
我领导着一个与电动汽车制造商合作的大数据团队,我已经尝试了市场上可用的OLAP工具。阅读下面的内容,了解我认为您需要了解的关于这些工具的内容,包括许多OLAP工具的优缺点以及我在OLAP方面的经验。
讨论的OLAP工具:
- Apache Druid (and Apache Kylin)
- TiDB
- ClickHouse
- Apache Doris
Apache Druid(和Apache Kylin)
早在2017年,在市场上寻找OLAP工具就像在非洲大草原上寻找一棵树一样——只有少数。当我们抬头扫视地平线时,我们的目光停留在阿帕奇·德鲁伊和阿帕奇·凯林身上。我们之所以选择Druid,是因为我们已经对它很熟悉了,而Kylin尽管在预计算中具有令人印象深刻的高查询效率,但也有一些缺点。
Kylin的缺点:
- Kylin最好的存储引擎是HBase,但引入HBase会带来新的操作和维护负担。
- Kylin预先计算了维度和度量,但它带来的维度爆炸给存储带来了巨大压力。
至于Apache Druid,它使用了列式存储,支持实时和离线数据接收,并提供了快速查询。
另一方面,Druid:
- 不使用JDBC等标准协议,因此对初学者不友好。
- 对Joins的支持率很低。
- 精确重复数据消除可能较慢,从而降低性能。
- 由于许多组件需要各种安装方法和依赖关系,因此需要大量的维护工作。
- 在数据接收方面,Hadoop集成和JAR包的依赖性需要更改。
TiDB公司
2019年,我们尝试了TiDB。长话短说,以下是它的优点和缺点:
优点:
- 它是一个OLTP+OLAP数据库,支持简单的更新。
- 它具有我们需要的功能,包括聚合和细分查询、度量计算和仪表板。
- 它支持标准SQL,因此很容易掌握。
- 它不需要太多的维护。
缺点:
- TiFlash依赖OLTP这一事实可能会给存储带来更大的压力。作为一个非独立的OLAP,其分析处理能力并不理想。
- 它的性能因场景而异。
ClickHouse与Apache Doris之争
我们对ClickHouse和Apache Doris进行了研究。ClickHouse出色的独立性能给我们留下了深刻印象,但当我们发现:
- 当涉及到多表联接时,它并没有给我们想要的东西,这对我们来说是一个重要的用法。
- 它的并发性相对较低。
- 这可能会带来高昂的运营和维护成本。
另一方面,Apache Doris在我们的需求列表中勾选了很多框:
- 它支持高并发查询,这是我们最关心的问题。
- 它能够同时进行实时和离线数据处理。
- 它同时支持聚合查询和细分查询。
- 它的Unique模型(Doris中的一种数据模型,确保了唯一的密钥)支持更新。
- 它可以通过Materialized View大大加快查询速度。
- 它与MySQL协议兼容,因此在开发和采用方面几乎没有问题。
- 它的查询性能令人满意。
- 它只需要简单的运维。
总之,Apache Doris似乎是Apache Druid+TiDB的理想替代品。
我们的OLAP实践经验
以下是一张图表,向您展示数据是如何在我们的OLAP系统中流动的:

数据源
我们将来自业务系统、事件跟踪、设备和车辆的数据汇集到我们的大数据平台中。
数据导入
我们为我们的业务数据启用CDC。这些数据中的任何更改都将转换为数据流并存储在Kafka中,为流计算做好准备。对于只能批量导入的数据,它将直接进入我们的分布式存储。
数据处理
我们采用了Lambda架构,而不是集成、流式处理和批处理。我们的业务现状决定了我们的实时和离线数据来自不同的环节。特别地:
- 有些数据是以流的形式出现的。
- 有些数据可以存储在流中,而有些历史数据则不会存储在卡夫卡中;
- 某些场景需要高数据精度。为了实现这一点,我们有一个离线管道,可以重新计算和刷新所有相关数据。
