
category
TL;DR:
- LLM通过基于先前的令牌预测下一个令牌来生成输出,使用logits向量来表示每个令牌的概率。
- 贪婪解码、波束搜索和采样策略(top-k、top-p)等后处理技术控制如何详细确定下一个令牌,在可预测性和创造性之间取得平衡。
- 先进的技术,如频率和存在惩罚、logit偏差和结构化输出(通过即时工程或微调),通过考虑令牌概率之外的信息,进一步细化LLM的输出。
如果你深入研究过像ChatGPT、Llama或Mistral这样的大型语言模型(LLM),你可能已经注意到调整输入参数可以改变你得到的响应。这些模型能够提供广泛的输出,从创造性的叙述到结构化的JSON。这种多功能性使LLM对各种应用程序非常有用,从激发作者的创造力到简化数据处理。
所有这些都是可能的,这要归功于LLM中编码的大量信息,以及通过微调和提示对其进行调整的可能性。我们可以通过“温度”或“频率惩罚”等参数进一步控制LLM的输出,这些参数会逐个令牌地影响LLM的输出来。
更广泛地了解这些参数和输出后处理技术可以显著提高LLM在特定应用中的实用性。例如,改变温度设置可以改变多样性和可预测性之间的平衡,而调整频率惩罚有助于最大限度地减少重复。
在本文中,我们将详细介绍LLM如何生成其输出,以及我们如何影响这一过程。一路走来,您将学到:
- LLM如何使用logits向量和softmax函数生成输出。
- 贪婪解码、波束搜索和采样后处理技术如何确定下一个要输出的令牌。
- 如何通过top-k采样、top-p采样以及调整softmax温度来平衡可变性和一致性。
- 频率惩罚、logit偏差和结构化输出等先进技术如何让您对LLM的输出有更多的控制权。
- 在LLM空间中实现后处理技术时,典型的挑战是什么,以及如何解决这些挑战。
LLM如何生成输出?
在我们深入研究定制LLM输出的后处理技术之前,首先了解LLM是如何生成其输出的至关重要。
一般来说,当我们谈论LLM时,我们指的是自回归语言模型。这些模型仅基于先前的令牌来预测下一个令牌。但是,它们不会直接输出令牌。相反,他们生成一个logits向量,在应用softmax函数后,该向量可以被解释为词汇表中每个标记的概率。

