
category
1.1. The Benefits of Using GPUs
The Graphics Processing Unit (GPU)1 provides much higher instruction throughput and memory bandwidth than the CPU within a similar price and power envelope. Many applications leverage these higher capabilities to run faster on the GPU than on the CPU (see GPU Applications). Other computing devices, like FPGAs, are also very energy efficient, but offer much less programming flexibility than GPUs.
This difference in capabilities between the GPU and the CPU exists because they are designed with different goals in mind. While the CPU is designed to excel at executing a sequence of operations, called a thread, as fast as possible and can execute a few tens of these threads in parallel, the GPU is designed to excel at executing thousands of them in parallel (amortizing the slower single-thread performance to achieve greater throughput).
The GPU is specialized for highly parallel computations and therefore designed such that more transistors are devoted to data processing rather than data caching and flow control. The schematic Figure 1 shows an example distribution of chip resources for a CPU versus a GPU.
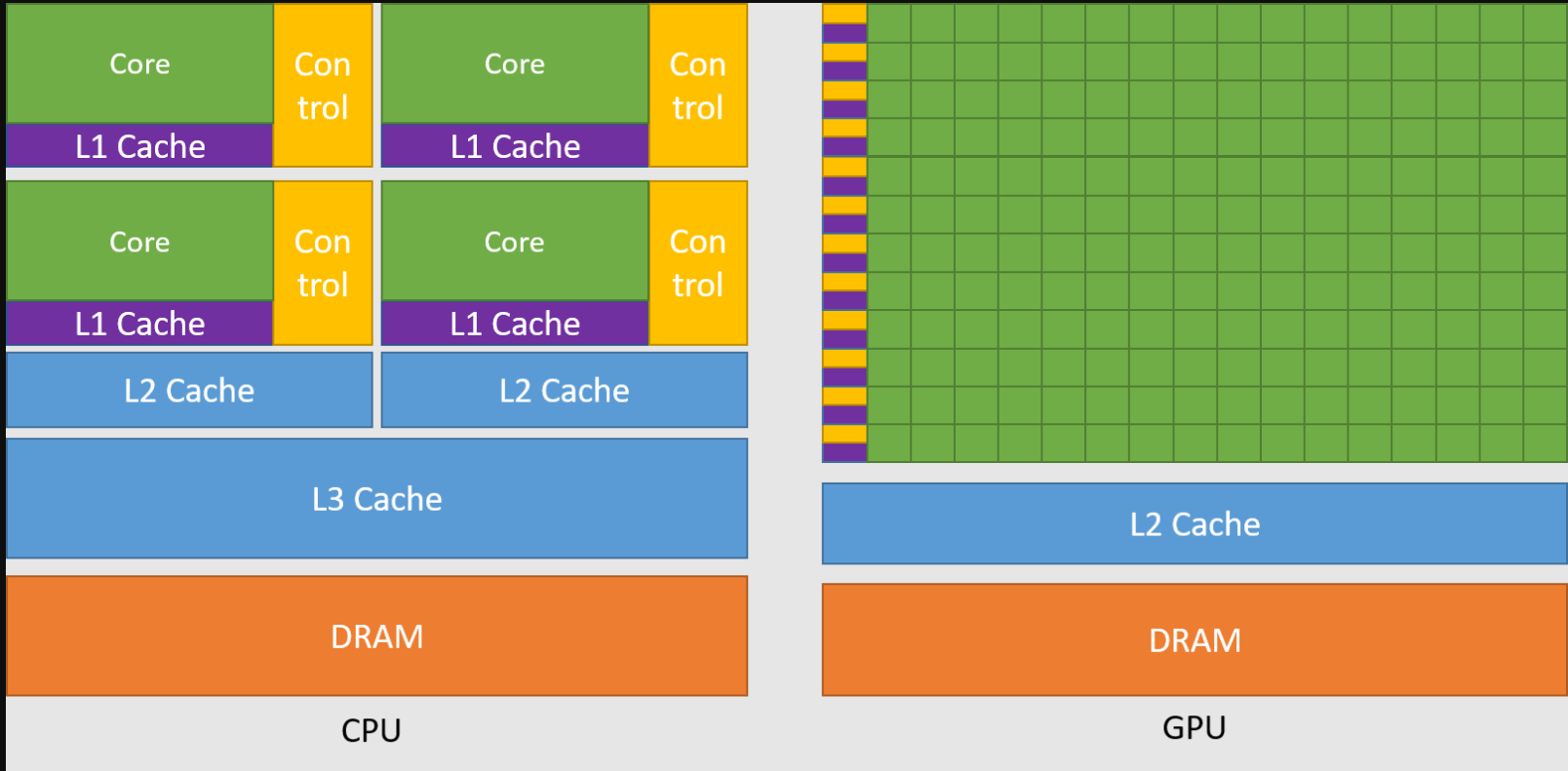
Figure 1 The GPU Devotes More Transistors to Data Processing
Devoting more transistors to data processing, for example, floating-point computations, is beneficial for highly parallel computations; the GPU can hide memory access latencies with computation, instead of relying on large data caches and complex flow control to avoid long memory access latencies, both of which are expensive in terms of transistors.
In general, an application has a mix of parallel parts and sequential parts, so systems are designed with a mix of GPUs and CPUs in order to maximize overall performance. Applications with a high degree of parallelism can exploit this massively parallel nature of the GPU to achieve higher performance than on the CPU.
1.2. CUDA®: A General-Purpose Parallel Computing Platform and Programming Model
In November 2006, NVIDIA® introduced CUDA®, a general purpose parallel computing platform and programming model that leverages the parallel compute engine in NVIDIA GPUs to solve many complex computational problems in a more efficient way than on a CPU.
CUDA comes with a software environment that allows developers to use C++ as a high-level programming language. As illustrated by Figure 2, other languages, application programming interfaces, or directives-based approaches are supported, such as FORTRAN, DirectCompute, OpenACC.
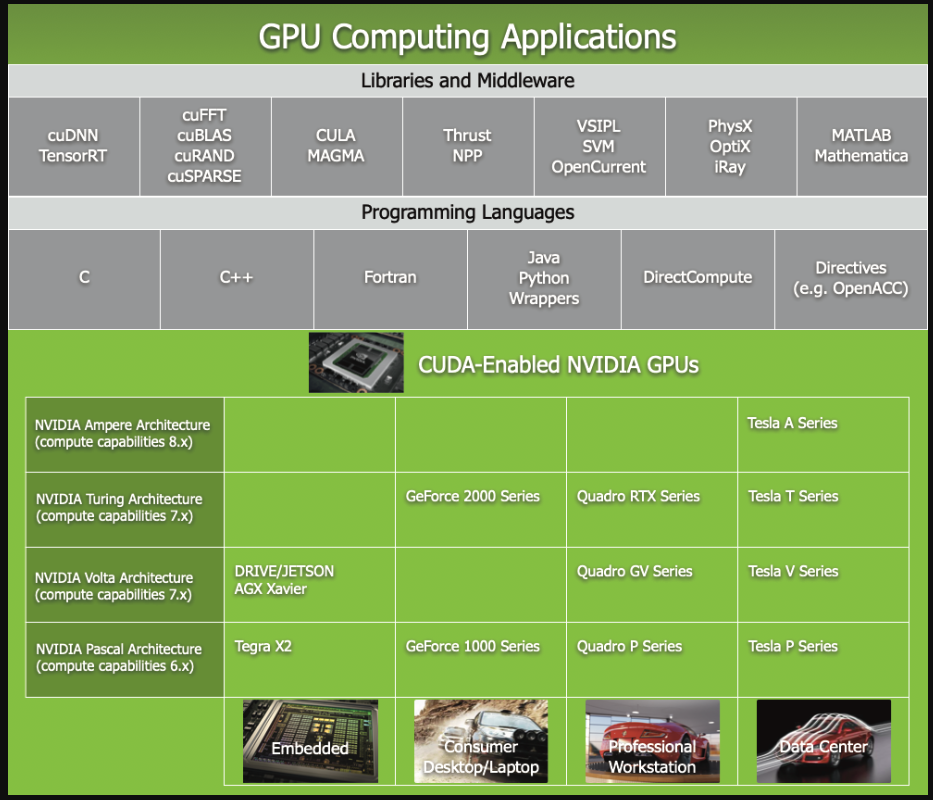
Figure 2 GPU Computing Applications. CUDA is designed to support various languages and application programming interfaces.
1.3. A Scalable Programming Model
The advent of multicore CPUs and manycore GPUs means that mainstream processor chips are now parallel systems. The challenge is to develop application software that transparently scales its parallelism to leverage the increasing number of processor cores, much as 3D graphics applications transparently scale their parallelism to manycore GPUs with widely varying numbers of cores.
The CUDA parallel programming model is designed to overcome this challenge while maintaining a low learning curve for programmers familiar with standard programming languages such as C.
At its core are three key abstractions — a hierarchy of thread groups, shared memories, and barrier synchronization — that are simply exposed to the programmer as a minimal set of language extensions.
These abstractions provide fine-grained data parallelism and thread parallelism, nested within coarse-grained data parallelism and task parallelism. They guide the programmer to partition the problem into coarse sub-problems that can be solved independently in parallel by blocks of threads, and each sub-problem into finer pieces that can be solved cooperatively in parallel by all threads within the block.
This decomposition preserves language expressivity by allowing threads to cooperate when solving each sub-problem, and at the same time enables automatic scalability. Indeed, each block of threads can be scheduled on any of the available multiprocessors within a GPU, in any order, concurrently or sequentially, so that a compiled CUDA program can execute on any number of multiprocessors as illustrated by Figure 3, and only the runtime system needs to know the physical multiprocessor count.
This scalable programming model allows the GPU architecture to span a wide market range by simply scaling the number of multiprocessors and memory partitions: from the high-performance enthusiast GeForce GPUs and professional Quadro and Tesla computing products to a variety of inexpensive, mainstream GeForce GPUs (see CUDA-Enabled GPUs for a list of all CUDA-enabled GPUs).
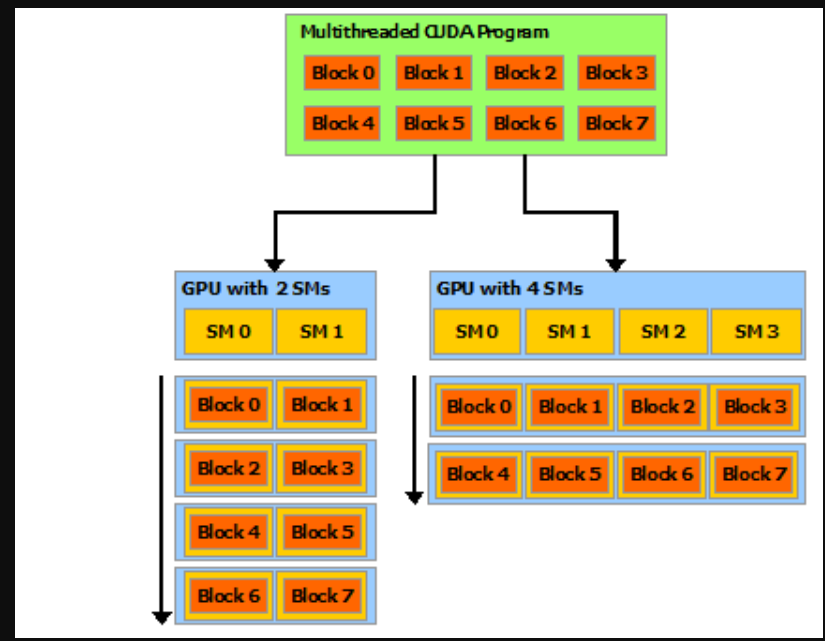
Figure 3 Automatic Scalability
Note
A GPU is built around an array of Streaming Multiprocessors (SMs) (see Hardware Implementation for more details). A multithreaded program is partitioned into blocks of threads that execute independently from each other, so that a GPU with more multiprocessors will automatically execute the program in less time than a GPU with fewer multiprocessors.
1.4. Document Structure
This document is organized into the following sections:
-
Introduction is a general introduction to CUDA.
-
Programming Model outlines the CUDA programming model.
-
Programming Interface describes the programming interface.
-
Hardware Implementation describes the hardware implementation.
-
Performance Guidelines gives some guidance on how to achieve maximum performance.
-
CUDA-Enabled GPUs lists all CUDA-enabled devices.
-
C++ Language Extensions is a detailed description of all extensions to the C++ language.
-
Cooperative Groups describes synchronization primitives for various groups of CUDA threads.
-
CUDA Dynamic Parallelism describes how to launch and synchronize one kernel from another.
-
Virtual Memory Management describes how to manage the unified virtual address space.
-
Stream Ordered Memory Allocator describes how applications can order memory allocation and deallocation.
-
Graph Memory Nodes describes how graphs can create and own memory allocations.
-
Mathematical Functions lists the mathematical functions supported in CUDA.
-
C++ Language Support lists the C++ features supported in device code.
-
Texture Fetching gives more details on texture fetching.
-
Compute Capabilities gives the technical specifications of various devices, as well as more architectural details.
-
Driver API introduces the low-level driver API.
-
CUDA Environment Variables lists all the CUDA environment variables.
-
Unified Memory Programming introduces the Unified Memory programming model.
-
The graphics qualifier comes from the fact that when the GPU was originally created, two decades ago, it was designed as a specialized processor to accelerate graphics rendering. Driven by the insatiable market demand for real-time, high-definition, 3D graphics, it has evolved into a general processor used for many more workloads than just graphics rendering.
- 登录 发表评论
- 61 次浏览
最新内容
- 7 hours 54 minutes ago
- 1 week 6 days ago
- 3 weeks ago
- 3 weeks 4 days ago
- 2 months 1 week ago
- 6 months 1 week ago
- 6 months 1 week ago
- 6 months 1 week ago
- 6 months 1 week ago
- 6 months 1 week ago