【建模数据】使用Amazon DynamoDB建模数据
视频号

微信公众号

知识星球

使用 Amazon DynamoDB
Regis Gimenis 和 Camilo Gonzalez,Amazon Web Services(AWS)
2020 年 10 月(文档历史记录)
NoSQL 数据库为构建现代应用程序提供了灵活的架构。它们因其易于开发、功能和大规模性能而广受认可。Amazon DynamoDB 提供快速而可预测的性能,能够实现无缝扩展(AWS) Cloud。DynamoDB 是一项完全托管的数据库服务,您可以用它免除操作和扩展分布式数据库的管理工作负担,因而无需担心硬件预置、设置和配置、复制、软件修补或集群扩展等问题。
NoSQL 架构设计需要一种与传统关系数据库管理系统 (RDBMS) 设计不同的方法。RDBMS 数据模型侧重于数据的结构及其与其他数据的关系。NoSQL 数据建模侧重于访问模式或应用程序将如何使用数据,因此它以支持简单查询操作的方式存储数据。对于像 Microsoft SQL Server 或 IBM Db2 这样的 RDBMS,你可以在不考虑访问模式的情况下创建标准化数据模型,然后将其扩展以支持以后的模式和查询。
本指南介绍了使用 DynamoDB 的数据建模流程,该过程提供了功能要求、性能和有效成本。该指南适用于计划使用 DynamoDB 作为正在运行的应用程序的操作数据库的数据库工程师AWS.AWS 专业服务已使用推荐流程来帮助企业公司针对不同的用例和工作负载进行 DynamoDB 数据建模。
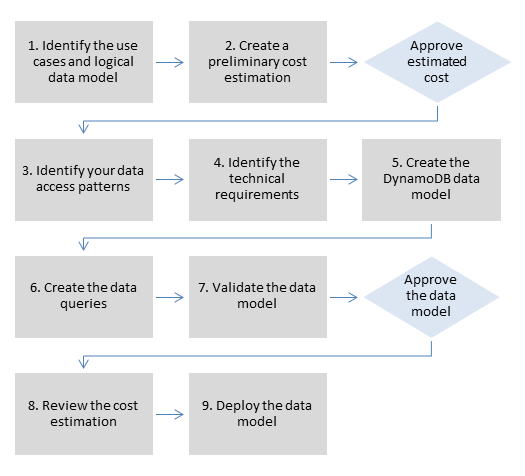
数据建模流程
我们建议在使用 Amazon DynamoDB 建模数据时采用以下流程。详细讨论了这些步骤本指南后面的部分.
RACI 矩阵
一些组织使用责任分配矩阵(也称为RACI 矩阵)来描述一个特定项目或业务流程中涉及的各种角色。本指南提供了一个建议的 RACI 矩阵,可以帮助您的组织为 DynamoDB 数据建模过程确定合适的人员和正确的责任。对于该过程中的每个步骤,它列出了利益相关者及其参与程度:
-
R— 负责完成该步骤
-
一个— 负责批准和签署工作
-
C— 咨询以提供任务的意见
-
I— 了解了进展情况,但不直接参与任务
根据组织和项目团队的结构,以下 RACI 矩阵中的角色可以由同一个利益相关者履行。在某些情况下,利益攸关方对具体步骤负责和问责。例如,数据库工程师可以负责创建和批准数据模型,因为这是他们的域区。
| 处理步骤 | 商业用户 | 商业分析师 | 解决方案师 | 数据库工师 | 程序开发者 | DevOps 工程师 |
|---|---|---|---|---|---|---|
|
1. 确定使用案例和逻辑数据模型 |
C |
R/ |
I |
R |
|
|
|
2. 创建初步成本估算 |
C |
A |
I |
R |
|
|
|
3. 确定数据访问模式 |
C |
A |
I |
R |
|
|
|
4. 确定技术要求 |
C |
C |
A |
R |
|
|
|
5. 创建 DynamoDB 数据模型 |
I |
I |
I |
R/ |
|
|
|
6. 创建数据查询 |
I |
I |
I |
R/ |
R |
|
|
7. 验证数据模型 |
A |
R |
I |
C |
|
|
|
8. 查看成本估算 |
C |
A |
I |
R |
|
|
|
9. 部署 DynamoDB 数据模型 |
I |
I |
C |
C |
|
R/ |
数据建模流程步骤
本节详细介绍了 Amazon DynamoDB 推荐的数据建模流程的每个步骤。
主题
- 第 1 步 确定使用案例和逻辑数据模型
- 第 2 步 创建初步成本估算
- 第 3 步 确定数据访问模式
- 第 4 步 确定技术要求
- 第 5 步 创建 DynamoDB 数据模型
- 第 6 步 创建数据查询
- 第 7 步 验证数据模型
- 第 8 步 查看成本估算
- 第 9 步 部署数据模型
第 1 步 确定使用案例和逻辑数据模型
目标
-
收集需要 NoSQL 数据库的业务需求和使用案例。
-
使用实体关系 (ER) 图定义逻辑数据模型。
过程
-
业务分析师访谈业务用户,以确定使用案例和预期结果。
-
数据库工程师创建概念性数据模型。
-
数据库工程师创建逻辑数据模型。
-
数据库工程师收集有关项目大小、数据量和预期读取和写入吞吐量的信息。
工具和资源
RACI
| 商业用户 | 商业分析师 | 解决方案构 | 数据库技术 | 应用程序 | DevOps 工程师 |
|---|---|---|---|---|---|
|
C |
R/ |
I |
R |
|
|
输出
-
记录的使用案例和业务要求
-
逻辑数据模型(ER 图)
第 2 步 创建初步成本估算
目标
-
为 DynamoDB 制定初步成本估算。
过程
-
数据库工程师使用可用信息和在DynamoDB 定价页面.