说明使用大型语言模型(LLM)生成文本的过程。处理令牌的输入序列以产生logits向量,logits向量表示每个潜在下一个令牌的未规范化概率。然后,使用softmax函数将这些logits转换为实际概率,确定输入后每个令牌的可能性。|来源:作者
每个生成步骤都会发生此过程。为了在输出中生成下一个令牌,我们取迄今为止生成的令牌序列,将其输入LLM,并根据softmax函数的输出选择下一个代币。
我们可以通过操纵、细化或约束模型的logits或概率来提高LLM的输出。总的来说,我们将这种技术称为“后处理技术”——这就是我们将在以下章节中介绍的内容。
LLM的后处理技术
贪婪的解码(Beam search)
在这一点上,你可能会想:“如果我有概率,我只需要选择概率最高的代币,就这样。”如果你想到了这一点,你就想到了贪婪解码。这是最简单的算法。我们将概率最高的代币作为下一个代币,并以相同的方式继续选择后续代币。
让我们看一个例子:
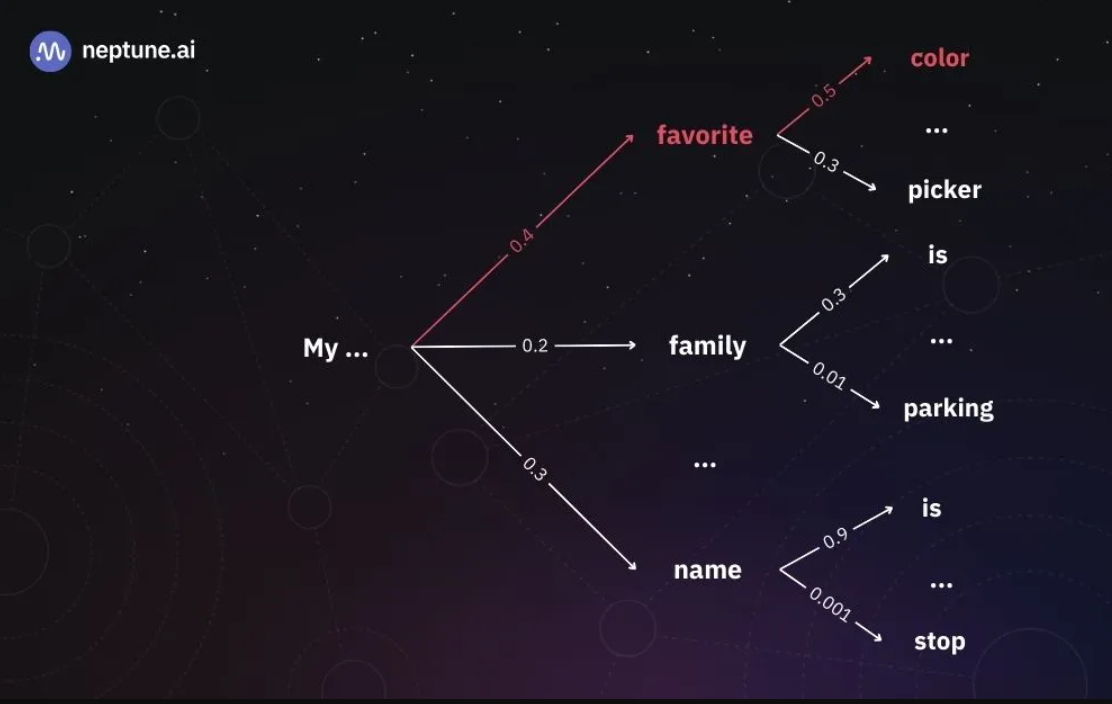
使用贪婪解码生成LLM的输出。在红色中,我们可以看到贪婪解码算法选择的令牌序列。下一个令牌总是具有最高相对概率的令牌。|来源:作者
在上图中,我们可以看到我们以“My”作为初始标记。在第一代步骤中,最有可能的下一个令牌是“收藏夹”,所以我们选择它并将“我的收藏夹”输入到模型中。在接下来的生成步骤中,最可能的标记是“颜色”,剩下“我最喜欢的颜色”作为LLM的输出。
贪婪解码被广泛用于寻找可复制的结果,也称为确定性结果。然而,尽管我们总是选择概率最高的代币,但我们不一定最终得到总体上最有可能的序列。在我们上面的例子中,句子“我的名字是”的累积概率(0.27)高于“我最喜欢的颜色”(0.2)。尽管如此,我们还是选择了“最喜欢的”而不是“名字”,因为在第一代步骤中,它在所有代币中的相对概率最高。
通过在每个生成步骤中一致地选择具有最高概率的令牌,我们有时会错过“隐藏”在具有较低概率的令牌后面的具有较高概率的令牌。我们刚刚看到这种情况发生在令牌“名称”后面的令牌“is”中:“即使令牌“名称“在第一次迭代中不是最有可能的,它也隐藏了一个非常有可能的令牌。
波束搜索(Beam search)
