
category
介绍
在当今世界,机器学习已成为一个热门且令人兴奋的研究领域。机器学习模型现在可以学习并更准确地预测甚至看不见的数据的结果。机器学习中的思想与人工智能和许多其他相关技术重叠并相互接受。今天,机器学习是从模式识别和计算机可以学习而无需明确编程来执行特定任务的概念发展而来的。我们可以使用机器学习算法(例如逻辑回归、朴素贝叶斯等)来识别口语单词、挖掘数据、构建从数据中学习的应用程序等等。此外,这些算法的准确性会随着时间的推移而提高。
在本文中,您将探索生成模型与判别模型之间的差异,了解生成模型与鉴别模型的细微差别,并在实际应用中发现判别模型与生成模型的示例。
学习目标
- 了解基本的判别和生成模型
- 了解判别模型和生成模型之间的差异,以及何时使用每种模型
- 探索模型的方法
- 探索一些判别和生成模型的例子
本文作为数据科学博客马拉松的一部分发表。
目录
- Understanding Machine Learning Models
- What Are Discriminative Models?
- What Are Generative Models?
- Difference Between Generative vs Discriminative Models
- Application Based Differences: Generative vs Discriminative Models
理解机器学习模型
机器学习模型可分为两类:判别型和生成型。简单地说,判别模型基于条件概率对看不见的数据进行预测,可用于分类或回归问题陈述。相反,生成模型侧重于数据集的分布,以返回给定示例的概率。
机器学习模型
作为人类,我们在学习人工语言时可以采用两种不同的机器学习模型方法中的任何一种。这两种模型以前从未在人类学习中被探索过。然而,它与因果方向、分类与推理学习、观察与反馈学习的已知效应有关。因此,在这篇文章中,我们的重点是两种类型的机器学习模型——生成型和判别型,并考虑到生成型和鉴别型模型等方面,了解这两种模型的重要性、比较和差异。
问题表述
假设我们正在处理一个分类问题,我们的任务是根据特定电子邮件中的单词来决定一封电子邮件是否是垃圾邮件。为了解决这个问题,我们有一个联合模型。
- Labels: Y=y, and
- Features: X={x1, x2, …xn}
因此,模型的联合分布可以表示为
p(Y,X) = P(y,x1,x2…xn)
现在,我们的目标是估计垃圾邮件的概率,即P(Y=1|X)。生成模型和判别模型都可以解决这个问题,但方式不同。
让我们看看为什么以及它们是如何不同的!
生成模型的方法
在生成模型的情况下,为了找到条件概率P(Y|X),他们在训练数据的帮助下估计先验概率P(Y)和似然概率P(X|Y),并使用贝叶斯定理计算后验概率P(Y|X):
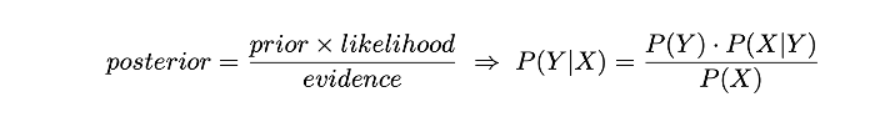
生成模型方法[机器学习模型]
判别模型的方法
在判别模型的情况下,为了找到概率,它们直接假设P(Y|X)的某种函数形式,然后在训练数据的帮助下估计P(Y| X)的参数。
什么是判别模型?
判别模型是指统计分类中使用的一类模型,主要用于监督机器学习。这些类型的模型也被称为条件模型,因为它们学习数据集中类或标签之间的边界。
判别模型侧重于对分类问题中类之间的决策边界进行建模。目标是学习一个将输入映射到二进制输出的函数,指示输入的类标签。最大似然估计通常用于估计判别模型的参数,例如逻辑回归模型的系数或神经网络的权重。
判别模型(就像字面意思一样)将类分开,而不是对条件概率进行建模,并且不对数据点做出任何假设。但这些模型无法生成新的数据点。因此,判别模型的最终目标是将一个类与另一个类分开。
如果数据集中存在一些异常值,那么与生成模型相比,判别模型的工作效果更好,即判别模型对异常值更稳健。然而,这些模型的一个主要缺点是错误分类问题,即错误地对数据点进行分类。
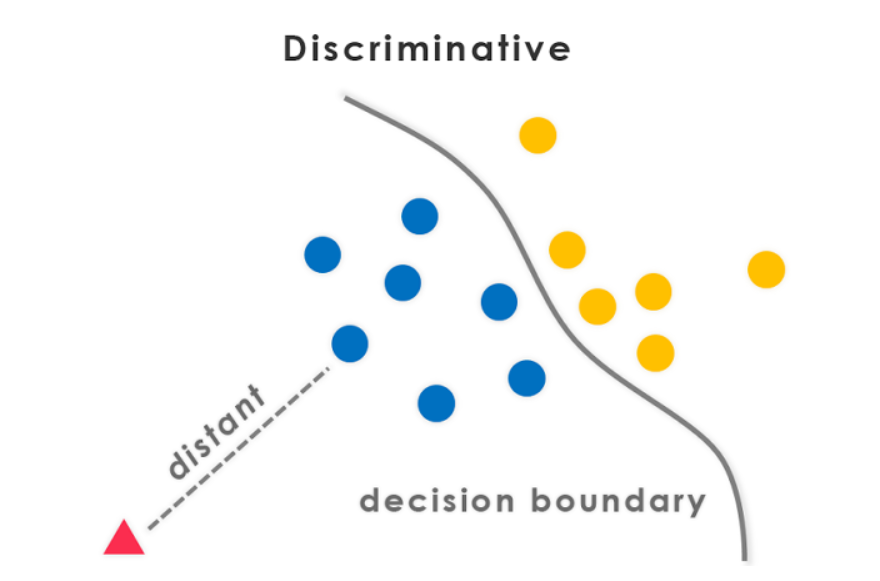
什么是判别模型?
图片来源:medium.com
判别模型的数学
训练判别分类器或判别分析涉及估计函数f:X->Y或概率P(Y|X)
假设概率的某种函数形式,例如P(Y|X)
借助训练数据,我们估计了P(Y|X)的参数
判别模型示例
- 逻辑回归
- 支持向量机(SVM)
- 传统神经网络
- 最近的邻居
- 条件随机字段(CRF)
- 决策树与随机森林
什么是生成模型?
生成模型是一种机器学习模型,可以学习生成与训练数据类似的新数据样本。它们捕获数据的潜在分布,并可以生成新的实例。生成模型在图像合成、数据增强和生成逼真的内容(如图像、音乐和文本)中得到了应用。
生成模型被认为是一类可以生成新数据实例的统计模型。这些模型用于无监督机器学习,作为执行以下任务的一种手段:
- 概率和似然估计,
- 建模数据点
- 为了描述数据中的现象,
- 根据这些概率区分类别。
由于这些模型通常依赖贝叶斯定理来找到联合概率,因此生成模型可以处理比类似的判别模型更复杂的任务。
因此,生成方法侧重于数据集中单个类的分布,学习算法倾向于对数据点的潜在模式或分布进行建模(例如高斯)。这些模型使用联合概率的概念,并创建给定特征(x)或输入和所需输出或标签(y)同时存在的实例。
这些模型使用概率估计和似然性来对数据点进行建模,并区分数据集中存在的不同类别标签。与判别模型不同,这些模型还可以生成新的数据点。
然而,它们也有一个主要的缺点——如果数据集中存在异常值,那么它会在很大程度上影响这些类型的模型。
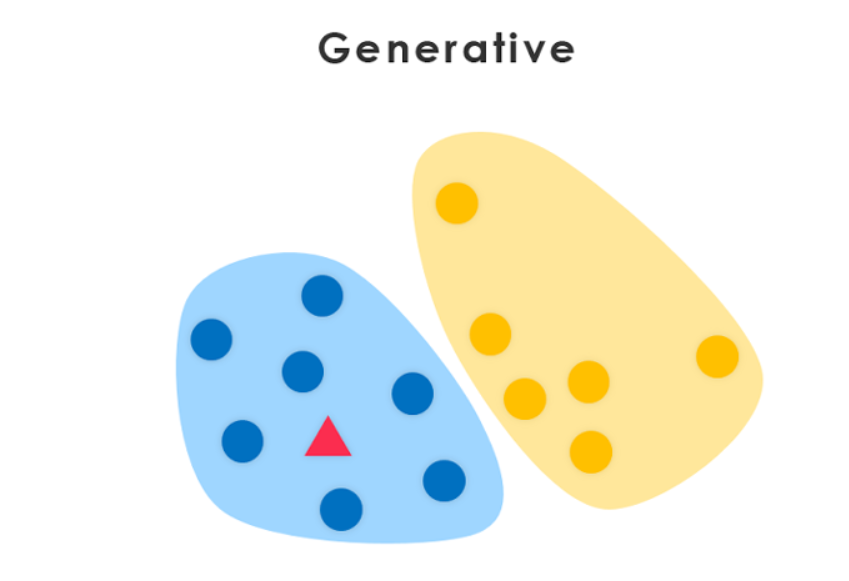
图片来源:medium.com
生成
生成模型的数学
训练生成分类器涉及估计函数f:X->Y或概率P(Y|X):
- 假设概率的某种函数形式,如P(Y),P(X|Y)
- 借助训练数据,我们估计了P(X|Y)、P(Y)的参数
- 使用贝叶斯定理计算后验概率P(Y|X)
生成模型示例
- 朴素贝叶斯
- 贝叶斯网络
- 马尔可夫随机场
- 隐马尔可夫模型(HMM)
- 潜在狄利克雷分配(LDA)
- 生成对抗网络(GANs)
- 自回归模型
生成模型与判别模型的区别
让我们看看生成模型和判别模型之间的一些差异:
| Aspect | Generative Models | Discriminative Models |
|---|---|---|
| Purpose | Model data distribution | Model conditional probability of labels given data |
| Use Cases | Data generation, denoising, unsupervised learning | Classification, supervised learning tasks |
| Common Examples | Variational Autoencoders (VAEs), Generative Adversarial Networks (GANs) | Logistic Regression, Support Vector Machines, Deep Neural Networks |