-
业务分析师审查并批准或拒绝初步成本估算。
工具和资源
RACI
| 商业用户 | 商业分析师 | 解决方案构 | 数据库技术 | 应用程序 | DevOps 工程师 |
|---|---|---|---|---|---|
|
C |
A |
I |
R |
|
|
输出
-
初步估算
第 3 步 确定数据访问模式
访问模式或查询模式定义了用户和系统如何访问数据以满足业务需求。
目标
-
记录数据访问模式。
过程
-
数据库工程师和业务分析师访谈最终用户,以确定如何使用数据访问模式矩阵模板查询数据。
-
对于新应用程序,他们会查看有关活动和目标的用户案例。他们记录使用案例并分析使用案例需要的访问模式。
-
对于现有应用程序,他们分析查询日志以了解人们目前使用该系统的方式并确定密钥访问模式。
-
-
数据库工程师确定访问模式的以下属性:
-
数据大小: 了解一次存储和请求的数据量有助于确定对数据进行分区的最有效方法(请参阅博客帖子)。
-
数据形状: NoSQL 数据库不会在处理查询时重塑数据(如 RDBMS 系统所做的一样),而是整理数据以便数据在数据库中的形状与查询内容对应。这是加快速度并增强可扩展性的一个关键因素。
-
数据速度: DynamoDB 通过增加可用于处理查询的物理分区的数量并通过跨这些分区有效分发数据来进行扩展。预先了解峰值查询负载可能有助于确定数据分区方式,从而最高效地使用 I/O 容量。
-
-
企业用户优先考虑访问或查询模式。
-
优先级查询通常是最常用或最相关的查询。确定需要较低响应延迟的查询也很重要。
-
工具和资源
-
访问模式矩阵(请参阅模板)
-
选择正确的 DynamoDB 分区键(AWS 数据库博客)
-
面向 DynamoDB 的 NoSQL 设计(DynamoDB 文档)
RACI
| 商业用户 | 商业分析师 | 解决方案构 | 数据库技术 | 应用程序 | DevOps 工程师 |
|---|---|---|---|---|---|
|
C |
A |
I |
R |
|
|
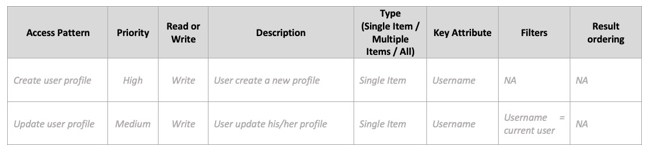
输出
-
数据访问模式矩阵
示例
第 4 步 确定技术要求
目标
-
收集 DynamoDB 数据库的技术要求。
过程
-
业务分析师采访了业务用户和 DevOps 团队,通过使用评估调查表收集技术要求。
工具和资源
-
技术需求评估(请参阅调查表样本)
RACI
| 商业用户 | 商业分析师 | 解决方案构 | 数据库技术 | 应用程序 | DevOps 工程师 |
|---|---|---|---|---|---|
|
C |
C |
A |
R |
|
|
输出
-
技术要求文档
第 5 步 创建 DynamoDB 数据模型
目标
-
创建 DynamoDB 数据模型。
过程
-
数据库工程师确定每个使用案例需要多少个表。我们建议在 DynamoDB 应用程序中保留尽可能少的表。
-
根据最常见的访问模式,确定可以是两种类型之一的主键:带有标识数据的简单分区键的主键,或者是带分区键和排序键的主键。排序键是用于对数据进行分组和组织的辅助键,因此可以在分区内有效地查询数据。可以使用排序键定义可在任何层次结构级别查询的层次关系(请参阅博客帖子)。
-
分区键设计
-
定义分区键并评估其分布情况。
-
确定需要写入分片以均匀分配工作负载。
-
-
排序键设计
-
确定排序键。
-
确定是否需要复合排序键。
-
确定版本控制的需求。
-
-
-
根据访问模式,确定二级索引以满足查询要求。
-
数据库工程师决定数据是否将包括大型项目。如果是这样,他们设计解决方案通过使用压缩或存储数据在 Amazon Simple Storage Service (Amazon S3) 中。
-
数据库工程师决定是否需要时间序列数据。如果是这样,他们会使用时间序列设计模式对数据进行建模。
-
数据库工程师确定 ER 模型是否包括多对多关系。如果是这样,他们使用邻接列表设计模式对数据进行建模。
工具和资源
-
适用于 Amazon DynamoDB 的 NoSQL Workbench— 提供数据建模、数据可视化和查询开发/测试功能,可帮助您设计 DynamoDB 数据库
-
面向 DynamoDB 的 NoSQL 设计(DynamoDB 文档)
-
选择正确的 DynamoDB 分区键(AWS 数据库博客)
-
DynamoDB 中使用二级索引的最佳实践(DynamoDB 文档)
-
如何设计 Amazon DynamoDB 全局二级索引(AWS 数据库博客)
RACI
| 商业用户 | 商业分析师 | 解决方案构 | 数据库技术 | 应用程序 | DevOps 工程师 |
|---|---|---|---|---|---|
|
I |
I |
I |
R/ |
|
|
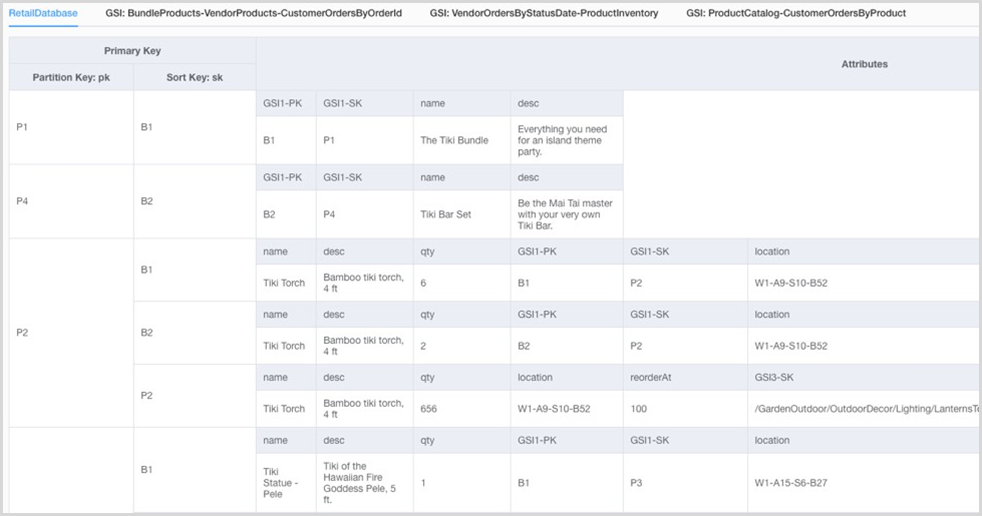
输出
-
满足您的访问模式和要求的 DynamoDB 表架构
示例
第 6 步 创建数据查询
目标
-
创建主要查询以验证数据模型。
过程
-
数据库 DynamoDB 序在AWS区域或计算机上(DynamoDB 本地)。
-
数据库工程师将示例数据添加到 DynamoDB 表中。
-
