
category
Meta的Llama-3、微软的Phi-3和Hugging Face的Zephyr在特定任务上的微调表现优于OpenAI的GPT-4!🤯
这是Predibase的微调指数的发现之一,该指数展示了我们从Lora Land实验中获得的经验。这是一个实时的基准测试,我们将用新的#开源基础模型和新任务进行更新。
微调指数有助于回答我们所有客户在#AI和#LLM采用过程中不断向我们提出的问题:
- -我应该微调哪个开源模型?
- -哪些任务从微调中受益最大?
- -培训和服务微调模型的成本是多少?
当前的微调指数包括我们Lora Land论文的所有结果,并将Llama-3、Phi-3和GPT-4o添加到组合中。
开发人员不再局限于像GPT-4这样昂贵的商业模型。Zephyr、Mistral和Llama等高性能开源LLM的兴起提供了一种有吸引力的替代方案,使组织能够降低成本并拥有模型IP。然而,开源模型可能达不到商业产品。这就是微调的作用所在。较小的开源模型可以通过微调的力量提供类似GPT的性能。
为了说明这一点,并帮助企业人工智能团队为其应用程序选择最佳的开源模型,我们进行了700多次LLM微调实验。我们的实验结果可在我们的Arxiv研究论文中获得,并在下面通过一系列互动图表分享。享受
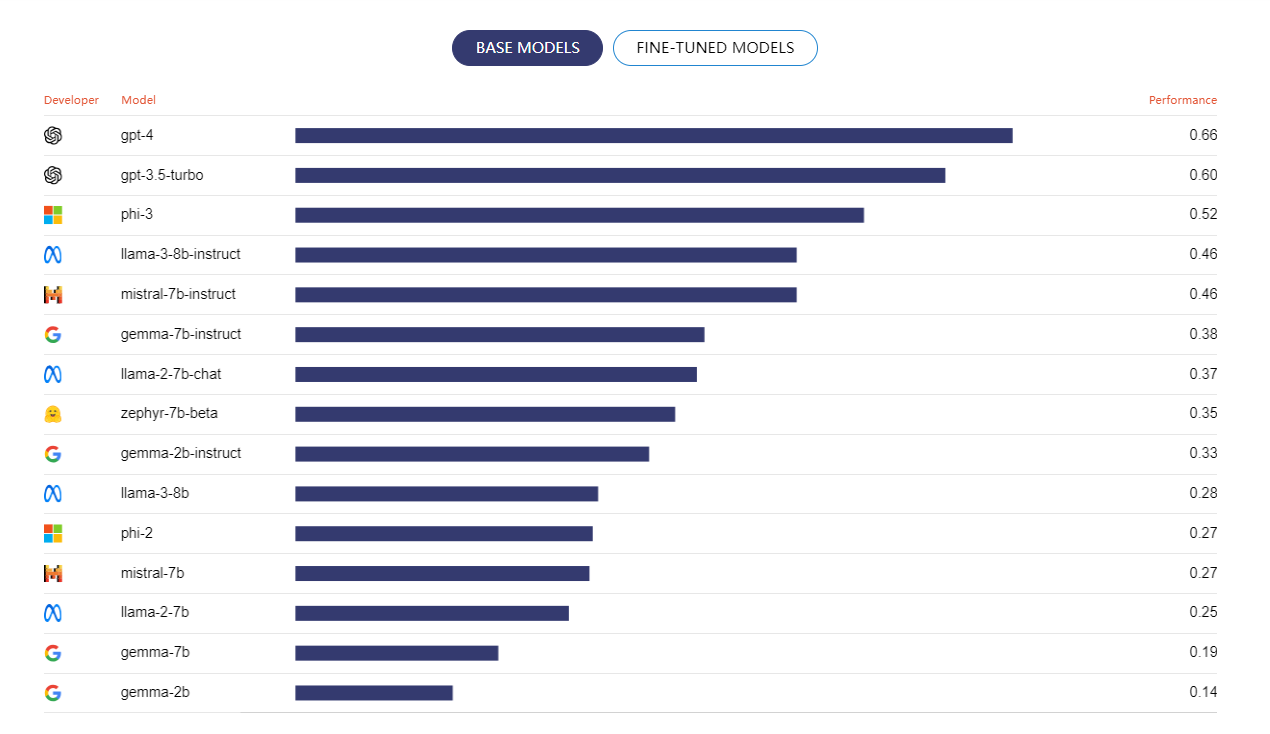
开源模型微调排行榜
微调排行榜显示了在31个不同任务中聚合的每个模型的性能。您可以通过选择顶部的基本或微调模型按钮来评估微调前后的性能。值得注意的是,大多数经过微调的开源模型都超过了GPT-4,其中Llama-3、Phi-3和Zephyr表现出了最强的性能。

关于报告
为什么?
我们听到的最常见的问题是:微调有效吗?我应该使用什么模型?通过这份报告,我们试图回答这些问题和其他问题,例如哪项任务最适合微调。我们还旨在为人工智能团队提供一个具有成本效益的框架,用于生产开源LLM。
什么
微调索引包含一系列交互式表格和图表,从我们的模型微调排行榜开始。排行榜将GPT-4的性能与我们在一系列任务中微调的流行开源模型进行了比较。我们包含了10个额外的关键发现,以帮助团队改进他们的微调工作。
怎样
我们使用13个最流行的开源模型和31个不同的数据集和任务分析了700多个微调实验。我们选择了最大参数为7B的模型,以确保任何组织都可以在低端GPU上训练模型。我们使用准确度得分、胭脂度量和HumanEval来评估性能。
关键要点
LoRA微调模型在专业任务上优于GPT-4
经过微调的模型在其特定领域内充当专家,在我们测试的85%的任务中超过了GPT-4的性能。平均而言,微调产生了25%-50%的令人印象深刻的改善。
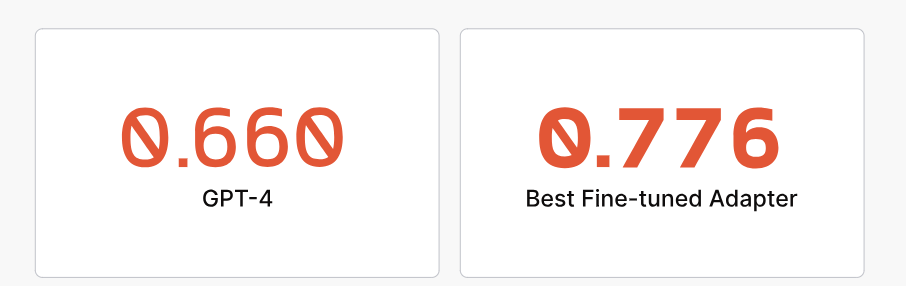
31个不同任务的平均模型质量
如下图所示,经过微调的模型在几乎所有任务上的表现都远远优于GPT-4。详细分析部分提供了按任务对单个模型性能的更深入了解。
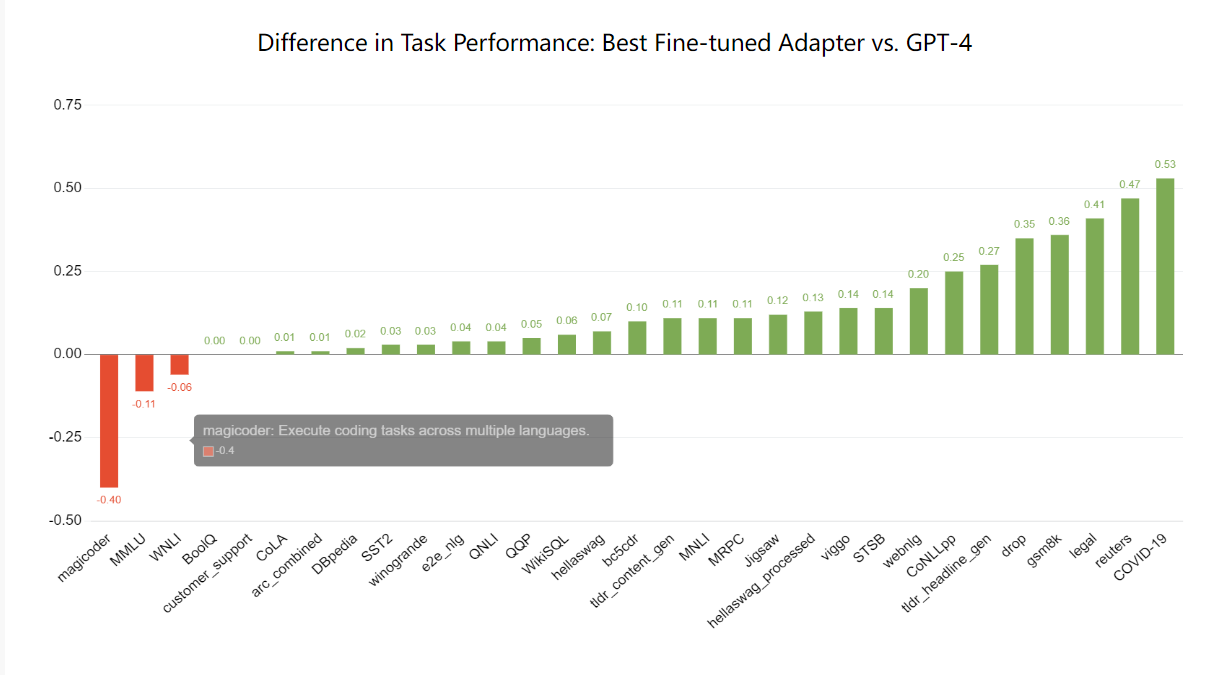
任务性能差异:最佳微调适配器与GPT-4
LoRA微调型号的训练和服务既快捷又便宜
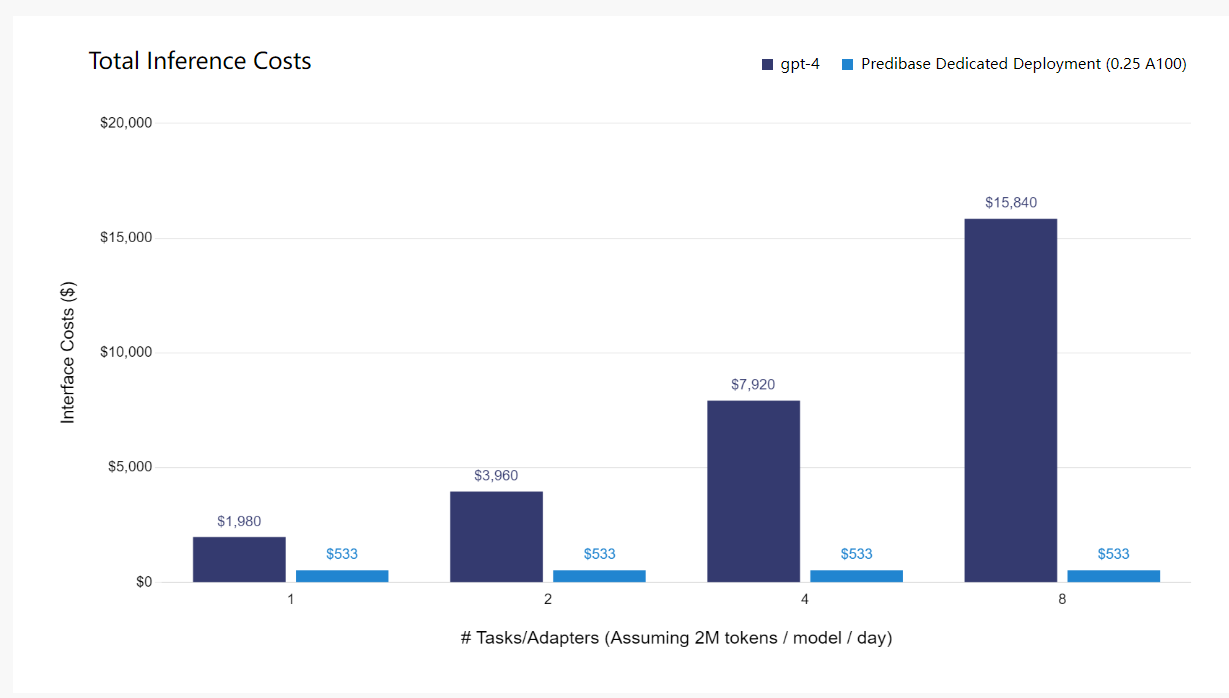
作为基准测试的一部分,我们推出了LoRA Land,这是一款交互式网络应用程序,允许用户查询25个以上性能优于GPT-4的微调Mistral适配器。LoRA Land模型在Predibase上进行了微调,每个售价8美元,并在带有开源LoRAX的单个GPU上提供服务。
LoRA Land使我们能够在生产环境中对服务于LoRA微调型号的性能和成本进行基准测试。如下表所示,在Predibase上提供微调LLM不仅比GPT-4便宜得多,而且在扩展到许多型号和用户时,我们提供了更快的速度,对请求时间几乎没有影响。您可以在Arxiv论文中阅读更多关于我们分析的内容。GPT-4基准取自人工分析。
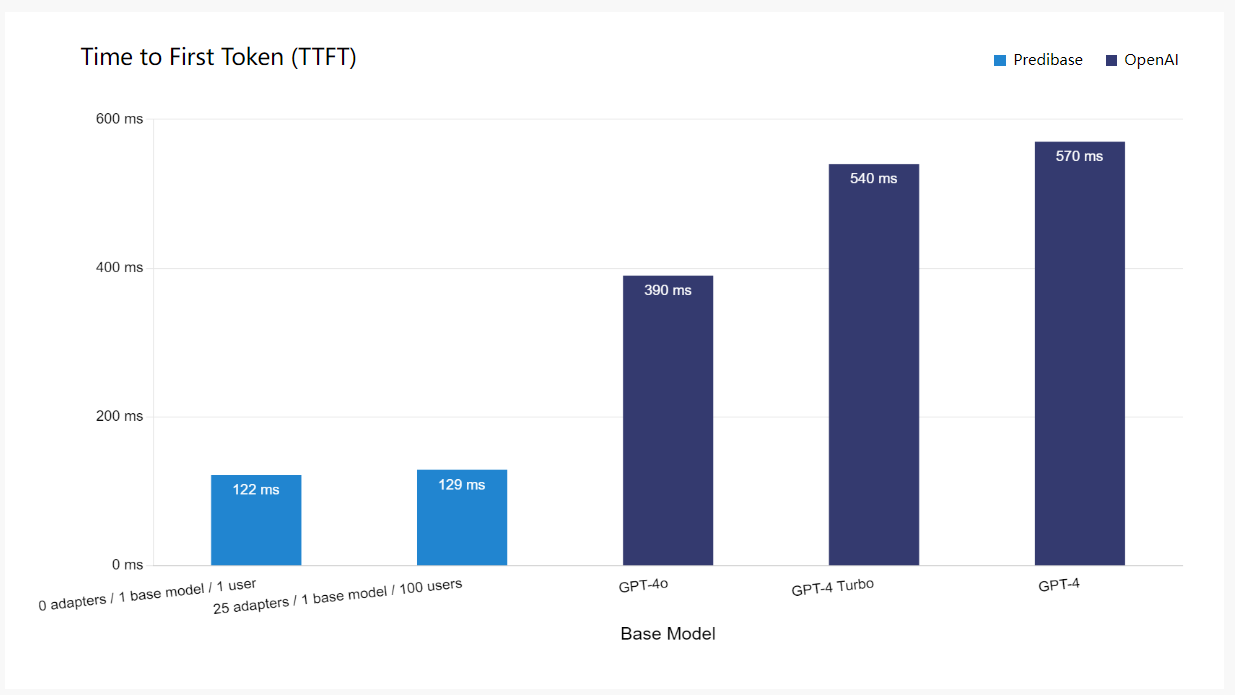
如上所述,我们还将GPT-4的成本与在使用开源LoRAX和Predibase的专用部署上为您自己的微调适配器提供服务的成本进行了比较。LoRAX使您能够在单个GPU上经济高效地为多个适配器提供服务,从而可以使用一系列经过微调的特定任务模型构建自己的GPT-4。
选择正确的任务进行微调
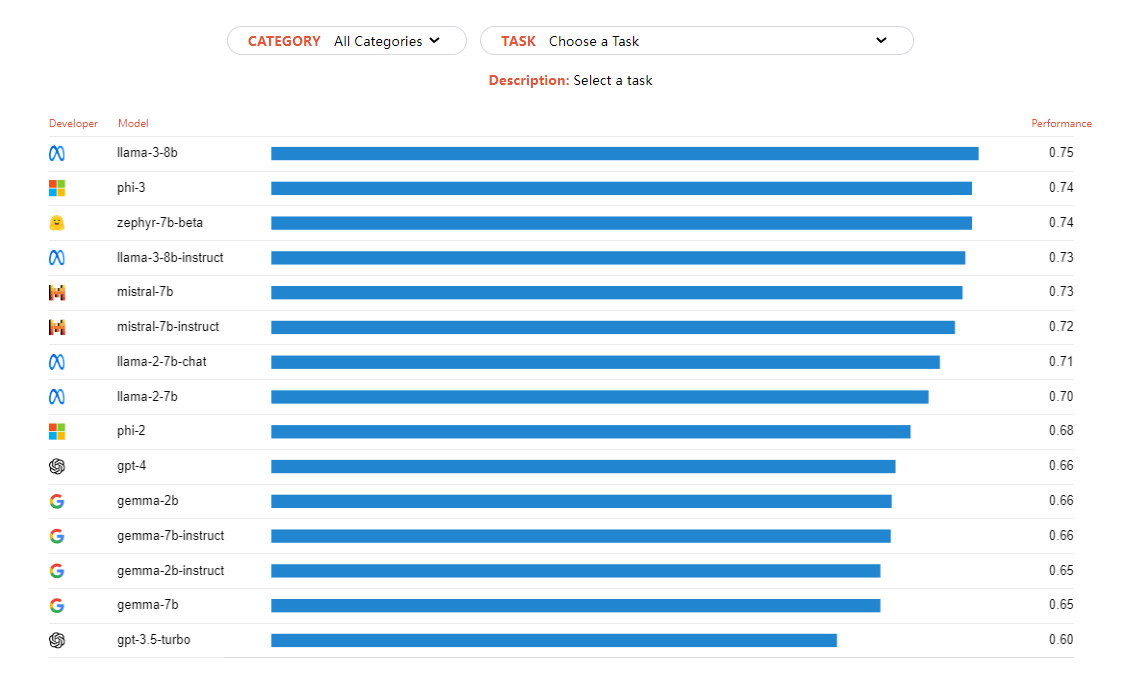
微调任务排行榜
任务排行榜显示所选任务的每个微调和GPT模型的性能。使用此图表可以确定哪种模型最适合特定任务。值得注意的是,大多数经过微调的开源机型都超过了GPT-4,Llama-3b系列最常表现出最强的性能。
专业任务是LoRA微调的理想选择
我们的分析表明,在广泛的任务中击败GPT-4更为困难。例如,以下执行较差的任务范围非常广:为Python、Java和R等多种编程语言生成代码;回答涉及数十个主题的多项选择题。
相反,我们在微调开源LLM以执行重点狭窄或特定领域的任务时取得了巨大成功,例如法律合同审查、医疗文本分类和特定领域的代码生成,如公司的内部代码库。因此,与通用用例相比,在针对特定任务进行微调时,它需要更少的努力才能优于GPT-4。
GPT-4和按类别划分的性能最高的微调模型之间的差异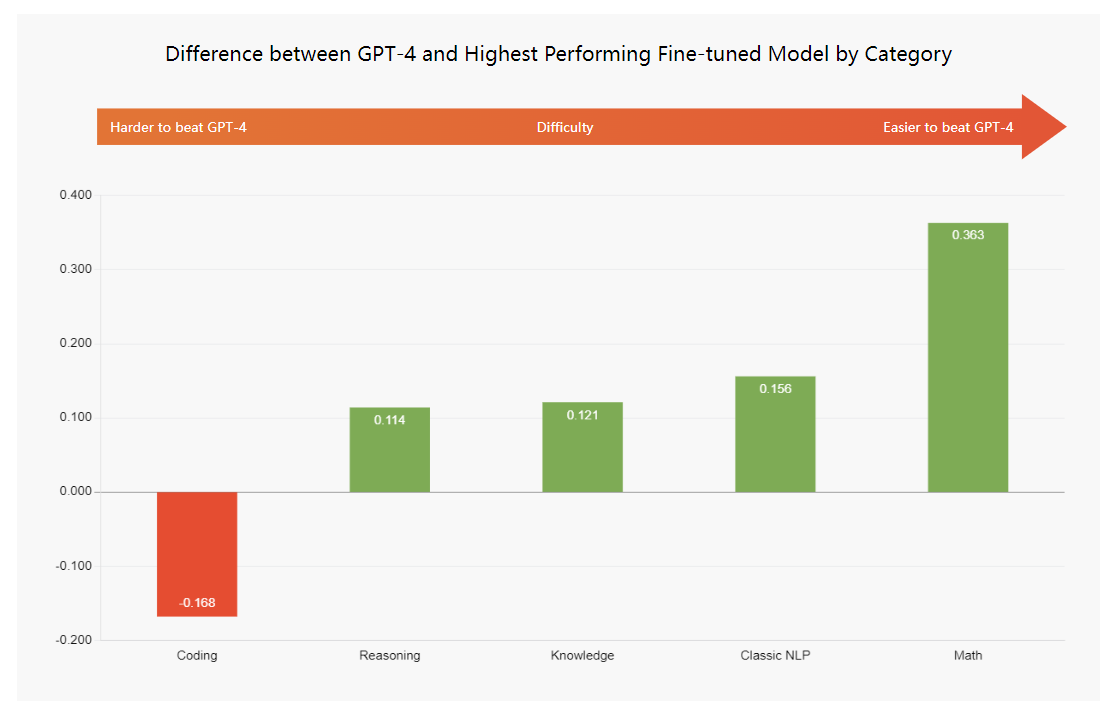
选择最佳基础模型进行微调
在选择基本模型时,重要的是要考虑任务级别和许多任务的总体性能。具体来说,当使用LoRAX等开源框架时,这一点很重要,因为LoRAX允许您在单个基础模型上提供多个微调适配器。从一个模型中获得最大收益是理想的。
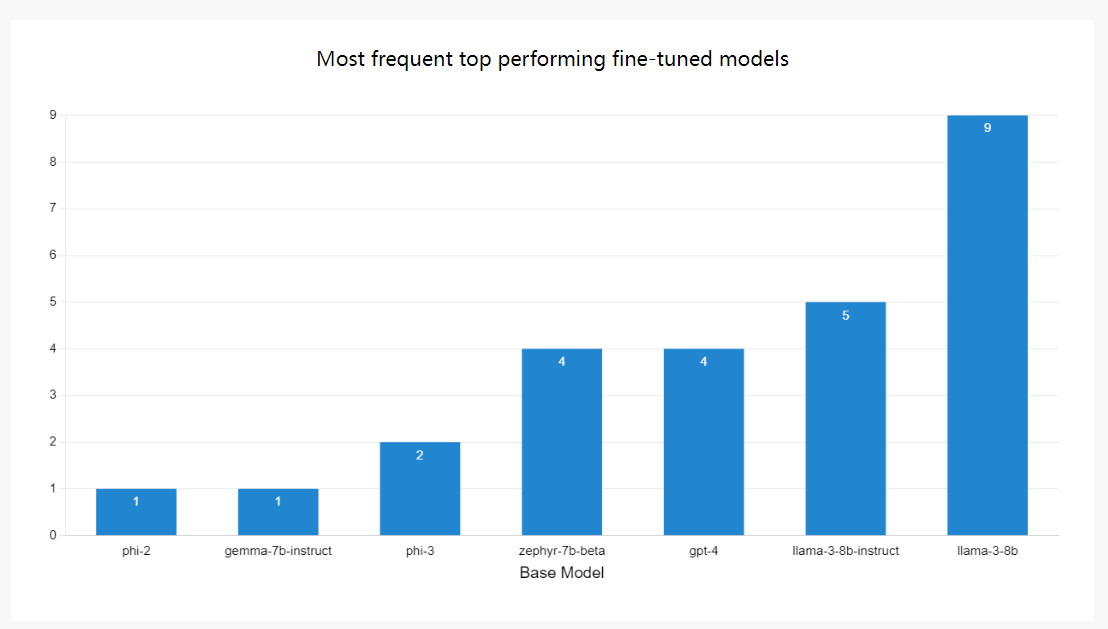
Llama车型领先
在架构方面,我们的研究结果表明,Llama系列平均领先,Phi、Zephyr和Mistral紧随其后。有趣的是,Mistral部分建立在Llama建筑上,Zephyr是最初Mistral Instruction模型的衍生物。这表明Llama和Mistral模型系列非常适合适应较小的特定任务的工作。
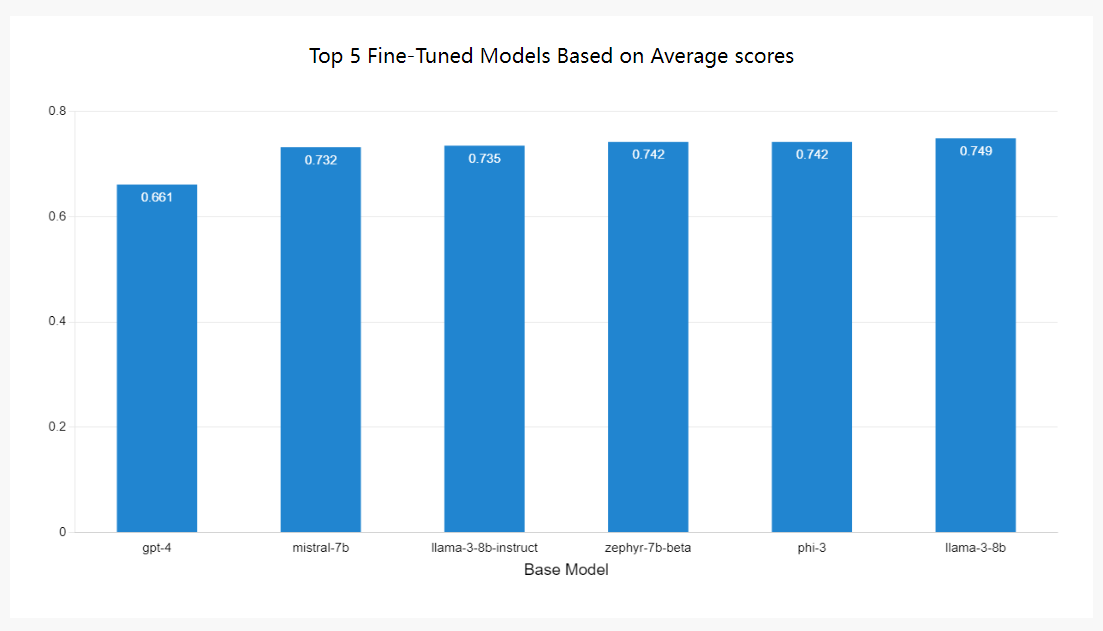
基于平均分数的前5个微调模型
此外,从最高性能的频率来看,Llama-3系列脱颖而出,巩固了其作为微调领先架构的地位。
最常见的性能最佳的微调型号
选择要进行微调的数据
专用数据集可产生最佳结果
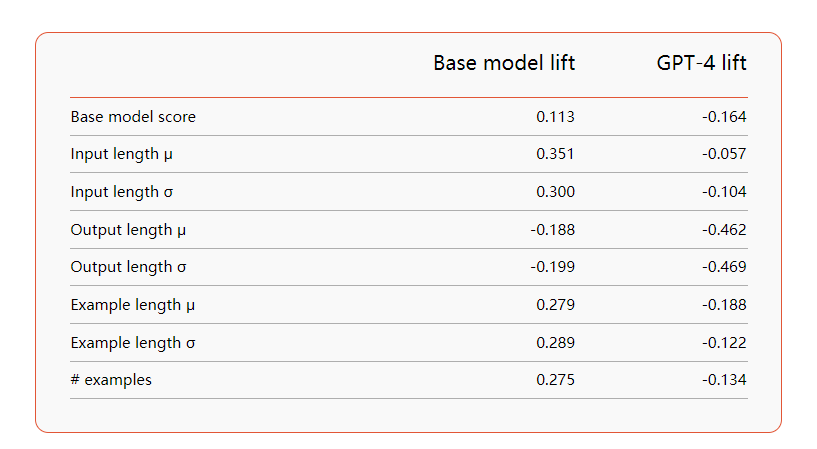
在我们的评估过程中,我们探讨了数据复杂性对微调结果的影响,并发现了一些适度的相关性。当考察基本模型升力时,我们发现输入长度呈正相关。相反,当观察GPT-4的升力时,我们发现与输出长度呈中度负相关。这表明,使用微调的适配器,更窄、更容易的任务更有可能取得成功。
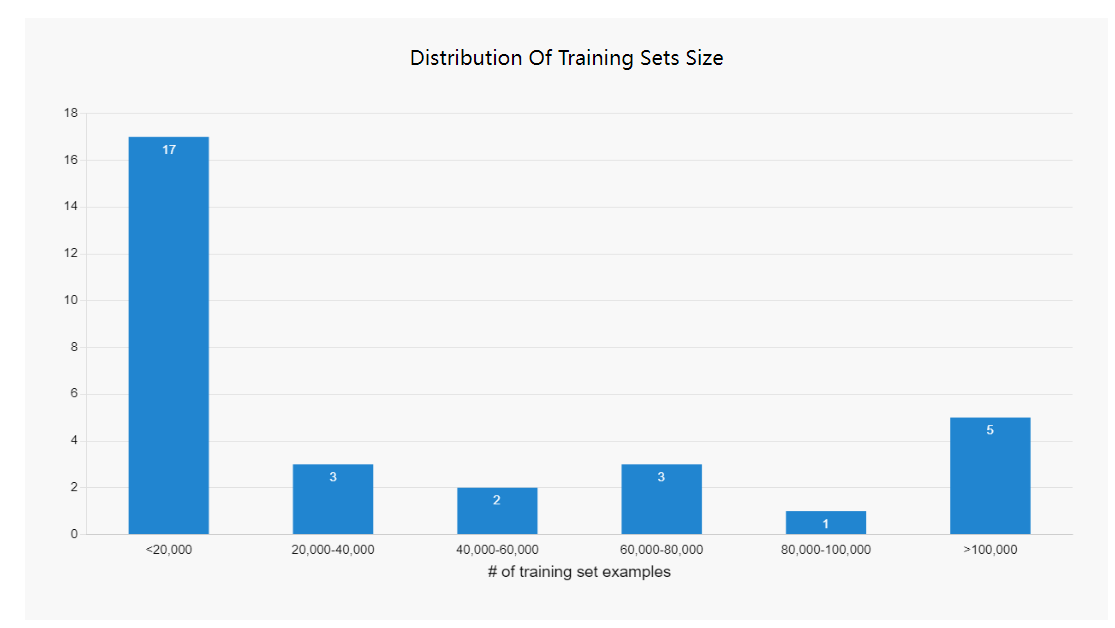
您只需要小数据:<10000个示例
与初始模型训练不同,微调可以通过较少的示例来有效。尽管我们的一些数据集是广泛的,但大多数数据集包含的例子不到20000个。事实上,超过40%的数据点少于10000个。
了解更多信息
我们希望您喜欢微调索引,并在训练自己的特定任务LLM时发现它很有帮助。我们计划用新型号进行更新,所以请定期查看。
所有型号都经过微调,价格不到8美元,并使用Predibase和LoRAX进行生产。以下是一些资源,可以帮助您微调性能优于GPT-4的模型。
https://arxiv.org/abs/2405.00732
- 登录 发表评论
- 30 次浏览
最新内容
- 1 day 13 hours ago
- 1 month 2 weeks ago
- 5 months 2 weeks ago
- 5 months 2 weeks ago
- 5 months 2 weeks ago
- 5 months 2 weeks ago
- 5 months 2 weeks ago
- 5 months 2 weeks ago
- 5 months 2 weeks ago
- 5 months 2 weeks ago