数据仓库
我们没有使用Flink/Spark Doris连接器,而是使用Routine Load方法将数据从Flink传输到Doris,并使用Broker Load将数据从Spark传输到Dors。Flink和Spark批量生成的数据将备份到Hive,以便在其他场景中使用。这是我们提高数据效率的方法。
数据服务
在数据服务方面,我们通过数据源注册和灵活配置实现了API的自动生成,因此我们可以通过API管理流量和权限。与K8s无服务器解决方案相结合,整个过程非常有效。
数据应用程序
在数据应用层,我们有两种类型的场景:
- 面向用户的场景,如仪表板和指标。
- 面向车辆的场景,将车辆数据收集到Apache Doris中进行进一步处理。即使在聚合之后,我们仍然有以亿为单位的数据大小,但总体计算性能达到了标准。
我们的CDP实践
与大多数公司一样,我们建立了自己的客户数据平台(CDP):
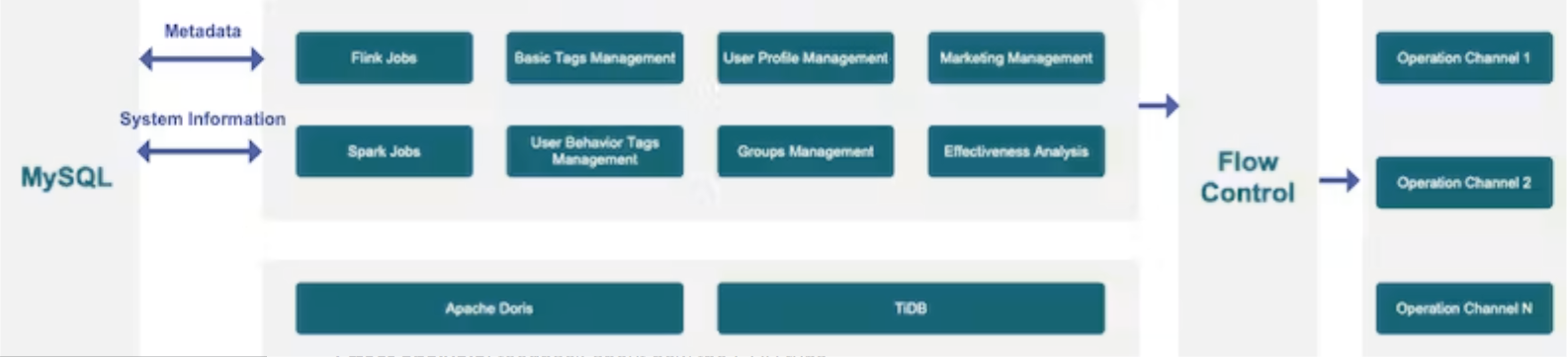
通常,CDP由几个模块组成:
- 标签:积木,显然;(我们有基本标签和客户行为标签。我们也可以根据需要定义其他标签。)
- 分组:根据标签将客户分组。
- 见解:每个客户群体的特点。
- 联系:联系客户的方式,包括短信、电话、应用程序通知和即时消息。
- 效果分析:关于CDP如何运行的反馈。
我们希望在CDP中实现实时+离线集成、快速分组、快速聚合、多表联接和联合查询。以下是它们的操作方法:
实时+离线
我们有实时标签和离线标签,我们需要将它们放在一起。此外,同一数据上的列可能会以不同的频率更新。一些基本标签(关于客户身份)应该实时更新,而其他标签(年龄、性别)可以每天更新。我们希望将客户的所有原子标签放在一个表中,因为这样可以带来最少的维护成本,并且在添加自定义标签时可以大大减少所需的表的数量。
那么我们如何实现这一点呢?
我们使用Apache Doris的Routine Load方法更新实时数据,使用Broker Load方法批量导入离线数据。我们还使用这两种方法分别更新同一表中的不同列。
快速分组
基本上,分组就是将某一组标签组合起来,找到重叠的数据。这可能很复杂。Doris通过SIMD优化帮助加快了这一过程。
快速聚合
我们需要更新所有标签,重新计算客户群体的分布,并每天分析影响。这样的处理需要快速而整洁。因此,我们根据时间将数据划分为平板电脑,这样就可以减少数据传输,加快计算速度。在计算客户组的分布时,我们在每个节点预聚合数据,然后收集它们进行进一步聚合。此外,Doris的矢量化执行引擎是一个真正的性能加速器。
多表联接
由于我们的基础数据存储在多个数据表中,当CDP用户自定义他们需要的标签时,他们需要进行多表联接。吸引我们使用ApacheDoris的一个重要因素是它有前途的多表联接功能。
联合查询
目前,我们将Apache Doris与TiDB结合使用。关于客户接触的记录将被放入TiDB中,关于信用点和代金券的数据也将在TiDB中处理,因为它是一个更好的OLTP工具。对于更复杂的分析,例如监控客户运营的有效性,我们需要整合有关任务执行和目标群体的信息。这就是我们在Doris和TiDB之间进行联合查询的时候。
结论
这是我们从Apache Druid、TiDB和Apache Doris的旅程(中间是对ClickHouse的简短介绍)。我们研究了它们的性能、SQL语义、系统兼容性和维护成本,最终得出了我们现在的OLAP体系结构。如果你和我们有同样的担忧,这可能是你的参考。
最新内容
- 2 hours ago
- 1 week 1 day ago
- 1 week 5 days ago
- 1 month 4 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago