
MosaicML发布了新的模型套件,并支持针对指令、聊天、故事等进行了优化的模型。
我最近创办了一份以人工智能为重点的教育通讯,该通讯已经有超过150000名订户。TheSequence是一个无BS(意思是没有炒作,没有新闻等)面向ML的时事通讯,需要5分钟的阅读时间。目标是让你了解机器学习项目、研究论文和概念的最新情况。请尝试订阅以下内容:
由于大型语言模型(LLM)的显著影响,世界正在经历一场变革。然而,对于资金充足的行业实验室之外的个人来说,培训和实施这些模式的过程可能是一项艰巨的任务。因此,围绕开源LLM的活动激增。突出的例子包括Meta的LLaMA系列、EleutherAI的Pythia系列、StabilityAI的StableLM系列和Berkeley AI Research的OpenLLaMA模型。
MosaicML最近推出了一个名为MPT(MosaicMLPretrained Transformer)的新模型系列,以解决上述模型遇到的限制。本版本旨在提供一个开源模型,该模型在商业上可行,并在各个方面超越LLaMA-7B的能力。我们的MPT型号系列的主要功能包括:
- ·商业使用许可证:与LLaMA不同,MPT型号系列获得商业应用许可。
- ·广泛的数据训练:MPT已经在大量数据上进行了训练,与LLaMA的1万亿代币相当,而Pythia、OpenLLaMA和StableLM分别使用3000亿、3000亿和8000亿代币。
- ·对长输入的特殊处理:MPT已准备好有效地处理极其长的输入。利用ALiBi,我们对该模型进行了高达65000个输入的训练,其处理输入的能力高达84000个代币,远远超过了其他开源模型的限制,这些模型通常在2000到4000个代币之间。
- ·优化快速训练和推理:MPT结合了FlashAttention和FasterTransformer等先进技术,实现了加速训练和推理过程。
- ·高效开源培训代码:MPT配备了精心设计的开源培训代码,强调效率和有效性。
MPT模型
MPT版本由几个针对不同功能进行优化的模型组成。
1) MPT-7B型
MPT-7B的性能水平与LLaMA-7B不相上下,在各种标准学术任务中超过了7B至20B范围内的其他开源模型的能力。为了评估该模型的质量,使用了11个广泛认可的开源基准进行了评估,这些基准通常用于情境学习(ICL)。这些基准是根据行业标准做法精心制定和评估的。此外,我们的团队精心策划的《危险边缘》基准被纳入其中,以衡量该模型在对复杂而苛刻的问题做出准确回答方面的熟练程度。
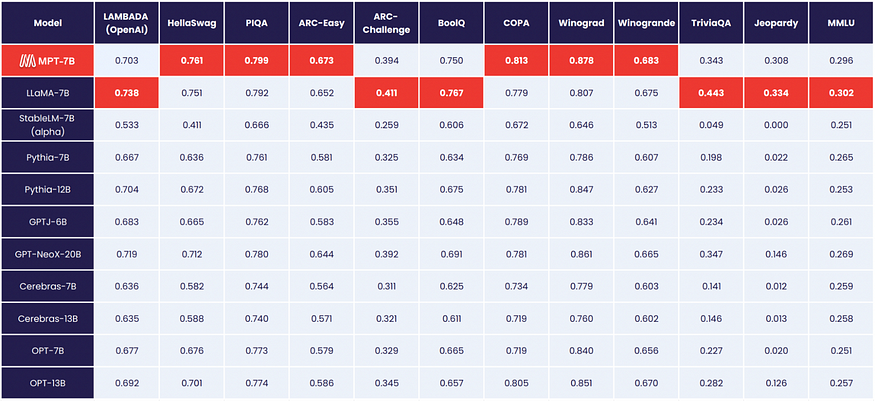
2) MPT-7B-StoryWriter-65K
大多数开源语言模型在处理仅包含几千个令牌的序列方面都有局限性。然而,随着MosaicML平台和由8xA100–80GB组成的单个节点的使用,MPT-7B的微调成为一个无缝过程,使其能够适应高达65k的上下文长度。这种适应如此广泛的上下文长度的非凡能力是由嵌入MPT-7B中的关键架构选择ALiBi实现的。
为了展示这种非凡的能力,并激发您对65k上下文窗口所呈现的可能性的想象力,MosaicML很自豪地推出了MPT-7B-StoryWriter-65k+。StoryWriter经历了一个涉及2500个步骤的微调过程,利用从books3语料库中发现的小说中提取的65k个象征性摘录。与预训练阶段类似,此微调过程依赖于下一个令牌预测目标。训练过程需要使用具有FSDP、激活检查点和1的微批量的Composer,以确保最佳的训练结果。

3) MPT-7B-Instruct
LLM预训练的传统方法包括训练模型以基于所提供的输入生成文本。然而,在实际应用中,我们期望LLM将输入解释为要遵循的指令。教学微调的目的是培训LLM在教学后续任务中表现出色。这种范式转变减少了对复杂的即时工程的依赖,使LLM更易于访问、直观和易于应用。在指令微调方面取得的进展可归因于FLAN、Alpaca和Dolly-15k等开源数据集的可用性。
为了满足商业需求,我们开发了一种称为MPT-7B-Directive的模型变体,专门为以下指令而设计。虽然我们很欣赏Dolly提供的商业许可,但我们希望有一个更大的数据集。为了实现这一点,我们用Anthropic的Helpful&Harmless数据集的一个子集增强了Dolly,使数据集的大小增加了四倍,同时确保了其商业可行性。
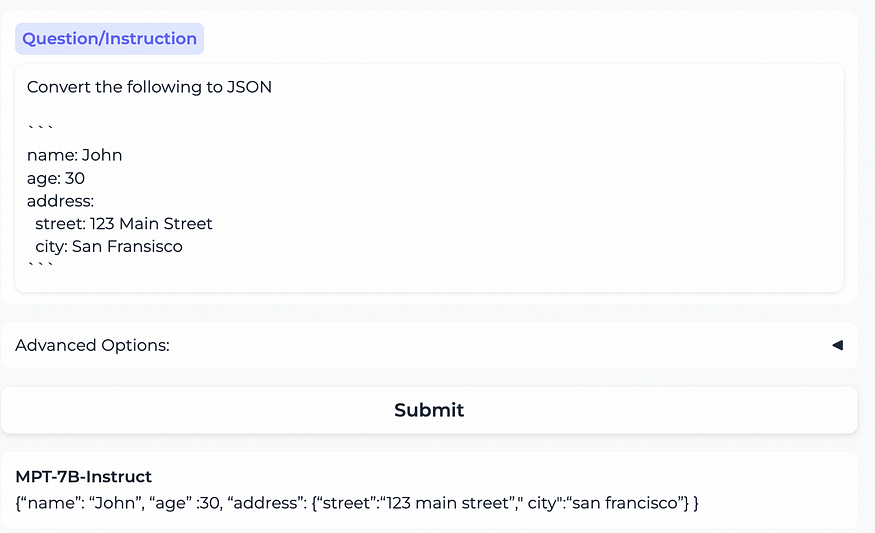
由此产生的组合数据集被用于对MPT-7B进行微调,从而创建了MPT-7B-Directive——一个具有特殊指令跟随功能的商业可用模型。利用其在1万亿代币上的广泛培训,MPT-7B-Directive预计即使与更大的美元v2–12b模型相比也具有竞争力。值得注意的是,Pythia-12B的基本模型,即美元-v2-12B的基础,仅在3000亿个代币上进行了训练。
4) MPT-7B-Chat
MosaicML通过开发MPT-7B-Chat(MPT-7B的会话变体)进一步扩展了其产品。MPT-7B-Chat使用多种数据集进行了微调,包括ShareGPT Vicuna、HC3、Alpaca、Helpful和Harmless以及Evol Instruction。这种细致的微调过程使MPT-7B-Chat具备了在各种会话任务和应用程序中脱颖而出的必要能力。ChatML格式的实现确保了向模型传输系统消息的简化和标准化方法,同时也防止了潜在的恶意提示注入。
虽然MPT-7B指令主要致力于为指令后续任务提供更自然、直观的界面,但MPT-7B-Chat旨在为用户提供无缝、引人入胜的多回合互动。通过利用其复杂的培训和微调,MPT-7B-Chat提供了增强的对话体验,促进了与模型的动态和互动交流。

架构
MPT系列模型的体系结构由一系列常见的构建块支持
1) 数据
为了确保MPT-7B是一个高质量的独立模型,能够适应广泛的下游应用,人们对预训练数据的选择给予了广泛的关注。用于预训练的数据由MosaicML从各种来源精心策划。这些来源的摘要见表2,附录部分提供了进一步的详细说明。使用EleutherAI GPT-NeoX-20B标记器对文本进行标记,并在由1万亿个标记组成的广泛数据集上对模型进行预训练。
该数据集的组成优先考虑英语自然语言文本,同时也融入了多样性元素,以适应未来的应用,如代码或科学模型。值得注意的是,该数据集包括来自最近发布的RedPajama数据集的部分。因此,数据集的网络爬行和维基百科部分富含2023年的最新信息,确保模型具备最新知识。
2) Tokenizer
出于标记化的目的,采用了EleutherAI GPT NeoX 20B标记化器,选择该标记化器是因为其所需的特性在标记化代码时被证明特别相关。这些特征包括:
- ·对各种数据的混合进行培训,包括代码(称为“The Pile”)。这确保了标记化器熟悉特定于代码的语法和结构。
- ·一致的空间划界:与GPT2标记器不同,GPT2标记化器根据前缀空间的存在进行不一致的标记化,GPT NeoX 20B标记化器在整个标记化过程中保持了一致的空间定界方法。
- ·为重复的空格字符合并标记:标记化器包括特定的标记,用于处理存在大量重复空格字符的实例。这使得能够对包含大量重复空格字符的文本进行卓越的压缩。
标记化器的词汇表大小设置为50257;然而,出于我们的目的,我们将模型词汇表大小扩展到50432,确保了有效标记化所需的令牌的全面覆盖。
3) 计算
MPT-7B模型使用MosaicML平台提供的一系列工具进行了训练。培训过程中使用的具体工具如下:
- ·计算:培训使用了Oracle Cloud的A100–40GB和A100–80GB GPU,它们以卓越的计算能力而闻名。
- ·编排和容错:MCLI和MosaicML平台在编排训练过程和确保容错方面发挥了至关重要的作用,从而提高了训练过程的效率和稳定性。
- ·数据:培训数据来源于OCI对象存储和流数据集,利用这些资源访问和管理必要的数据集。
- ·培训软件:使用的培训软件包括Composer、PyTorch FSDP(完全共享数据并行)和LLM Foundry。这些软件框架结合了先进的技术和简化的流程,促进了高效的模型培训。
正如许多团队所记录的那样,在数百到数千个GPU上训练具有数十亿参数的大型语言模型(LLM)是一项艰巨的挑战。训练过程中使用的硬件经常以各种创造性的方式遇到频繁和意想不到的故障。损失高峰可能会扰乱训练进度,因此监督训练的团队必须保持警惕,甚至需要在出现问题时进行手动干预以纠正问题。
然而,在MosaicML,专门的研究和工程团队已经投入了六个月的不懈努力来正面应对这些挑战。MPT-7B从开始到结束都是在1万亿个代币上无缝训练的,不需要人工干预。值得注意的是,训练过程没有表现出显著的损失峰值,不需要中间流学习速率调整或数据跳过,并且自动处理任何失效GPU的实例。
4) 推论
MPT的设计非常注重推理任务的速度、易部署性和成本效率。在性能方面,MPT在其层中展示了令人印象深刻的优化,利用了FlashAttention和低精度层rm等专业组件。与LLaMa-7B等其他7B型号相比,这种优化转化为MPT-7B卓越的开箱即用性能。事实上,MPT-7B的速度显著提高了1.5x-2x,使得仅使用HuggingFace和PyTorch就可以开发快速灵活的推理管道。这种组合使用户能够高效地部署MPT模型,同时享受增强的性能和简化的推理过程。
MPT-7B版本是市场上最完整的开源LLM系列之一。此版本的商业可用性代表了基础模型开源势头的一个重要里程碑。
最新内容
- 5 days 18 hours ago
- 1 week 6 days ago
- 2 weeks 3 days ago
- 2 months ago
- 5 months 4 weeks ago
- 5 months 4 weeks ago
- 5 months 4 weeks ago
- 5 months 4 weeks ago
- 5 months 4 weeks ago
- 5 months 4 weeks ago