
介绍
作为一名数据工程师,在使用Apache Spark准备和转换数据时,我们经常会要求对数据湖中文件中的某些列数据进行加密、解密、屏蔽或匿名处理。Spark的可扩展性特性使我们能够利用非Spark原生的库。其中一个库是Microsoft Presidio,它为私人实体提供快速识别和匿名模块,包括信用卡号、姓名、位置、社会安全号码、比特币钱包、美国电话号码、财务数据等文本。它有助于在多个平台上实现全自动化和半自动化的PII(个人身份信息)去识别和匿名化流程。
在这篇博客文章中,我将逐步演示如何下载和使用这个库来满足Azure Synapse Analytics的Spark池的上述要求。
做好准备
Microsoft Presidio是微软的一个开源库,可以与Spark一起使用,以确保对私人和敏感数据进行正确的管理和治理。它主要提供两个模块,用于快速识别的分析器模块和用于匿名化文本中的私人实体的匿名化模块,如信用卡号、姓名、位置、社会安全号码、比特币钱包、美国电话号码、金融数据等。
Presidio分析仪
Presidio分析器是一种基于Python的服务,用于检测文本中的PII实体。在分析过程中,它运行一组不同的PII识别器,每个识别器负责使用不同的机制检测一个或多个PII实体。它附带了一组预定义的识别器,但可以很容易地使用其他类型的自定义识别器进行扩展。预定义和自定义识别器利用正则表达式、命名实体识别(NER)和其他类型的逻辑来检测非结构化文本中的PII。

You can download this library from here by clicking on “Download files” under Navigation on the left of the page: https://pypi.org/project/presidio-analyzer/
Presidio匿名器(anonymizer)
Presidio匿名器是一个基于Python的模块,用于匿名检测到的具有所需值的PII文本实体。Presidio匿名器通过应用不同的运算符来支持匿名化和去匿名化。运算符是内置的文本操作类,可以像自定义分析器一样轻松扩展。它同时包含匿名者和匿名者:
- 匿名器用于通过应用某个运算符(例如,replace、mask、redact、encrypt)将PII实体文本替换为其他值
- 匿名化器用于恢复匿名化操作。(例如解密加密的文本)。

This library includes several built-in operators.
Step 1 - You can download this library from here by clicking on “Download files” under Navigation on the left of the page: https://pypi.org/project/presidio-anonymizer/
|
Additionally, it also contains, Presidio Image Redactor module as well, which is again a Python based module and used for detecting and redacting PII text entities in images. You can learn more about it here: https://microsoft.github.io/presidio/image-redactor/ |
Presidio uses an NLP engine which is an open-source model (the en_core_web_lg model from spaCy), however it can be customized to leverage other NLP engines as well, either public or proprietary. You can download this default NLP engine library from here:
https://spacy.io/models/en#en_core_web_lg
https://github.com/explosion/spacy-models/releases/tag/en_core_web_lg-3.4.0
Step 2 - Once you have downloaded all three libraries you can upload them to Synapse workspace, as documented here (https://docs.microsoft.com/en-us/azure/synapse-analytics/spark/apache-spark-manage-workspace-package...) and shown in the image below:
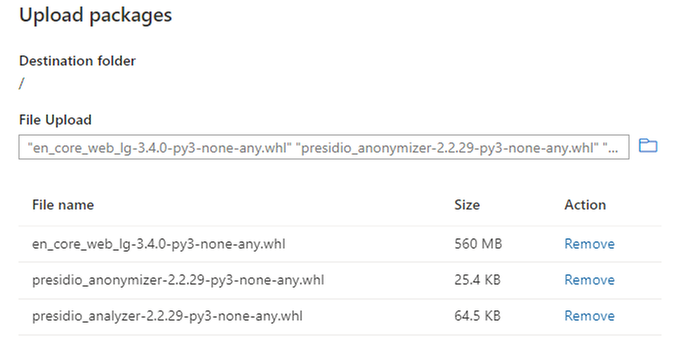
Figure 1 - Upload Libraries to Synapse Workspace
Given that NLP engine library is slightly bigger in size, you might have to wait a couple of minutes for the upload to complete. Once successfully uploaded, you will see a “Succeeded” status message for each of these libraries, as shown below:

Figure 2 - Required libraries uploaded to Synapse Workspace
Step 3 - Next, you have to apply these libraries from the Synapse workspace to the Spark pool where you are going to use it. Here are the instructions on how to do that and the screenshot below shows how it looks:
https://docs.microsoft.com/en-us/azure/synapse-analytics/spark/apache-spark-manage-pool-packages
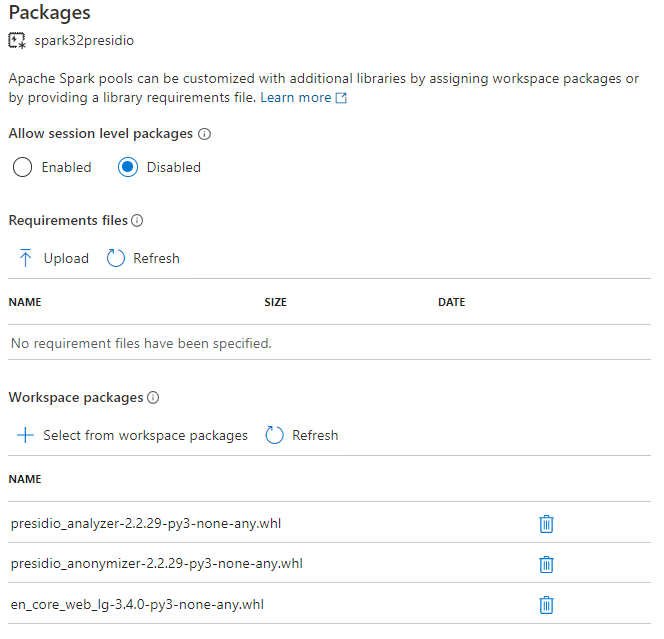
Figure 3 - Applying libraries to Synapse Spark pool
一旦点击“应用”,Synapse将触发一个系统作业,在选定的Spark池上安装和缓存指定的库。此过程有助于减少整个会话启动时间。一旦此系统作业成功完成,所有新会话都将获取更新的池库。
把所有这些放在一起
步骤1-首先,我们需要导入我们刚刚应用到Spark池的相关类/模块(以及其他现有库中的其他相关类/模)。
from presidio_analyzer import AnalyzerEngine, PatternRecognizer, EntityRecognizer, Pattern, RecognizerResult
from presidio_anonymizer import AnonymizerEngine
from presidio_anonymizer.entities import OperatorConfig
from pyspark.sql.types import StringType
from pyspark.sql.functions import input_file_name, regexp_replace
from pyspark.sql.functions import col, pandas_udf
import pandas as pd
Presidio分析仪
步骤2-接下来,您可以使用分析器模块来检测文本中的PII实体。下面是一个在给定文本中检测电话号码的示例。
# Set up the engine, loads the NLP module (spaCy model by default) and other PII recognizers
analyzer = AnalyzerEngine()
# Call analyzer to get results
results = analyzer.analyze(text="My phone number is 212-555-5555",
entities=["PHONE_NUMBER"],
language='en')
print(results)
As you can see, it detected the phone number which starts at position 19 and ends at position 31 with a score of 75%:

In addition to the phone number entity, which we used earlier, you can use any of the other built-in entities, as below, or use custom developed entities:

For example, the next code uses two entities Person and Phone Number to detect the name of the person and phone number in the given text:
# Set up the engine, loads the NLP module (spaCy model by default) and other PII recognizers
analyzer = AnalyzerEngine()
# Call analyzer to get results
results = analyzer.analyze(text="My name is David and my number is 212-555-1234",
entities=["PERSON", "PHONE_NUMBER"],
language='en')
print(results)

Presidio匿名器
步骤3-使用分析器识别具有私人或敏感数据的文本后,可以使用匿名器类使用不同的运算符对其进行匿名。
匿名示例
以下是通过使用replace运算符对已识别的敏感数据进行匿名化的示例。在这个例子中,为了简单起见,我使用识别器结果作为硬编码值,但是您可以在运行时直接从分析器获得这些信息。
# Anonymization Example
from presidio_anonymizer import AnonymizerEngine
from presidio_anonymizer.entities import RecognizerResult, OperatorConfig
# Initialize the engine with logger.
engine = AnonymizerEngine()
# Invoke the anonymize function with the text,
# analyzer results (potentially coming from presidio-analyzer) and
# Operators to get the anonymization output:
result = engine.anonymize(
text="My name is Bond, James Bond",
analyzer_results=[
RecognizerResult(entity_type="PERSON", start=11, end=15, score=0.8),
RecognizerResult(entity_type="PERSON", start=17, end=27, score=0.8),
],
operators={"PERSON": OperatorConfig("replace", {"new_value": "<ANONYMIZED>"})},
)
print(result)

Figure 4 - Person name anonymized by using replace operator
加密示例
步骤4-下一个示例演示如何使用encrypt运算符对文本中已识别的敏感数据进行加密。同样,在这个例子中,为了简单起见,我使用识别器结果作为硬编码值,但是您可以在运行时直接从分析器获得这些信息。
此外,我对加密密钥进行了硬编码,但在您的情况下,您将从Azure KeyVault获得以下信息:
# Encryption Example
encryption_key = "WmZq4t7w!z%C&F)J" # in real world, this will come from Azure KeyVault
engine = AnonymizerEngine()
# Invoke the anonymize function with the text,
# analyzer results (potentially coming from presidio-analyzer)
# and an 'encrypt' operator to get an encrypted anonymization output:
anonymize_result = engine.anonymize(
text="My name is Bond, James Bond",
analyzer_results=[
RecognizerResult(entity_type="PERSON", start=11, end=15, score=0.8),
RecognizerResult(entity_type="PERSON", start=17, end=27, score=0.8),
],
operators={"PERSON": OperatorConfig("encrypt", {"key": encryption_key})},
)
anonymize_result

Figure 5 - Person name anonymized by using encrypt operator
解密示例
步骤5-与加密运算符加密已识别的私人和敏感数据一样,您可以使用解密运算符使用加密过程中使用的相同密钥解密已加密的私人数据。
# Decryption Example
# Initialize the engine:
engine = DeanonymizeEngine()
# Fetch the anonymized text from the result.
anonymized_text = anonymize_result.text
# Fetch the anonynized entities from the result.
anonymized_entities = anonymize_result.items
# Invoke the deanonymize function with the text, anonymizer results
# and a 'decrypt' operator to get the original text as output.
deanonymized_result = engine.deanonymize(
text=anonymized_text,
entities=anonymized_entities,
operators={"DEFAULT": OperatorConfig("decrypt", {"key": encryption_key})},
)
deanonymized_result

Figure 6 - Person name decrypted by using decrypt operator
Spark示例-将其与Dataframe和UDF一起使用
ApacheSpark是一个分布式数据处理平台,要在Spark中使用这些库,可以使用用户定义的函数来封装逻辑。接下来,您可以使用该函数对Spark数据帧执行操作(匿名化、加密或解密等),如下所示,以进行替换。
analyzer = AnalyzerEngine()
anonymizer = AnonymizerEngine()
broadcasted_analyzer = sc.broadcast(analyzer)
broadcasted_anonymizer = sc.broadcast(anonymizer)
# define a pandas UDF function and a series function over it.
# Note that analyzer and anonymizer are broadcasted.
def anonymize_text(text: str) -> str:
analyzer = broadcasted_analyzer.value
anonymizer = broadcasted_anonymizer.value
analyzer_results = analyzer.analyze(text=text, language="en")
anonymized_results = anonymizer.anonymize(
text=text,
analyzer_results=analyzer_results,
operators={"DEFAULT": OperatorConfig("replace", {"new_value": "<ANONYMIZED>"})},
)
return anonymized_results.text
def anonymize_series(s: pd.Series) -> pd.Series:
return s.apply(anonymize_text)
# define a the function as pandas UDF
anonymize = pandas_udf(anonymize_series, returnType=StringType())

Figure 7 - Sample data with no encryption yet (for Email and IP Address)
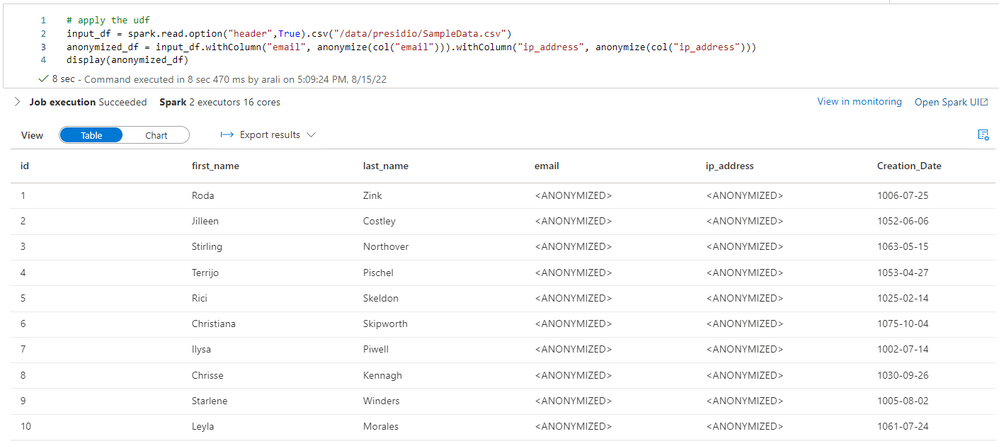
Figure 8 - Sample data anonymized for Email and IP Address
What we discussed so far barely scratched the surface. The possibilities are endless, and Presidio includes several samples for various kinds of scenarios. You can find more details here: https://microsoft.github.io/presidio/samples/
Here is the FAQ: https://microsoft.github.io/presidio/faq/
总结
当我们希望更好地控制和治理法规遵从性时,我们经常被要求加密、解密、屏蔽或匿名某些包含私人或敏感信息的列。在这篇博客文章中,我演示了如何使用Microsoft Presidio库和Azure Synapse Analytics的Spark池来对大规模数据执行操作。
Our team will be publishing blogs regularly and you can find all these blogs here: https://aka.ms/synapsecseblog
For deeper level understanding of Synapse implementation best practices, please refer to our Success By Design (SBD) site: https://aka.ms/Synapse-Success-By-Design
Tags
最新内容
- 3 months 3 weeks ago
- 3 months 3 weeks ago
- 3 months 3 weeks ago
- 3 months 3 weeks ago
- 3 months 3 weeks ago
- 3 months 3 weeks ago
- 3 months 3 weeks ago
- 3 months 3 weeks ago
- 3 months 3 weeks ago
- 3 months 3 weeks ago