
十大精选
1. Django Ninja

几年来,Django REST框架一直是在Django应用程序中构建RESTful API的首选。但在2021,一个新的竞争者诞生了。
遇到Django Ninja,这是一个使用Django构建API的快速web框架(顺便说一句,它最近发布了4.0),正如我们从这些库中所期望的那样,键入提示!
它使构建RESTAPI变得非常简单,在RESTAPI中,您可以免费获得参数的类型转换和验证(再次感谢Pydantic)以及文档。除此之外,您最喜欢的编辑器中的autocomplete也可以正常工作,而且该库支持异步视图!
我们是否错过了它也是基于OpenAPI和JSON模式开放标准的,这将为您提供互操作性优势?
2.SQLModel

继FastAPI和Typer的成功之后,tiangolo连续第三年凭借SQLModel(一个使用Python对象与SQL数据库交互的库)进入此列表。
你已经猜到了吗?是的,SQLModel基于Python的类型注释,并由Pydantic和SQLAlchemy提供支持,您可以充分利用这些功能。
您将拥有一个看起来非常直观的ORM,它具有强大的编辑器支持(代码完成、内联错误),以及数据验证和文档。和往常一样,图书馆的文档是一流的。天戈罗,明年的惊喜是什么?😂
3. Awkward Array

您可能已经熟悉numpy及其数组。它们是中心数据结构:基本上是一个值网格(二维矩阵或高维张量)。它们支持对数据块(如广播)进行矢量化操作,利用低级别库中的并行性和优化,因此可以比常规Python for循环运行得更快。
但是NumPy数组中的值必须都是相同的类型。它们不能表示可变长度的结构。虽然可以将dtype设置为object,但这还不够。
尴尬的阵型开始施救。对于用户来说,它们看起来像常规数组,但在下面,它们是一个通用的树状数据结构(如JSON)。他们将高效地在内存中连续存储数据,并使用编译的矢量化代码对其进行操作,就像NumPy一样。
考虑项目GITHUB ReMeME中列出的示例:
array = ak.Array([
[{"x": 1.1, "y": [1]}, {"x": 2.2, "y": [1, 2]}, {"x": 3.3, "y": [1, 2, 3]}],
[],
[{"x": 4.4, "y": [1, 2, 3, 4]}, {"x": 5.5, "y": [1, 2, 3, 4, 5]}]
])
以及以下片段:
使用常规Python:
output = []
for sublist in array:
tmp1 = []
for record in sublist:
tmp2 = []
for number in record["y"][1:]:
tmp2.append(np.square(number))
tmp1.append(tmp2)
output.append(tmp1)
Using Awkward Arrays
output = np.square(array["y", ..., 1:])
两个代码段生成相同的输出:
[
[[], [4], [4, 9]],
[],
[[4, 9, 16], [4, 9, 16, 25]]
]
但不仅仅是2。更简洁的是,它的速度也快了几个数量级,占用的内存更少。与Numba搭配使用时,速度会更快。含糖的
4. jupytext

Jupyter笔记本是一个很好的工具,但是在浏览器中编写代码并丢失您最喜欢的IDE的所有功能并不是很好。更糟糕的是,笔记本电脑通常会给版本控制和协作带来很多麻烦,因为它们最终存储为JSON文件。
Jupytext是一个Jupyter插件,用于解决这些问题,并允许您将笔记本保存为标记或几种语言的脚本。通过生成的纯文本文件,可以轻松地在版本控制中共享它们,合并其他人所做的更改,甚至可以使用IDE及其良好的自动完成或类型检查功能。
在2021的数据科学家的武器库中是必不可少的。
(同样相关,从我们的额外选择中检查Jupyter升序)。
5. Gradio

如果你在数据科学领域,你可能听说过Streamlit(它在2019年进入我们的前十名)。Streamlit可以轻松地将数据脚本转换为可共享的web应用程序,因此您可以将结果演示为实际应用程序,而不是Jupyter笔记本。
Gradio是一个新的工具,它将这一点更进一步:如果您想要构建一个ML模型的演示,它将使事情比Streamlit更容易。
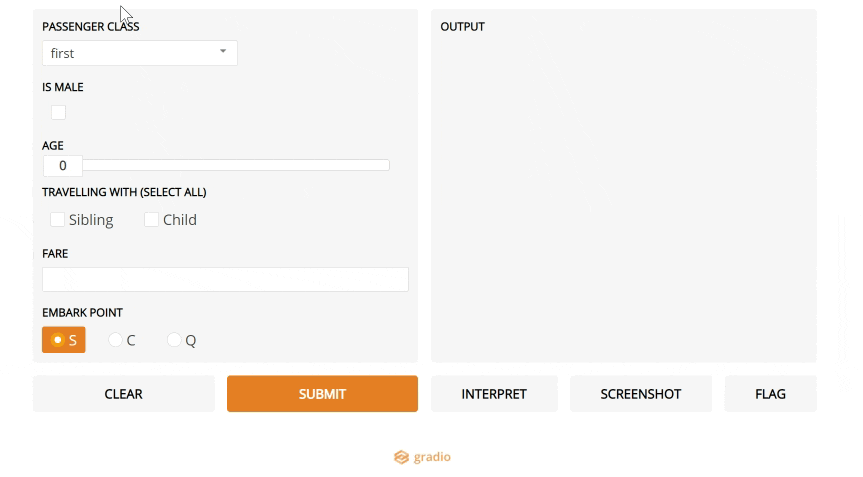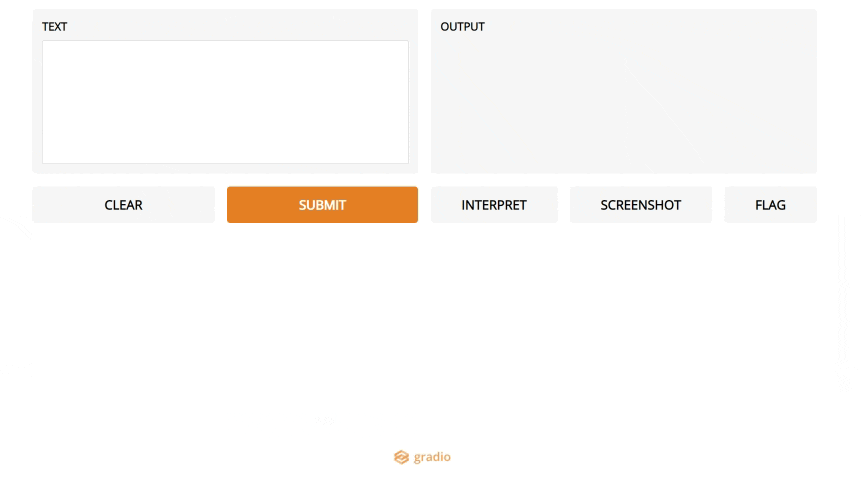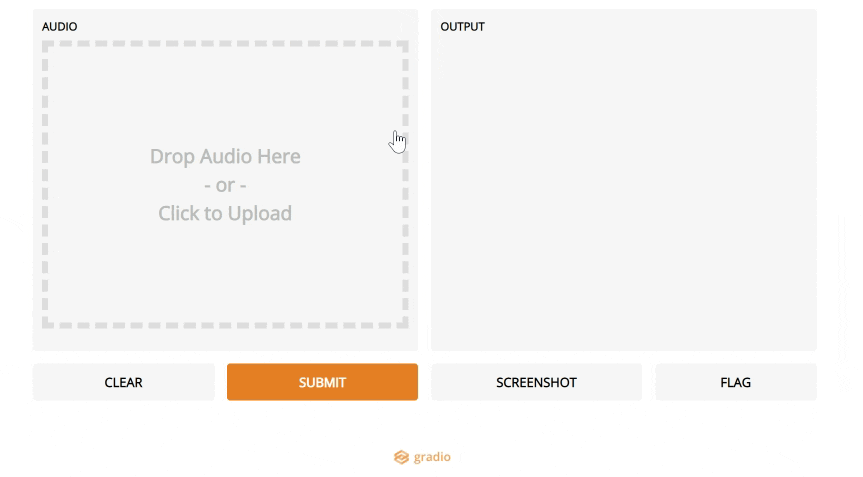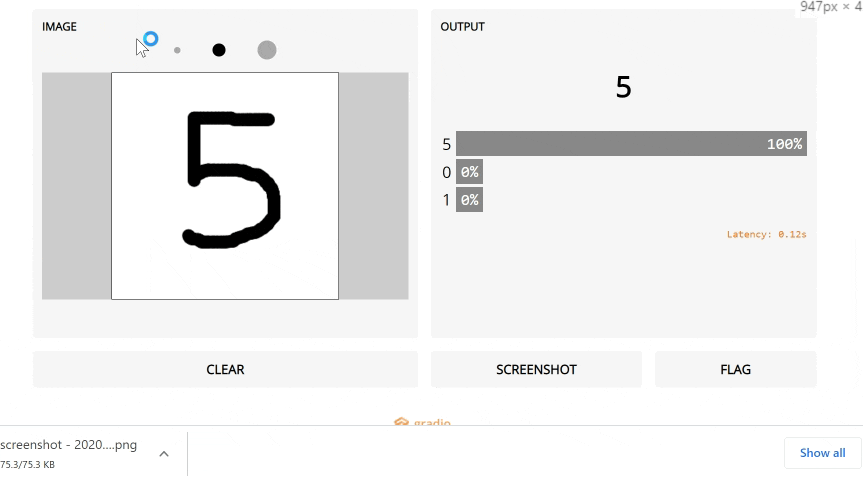
这是创建特定于您的模型的web UI的最简单方法,用户可以通过使用滑块更改参数、上传图像、编写文本甚至录制语音来进行操作。
这无疑是朝着使模型更容易访问的正确方向迈出的一步,数据科学家将注意力集中在对他们来说最重要的方面,而不是UI工作。
看起来Gradio刚被HuggingFace收购了!
6. AugLy

最初用于训练计算机视觉中更健壮的模型,数据增强很快被证明对所有机器学习学科都至关重要。正如我们所知,标记数据是稀缺的,因此充分利用它是非常重要的。此外,数据扩充是2021个领域中非常先进的SOTA的核心,就像自我监督学习一样。
AugLy,by Facebook Research(现在的Meta Research)是一个数据增强库,支持100多种音频、图像、文本和视频增强。可以使用元数据对增强进行配置,并进行组合以实现所需的效果。
除了通常可以在其他库中找到的图像缩放、翻转、调整大小或颜色抖动外,还有许多非经典的增强类型:将图像转换为模因或屏幕截图、将文本覆盖到图像、将某些单词更改为表情符号,或类似Instagram的过滤器。当然,这是一个让你关注的问题!
7. skweak

最初用于训练计算机视觉中更健壮的模型,数据增强很快被证明对所有机器学习学科都至关重要。正如我们所知,标记数据是稀缺的,因此充分利用它是非常重要的。此外,数据扩充是2021个领域中非常先进的SOTA的核心,就像自我监督学习一样。
AugLy,by Facebook Research(现在的Meta Research)是一个数据增强库,支持100多种音频、图像、文本和视频增强。可以使用元数据对增强进行配置,并进行组合以实现所需的效果。
除了通常可以在其他库中找到的图像缩放、翻转、调整大小或颜色抖动外,还有许多非经典的增强类型:将图像转换为模因或屏幕截图、将文本覆盖到图像、将某些单词更改为表情符号,或类似Instagram的过滤器。当然,这是一个让你关注的问题!
8. Evidently

在数据科学家和ML工程师团队完成了过去几个月的工作后,ML模型投入生产。它开始接收数据并发送预测以填充非常重要的仪表盘。ML人员开始着手解决其他一些重要问题。商业利益相关者很高兴。还是应该?
事实上,有很多事情可能会出错,往往是以意想不到的方式。可能模型在生产中接收到的数据类型与用于培训的数据类型不同,导致其表现不佳。也许数据是正确的,但是预测开始慢慢地出现错误,导致你在这个过程中做出各种糟糕的商业决策(损失很多钱!)。
我们的建议:如果你要持续依赖ML,你需要有一个ML监控系统,当出现问题时,它会提醒你。
欢迎使用这个工具,它可以帮助在验证期间评估ML模型,并在生产中监控它们。该工具不会直接检测数据中的异常情况,但如果您碰巧获得了地面真实值标签(如果回路中有人,通常情况下),它将帮助您检测所谓的数据漂移和目标漂移,以及生产中的模型性能。
显然,我们可以构建交互式可视化报告,由数据科学家手动检查以确保一切正常,还可以从pandas DataFrame或csv文件生成JSON配置文件,这些文件可以集成到自动预测管道中或与其他工具一起使用。
这是一段视频,演示了Jupyter笔记本中的应用。这很容易,对吧?
9. Jina and Finetuner

幕后正在发生一场悄无声息的革命。你肯定已经使用谷歌这样的搜索引擎有一段时间了,但可能没有注意到它们比几年前有多大的改进。
发生了什么:基于关键字的搜索正在慢慢地被淘汰。
新来者?神经搜索。这一切都是关于使用深层神经网络可以学习的表示,为搜索系统的组件提供动力。神经搜索不是将文本分割成离散的标记并使用这些标记进行匹配,而是将整个文本反馈给神经网络,神经网络将其转化为向量。然后,空间中与这些向量更接近的向量可以是匹配的文档。因此,如果你搜索同义词“请帮帮我”,你可能会得到“我需要一些帮助”作为第一个匹配词,即使这些词没有一个相同的词。
但它不仅仅适用于文本。它几乎可以处理任何类型的数据。您可以搜索与某些文本匹配的图像。您可以查询与其他图像类似的图像。音频,视频。。。你说吧。
Jina是一个神经搜索框架,任何人都可以在几分钟内构建可伸缩的深度学习搜索应用程序。它基本上为您提供了抽象,从代码和部署的角度来看,在实现神经搜索系统时,这些抽象将使您的生活更加轻松。它具有分布式体系结构、可扩展性和云本机特性。
伴随着Jina,FineTunner允许您微调神经网络表示,以获得神经搜索任务的最佳结果。它为人在回路方法提供了一个web界面。首先,您使用预训练的NN获得批次的结果,并开始选择您最喜欢的结果和不喜欢的结果。在此基础上,FineTunner将调整NN的权重,并向您呈现一个新批次,结果将越来越好。
我们非常兴奋地看到2022年将给这些图书馆带来什么!
10. Hub

数据科学的不幸现实是,大部分时间没有花在调整模型或思考解决新问题的聪明方法上。不。数据科学家花费大量时间获取数据,将其转换为正确的格式,并编写样板代码。
为了处理大量数据(几GB),还需要构建能够支持每个工作流的基础架构代码。
但随着工具的成熟,这可能成为过去的问题?
Meet Hub是一种具有简单API的数据集格式,可以帮助您处理任何类型的数据集,而无需担心数据集的存储位置和大小。它确保数据以压缩格式(分块数组)存储,基本上是可以存储在任何地方的二进制blob。是的,这意味着您可以透明地使用任何存储选项,如AWS S3、GCP存储桶,或者(如果您敢的话)本地存储,而无需更改代码。
我们有没有提到Hub工作迟缓,这意味着只有在需要时才能获取数据?使用多TB数据集不需要多TB硬盘。还有一个API用于将中心数据集连接到最常用的工具,如PyTorch或TensorFlow,构建管道,以及进行数据版本控制。您可以对数据集进行分布式转换。并将其形象化。还有,谁知道2022年还会发生什么?令人兴奋的
额外选择-不要错过这些
Various
- Textual — TUI (Text User Interface) framework for Python inspired by modern web development, from the author of our beloved rich.
- chime — Python sound notifications made easy.
- Jupyter Ascending — sync Jupyter Notebooks so you can type the code from your favorite code editor.
Model deployment & training
- transformer-deploy — deploy 🤗 Transformers models in production, behind an API with submillisecond inference️ time using TensorRT and Nvidia Triton.
- opyrator — turn your Python functions into production-ready microservices, powered by FastAPI, Streamlit, and Pydantic.
- koila — prevent PyTorch's
CUDA error: out of memoryin just 1 line of code.
Vision
- VISSL — a library for state-of-the-art self-supervised learning from images, by Meta Research.
- YOLOX — an anchor-free version of YOLO, a fast and accurate object detection model, with a simpler design but better performance.
- layout-parser — deep learning-based document image analysis: detect paragraphs, titles, images, and more in pages with complex layouts.
- SAHI — clever library to perform object detection in large images, without sacrificing performance, by using slicing. Supports both bounding boxes or masks by categories!
NLP / Topic modeling
- lightseq — a high-performance training and inference library for sequence processing and generation implemented in CUDA, enabling efficient computation of modern NLP models such as BERT, GPT, Transformer, and more.
- Top2Vec — automatically detects topics present in text and generates jointly embedded topic, document and word vectors.
- BERTopic — leverages 🤗 Transformers and c-TF-IDF to create dense clusters allowing for easily interpretable topics whilst keeping important words in the topic descriptions.
Time series
- Greykite — flexible, intuitive and fast forecasts through its flagship algorithm, Silverkite, which provides interpretable forecasts. By LinkedIn.
- Kats — toolkit for time series analysis, from understanding the key statistics and characteristics, detecting change points and anomalies, to forecasting. By Meta Research.
- Merlion — an end-to-end machine learning framework for loading and transforming data, building and training models, post-processing model outputs, and evaluating model performance, supporting several tasks.
- Spice.ai — for developers who want to build intelligent applications leveraging time series data without too much hassle.
Graphs / Geospatial / Spatiotemporal
- prettymaps — a small set of Python functions to draw pretty maps from OpenStreetMap data.
- TorchGeo — torchvision for geospatial data, providing datasets, transforms, samplers, and pre-trained models. By Microsoft.
- pytorch_geometric — easily write and train Graph Neural Networks (GNNs) for a wide range of applications related to structured data, built on PyTorch.
- nodevectors — fast and scalable node embedding algorithms.
- PyTorch Geometric Temporal — temporal (dynamic) extension library for PyTorch Geometric.
Audio
- pedalboard — Spotify's library for programmatically adding effects to audio.
- SpeechBrain — an all-in-one speech toolkit based on PyTorch.
Metric learning
- PyTorch Metric Learning — the easiest way to use deep metric learning in your application. Modular, flexible, and extensible. Implements several losses, distance metrics, miners, and more.
- TensorFlow Similarity — Google's take on their tool for metric and contrastive learning.
Optimization
- Hyperactive — optimization and data collection toolbox for convenient and fast prototyping of computationally expensive models.
- Gradient-Free-Optimizers — simple and reliable optimization with local, global, population-based and sequential techniques in numerical discrete search spaces
- higher — PyTorch library allowing users to obtain higher-order gradients over losses spanning training loops, by Meta Research.
Explainability / monitoring / causality
- Ecco — visualize and explore NLP language models.
- explainerdashboard — quickly deploy a dashboard web app that explains the workings of a (scikit-learn compatible) machine learning model.
- Transformers Interpret — explain models in the 🤗 transformers package with 2 lines of code.
- Shapley — various methods to compute (approximate) the Shapley value of players (models) in weighted voting games (ensemble games).
- UpliftML — uplift modeling, great for studying causality in personalization/marketing.
Reinforcement learning
- maro — Multi-Agent Resource Optimization (MARO) platform is an instance of Reinforcement learning as a Service (RaaS) for real-world resource optimization. By Microsoft.
Some worthy misses from 2020 (sorry!)
- pqdm a parallel version of tqdm (widely used progress bar for Python and CLI).
- AutoScraper — a neat library implementing auto scraping using clever ideas that don't require you to write or maintain selectors or XPath expressions.
- Aim — easy-to-use and performant open-source experiment tracker.
- NeuralProphet — NN-based time series model, inspired by Facebook Prophet and AR-Net, built on PyTorch.
- glacier — build Python CLIs really easily, using type hints.
- Haystack — an open-source NLP framework that leverages Transformer models to implement production-ready neural search, question answering, semantic document search and summarization for a wide range of applications.
- MPIRE — an almost drop-in replacement for multiprocessing, will save you from writing a lot of code for things you probably need when designing applications leveraging multiprocessing: init and exit functions for workers (where for example you can handle stuff like DB connections), managing of worker state and handling of exceptions. It also has a nice feature where you can pass objects as copy-on-write.
原文:https://tryolabs.com/blog/2021/12/21/top-python-libraries-2021
- 登录 发表评论
- 125 次浏览