
激活元数据如何为数据网格梦想提供动力

可发现。可以理解。值得信赖的。这些只是数据网格基础设施的一些关键思想。浏览所有这些,您会很快找到一个共同的元素,它是实现每一个元素的关键——元数据。
如今,元数据已经成为大数据。现代数据堆栈的每个组件及其上的每个用户交互都会生成元数据。可以毫不夸张地说,元数据的潜力是巨大的。事实上,我认为它是解锁数据网格真正价值的关键。
然而,元数据-就像数据网格一样-还有一些成长的事情要做。正如任何从业者都知道的那样,元数据的大小和规模的爆炸性增长使数据团队很难真正使用它。通常,它最终在另一个孤立的工具中未被使用。
我是一名终身数据从业者,花了十年时间管理数据团队并建立了良好的数据文化。我经历过很多失败和成功,比如建立印度的国家数据平台。在这一过程中,我处理了大量的混乱,这促使我的团队构建工具,使我们自己更加敏捷。四次尝试后,我们构建了一个活跃的元数据平台,真正改变了我们的工作方式。
我有机会在Datanova 2022:数据网格峰会上发表演讲,这是Starburst的第二届年会。我分享了我对现代元数据的看法,它在我们的数据堆栈中的不足之处,以及我们如何使用它来推动数据网格的梦想。我已经掌握了以下要点。
什么不起作用
如今元数据的使用方式完全是错误的。我们从一堆独立的、孤立的工具中编译所有元数据,并将其放入自己的孤立数据目录或治理工具中。我们期望数据从业者在需要上下文时切换回该目录工具,但这并不奏效。
用户需要上下文时需要上下文。
当某人处于日常工作流程的中间时,例如查看BI工具上的仪表板,他们需要知道自己是否可以信任该仪表板,而不是在切换到数据目录并登录到其数据目录、搜索相关数据资产并找出它们上次更新的时间之后。
我们目前的元数据方法的另一个问题是,它对每个数据人都一视同仁。在我们的正常生活中,我们都习惯了令人难以置信的个性化体验——想想Netflix的策展或亚马逊的推荐就知道了。如今,数据平台拥有大量关于用户的数据,比如首席技术官周一早上进行的搜索,或者数据工程师在管道中使用最多的资产。为什么我们不使用这些数据为不同领域的不同用户个性化数据体验?
最后,今天的元数据大多存在于自上而下的治理模型中。大多数数据治理工具都是为集中式治理结构而构建的,由“委员会”制定规则和政策。这与自下而上、民主化的数据网格世界正好相反。
元数据的未来
花点时间想象一下你日常生活中的经历。您使用Segment来完成过去的大量手动工作,从数十个网站、应用程序和工具中获取客户数据。然后Zapier走到盘子前,让这些信息变得可操作——如果一个工具发生了什么事情,它会触发其他工具的一系列操作。在你注销这些工具回家后,你会打开Netflix,他们在那里策划了最新的节目,甚至根据你想看的节目创建了一些新的节目。
为什么我们不能在我们的数据平台上实现这一点?
一个真正智能的数据管理系统应该考虑到最终用户及其需求。它将使用元数据自然地联合和管理我们的数据系统,为围绕当今多样化的数据用户构建的自动化、个性化体验提供动力。
它应该围绕这样的问题创建,“数据分析师的体验是什么样的?市场营销或销售中的数据分析师呢?这与数据工程师或业务用户的体验有何不同?”然后我们可以将这种个性化和知识带回数据人每天使用的工具和体验中,如Jira、Slack和Microsoft Teams。
例如,假设您在Looker仪表板中,可以从数据生态系统中的其他工具中查看所有上下文。您可以立即了解谁是所有者和专家,您是否可以信任仪表板,以及为其提供动力的管道是否已更新。这就是数据变得“本机可访问”的时候,这是数据网格最重要的目标之一。
元数据和数据网格
数据网格背后的一个关键概念是联合计算治理,或者说是一种使用来自整个组织的反馈循环和自下而上的输入来自然地联合和管理数据产品的系统。元数据使这成为可能。
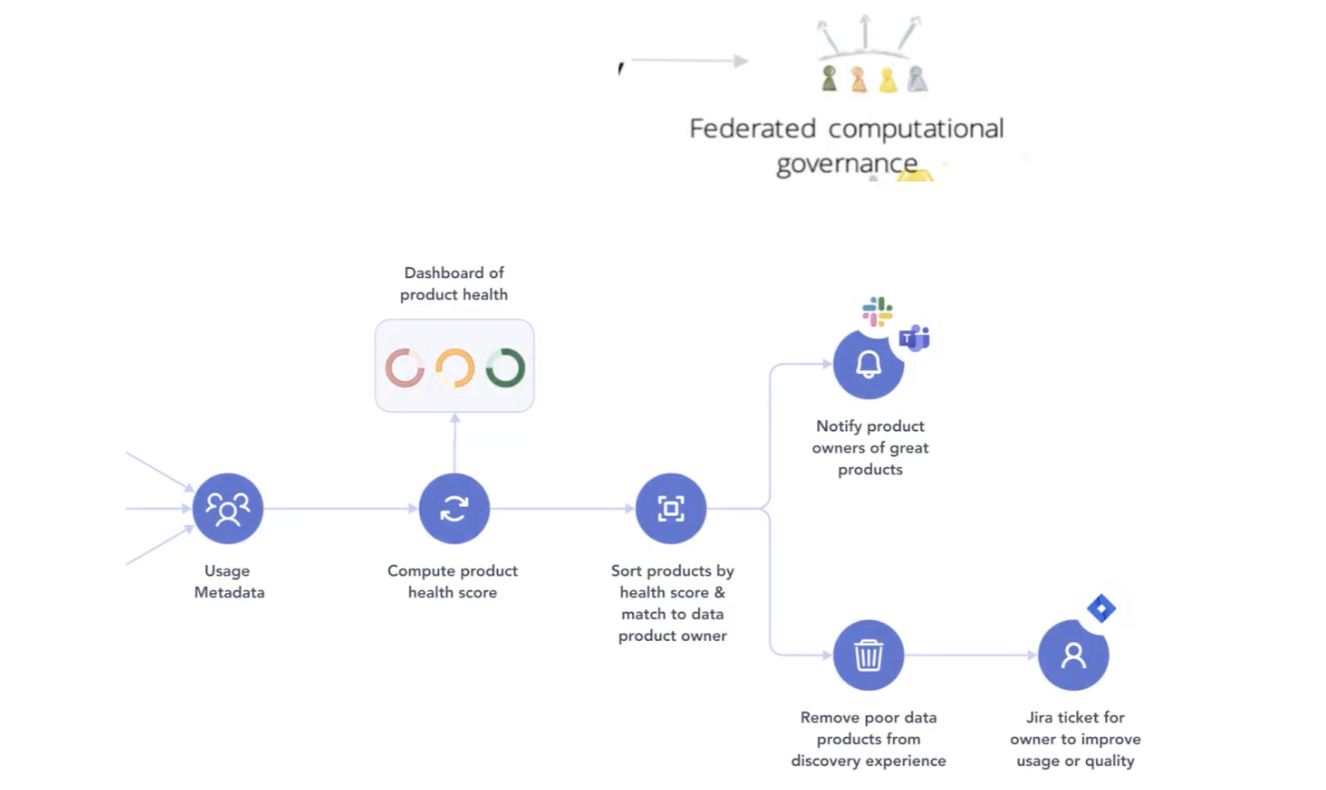 An automated workflow for finding and governing data product health (Image by author, from my talk at Datanova 2022: The Data Mesh Summit)
An automated workflow for finding and governing data product health (Image by author, from my talk at Datanova 2022: The Data Mesh Summit)
例如,考虑上面的自动化元数据工作流。有了关于人们实际使用的资产的使用元数据,我们可以创建一个关于每个数据产品的使用和更新量的产品健康评分。然后,我们可以根据健康评分对产品进行排序,并将每个产品与其数据产品所有者进行匹配。对于出色的产品,产品所有者可以收到一条Slack消息:“祝贺你!你的数据产品做得很好。”低质量或过时的产品可以自动从发现体验中删除或弃用,并且可以在Jira上为相关所有者添加一张改进产品的票。
这就是我所看到的数据网格的未来——使用元数据创建一个真正的动作层,为数据网格背后的基本概念提供动力。
通过从许多不同的地方引入元数据,我们可以自动化和协调数据网格背后的基本概念,如民主化、可发现性、信任、安全性和可访问性。
元数据在实践中
到目前为止,我相信你在问,“在数据网格中真正实现主动元数据实践意味着什么?”
元数据允许您从孤立的上下文转变为嵌入式上下文(域),从通用体验转变为个性化体验(数据产品),从最低限度的自动化转变为真正的自治(自助服务基础设施),从自上而下的治理转变为民主化的治理(联合计算治理)。
但是,从理论到实践的第一步是什么?创建数据产品运输标准。我已经谈到了“数据即产品”的特征,这是数据网格背后的一个关键概念。其中的每一项都可以在组织或网格级别编码为运输标准。

The characteristics of “Data as a Product,” a key concept behind the Data Mesh (Image by author, from my talk at Datanova 2022: The Data Mesh Summit)
例如,对于“可理解”,我已经看到了很多使用5W1H框架来定义数据产品可理解性的成功案例。作为一个组织,您可以选择框架中哪些元素最重要,并专注于这些元素。
下一步是将这些过程完全自动化。这使得基础设施真正实现了自助服务,这是数据网格范式的重要组成部分。例如,为了使数据产品易于理解,您可以在整个数据堆栈中引入上下文。解析SQL日志可以用于在列级别自动对每个数据产品的受欢迎程度进行排名。数据管道中的上下文可用于基于数据产品的源创建列描述。
这一步骤可能需要实施新的工具来促进,但归根结底,数据网格是一种文化和心态的转变。这就是为什么最后一个重要步骤是将人类驱动的标准和仪式纳入产品运输过程。
最后,你要求你的工程师和开发人员开始以不同的方式思考他们的角色,这并不容易。
这关乎文化变革,而不仅仅是技术。设定数据团队的价值观(例如可重用性),创建仪式来帮助每个人实现这些价值观(如文档时间),你最终会看到人们的心态和生产力发生真正的转变。
总而言之,很明显,数据网格的未来看起来很光明。有关我对这个主题的更多想法,请查看我在Datanova 2022的完整演讲:数据网格峰会!
这个博客最初发布在Starburst的博客上,并在获得许可后在这里重新发布。
发现这些内容有帮助吗?我在我的时事通讯《元数据周刊》上每周写一篇关于活动元数据、数据操作、数据文化和我们构建Atlan的经验教训的文章。在此处订阅。
最新内容
- 6 hours ago
- 1 week 6 days ago
- 3 weeks ago
- 3 weeks 4 days ago
- 2 months 1 week ago
- 6 months 1 week ago
- 6 months 1 week ago
- 6 months 1 week ago
- 6 months 1 week ago
- 6 months 1 week ago