
category
大型语言模型(LLM)是一种深度学习算法,可以使用非常大的数据集识别、总结、翻译、预测和生成内容。
什么是大型语言模型?
大型语言模型在很大程度上代表了一类称为转换器网络的深度学习架构。转换器模型是一种神经网络,它通过跟踪顺序数据中的关系来学习上下文和含义,比如这句话中的单词。
变压器由多个变压器块(也称为层)组成。例如,转换器具有自注意层、前馈层和归一化层,所有这些层一起工作来解密输入,以在推理时预测输出流。这些层可以堆叠起来,形成更深层次的转换器和强大的语言模型。变形金刚是谷歌在2017年的论文《注意力就是你所需要的一切》中首次推出的
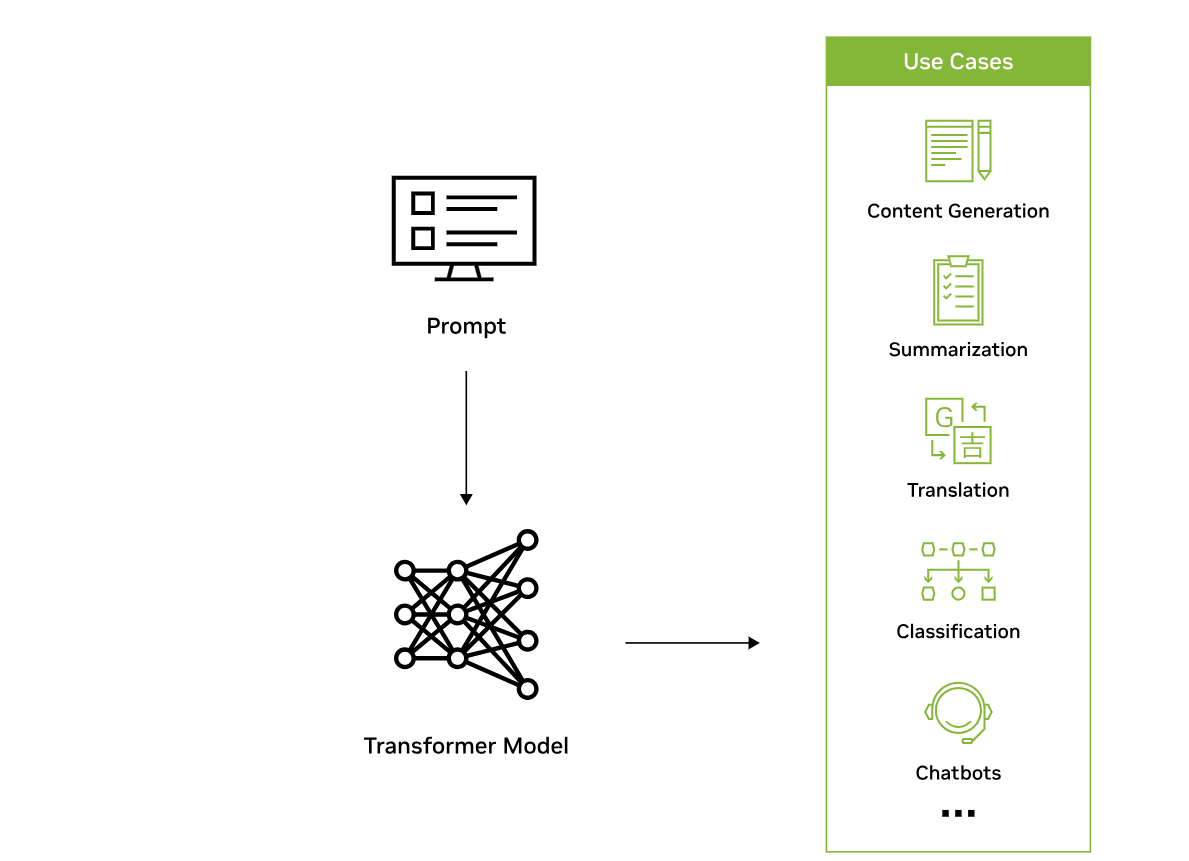
图1。变压器模型的工作原理。
有两个关键的创新使transformer特别适合大型语言模型:位置编码和自我关注。
位置编码嵌入输入在给定序列中发生的顺序。从本质上讲,由于位置编码,单词可以不按顺序输入,而不是按顺序将句子中的单词输入神经网络。
自我注意在处理输入数据时为其每一部分分配一个权重。这个权重表示该输入在上下文中对其余输入的重要性。换句话说,模型不再需要对所有输入都给予同样的关注,而是可以专注于输入中实际重要的部分。随着模型筛选和分析堆积如山的数据,随着时间的推移,神经网络需要注意输入的哪些部分的这种表示会被学习。
这两种技术相结合,可以分析不同元素在长距离、非顺序地相互影响和联系的微妙方式和背景。
非顺序处理数据的能力使复杂问题能够分解为多个较小的同时计算。当然,GPU非常适合并行解决这些类型的问题,允许大规模处理大规模未标记的数据集和巨大的变换器网络。
为什么大型语言模型很重要?
从历史上看,人工智能模型一直专注于感知和理解。
然而,在具有数千亿参数的互联网规模数据集上训练的大型语言模型,现在已经解锁了人工智能模型生成类人内容的能力。
模型可以以可信的方式读、写、编码、绘制和创建,增强人类创造力,提高各行业的生产力,以解决世界上最棘手的问题。