解决隐藏在低概率令牌后面的高概率令牌丢失问题的一种方法是跟踪每一代的几个可能的下一个令牌。如果我们将n个最可能的下一个令牌保存在内存中,并在随后的生成步骤中考虑它们,我们将显著降低丢失隐藏在低概率令牌后面的高概率令牌的几率。这被称为波束搜索,是人工智能研究和计算机科学中的一种著名算法,比LLM早了几十年。
让我们看看这将如何在我们的示例中发挥作用:

使用n=2的波束搜索生成LLM的输出。在红色中,我们可以看到我们跟踪的两个标记序列(波束)。红色实线表示总概率较高的序列,红色虚线是第二大概率序列。尽管“名字”的概率比“最喜欢的”大,但我们选择“我的名字是”而不是“我最喜欢的颜色”,因为前者的总概率最高。|来源:作者
如上图所示,我们跟踪两个最可能的令牌序列。波束搜索算法将总是以比贪婪搜索更高或相等的概率找到序列。然而,这也有一个缺点:我们将不得不进行n次推理,对于我们保存在内存中的每个可能的输出序列都要进行一次推理。
同样重要的是,与贪婪搜索类似,这种方法是确定性的。当我们的目标是更多样和多样化的反应时,这可能是一个缺点。
采样(Sampling)
为了引入一点多样性,我们必须转向随机性。最常见的方法之一是根据每个生成步骤中的令牌概率分布随机选择令牌。
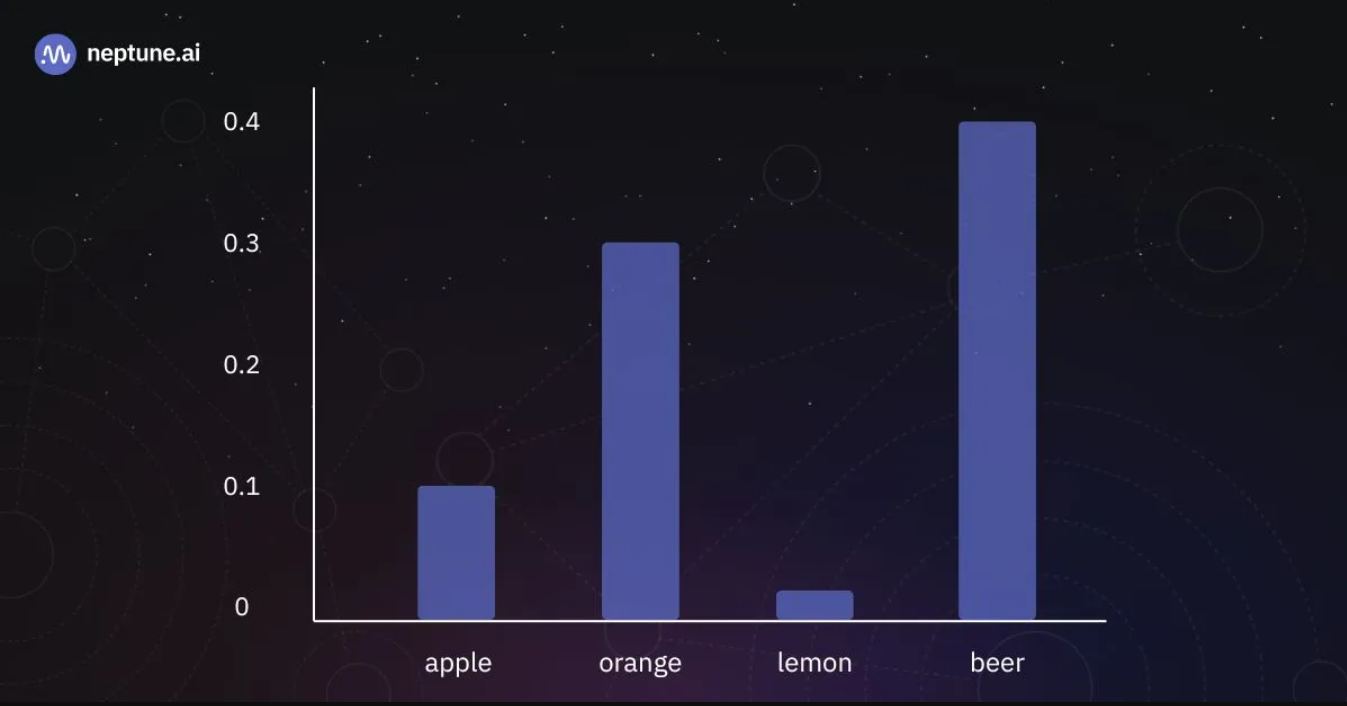
在单个生成步骤中输出令牌上的概率分布。|来源:作者
为了给出一个具体的例子,请查看上面描述的令牌概率分布。如果我们应用我们刚刚概述的采样算法,选择“啤酒”代币的可能性为40%,选择“橙色”代币的几率为30%,依此类推。然而,通过在所有代币中随机选择,我们偶尔会有出现无意义输出的风险。
Top-k采样(Top-k sampling)
为了避免选择低概率输出序列,我们可以将采样的令牌集限制为k个最可能的令牌。这种方法被称为“top-k采样”,旨在增加多样性,同时确保输出保持高度可能——因此是合理的。
在该算法中,其思想是选择前k个令牌,并在这k个令牌之间重新分配概率质量,即调整前k个代币的概率,以确保所有概率的总和保持为1。(例如,如果我们选择概率为0.35和0.25的前2个代币,在调整概率后,新值将分别为0.58和0.42。)
这还有另一个好处。由于LLM具有大量词汇表(通常为数万个令牌),因此计算softmax函数通常成本高昂,因为它涉及到计算每个输入值的指数。因此,基于它们的logits选择前k个令牌允许我们缩小将应用softmax的集合,与天真采样相比,加速了推理。

使用k=3的top-k采样生成LLM的输出。我们按值对logits进行排序,并通过仅对前3个标记(“color”、“fruit”和“song”)应用softmax函数来计算下一个标记概率。|来源:作者
虽然将采样限制在前k个令牌将以极低的概率可靠地剔除输出序列,但有两种情况达不到要求:
- 假设我们将k设置为10。如果只有三个具有高logit值的令牌,尽管它们极不可能,但我们仍将包括七个额外的令牌进行采样。事实上,由于我们正在重新分配概率质量,我们甚至(稍微)提高了它们被选中的可能性。
- 如果存在大量具有大致相同logit值的令牌,则将令牌集限制为k将排除许多同样可能的令牌。在m>k个令牌具有相同logit值的极端情况下,我们选择的令牌将是排序算法实现的工件。
顶部p采样(Top-p sampling)
top-p采样(也称为核采样)背后的概念与top-k采样相似。然而,我们不选择前k个令牌,而是选择累积概率等于或大于p的令牌集。换句话说,它基于指定的概率阈值p动态调整所考虑的令牌集的大小。
与top-k不同,top-p不利于计算效率,因为它需要计算概率才能应用算法。尽管如此,它确保在所有情况下都使用最相关的令牌。
理论上,它并不能真正解决top-k部分中描述的问题。仍然有可能包括低可能性令牌,而排除高可能性令牌。然而,在实践中,top-p已经被证明是有效的,因为所考虑的候选数量会动态地上升和下降,这与模型在词汇表上的置信区间的变化相对应,而top-k采样无法捕捉到k的任何一个选择

使用p=0.9的top-p采样生成LLM的输出。我们只选择前两个标记(“颜色”和“水果”),因为它们的累积概率超过了参数p定义的0.9的阈值。|来源:作者
这方面的一个例子可以在上图中看到,其中只有标记“颜色”和“水果”被选择,因为它们的累积概率超过了定义的阈值0.9。如果我们使用k=3的top-k采样,我们也会选择单词“停止”,这可能与输入不太相关。这说明了top-p采样如何有效地过滤掉不太相关的选项,将重点放在与上下文最相关的标记上,从而保持生成内容的一致性和相关性。
也可以同时使用top-p和top-k策略,在先满足的条件下停止生成。这种混合方法利用了这两种方法的优势:top-k将选择限制在可管理的令牌子集的能力,以及top-p通过只考虑共同满足特定概率阈值的令牌来关注相关性。
温度(Temperature)
如果你想更好地控制你的反应的“创造性”,也许最重要的调整参数是softmax函数的“温度”
通常,softmax函数由以下等式表示:
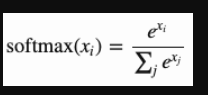
当我们引入温度参数T时,公式被修改为如下所示:
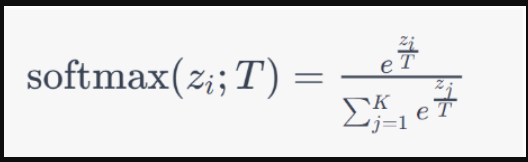
在下图中,我们可以看到改变温度T的效果:
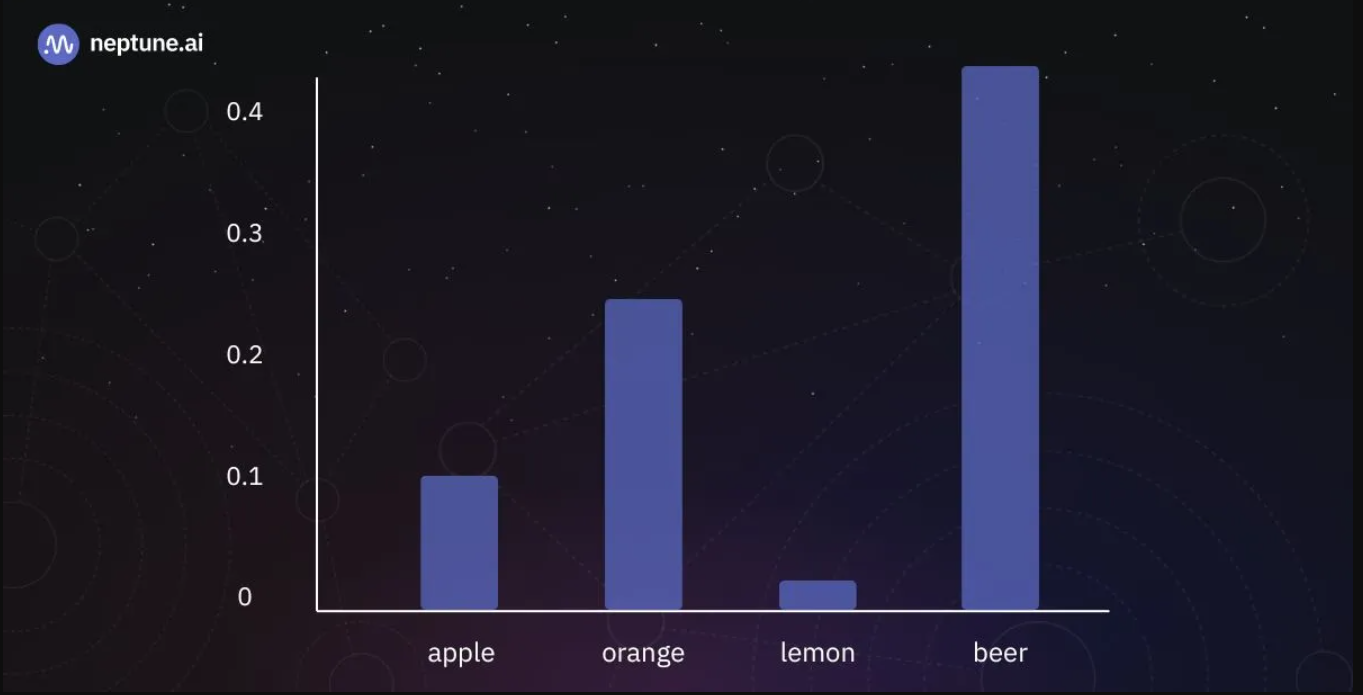
Resulting token probabilities for T=1. | Source: Author

Resulting token probabilities for T≈0. | Source: Author
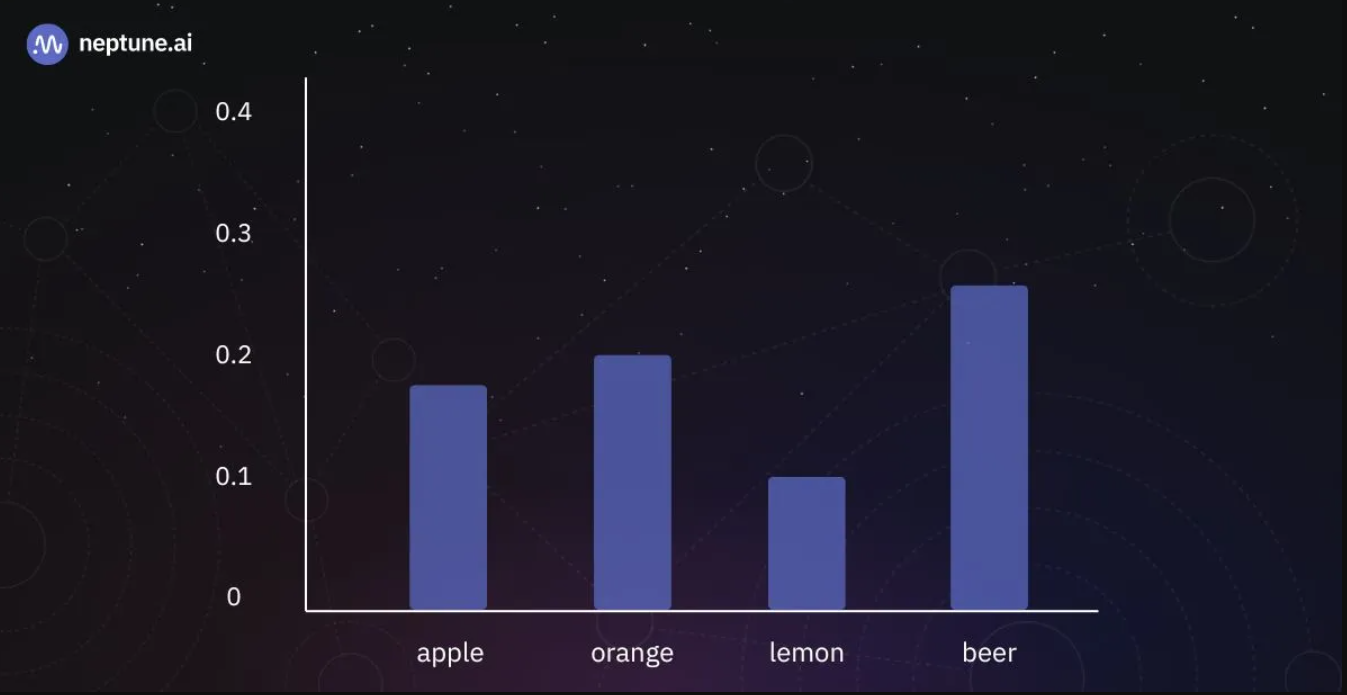
T~1.|的结果令牌概率来源:作者
如果我们设置T=1,我们将得到与以前相同的结果。然而,如果我们使用大于1的值(更高的温度),我们会减少具有高值和低值的logits的概率之间的差异,从而使可能和不可能的令牌的概率更接近。相反,我们也可以通过使用小于1的T值来做相反的事情。这将进一步有利于可能的代币,并降低不太可能的代币的概率。这种对温度的操纵允许对模型输出的多样性和可预测性进行细微的控制。
约束采样的高级技术(constraining sampling)
除了我们迄今为止讨论的技术和策略之外,还有其他方法可以调整采样的概率。在这里,我们将讨论一些用于通过softmax函数之前应用的约束来引导文本生成的技术。

将约束应用于logits的向量,生成一个新的受约束logits向量。然后将该向量馈送到softmax函数中,以产生用于采样的令牌概率。|来源:作者
频率惩罚(Frequency penalty)
如果你使用过一些较小的LLM,比如那些有几百万个参数的LLMs,或者尝试使用用一种语言训练的模型来代替另一种语言,你可能会注意到回答中的重复很常见。(如论文《不太可能训练的神经文本生成》中所述,已经对这种行为进行了详细研究。)
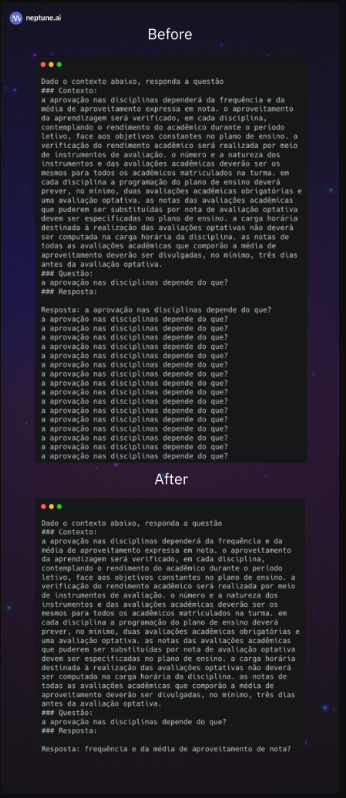
当提示葡萄牙语QA任务时,在英语文本上训练的LLM的输出。该模型一次又一次地生成相同的句子。|来源
由于这种行为在LLM中非常常见,因此惩罚已经生成的令牌以防止它们再次出现将是非常有趣的,除非它们真的有很高的发生概率。
这就是频率和在场罚分的作用所在。这些惩罚通过修改logits来起作用。具体而言,根据以下公式进行调整:
𝘈𝘥𝘫𝘶𝘴𝘵𝘦𝘥 𝘓𝘰𝘨𝘪𝘵 ═ 𝘖𝘳𝘪𝘨𝘪𝘯𝘢𝘭 𝘓𝘰𝘨𝘪𝘵 – (𝘍𝘳𝘦𝘲𝘶𝘦𝘯𝘤𝘺 𝘊𝘰𝘶𝘯𝘵 *𝘍𝘳𝘦𝘲𝘶𝘦𝘯𝘤𝘺 𝘗𝘦𝘯𝘢𝘭𝘵𝘺) – (𝘏𝘢𝘴 𝘈𝘱𝘱𝘦𝘢𝘳𝘥? * 𝘗𝘳𝘦𝘴𝘦𝘯𝘤𝘦 𝘗𝘦𝘯𝘢𝘭𝘵𝘺)
其中“原始登录”是模型对下一个令牌的初始猜测,“频率计数”是令牌被使用的次数,“是否出现?”反映令牌是否至少使用过一次,“频率惩罚”和“存在惩罚”控制原始登录的调整方式。
为了巧妙地阻止重复,可以将惩罚设置在0.1到1之间。为了获得更明显的效果,将值增加到2可以显著减少重复,尽管有影响文本自然度的风险。有趣的是,负值可以用来实现相反的效果,鼓励模型支持重复的术语,这在某些情况下是有用的。通过这个公式,LLM可以很好地平衡新颖性和重复性,确保内容保持新鲜和引人入胜,而不会变得单调。
Logit偏差
想象一下,您正试图使用LLM进行分类,其中类为“红色”、“绿色”和“蓝色”。您希望下一个令牌(要预测的令牌)是这些类中的一个,但通常会出现意外的令牌,从而中断您的工作流程。
解决这个问题的一种方法是使用一种称为logit-bias的技术,这个术语也用于OpenAI和AI21Studio的API中。该方法指定一组令牌和要添加到每个令牌的logit的偏差值,从而在预测期间改变选择该令牌的概率。

通过偏差值调整令牌概率。代币“绿色”收到+3的偏差,将其softmax计算的概率转变为最有可能的选择。|来源:作者
logit偏见的影响可能因模型和环境而异。通常,-1和1之间的偏差值可以微调选择令牌的可能性。值为-100或100可以完全取消对代币的考虑,也可以保证其选择。因此,偏差值是确保分类任务中所需结果的通用工具。
结构化输出
正如本文开头所提到的,您可能已经注意到一些LLM,如ChatGPT,可以生成JSON格式的响应。此功能可能非常有用,具体取决于您的应用程序。例如,如果您的工作流包括在文本中搜索特定实体的步骤,那么依赖可解析结构进行操作至关重要。另一个例子可以是生成SQL查询格式的输出以进行数据分析。
这些示例的共同点是期望输出具有特定的结构化格式,允许工作流的后续阶段基于这些格式执行操作。
有两种主要方法使LLM能够生成这些结构化输出:
- 提示工程:制作一个提示,指示模型应生成响应的格式。这是两种方法中比较简单的一种,因为它不需要更改模型,并且只能应用于通过API提供的模型。但是,不能保证该型号始终遵循说明。
- 微调:在特定任务的输入/输出对上进一步训练预训练的LLM。这种方法更常用于这类问题。虽然它不能完全保证产生预期的输出格式,但它比使用提示工程要可靠得多。此外,值得注意的是,由于不需要传递冗长复杂的指令,因此在推理时处理的令牌往往较少。这使得推理更快、更具成本效益。
与实施相关的挑战、解决方案和用于自定义LLM输出的工具
实现后处理算法时最困难的挑战之一是验证您的实现是否正确。LLM通常有大量的词汇表,很难知道预期的输出。
克服这一问题的最佳方法是模拟logit向量,并将算法应用于该模拟向量。通过这种方式,您可以可靠地将实际输出与预期输出进行比较。以下是如何测试贪婪解码算法的一个示例:
import numpy as np
from typing import List
# Greedy decoding algorithm
def greedy_decoding(logit_vector: np.ndarray, vocabulary: List[str]):
# Select the index with the highest score in the logit vector
max_index = np.argmax(logit_vector)
# Returning the corresponding word
return vocabulary[max_index]
vocabulary = ['hello', 'world', 'goodbye', 'the', 'is'] # Vocabulary of the model
logit_vector = np.array([2.1, 3.5, -1.2, 1.2, 0.2]) # Mocking logit vector
assert len(vocabulary) == logit_vector.shape[-1]
# Apply greedy decoding
next_token = greedy_decoding(logit_vector, vocabulary)
print("Next token:", next_token)
>> Next token: world使用numpy库在Python中测试贪婪解码算法的示例实现。不出所料,选择了logit值最高的令牌(“world”)。
然而,除非你想实现这些算法来学习,否则你不必自己实现它们。大多数LLM API和库已经包含了最常见的方法。
在OpenAI的API中,可以指定各种参数,如temperature、top_p、response_format、presence_penalty、frequency_penalty和logit_bias。Hugging Face的transformer库也实现了各种文本生成策略。
如果您的目标是更结构化的输出,您应该检查指南库的约束生成功能。指南允许您使用regex、上下文无关语法和简单提示来约束您的生成。另一个有用的工具是Coacher,它使用Pydantic模型来执行数据提取,并引入了一个名为Validator的概念,该概念使用LLM来验证输出是否匹配某些模式。
结论
在本文中,我们深入研究了用于修改LLM输出的关键技术。鉴于这一领域的蓬勃发展,新技术很可能会出现。然而,对我们讨论的方法有了扎实的理解,你应该能够掌握任何新的策略。
我希望您喜欢这篇文章,并了解到更多关于输出后处理这一经常被讨论不足的主题。如果你有机会,我鼓励你尝试这些技术,并观察它们能产生的不同结果!
- 登录 发表评论
- 290 次浏览
最新内容
- 1 week 2 days ago
- 2 weeks 3 days ago
- 3 weeks ago
- 2 months 1 week ago
- 6 months ago
- 6 months ago
- 6 months ago
- 6 months ago
- 6 months ago
- 6 months ago