数据库工程师使用适用于 Amazon DynamoDB 的 NoSQL 工作台或AWS适用于 Java 或 Python 的 SDK 来构建示例查询(请参阅博客帖子)。
方面就像 DynamoDB 表的视图。
-
数据库工程师和云开发人员使用AWS Command Line Interface(AWS CLI) 或AWS首选语言的 SDK。
工具和资源
-
活跃AWS账户,以获得对 DynamoDB 控制台的访问权限
-
DynamoDB Local(可选),如果您想在不访问 DynamoDB Web 服务的情况下在计算机上构建数据库
-
适用于 Amazon DynamoDB 的 NoSQL Workbench(AWS 新闻博客)
-
AWS开发工具包用你选择的语言
RACI
| 商业用户 | 商业分析师 | 解决方案构 | 数据库技术 | 应用程序 | DevOps 工程师 |
|---|---|---|---|---|---|
|
I |
I |
I |
R/ |
R |
|
输出
-
查询 DynamoDB 表的代码
示例
第 7 步 验证数据模型
目标
-
确保数据模型符合您的要求。
过程
-
数据库工程序将使用示例数据填充 DynamoDB 表。
-
数据库工程师运行代码来查询 DynamoDB 表。
-
数据库工程师收集查询结果。
-
数据库工程师收集查询执行指标。
-
企业用户验证查询结果是否满足业务需求。
-
业务分析师验证了技术要求。
工具和资源
-
活跃AWS账户,以获得对 DynamoDB 控制台的访问权限
-
DynamoDB Local(可选),如果您想在不访问 DynamoDB Web 服务的情况下在计算机上构建数据库
-
AWS开发工具包用你选择的语言
RACI
| 商业用户 | 商业分析师 | 解决方案构 | 数据库技术 | 应用程序 | DevOps 工程师 |
|---|---|---|---|---|---|
|
A |
R |
I |
C |
|
|
输出
-
批准的数据模型
第 8 步 查看成本估算
目标
-
定义容量模型并估计 DynamoDB 成本,以便从步骤 2.
过程
-
数据库工程师确定了估计数据量。
-
数据库工程师确定了数据传输要求。
-
数据库工程师定义了所需的读取和写入容量单位。
-
业务分析师决定按需和预配置容量模型.
-
数据库工程师确定需要DynamoDB Auto Scaling.
-
数据库工程师在简单月度计算器工具中输入参数。
工具和资源
RACI
| 商业用户 | 商业分析师 | 解决方案构 | 数据库技术 | 应用程序 | DevOps 工程师 |
|---|---|---|---|---|---|
|
C |
A |
I |
R |
|
|
输出
-
容量模型
-
修订费用估算
第 9 步 部署数据模型
目标
-
将 DynamoDB 表部署到AWS区域。
过程
-
DevOps 架构师创建AWS CloudFormation用于 DynamoDB 表的模板或其他基础设施即代码 (iAC) 工具。AWS CloudFormation提供了一种自动配置和配置表和相关资源的方法。
工具和资源
RACI
| 商业用户 | 商业分析师 | 解决方案构 | 数据库技术 | 应用程序 | DevOps 工程师 |
|---|---|---|---|---|---|
|
I |
I |
C |
C |
|
R/ |
输出
-
CloudFormation 模板
示例
mySecondDDBTable: Type: AWS::DynamoDB:: Table DependsOn: "myFirstDDBTable" Properties: AttributeDefinitions: - AttributeName: "ArtistId" AttributeType: "S" - AttributeName: "Concert" AttributeType: "S" - AttributeName: "TicketSales" AttributeType: "S" KeySchema: - AttributeName: "ArtistId" KeyType: "HASH" - AttributeName: "Concert" KeyType: "RANGE" ProvisionedThroughput: ReadCapacityUnits: Ref: "ReadCapacityUnits" WriteCapacityUnits: Ref: "WriteCapacityUnits" GlobalSecondaryIndexes: - IndexName: "myGSI" KeySchema: - AttributeName: "TicketSales" KeyType: "HASH" Projection: ProjectionType: "KEYS_ONLY" ProvisionedThroughput: ReadCapacityUnits: Ref: "ReadCapacityUnits" WriteCapacityUnits: Ref: "WriteCapacityUnits" Tags: - Key: mykey Value: myvalue
模板
本节中提供的模板基于使用 Amazon DynamoDB 建模玩家数据在AWS网站.
注意
本部分中的表使用MM作为百万美元的缩写,以及K作为千人的缩写。
主题
业务需求评估模板
提供用例的描述:
描述
想象一下你正在构建一个在线多人游戏。在你的游戏中,由 50 名玩家组成的小组加入一个会话玩游戏,玩游戏通常需要 30 分钟左右。在游戏过程中,你必须更新特定玩家的记录,以表明玩家玩过的时间、他们的统计数据,或者他们是否赢了比赛。用户希望看到他们玩过的旧游戏,既可以查看游戏的获胜者,也可以观看每个游戏动作的重播。
提供有关您的用户的信息:

提供有关数据来源以及将如何摄取数据的信息:

提供有关如何使用数据的信息:

提供实体清单以及如何识别它们:

为实体创建 ER 模型:
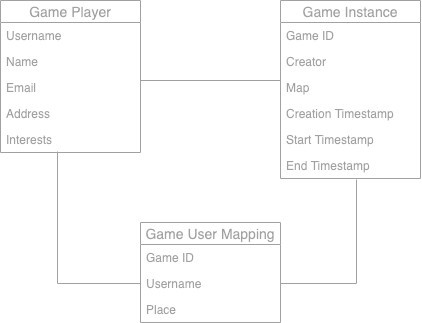
提供有关实体的高级统计数据:
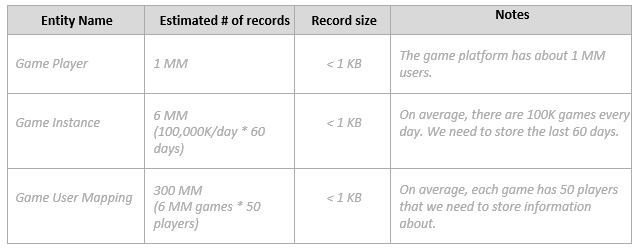
技术需求评估模板
提供有关数据摄取类型的信息:
提供有关数据消耗类型的信息:
提供数据量估计:
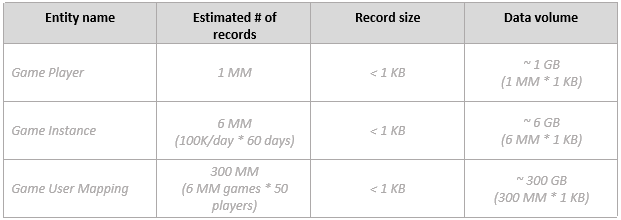
注意
数据保留期为 60 天。60 天后,数据必须存储在 Amazon S3 中进行分析,方法是使用DynamoDB 生存时间 (TTTL)将数据自动从 DynamoDB 移出到 Amazon S3。
回答这些关于时间模式的问题:
-
用户可以使用该应用程序的时间范围(例如,平日 24/7 或上午 9 点至下午 5 点)?
-
白天的使用率是否达到高峰? 多少个小时? 应用程序使用的百分比是多少?
指定写入吞吐量要求:
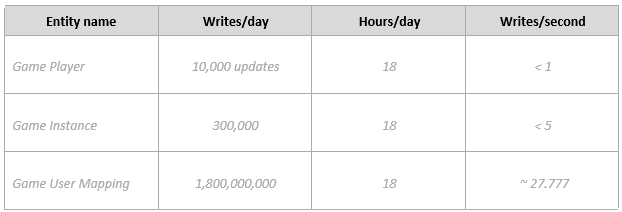
注意
玩家写操作:1% 的用户每天更新个人资料,因此我们预计将为 100 万名用户提供 10,000 次更新。
游戏实例写入操作:100,000 个游戏/天。对于每个游戏,我们至少有 3 个写入操作(在创建、开始和结束时),因此总数为 300,000 次写入操作。
游戏用户映射写操作:有 50 名玩家的每个游戏每天 100,000 个游戏。平均游戏持续时间为 30 分钟,游戏玩家的位置每 5 秒更新一次。我们估计每位玩家平均有 360 次更新,因此总数为 100,000 * 50 * 360 = 1,800,000,000 次写入操作。
指定读取吞吐量要求:
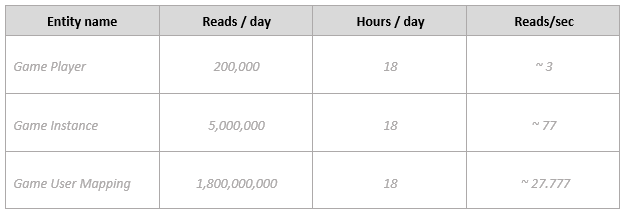
注意
玩家阅读操作:20% 的用户开始游戏,所以 1 毫米 * 0.2 = 200,000。
游戏实例读取操作:100,000 个游戏/天。对于每个游戏,我们每个玩家至少有 1 次读取操作,每个游戏有 50 名玩家,所以总数为 5,000,000 个读取操作。
游戏用户映射读取操作:50 名玩家每天 10 万个游戏。平均游戏持续时间为 30 分钟,游戏玩家的位置每 5 秒更新一次。我们估计每位玩家平均有 360 次更新,每次更新都需要一次读取操作,因此总数为 100,000 * 50 * 360 = 1,800,000,000 次读取操作。
指定数据访问延迟要求:
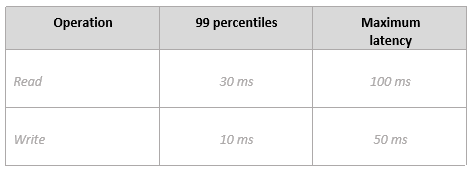
指定数据可用性要求:
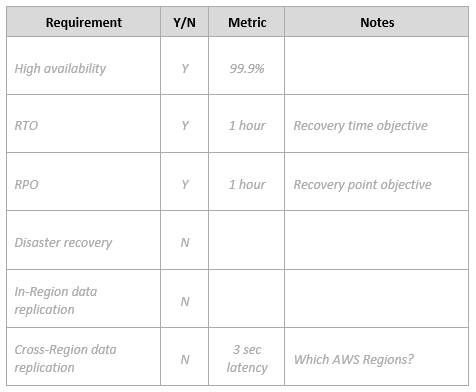
指定安全要求:
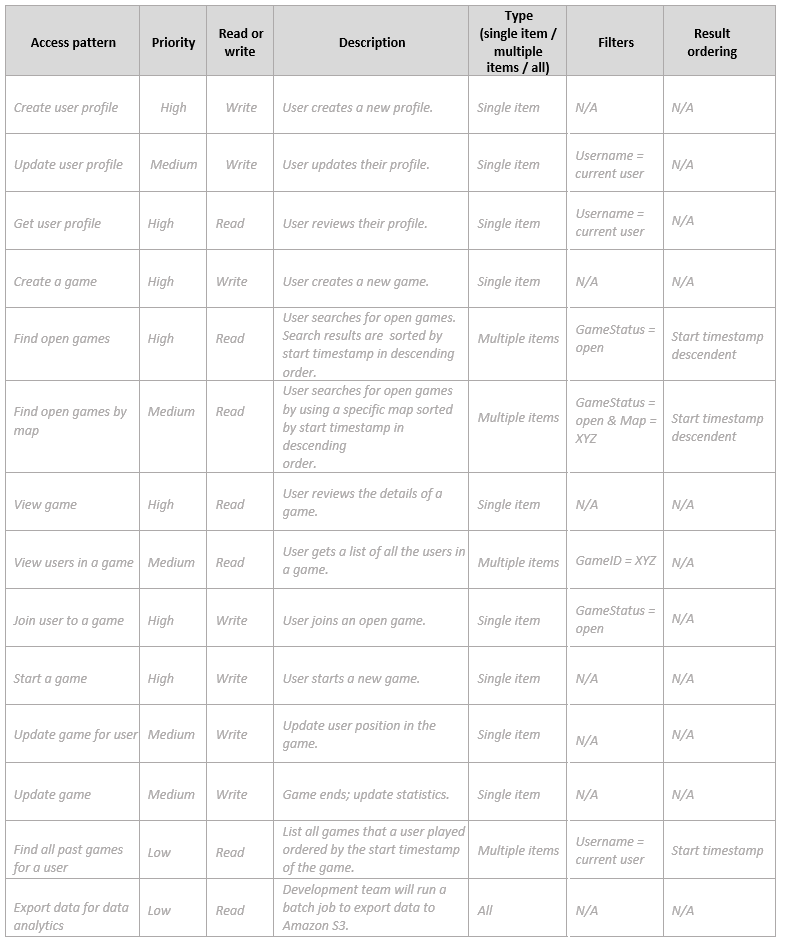
访问模式矩阵
使用以下字段收集和记录有关用例访问模式的信息:
| 字段 | 描述 |
|---|---|
|
访问模式 |
提供访问模式的名称。 |
|
描述 |
提供有关访问模式的更详细描述。 |
|
Priority |
定义访问模式的优先级(高/中/低)。这定义了与应用程序最相关的访问模式。 |
|
读写 |
这是读访问还是写访问模式? |
|
Type |
模式是否访问单件物品、多个物品还是所有物品? |
|
筛选条件 |
访问模式是否需要任何过滤器? |
|
排序 |
结果是否需要进行任何排序? |
:
其他资源
有关 DynamoDB 的更多信息
-
使用 DynamoDB 建模玩家数据(实验室)
AWS 服务
工具
最佳实践
-
使用 DynamoDB 进行设计和架构的最佳实践(D ynamoDB 文档)
-
使用二级索引的最佳实践(DynamoDB 文档)
-
存储大型项目和属性的最佳实践(DynamoDB 文档)
-
选择正确的 DynamoDB 分区密钥(AWS 数据库博客)
-
如何设计Amazon DynamoDB 全球二级索引(AWS 数据库博客)
AWS一般资源
文档历史记录
下表描述了对本指南的重大更改。如果你想获得future 更新的通知,你可以订阅RSS 源.
| 变更 | 说明 | 日期 |
|---|---|---|
|
首次发布 |
— |
2020 年 10 月 26 日 |