这些LLM的应用程序跨越了过多的用例。例如,人工智能系统可以学习蛋白质序列的语言,以提供可行的化合物,帮助科学家开发开创性的救命疫苗。
或者,计算机可以帮助人类做他们最擅长的事情——创造、交流和创造。患有作家障碍的作家可以使用大型语言模型来帮助激发他们的创造力。
或者,软件程序员可以更高效地利用LLM生成基于自然语言描述的代码。
什么是大型语言模型示例?
整个计算堆栈的进步允许开发越来越复杂的LLM。2020年6月,OpenAI发布了GPT-3,这是一个1750亿参数的模型,通过简短的书面提示生成文本和代码。2021年,NVIDIA和微软开发了威震天图灵自然语言第530B代,这是世界上最大的阅读理解和自然语言推理模型之一,具有5300亿个参数。
随着LLM的规模不断扩大,它们的能力也在不断增强。一般来说,基于文本的内容的LLM用例可以按以下方式进行划分:
- 生成(例如,故事写作、营销内容创作)
- 摘要(例如,法律释义、会议笔记摘要)
- 翻译(例如,语言之间、文本到代码)
- 分类(如毒性分类、情绪分析)
- 聊天机器人(例如,开放域Q+A、虚拟助理)
世界各地的企业都开始利用LLM来释放新的可能性:
- 医学研究人员根据教科书、研究论文和患者电子健康记录中的数据集,训练医疗保健中的大型语言模型,用于蛋白质结构预测等任务,这些任务可以揭示疾病模式并预测结果。
- 零售商可以利用LLM通过动态聊天机器人为客户提供一流的客户体验。
- 开发人员可以利用LLM编写软件并教机器人如何完成物理任务。
- 财务顾问可以使用LLM来总结财报电话会议,并创建重要会议的记录。
- 营销人员可以培训LLM,将客户的反馈和请求组织到集群中,或根据产品描述将产品细分到类别中。
大型语言模型仍处于早期阶段,前景广阔;一个具有零样本学习能力的单一模型可以通过即时理解和生成类人思想来解决几乎所有可以想象的问题。用例横跨每一家公司、每一笔商业交易和每一个行业,提供了巨大的价值创造机会。
大型语言模型是如何工作的?
使用无监督学习来训练大型语言模型。通过无监督学习,模型可以使用未标记的数据集在数据中找到以前未知的模式。这也消除了对广泛数据标签的需求,这是构建人工智能模型的最大挑战之一。
由于LLM经过了广泛的培训过程,这些模型不需要针对任何特定任务进行培训,而是可以为多个用例提供服务。这些类型的模型被称为基础模型。
基础模型在没有太多指导或训练的情况下为各种目的生成文本的能力被称为零样本学习。这种能力的不同变体包括一次或几次学习,其中向基础模型提供一个或几个示例,说明如何完成任务以理解并更好地执行选定的用例。
尽管使用大型语言模型进行零样本学习具有巨大的能力,但开发人员和企业都有一种天生的愿望,即驯服这些系统,使其以自己想要的方式工作。为了针对特定用例部署这些大型语言模型,可以使用多种技术对模型进行定制,以实现更高的准确性。一些技术包括即时调整、微调和适配器。
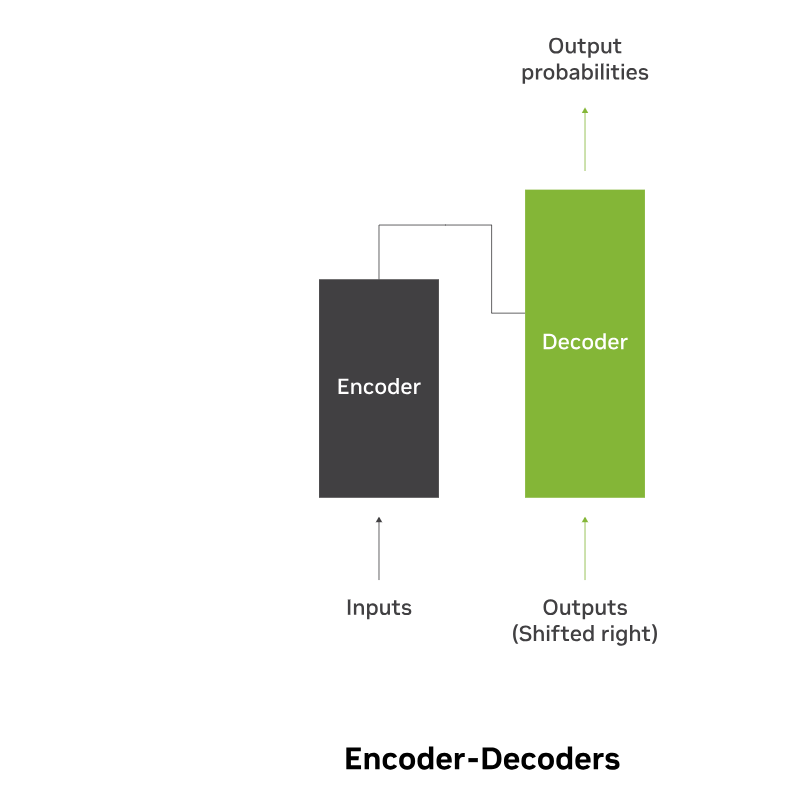
图2:图像显示了编码器-解码器语言模型的结构。
有几类大型语言模型适用于不同类型的用例:
- 仅限编码器:这些模型通常适用于能够理解语言的任务,如分类和情感分析。仅编码器模型的示例包括BERT(来自变压器的双向编码器表示)。
- 仅限解码器:这类模型非常擅长生成语言和内容。一些用例包括故事写作和博客生成。仅解码器架构的示例包括GPT-3(生成预训练变换器3)。
- 编码器-解码器:这些模型结合了转换器架构的编码器和解码器组件,以理解和生成内容。这种体系结构的一些用例包括翻译和摘要。编码器-解码器架构的实例包括T5(文本到文本转换器)。
大型语言模型的挑战是什么?