| Training Focus | Maximize likelihood of observed data, Capture data structure | Learn decision boundary, Differentiate between classes |
| Example Task | Image generation, Inpainting (e.g., GANs, VAEs) | Text classification, Object detection (e.g., Deep Neural Networks) |
现在,让我们看看这两个模型之间的具体区别:

生成模型与判别模型
图片来源:betterprograming.pub
核心理念
判别模型在数据空间中划定边界,而生成模型则试图对数据在整个空间中的放置方式进行建模。生成模型解释了数据是如何生成的,而判别模型则侧重于预测数据的标签。
数学直觉
用数学术语来说,判别式机器学习训练一个模型,这是通过学习最大化条件概率P(Y|X)的参数来完成的。另一方面,生成模型通过最大化P(X,Y)的联合概率来学习参数。
应用
判别模型识别现有数据,即判别建模识别标签并对数据进行排序,可用于对数据进行分类,而生成建模则产生一些结果。
由于这些模型使用不同的机器学习方法,因此都适用于特定的任务,即生成模型可用于无监督学习任务。相比之下,判别模型对监督学习任务很有用。GAN(生成对抗网络)可以被认为是生成器(生成模型的一个组成部分)和鉴别器之间的竞争,所以基本上,它是生成与鉴别模型。
异类
生成模型比判别模型对异常值的影响更大。
计算成本
与生成模型相比,判别模型在计算上更便宜。
基于应用的差异:生成模型与判别模型
让我们看看基于以下标准的生成模型与判别模型之间的一些比较:
基于性能
与判别模型相比,生成模型需要更少的数据来训练,因为生成模型在做出更强的假设(即条件独立性假设)时更具偏见。
基于缺失数据
一般来说,如果我们的数据集中有缺失的数据,那么生成模型可以处理这些缺失数据,而判别模型则不能。这是因为,在生成模型中,我们仍然可以通过边缘化看不见的变量来估计后验值。然而,判别模型通常需要观察所有特征X。
基于准确度得分
如果条件独立性的假设违反了,那么在那个时候,生成模型的准确性不如判别模型。
结论
总之,判别模型和生成模型是机器学习的两种基本方法,已被用于解决各种任务。判别方法侧重于学习类之间的决策边界,而生成模型用于对底层数据分布进行建模。了解判别模型和生成模型之间的区别有助于我们更好地决定在特定任务中使用哪种方法来构建更准确的机器学习解决方案。
希望你喜欢这篇文章!生成模型与判别模型代表了机器学习中的两种基本方法。生成模型通过估计联合概率分布来创建新数据,而判别模型则侧重于通过估计条件概率来对数据进行分类。示例包括用于生成的高斯混合模型和用于判别模型的支持向量机,突出了它们在分类和数据生成等任务中的不同应用。
关键要点
- 判别模型学习类之间的决策边界,而生成模型旨在对底层数据分布进行建模。
- 判别模型通常比生成模型更简单、训练更快,但在底层数据分布复杂或不确定的任务上可能表现不佳。
- 生成模型可用于更广泛的任务,包括图像和文本生成,但可能需要更多的训练数据和计算资源。
- 登录 发表评论
- 172 次浏览
最新内容
- 1 day 18 hours ago
- 2 weeks 1 day ago
- 3 weeks 2 days ago
- 3 weeks 6 days ago
- 2 months 2 weeks ago
- 6 months 1 week ago
- 6 months 1 week ago
- 6 months 1 week ago
- 6 months 1 week ago
- 6 months 1 week ago