本文:
- 83 次浏览
【数据建模】设计一个DynamoDB数据模型,用于管理图形化的层次关系 -- 介绍
视频号
微信公众号
知识星球
Amazon DynamoDB是Amazon Web Services(AWS)提供的一种快速、灵活、无服务器的数据库。它是一个NoSQL事务数据库系统,即使在PB大小的数据存储中,也可以提供一致的单位数毫秒性能。
本指南介绍了一种设计用于处理多级组件管理系统的DynamoDB数据模型的方法。在系统中,组件、其子组件及其子组件之间的层次关系得到维护,深度可以达到任何级别。
概述
通常,对于构建分层关系模型,像Amazon Neptune这样的图形数据库是更好的选择。然而,在某些情况下,DynamoDB是分层数据建模的更好选择,因为它具有灵活性、安全性、性能和规模。
例如,您可以构建一个系统,其中80%–90%的查询是事务性的,DynamicDB非常适合。在本例中,其他10-20%的查询是关系型的,类似海王星的图形数据库更适合。在这种情况下,在体系结构中添加一个额外的数据库以仅完成10%到20%的查询可能会增加维护多个系统和同步数据的成本和操作负担。相反,您可以在DynamicDB中模拟10%到20%的关系查询。
作为一个示例用例,汽车公司希望构建一个事务性组件管理系统,以存储和搜索所有可用的汽车零件,并在不同的组件和零件之间建立关系。例如,一辆汽车包含多个电池,每个电池包含多个高级模块,每个模块包含多个单元,每个单元包含多个低级组件。
由于以下原因,难以在DynamoDB中建立层次关系模型:
- 它使用非规范化的键值存储。
- 与关系数据库管理系统(RDBMS)不同,它不支持外键和联接操作。
- 与图形数据库不同,它不是为本地处理分层图形数据而设计的。
因此,为了在DynamoDB中高效地存储和搜索汽车组件相关性或任何层次关系数据,您必须格外小心地设计数据模型。否则,查询响应时间会更长,成本也会增加。
本指南首先定义一些访问模式。然后,它引入了一个数据模型来实现这些访问模式。最后,本指南详细讨论了几个查询,以验证设计的数据模型是否满足所有定义的访问模式。
- 139 次浏览
【数据建模】设计一个DynamoDB数据模型,用于管理图形化的层次关系 -- 定义访问模式
视频号
微信公众号
知识星球
作为最佳实践,首先定义支持业务案例的访问模式。然后进行数据建模以支持这些访问模式。在定义访问模式之前,请查看本指南示例中使用的汽车零部件层次结构树。
使用示例树
绘制汽车组件的示例树可以帮助您映射它们之间的关系。下图显示了具有四个级别的依赖关系图。CM1是示例汽车本身的顶级组件。它有两个子组件用于两个示例电池,CM2和CM3。每个电池有两个子组件,即模块。CM2具有模块CM4和CM5,而CM3具有模块CM6和CM7。每个模块都有几个子组件,即单元。CM4模块有两个单元,CM8和CM9。CM5具有一个单元CM10。CM6和CM7还没有任何相关联的细胞。

本指南将使用此树及其组件标识符作为参考。顶部组件将被称为父组件,子组件将被称作子组件。例如,顶部组件CM1是CM2和CM3的父组件。CM2是CM4和CM5的父代。这是父子关系的图表。
从树中,您可以看到组件的完整依赖关系图。例如,CM8依赖于CM4,CM4依赖于CM2,CM2依赖于CM1。树将完整的依赖关系图定义为路径。路径描述了两件事:
- 依赖关系图
- 树中的位置
CM8从上到下的路径是CM1|CM2|CM4|CM8。
本指南的示例用例具有以下访问模式,用于管理不同汽车组件之间的关系。
|
访问模式 |
|
|---|---|
|
1 |
作为一个用户,我想检索父组件ID的所有直接子组件(向下一级)。 |
|
2 |
作为一个用户,我想检索组件ID的所有子(下级)组件的递归列表。 |
|
3 |
作为用户,我希望看到组件的祖先。 |
使用汽车组件示例,每个组件(汽车、电池、模块和电池)都具有组件ID作为唯一标识符。在这种情况下,如果使用电池组件ID进行查询,则直接的子级是模块。递归列表显示模块和单元。对于电池来说,祖先是模块、电池和汽车。
要为您的用例定义必要的访问模式,请彻底分析业务需求。在您有完整的业务需求之前,不要开始数据建模。
- 78 次浏览
【数据建模】设计一个DynamoDB数据模型,用于管理图形化的层次关系 -- 最佳实践
视频号
微信公众号
知识星球
考虑使用以下DynamoDB设计最佳实践。
- 分区键设计–使用高基数分区键来均匀分配负载。
- 相邻列表设计模式–使用此设计模式管理一对多和多对多关系。
- 稀疏索引–对GSI使用稀疏索引。创建GSI时,可以指定分区键和排序键(可选)。只有基表中包含相应GSI分区键的项才会出现在稀疏索引中。这有助于保持GSI较小。
- 索引重载–使用相同的GSI为各种类型的项目编制索引。
- GSI写分片——明智地分片以跨分区分发数据,实现高效、快速的查询。
- 大型条目–仅将元数据存储在表中,将blob保存在AmazonS3中,并将引用保存在DynamoDB中。将大型项目分解为多个项目,并使用排序键高效地进行索引。
有关更多设计最佳实践,请参阅AmazonDynamoDB开发人员指南。
- 52 次浏览
【数据建模】设计一个DynamoDB数据模型,用于管理图形化的层次关系 -- 查询分层数据
视频号
微信公众号
知识星球
您已经定义了访问模式,并设计了一个DynamoDB数据模型来实现访问模式。现在,您可以在DynamoDB数据库中查询分层数据。作为节省成本和确保性能的最佳实践,以下示例仅使用查询操作而不使用SCAN。
如何查找组件的祖先
要查找CM8组件的祖先(父母、祖父母、曾祖父母等),请使用ComponentId=“CM8”查询基表。查询将返回以下记录。
|
ComponentId |
ParentId |
GraphId |
Path |
|---|---|---|---|
|
CM8 |
CM4 |
CM1#1 |
CM1|CM2|CM4|CM8 |
若要减小结果数据的大小,可以使用投影表达式仅返回Path属性。
|
Path |
|---|
|
CM1|CM2|CM4|CM8 |
现在,使用管道(“|”)分割路径,并获取第一个N-1组件以获取祖先。
查询结果:CM8的祖先是CM1、CM2、CM4。
如何查找组件的直接子级
要获取给定组件CM2的所有直接子级或下游一级组件,请使用ParentId=“CM2”查询GSI1。查询将返回以下记录。
|
ParentId |
ComponentId |
|---|---|
|
CM2 |
CM4 CM5 |
查询结果:CM2的直接子级是CM4和CM5。
如何使用顶级组件查找所有下游子组件
要获取顶级组件CM1的所有子组件或下游组件。使用GraphId=“CM1#1”和begins_with(“Path”,“CM1|”)查询GSI2,并使用带有ComponentId的投影表达式。它将返回与该树相关的所有组件。
此示例有一棵树,其中CM1是顶部组件。实际上,在同一个表中可能有数百万个顶级组件。
|
GraphId |
ComponentId |
|---|---|
|
CM1#1 |
CM2 CM3 CM4 CM5 CM8 CM9 CM10 CM6 CM7 |
查询结果:CM1的所有下游组件均为CM2、CM3、CM4、CM5、CM8、CM9、CM10、CM6和CM7。
如何使用中级组件查找所有下游子组件
要递归获取给定组件CM2的所有子组件或下游组件,您有两个选项。您可以逐层递归查询,也可以查询GSI2索引。
选项1
逐级递归地查询GSI1,直到到达子组件的最后一级。
1.使用ParentId=“CM2”查询GSI1。它将返回以下记录。
|
ParentId |
ComponentId |
|---|---|
|
CM2 |
CM4 CM5 |
2.再次使用ParentId=“CM4”查询GSI1。它将返回以下记录。
|
ParentId |
ComponentId |
|---|---|
|
CM4 |
CM8 CM9 |
3.再次使用ParentId=“CM5”查询GSI1。它将返回以下记录。
|
ParentId |
ComponentId |
|---|---|
|
CM5 |
CM10 |
继续循环:查询每个ComponentId,直到达到最后一级。当使用ParentId=“<ComponentId>”的查询不返回任何结果时,上一个结果来自树的最后一级。
4.合并所有结果。结果=[CM4,CM5]+[CM8,CM9]+[CM10]=[CM4、CM5、CM8、CM9、CM10]
查询结果:CM2的所有下游组件均为CM4、CM5、CM8、CM9和CM10。
选项2
查询GSI2,它存储顶级组件(汽车或CM1)的分层树。
1.首先,找到CM2的顶级组件或顶级祖先和路径。为此,使用ComponentId=“CM2”查询基表,以在层次树中查找该组件的路径。选择GraphId和Path属性。查询将返回以下记录。
|
GraphId |
Path |
|---|---|
|
CM1#1 |
CM1|CM2 |
2.使用GraphId=“CM1#1”AND BEGINS_WITH(“Path”,“CM1|CM2|”)查询GSI2。查询将返回以下结果。
|
GraphId |
Path |
ComponentId |
|---|---|---|
|
CM1#1 |
CM1|CM2|CM4 CM1|CM2|CM5 CM1|CM2|CM4|CM8 CM1|CM2|CM4|CM9 CM1|CM2|CM5|CM10 |
CM4 CM5 CM8 CM9 CM10 |
3.选择ComponentId属性以返回CM2的所有子组件。
查询结果:CM2的所有子组件均为CM4、CM5、CM8、CM9和CM10。
- 104 次浏览
【数据建模】设计一个DynamoDB数据模型,用于管理图形化的层次关系 -- 设计数据模型
视频号
微信公众号
知识星球
本节详细介绍分层数据模型设计概念,从设计原则、术语、原则开始,并定义用于在DynamoDB中存储组件数据的必要数据库属性。然后讨论了基表和全局二级索引(GSI)配置以及关键设计概念。最后,您可以看到在所有可用的汽车组件都存储在DynamoDB表中之后,基础表和GSI是什么样子的。
设计原则
作为最佳实践,最好定义设计原则。以下原则适用于本指南的用例。
- 设计一个可扩展和健壮的系统。确保性能足够高,延迟足够低,以符合数据检索服务级别协议(SLA)。
- 通过确保系统支持所有已识别的数据访问模式,遵守所有业务要求。
- 通过使用高效的写、读和数据存储机制,降低运营成本。
- 通过创建尽可能少的表和GSI,降低维护和操作复杂性。
- 通过分离实体项并应用行级细粒度访问模式和其他常见安全措施,确保数据安全性和可访问性。
术语
本指南使用以下术语。
- 分区键维护表内的数据分区和数据分片。
- 排序键支持分区内细粒度的项目级数据访问。
- 主键是DynamoDB中的唯一标识符。主键由分区键和排序键组成。
- 基本表是存储数据的主要DynamoDB表。
- 全局辅助索引(GSI)用于索引目的,以提供更快的数据查找。
- 在GSI中,分区键和排序键可能与基表中的键不同。
- 一次最多可以为单个DynamoDB表创建20个GSI。最大数量是AWS服务软限制。如果你需要更多的GSI,你可以要求增加。
- 每个GSI单独存储数据。您必须分别分配读和写单元,这会产生额外的成本。
- 每个GSI可以随时创建或销毁。创建或销毁GSI不会影响基表。
- 我们建议使用GSI而不是本地辅助索引(LSI)进行索引。
设计原则
使用以下方法设计了示例用例数据模型:
- 要有效地管理不同的实体,请使用DynamoDB单表设计模式。这意味着整个系统将有一个用于存储所有类型数据的DynamoDB表。
- 单表设计使您能够更灵活地维护一对多和多对多数据关系,而无需在多个DynamicDB表中复制数据。
- 使用单个表可降低维护复杂性和成本。
- 要了解有关单表设计的更多信息,请参阅DynamoDB文档中的“使用AmazonDynamoDB创建单表设计”博客文章和管理多对多关系的最佳实践。
- 为了在表分区内实现统一的数据分布,请使用更细粒度和分布式的属性作为分区键。有关更多信息,请参阅设计分区键以分配工作负载。
- 为了更快、更高效地查询并克服热分区问题,请使用适当的GSI Sharding跨分区分发数据。本指南中的示例对GSI2分区密钥使用随机分区。
- 对GSI1和GSI2中具有不同排序键的多个实体使用相同的分区键。
- 使用复合排序键。
- 使用两个GSI:
- GSI1,用于使用ParentID索引数据,以便您可以使用父ID进行查询
- GSI2,用于使用GraphId索引数据,以便您可以使用组件ID查询所有下级组件
- 仅使用分区键查询基表GSI1和GSI2。如果您不知道分区键,则无法执行数据查询。
- 我们建议在没有有力有效案例的情况下,不要在DynamoDB中使用SCAN操作。SCAN操作非常昂贵。
- 如果您必须经常使用SCAN操作,我们建议您重新设计数据模型。
- 仅限将数据插入基表。然后,GSI将以最终一致的方式自动同步。
定义属性
下一步是定义在DynamoDB表中存储组件信息所需的属性。每个属性用于在实体中存储键值对数据。实体可以包含任意数量的属性。我们建议使用较短的名称作为属性名称,因为在读取单元中将考虑属性的长度(字节大小)。对于本指南中的示例,定义了以下属性。
|
Attribute name |
Description |
|---|---|
|
|
每个组件的唯一标识符(例如,CM1、CM2)。 |
|
|
父组件ID。例如,CM2的ParentID是CM1。 |
|
|
图形或树标识符。此示例有一棵树,其中顶部组件是CM1。实际上,可以有多棵树。 |
|
|
图中组件的路径。例如,CM8的路径是CM1|CM2|CM4|CM8。 |
设计基表、GSI和键
定义基表和全局辅助索引(GSI)的分区键。
- 遵循键设计最佳实践,在本例中使用ComponentId作为基表的分区键。由于它是唯一的,ComponentId可以提供粒度。DynamoDB使用分区键的哈希值来确定物理存储数据的分区。唯一的组件ID生成一个不同的哈希值,这可以促进表内数据的分布。可以使用ComponentId分区键查询基表。
- 要查找组件的直接子级,请创建一个GSI,其中ParentId是分区键,ComponentId是排序键。您可以使用ParentId作为分区键来查询此GSI。
- 要查找组件的所有递归子级,请创建一个GSI,其中GraphId是分区键,Path是排序键。您可以通过使用GraphId作为分区键和排序键上的BEGINS_WITH(Path,“$Path”)运算符来查询此GSI。
DynamoDB表键配置
|
Partition key |
Sort key |
Mapping attributes |
|
|---|---|---|---|
|
Base table |
|
|
|
|
GSI1 |
|
|
|
|
GSI2 |
|
|
|
在表中存储组件
下一步是将每个组件存储在DynamoDB基表中。从示例树中插入所有组件后,将得到一个基本表,如下所示。
|
ComponentId |
ParentId |
GraphId |
Path |
|---|---|---|---|
|
CM1 |
CM1#1 |
CM1 |
|
|
CM2 |
CM1 |
CM1#1 |
CM1|CM2 |
|
CM3 |
CM1 |
CM1#1 |
CM1|CM3 |
|
CM4 |
CM2 |
CM1#1 |
CM1|CM2|CM4 |
|
CM5 |
CM2 |
CM1#1 |
CM1|CM2|CM5 |
|
CM6 |
CM3 |
CM1#1 |
CM1|CM3|CM6 |
|
CM7 |
CM3 |
CM1#1 |
CM1|CM3|CM7 |
|
CM8 |
CM4 |
CM1#1 |
CM1|CM2|CM4|CM8 |
|
CM9 |
CM4 |
CM1#1 |
CM1|CM2|CM4|CM9 |
|
CM10 |
CM5 |
CM1#1 |
CM1|CM2|CM5|CM10 |
您可以使用此基表通过使用组件ID来查找组件的信息。
基表中的数据形成顶层组件(CM1)的层次树。要在DynamoDB中生成可扩展树,请在顶级组件ID上附加POST-FIX,例如#N。在本例中,CM1的GraphId为CM1#N,其中N是0–N范围内的随机数。N值是根据树的大小定义的,用于GSI中正确的数据分布。这种POST-FIX有助于避免热分区问题,它支持使用多个客户端并行运行查询,这有助于减少查询包含100多个组件的大树时的响应时间。
因为本例中的树很小,所以本例使用N=1。这将创建一个单独的分区CM1#1来存储整个树。如果使用N=5,它将创建五个分区来存储该树。在这种情况下,您必须查询所有五个分区以检索所有组件。然后,您必须合并所有数据以获得最终结果。
Path值是通过使用管道(|)运算符串联祖先来生成的。例如,从顶部开始的CM5路径是CM1|CM2|CM5。
GSI1索引
要检查组件的所有直接子级,需要使用ParentId作为分区键,使用ComponentId作为排序键来创建索引。以下数据透视表表示GSI1索引。您可以使用此索引通过使用父组件ID检索所有直接的子组件。例如,您可以了解汽车(CM1)中有多少电池可用,或者模块(CM4)中有哪些电池可用。
|
ParentId |
ComponentId |
|---|---|
|
CM1 |
CM2 CM3 |
|
CM2 |
CM4 CM5 |
|
CM3 |
CM6 CM7 |
|
CM4 |
CM8 CM9 |
|
CM5 |
CM10 |
GSI2索引
以下数据透视表表示GSI2索引。它使用GraphId作为分区键,Path作为排序键进行配置。使用GraphId和排序键(Path)上的begins_with操作,可以在树中找到组件的完整谱系。
|
GraphId |
Path |
ComponentId |
|---|---|---|
|
CM1#1 |
CM1 CM1|CM2 CM1|CM3 CM1|CM2|CM4 CM1|CM2|CM5 CM1|CM2|CM4|CM8 CM1|CM2|CM4|CM9 CM1|CM2|CM5|CM10 CM1|CM3|CM6 CM1|CM3|CM7 |
CM1 CM2 CM3 CM4 CM5 CM8 CM9 CM10 CM6 CM7 |
- 44 次浏览
【数据建模】设计一个DynamoDB数据模型,用于管理图形化的层次关系 --验证访问模式
视频号
微信公众号
知识星球
要验证数据模型,请使用前面定义的访问模式。
|
Question |
Base table/GSI |
Query |
|
|---|---|---|---|
|
1 |
作为用户,我希望检索父组件ID的所有直接子组件。 |
GSI1 |
(Find immediate children of a component.) |
|
2 |
作为用户,我希望检索组件ID的所有子组件的递归列表。 |
GSI1 or GSI2 |
GSI1: or GSI2: (Find all down-level child components using a top- level component. Find all down-level child components using a middle-level component.) |
|
3 |
作为用户,我希望看到组件的祖先。 |
Base table |
(Find ancestors of a component.) |
- 42 次浏览