
在这个博客系列中,我们将探讨最终的一致性,如果没有合适的词汇表,这个术语很难定义。这是许多分布式系统使用的一致性模型,包括XDB Enterprise edition。理解最终一致性需要两个概念:暗示切换队列和反熵,这两个概念都值得特别关注。
注:
本系列的第一部分深入讨论了最终一致性的概念以及它在分布式计算中的重要性。你可以在这里读第一部分来复习。
第二部分
什么是反熵?
如果您阅读了本系列第一部分中的暗示切换队列,您已经知道暗示切换队列如何在数据节点中断期间保存数据并帮助您确保最终的一致性,但是在分布式系统中有很多方法会出错。尽管我们尽了最大的努力,仍然有丢失数据的方法,我们希望尽可能减少这种情况。进入保持最终一致性的后半部分:反熵(AE)。
如果我们反对熵,我们应该知道它是什么。根据互联网和我那些有科学头脑的朋友的说法,熵是由热力学第二定律定义的。基本上,随着时间的推移,有序系统趋向于更高的熵状态;因此,熵越高,无序越大。我们反对时间序列数据中的无序,因此反对熵。
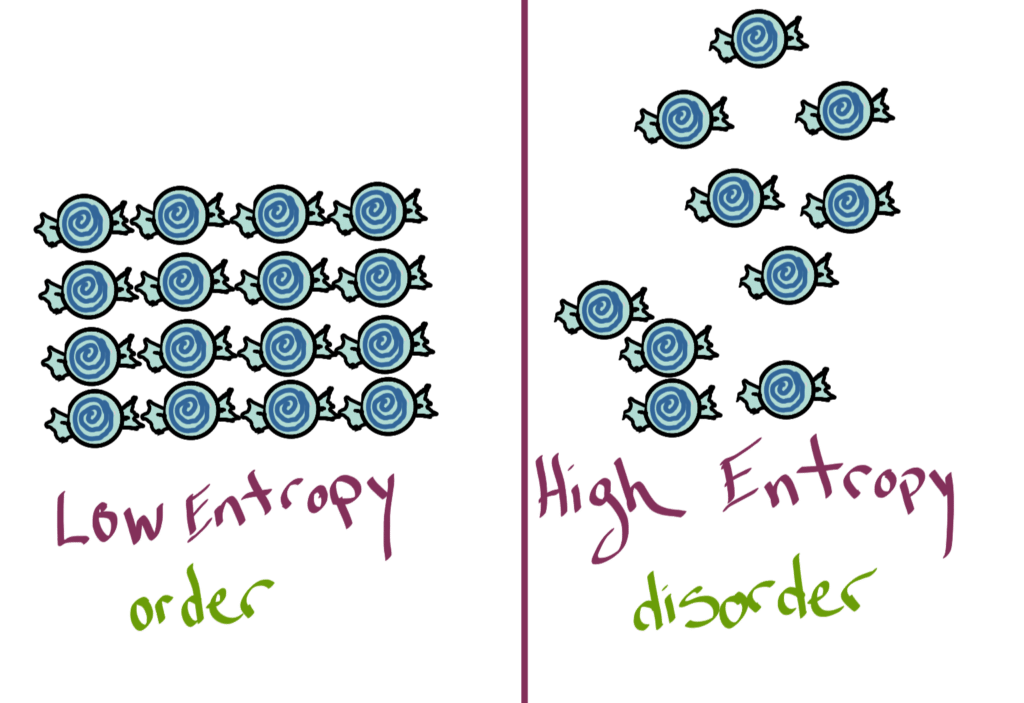
忘记任何恐吓因素这个词本身有反熵只是一个服务,我们可以运行在XDB企业中检查不一致性。我们知道,当我们收到来自系统的信息时,我们可能会要求得到一致的答案。由于引入“漂移”的方式多种多样,我们需要一个能够识别和修复底层数据差异的英雄。AE可以成为那个英雄。
例1
让我们回到我们的经典集群:包含2个数据节点和一个复制因子为2的数据库的XDB Enterprise。
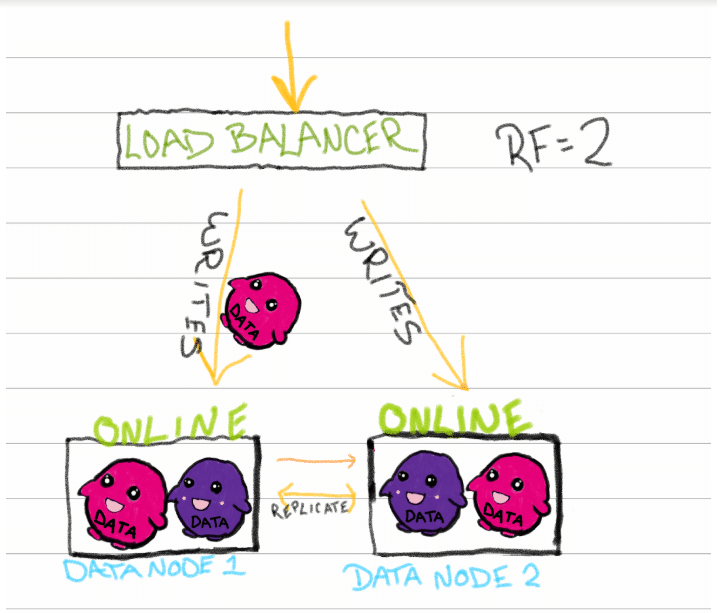
系统运行良好,发送数据以进行存储和复制。对于我们的数据来说,这是一个幸福的时刻,但有时我们必须努力做到这一点。分布式系统经常变化,而处理这种变化往往首先会干扰一致性。
系统中最常见的变化之一是硬件,所以让我们探索一条新的和改进的AE可以发挥作用的途径。假设节点2有一些坏硬件。也许它有缺陷或只是旧的,但它放弃了鬼魂在半夜(因为它当然会在半夜)。

当节点2脱机时,任何新的写入都会发送到HHQ,在那里它们等待节点2再次可用。读取被定向到节点1,它拥有与节点2相同的所有数据(因为我们的RF=2)。
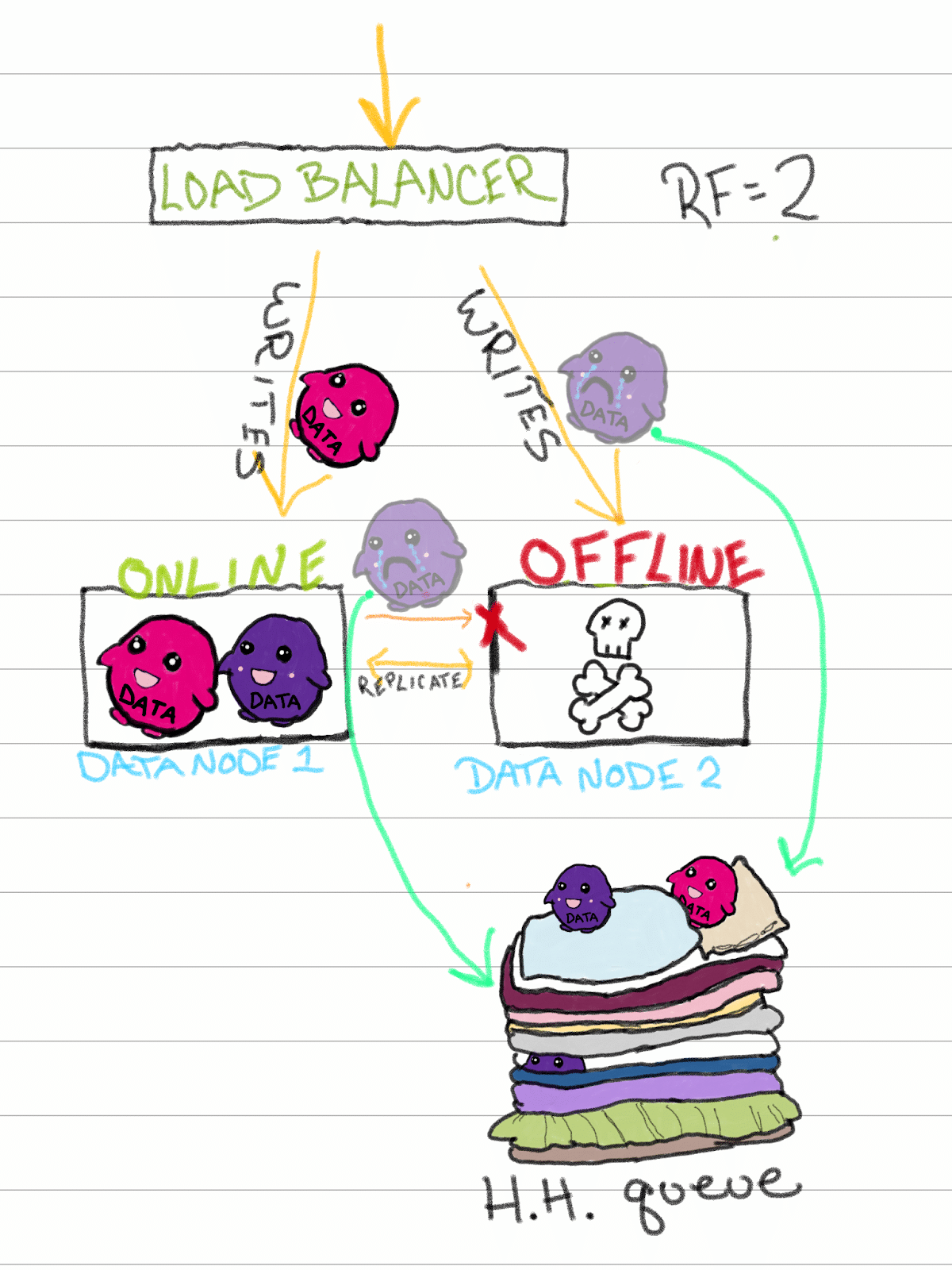
这是我们的英雄,反熵的起源故事,它是作为我们能想到的所有边缘案例的解决方案而开发的,希望还有很多我们没有想到的。