开发和维护大型语言模型所需的大量资本投资、大型数据集、技术专业知识和大规模计算基础设施一直是大多数企业进入的障碍。
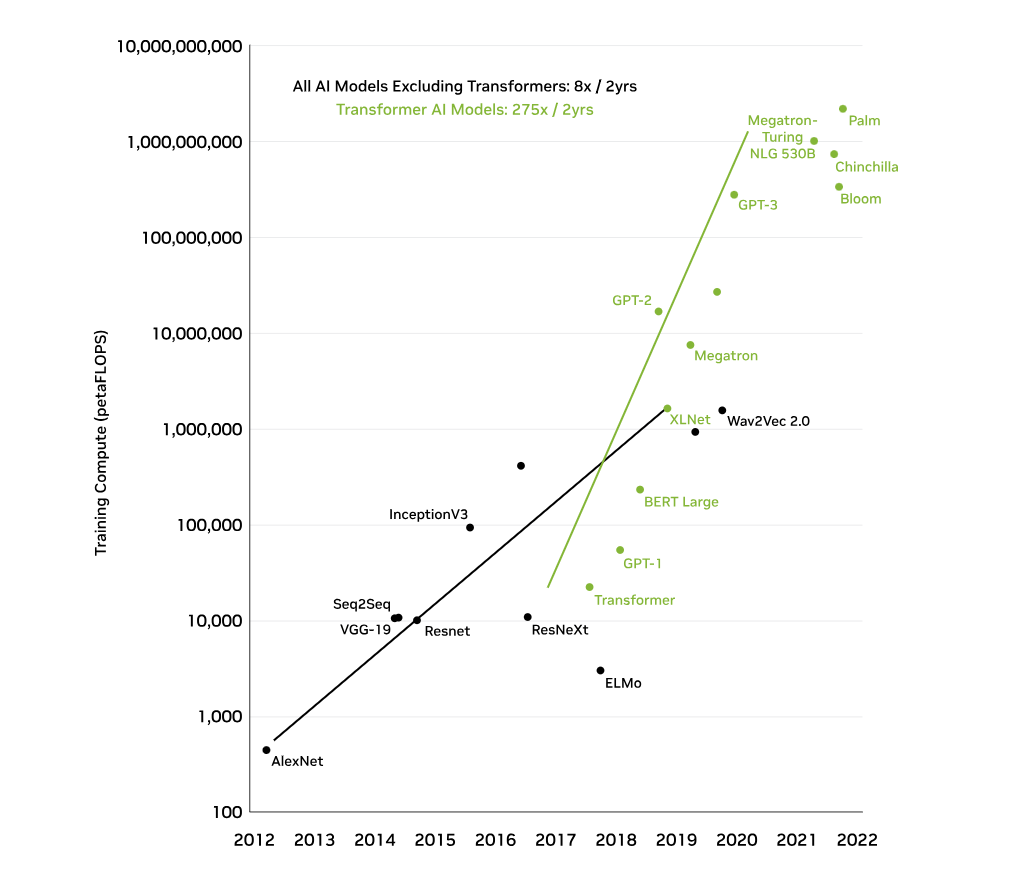
图3。训练变压器模型所需的计算。
- 计算、成本和时间密集型工作量:维护和开发LLM需要大量的资本投资、技术专业知识和大规模的计算基础设施。培训LLM需要数千个GPU和数周到数月的专门培训时间。一些估计表明,在3000亿个代币上训练的具有1750亿个参数的GPT-3模型的一次训练运行,仅计算成本就可能超过1200万美元。
- 所需数据的规模:如前所述,训练一个大型模型需要大量的数据。许多公司都很难访问足够大的数据集来训练他们的大型语言模型。对于需要私人数据(如财务或健康数据)的用例来说,这个问题更加复杂。事实上,训练模型所需的数据可能根本不存在。
- 技术专长:由于其规模,培训和部署大型语言模型非常困难,需要对深度学习工作流程、转换器、分布式软件和硬件有很强的了解,以及同时管理数千个GPU的能力。
- 登录 发表评论
- 101 次浏览
最新内容
- 1 week ago
- 1 week 4 days ago
- 1 month 4 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago