CloudFormation用于 DynamoDB 表的模板或其他基础设施即代码 (iAC) 工具。AWS CloudFormation提供了一种自动配置和配置表和相关资源的方法。
工具和资源
RACI
| 商业用户 | 商业分析师 | 解决方案构 | 数据库技术 | 应用程序 | DevOps 工程师 |
|---|---|---|---|---|---|
|
I |
I |
C |
C |
|
R/ |
输出
-
CloudFormation 模板
示例
mySecondDDBTable: Type: AWS::DynamoDB:: Table DependsOn: "myFirstDDBTable" Properties: AttributeDefinitions: - AttributeName: "ArtistId" AttributeType: "S" - AttributeName: "Concert" AttributeType: "S" - AttributeName: "TicketSales" AttributeType: "S" KeySchema: - AttributeName: "ArtistId" KeyType: "HASH" - AttributeName: "Concert" KeyType: "RANGE" ProvisionedThroughput: ReadCapacityUnits: Ref: "ReadCapacityUnits" WriteCapacityUnits: Ref: "WriteCapacityUnits" GlobalSecondaryIndexes: - IndexName: "myGSI" KeySchema: - AttributeName: "TicketSales" KeyType: "HASH" Projection: ProjectionType: "KEYS_ONLY" ProvisionedThroughput: ReadCapacityUnits: Ref: "ReadCapacityUnits" WriteCapacityUnits: Ref: "WriteCapacityUnits" Tags: - Key: mykey Value: myvalue
模板
本节中提供的模板基于使用 Amazon DynamoDB 建模玩家数据在AWS网站.
注意
本部分中的表使用MM作为百万美元的缩写,以及K作为千人的缩写。
主题
业务需求评估模板
提供用例的描述:
描述
想象一下你正在构建一个在线多人游戏。在你的游戏中,由 50 名玩家组成的小组加入一个会话玩游戏,玩游戏通常需要 30 分钟左右。在游戏过程中,你必须更新特定玩家的记录,以表明玩家玩过的时间、他们的统计数据,或者他们是否赢了比赛。用户希望看到他们玩过的旧游戏,既可以查看游戏的获胜者,也可以观看每个游戏动作的重播。
提供有关您的用户的信息:

提供有关数据来源以及将如何摄取数据的信息:

提供有关如何使用数据的信息:

提供实体清单以及如何识别它们:

为实体创建 ER 模型:
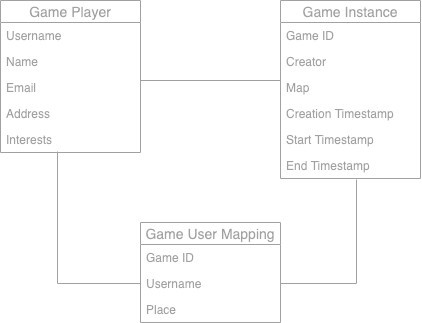
提供有关实体的高级统计数据:
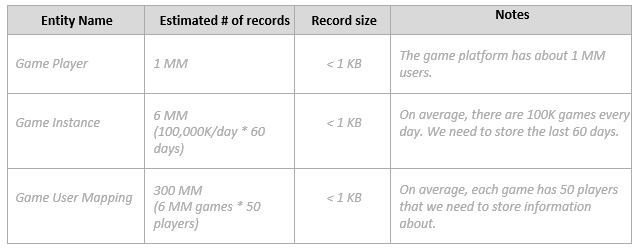
技术需求评估模板
提供有关数据摄取类型的信息:
提供有关数据消耗类型的信息:
提供数据量估计:
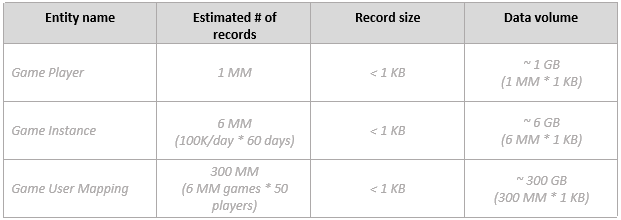
注意
数据保留期为 60 天。60 天后,数据必须存储在 Amazon S3 中进行分析,方法是使用DynamoDB 生存时间 (TTTL)将数据自动从 DynamoDB 移出到 Amazon S3。
回答这些关于时间模式的问题:
-
用户可以使用该应用程序的时间范围(例如,平日 24/7 或上午 9 点至下午 5 点)?
-
白天的使用率是否达到高峰? 多少个小时? 应用程序使用的百分比是多少?
指定写入吞吐量要求:
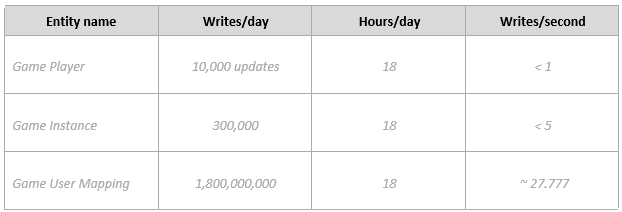
注意
玩家写操作:1% 的用户每天更新个人资料,因此我们预计将为 100 万名用户提供 10,000 次更新。
游戏实例写入操作:100,000 个游戏/天。对于每个游戏,我们至少有 3 个写入操作(在创建、开始和结束时),因此总数为 300,000 次写入操作。
游戏用户映射写操作:有 50 名玩家的每个游戏每天 100,000 个游戏。平均游戏持续时间为 30 分钟,游戏玩家的位置每 5 秒更新一次。我们估计每位玩家平均有 360 次更新,因此总数为 100,000 * 50 * 360 = 1,800,000,000 次写入操作。
指定读取吞吐量要求:
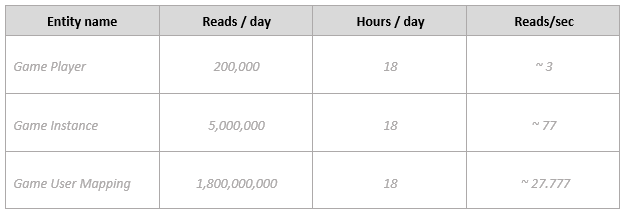
注意
玩家阅读操作:20% 的用户开始游戏,所以 1 毫米 * 0.2 = 200,000。
游戏实例读取操作:100,000 个游戏/天。对于每个游戏,我们每个玩家至少有 1 次读取操作,每个游戏有 50 名玩家,所以总数为 5,000,000 个读取操作。
游戏用户映射读取操作:50 名玩家每天 10 万个游戏。平均游戏持续时间为 30 分钟,游戏玩家的位置每 5 秒更新一次。我们估计每位玩家平均有 360 次更新,每次更新都需要一次读取操作,因此总数为 100,000 * 50 * 360 = 1,800,000,000 次读取操作。
指定数据访问延迟要求:
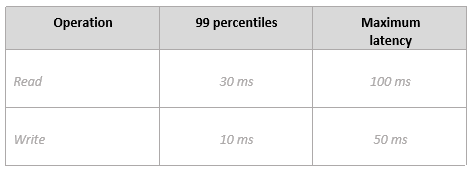
指定数据可用性要求:
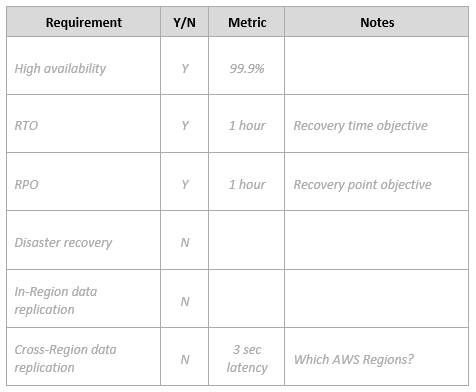
指定安全要求:
访问模式矩阵
使用以下字段收集和记录有关用例访问模式的信息:
| 字段 | 描述 |
|---|---|
|
访问模式 |
提供访问模式的名称。 |
|
描述 |
提供有关访问模式的更详细描述。 |
|
Priority |
定义访问模式的优先级(高/中/低)。这定义了与应用程序最相关的访问模式。 |
|
读写 |
这是读访问还是写访问模式? |
|
Type |
模式是否访问单件物品、多个物品还是所有物品? |
|
筛选条件 |
访问模式是否需要任何过滤器? |
|
排序 |
结果是否需要进行任何排序? |
:
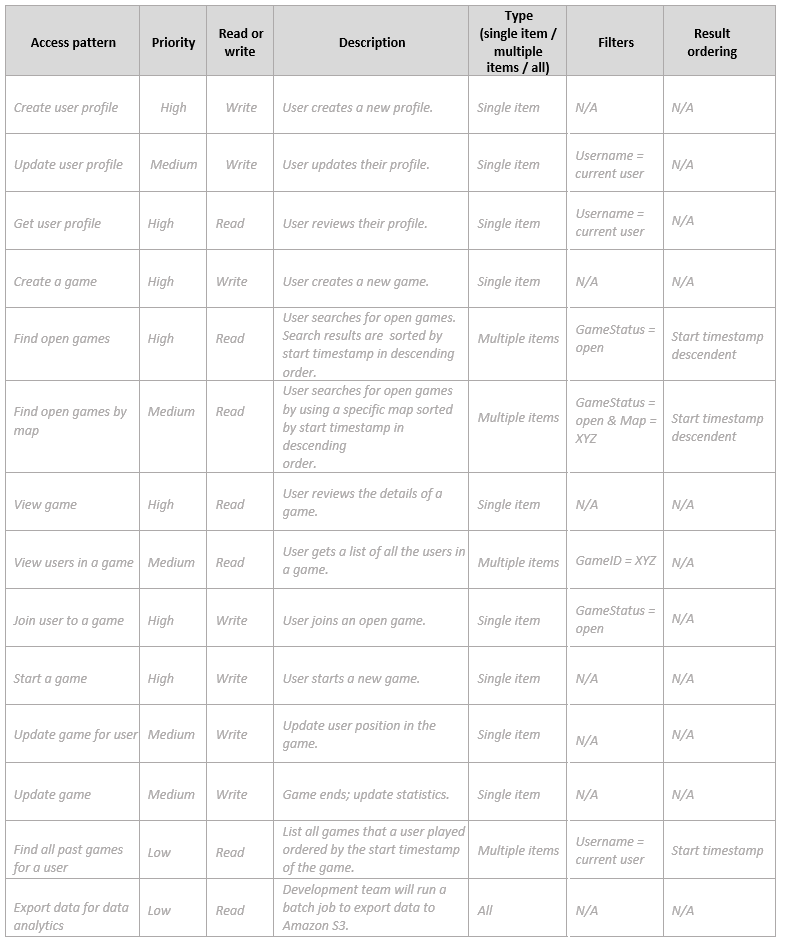
其他资源
有关 DynamoDB 的更多信息
-
使用 DynamoDB 建模玩家数据(实验室)
AWS 服务
工具
最佳实践
-
使用 DynamoDB 进行设计和架构的最佳实践(D ynamoDB 文档)
-
使用二级索引的最佳实践(DynamoDB 文档)
-
存储大型项目和属性的最佳实践(DynamoDB 文档)
-
选择正确的 DynamoDB 分区密钥(AWS 数据库博客)
-
如何设计Amazon DynamoDB 全球二级索引(AWS 数据库博客)
AWS一般资源
文档历史记录
下表描述了对本指南的重大更改。如果你想获得future 更新的通知,你可以订阅RSS 源.
| 变更 | 说明 | 日期 |
|---|---|---|
|
首次发布 |
— |
2020 年 10 月 26 日 |
本文: