
Chinese, Simplified
category
本指南旨在为用户提供大型语言模型(LLM)应用程序的全面资源和学习,涵盖以下主题:
引言:
- LLM概述
- 提示工程
- 微调
- 评估指标
- 总结评估
- 建议和学习
- 安全
- 实验
- 快速工程
- 微调
LLM概述
大型语言模型(LLM)是使用大型文本语料库训练的深度学习模型,用于生成文本。它们基于自回归模型的思想,在该模型中,它们经过训练,可以在给定前一个单词的情况下预测下一个单词(或最可能的单词)。LLM可用于处理大量文本并学习人类语言的结构和语法。
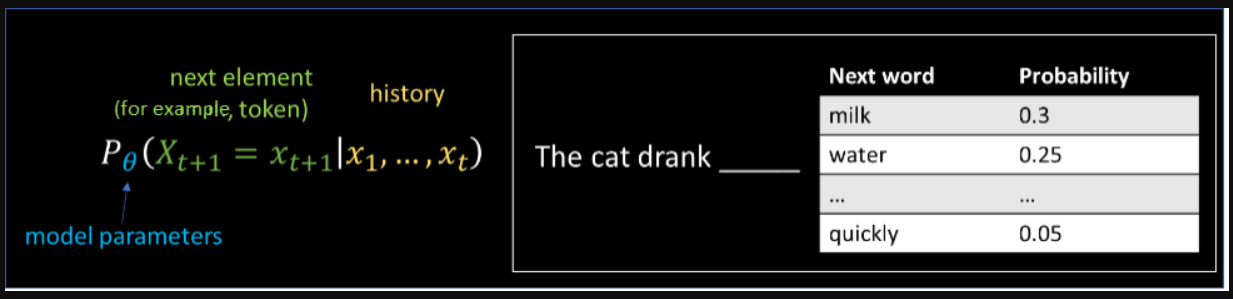
LLM模型
法学硕士的发展是一个渐进的过程,特别是在过去的十年里。第一批LLM相对较小,只能执行简单的语言任务。然而,随着深度神经网络的进步,更大、更强大的LLM被创造出来。下图显示了过去几年引入的LLM及其规模的示例。
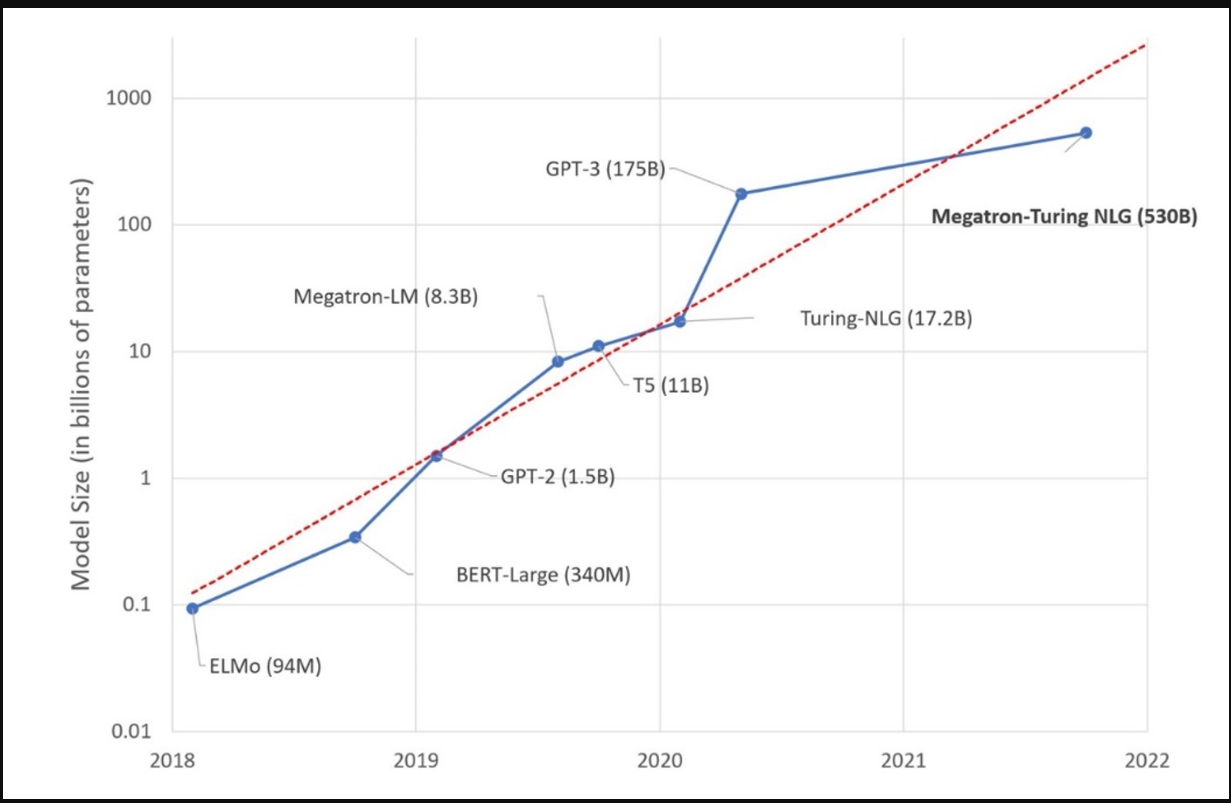
LLM趋势
2020年发布的GPT-3(生成预训练变压器3)模型标志着LLM发展的一个重要里程碑。GPT-3还代表了一系列不同尺寸的型号。GPT3展示了生成连贯和令人信服的文本的能力,这些文本很难与人类编写的文本区分开来。
与其他基础模型一样,GPT-3等LLM以自监督/无监督的方式进行训练,可以适应执行不同的任务和/或应用程序。这种训练过程与传统的机器学习模型形成鲜明对比,在传统机器学习模型中,使用标记数据为不同的任务训练不同的模型。例如,LLM可用于为聊天机器人、语言翻译和内容创建生成文本。它们还可以用于分析和总结大量文本数据,如新闻文章或社交媒体帖子。此外,LLM可用于根据自然语言请求编写编程代码。
调整LLM以适应不同的任务或应用可以通过两种方式完成:通过即时工程或微调进行上下文学习。无论使用哪种方法,开发人员和数据科学家都应该学习并采用新技术。
- 登录 发表评论
- 123 次浏览
发布日期
星期日, 十月 6, 2024 - 10:46
最后修改
星期日, 十月 6, 2024 - 10:46
Tags
Article
最新内容
- 1 week 3 days ago
- 2 weeks 4 days ago
- 3 weeks 1 day ago
- 2 months 1 week ago
- 6 months ago
- 6 months ago
- 6 months ago
- 6 months ago
- 6 months ago
- 6 months ago