在我们的示例中,我们的首要任务是使节点2重新联机,以便它可以恢复在系统中读取和写入数据的正确位置。我们可以使用InfluxDB Enterprise中的“replace node”命令将node 2与其新硬件重新连接起来。
在这种情况下,AE检查复制因子和碎片分布的组合,以查看是否所有应该存在的碎片都得到了适当的复制。在这种情况下,由于节点2有一个新的、快速的、空的且无缺陷的SSD,因此节点1上存在的所有碎片都被复制到节点2,并且HHQ中等待的任何数据都会被快速排出。我们的AE英雄已经确保两个节点返回相同的信息,并且存在适当数量的副本。哈扎!
例2
HHQ有一些实际的限制,但它不能永远保持。在XDB Enterprise中,它默认为10GB,这意味着如果大小超过10GB,最早的点将被删除,以便为新数据腾出空间。或者,如果数据在HHQ中存放的时间太长(xdb Enterprise中的默认值是168hrs),它将被丢弃。HHQ是为了临时中断和修复,可以很快解决,所以它不应该无限期地填补。它解决了最常见的情况,但HHQ只能承担这么多的负担。

在“故障”时间较长的场景中,我们希望相同的两个节点之间存在更大的数据漂移空间。如果一个节点关闭并且在很长一段时间内未被检测到,HHQ可能会超过存储、时间限制、并发或速率限制,在这种情况下,它要转发的数据将消失在遗忘中。不太理想。当然,可能会发生大量潜在的边缘情况:HHQ和AE服务的目标是提供一种方法,以确保最终的一致性,而不需要人类付出最小的努力。
在其他系统中,一旦节点2消失,用户就有责任确保节点得到修复并恢复到一致的状态,可能是通过手动识别和复制数据。说实话:谁有时间?我们有工作要做,还有华夫饼要吃。

从XDB Enterprise 1.5开始,AE检查集群中的每个节点,看看它是否拥有meta store所说的所有碎片。区别在于,如果缺少任何碎片,AE会从另一个拥有数据的节点复制现有碎片。任何丢失的碎片都会被服务自动复制。从XDB Enterprise 1.6开始,可以指示AE服务跨节点检查碎片中包含的数据的一致性。如果发现任何不一致,AE可以修复这些不一致。
在我们的第二个示例中,AE服务将节点1和2与从数据节点上的碎片构建的摘要进行比较。然后它会报告节点2丢失了信息,然后使用相同的摘要找出它应该拥有的信息。然后它将从好的shard节点1复制信息,以在节点2上填充它。砰!最终的一致性。
从更基本的角度来说,AE服务现在可以识别丢失或不一致的碎片并修复它们。这是自愈的最佳状态。不用担心集群的当前状态,我们可以调查失败的原因(在本例中,我们可能是在睡觉或吃华夫饼,尽管这并不总是那么简单)。
关于AE有一些重要的事情要知道。AE只能在至少有一个碎片副本可用时执行其英雄行为。在我们的示例中,RF为2,因此我们可以依赖Node 1来复制健康的shard。如果节点2有该碎片的部分副本,则比较这些碎片,然后在节点之间交换任何丢失的数据,以确保返回一致的答案。如果用户选择RF为1,那么他们会选择节省存储空间,但会错过高可用性,并且会受到更有限的查询量的限制。这也意味着AE将无法进行修复,因为一旦数据不一致,就没有真相的来源了。另一个警告是AE不会比较或修复热碎片,这意味着碎片不能有活动写入。热碎片更容易改变,在任何给定的时刻,新数据的到来都会影响AE的摘要比较。当碎片变冷或不活动时,数据不会改变,AE服务可以更准确地比较摘要。
摘要
最终一致性是一个保证高可用性的模型,如果我们的数据一直可用,那么它需要一直保持准确。像任何优秀的超级英雄组合一样,HHQ和AE在一起更好,在后台打击数据不一致的犯罪,这样我们就可以信任我们的数据,继续处理对我们来说重要的事情(即华夫饼)。

原文:https://www.influxdata.com/blog/eventual-consistency-anti-entropy/
本文:http://jiagoushi.pro/node/1455
讨论:请加入知识星球【首席架构师圈】或者微信【jiagoushi_pro】或者QQ群【11107777】
- 登录 发表评论
- 285 次浏览
最新内容
- 2 days 14 hours ago
- 1 week 3 days ago
- 2 weeks ago
- 2 months ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago