
构建聊天机器人已经成为一项热门技能,随着ChatGPT的发布,我们看到大量聊天应用程序正在发布。在所有这些应用程序的根源上,存在着大型语言模型——生成人工智能训练的引擎。但这头野兽必须被驯服——这并不总是一件容易的事。
由于LLM现在是拼图中不可或缺的一部分,为了使我们的聊天机器人产品化,我们需要应对几个挑战:
- 基础(Grounding ) ——默认情况下,LLM可以产生与客观现实无关的反应。我们把这些反应称为“幻觉”——它们看起来可能是真实的,甚至令人信服,但它们可能是完全错误的。我们需要想出一些机制,让对话建立在我们可以信任的真相来源上。
- 查询限制-当我们将现有知识与上下文相结合时,我们经常会碰到LLM提供商(例如OpenAI)设置的查询限制
- 会话记忆-LLM是无状态的,这意味着它们没有记忆的概念。这意味着他们不会独自维持谈话的链条。这可能会让用户感到非常沮丧。我们需要建立一个机制来维护对话历史记录,这将是我们从聊天机器人返回的每个响应的上下文的一部分。
- 多用户-我们的聊天机器人可以与多个用户实时交互。这意味着我们需要为每次对话保留单独的对话记忆和上下文。
有一波工具是专门为使开发人员更容易在创建会话代理的上下文中使用LLM而创建的。也许这些工具中最著名的是Langchain。它使我们能够轻松定义不同类型的抽象并与之交互,从而轻松构建强大的聊天机器人。它与Pinecone一起,使我们能够建立一个知识库,我们的机器人可以与之交互,并用上下文准确的信息对用户做出响应。
在这个例子中,我们将假设我们的聊天机器人需要回答有关网站内容的问题。要做到这一点,我们需要一种方法来存储和访问聊天机器人生成响应时的信息。这就是知识库的用武之地。知识库是我们
的聊天机器人可以查询的信息库。我们需要从语义上访问这些信息,并使用LLM来获取文本数据的嵌入,并将其存储在Pinecone中。我们案例中的文本数据将来自一个我们将定期抓取的网站。创建索引后,我们的聊天机器人将能够根据用户的提示在相关内容中找到答案。
先决条件
我们假设您熟悉Next.JS或对Javascript有很好的理解。
此演示使用了一系列令人惊叹的服务,您需要开立免费帐户才能在不修改的情况下使用演示:
架构
在非常高的级别上,以下是我们聊天机器人的架构:

有三个主要组件:聊天机器人、索引器和松果索引。
- 索引器抓取真相的来源,为检索到的文档生成向量嵌入,并将这些嵌入写入Pinecone
- 用户向聊天机器人进行查询
- 聊天机器人向Pinecone查询true的来源
- 聊天机器人会对用户做出响应。
让我们深入了解Indexer:
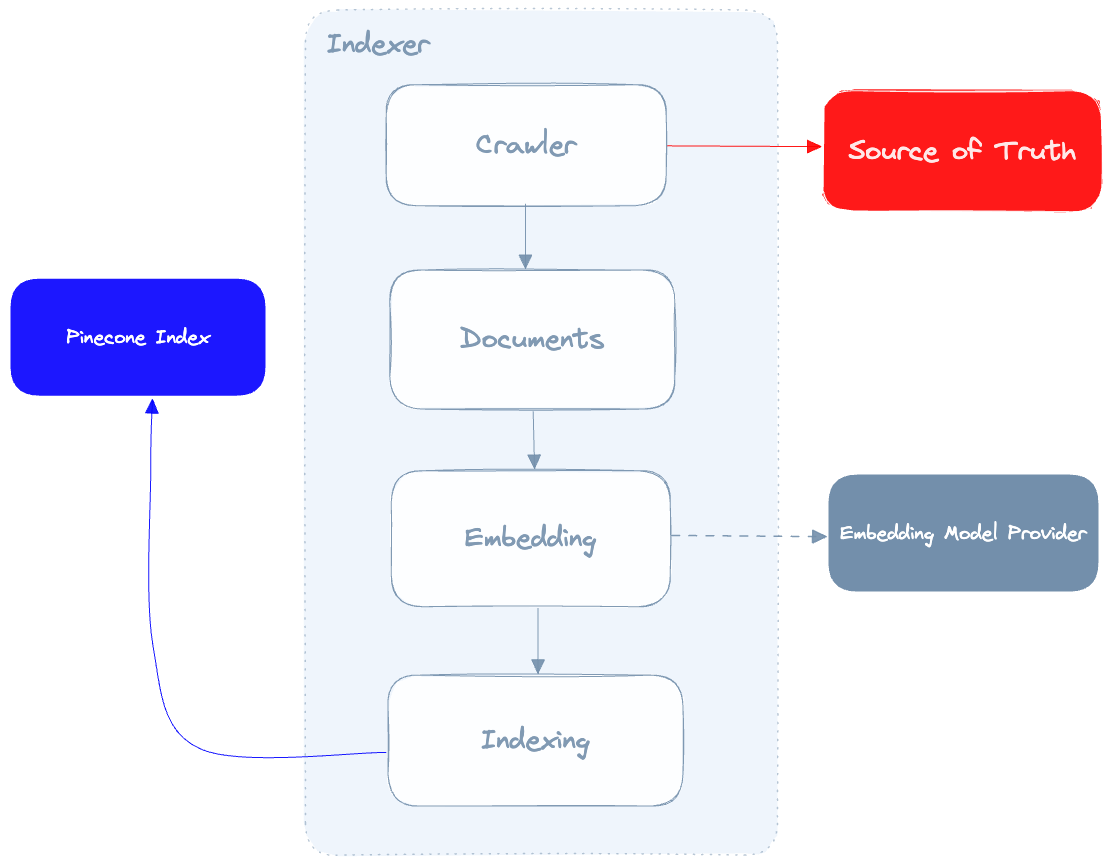
索引器的作用是抓取我们的真相来源,调用嵌入模型提供程序为每个文档生成嵌入,然后在Pinecone中对这些文档进行索引。这里要提到的一个重要细节是,我们从爬网程序中获得的数据质量将直接影响聊天机器人产生的结果的质量,因此,我们的爬网程序能够尽可能地清理从我们的真相来源中提取的数据至关重要。
接下来,这是我们的聊天机器人本身:
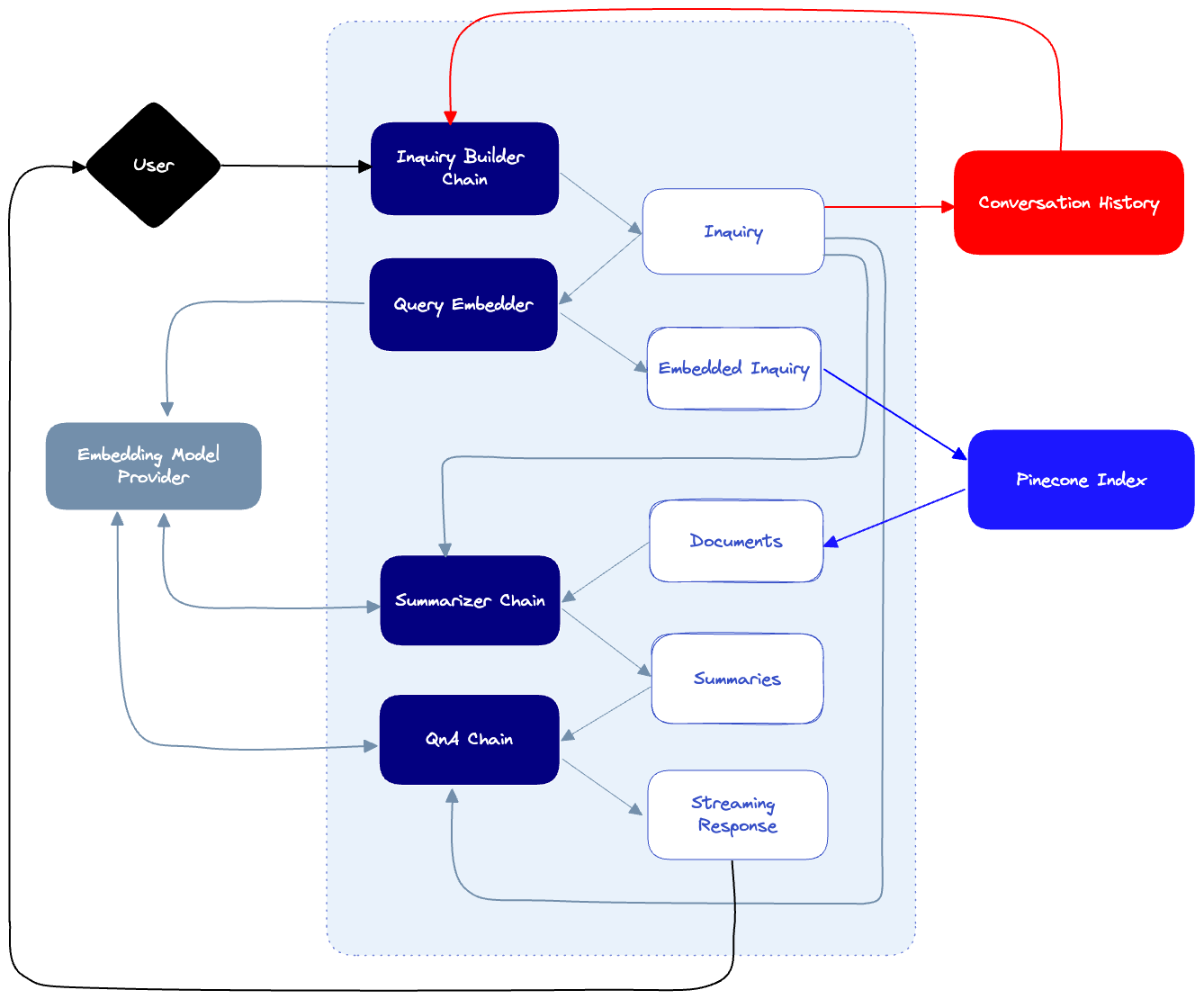
- 当用户发送提示时,我们会将其传递给Inquiry构建器链,该链将根据对话历史生成查询。这将确保我们的下游查询考虑到用户已经提出的问题。例如,如果用户问:“我在哪里可以买到电脑?”然后问“它要花多少钱?”,那么查询生成器将知道通过制定最终查询“电脑要花多少?”来解释用户的意图。
- 每当创建新的查询时,我们都会将其保存在对话历史记录日志中。
- 当查询被解析时,它将用于查询Pinecone索引,该索引由我们的索引器插入的文档填充。这将导致许多潜在的点击,每个点击都有来自我们真相来源的相应文档。
- 由于这些文档很可能很长,我们将使用汇总器链来汇总长文档,并生成最终的汇总文档,用于构成最终答案。汇总人将了解调查情况,并尽可能多地保存与该调查相关的信息。
- 最后,我们的QnA链将结合摘要文档、对话历史记录和查询,对用户的提示做出最终响应。
我们仍然需要解决我们的多用户策略:我们需要确保与我们的聊天机器人互动的用户不会污染彼此的对话记忆,并且响应会从聊天机器人流式传输回发起对话的用户。
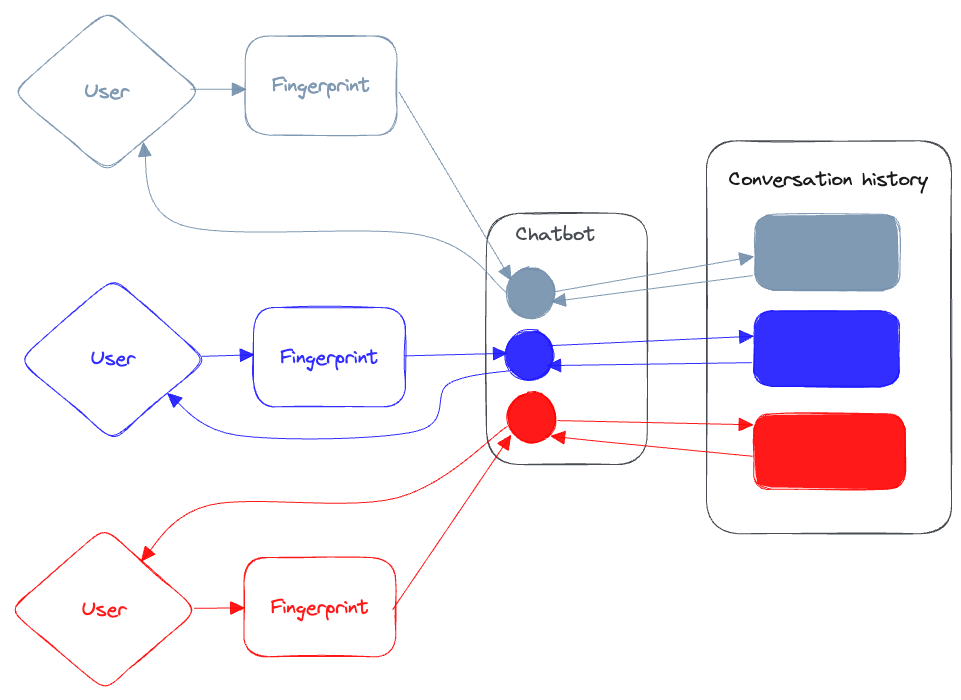
由于我们不需要对每个连接到聊天机器人的用户进行身份验证,我们将解析一些唯一的ID(或“指纹”),这将帮助我们根据用户的浏览器识别用户。我们的聊天机器人将使用这个唯一的ID来保存每个用户的对话历史记录,并使用该密钥将他们彼此分离。它还将使用ID通过一个独特的(有弹性的)流媒体频道从聊天机器人中流式传输我们的响应。
使用Langchain
正如我们之前提到的,Langchain提供了一组非常有用的抽象,当我们构建基于LLM的应用程序时,这些抽象会让我们的生活更轻松。要在Langchain中构建“链”,我们需要一个模型和一个提示。当我们查询模型时,提示将发送给模型,Langchain为我们提供了一个有用的格式化实用程序PromptTemplate:
import { PromptTemplate } from "langchain/prompts";
const template = "What sound does the {animal} make?";
const prompt = new PromptTemplate({
template: template,
inputVariables: ["animal"],
});
Langchain还可以很容易地与OpenAI等LLM提供商进行交互。以下是我们如何使用OpenAI作为提供者来定义模型:
import { OpenAI } from "langchain/llms";
const llm = new OpenAI();
以下是我们如何使用此提示模板和模型来生成链:
import { LLMChain } from "langchain/chains";
const chain = new LLMChain({ llm, prompt });
要调用链,我们使用调用方法:
const response = await chain.call({ animal: "cat" });
console.log({ response });
正如您将看到的,当我们将一系列链组合在一起时,这种非常简单的模板化提示的模式非常强大。
虽然Langchain提供了许多类型的会话内存实用程序,但它本身并不能处理与同一聊天机器人交互的多个用户。我们希望用户能够与我们的知识库进行交互并向其提问,而聊天机器人不会失去对话的线索,也不会用与之交互的其他用户的无关信息污染其他线索。因此,为此,我们将构建自己的会话记忆实用程序,其功能与Langchain非常相似。稍后将在帖子中详细介绍。
构建
是时候建造这个东西了!我们不会审查每一行代码——为此,您可以审查这个存储库。相反,我们将重点关注代码中需要进行一些解释的相关部分。
索引器
如上所述,索引器从爬网程序开始。我们使用nodespider和cheerio来抓取我们的目标url。每当我们获取页面时,我们都会对其进行解析,并在其中找到所有href元素——如果它们是同一根域的一部分,我们会对它们进行排队等待下载。由于我们计划将内容用于语义搜索,因此我们希望去掉所有HTML,只保留内容。为此,我们使用了turndown库,它可以帮助我们将HTML转换为markdown。
// Instantiate the crawler
const crawler = new Crawler(urls, 100, 200);
// Start the crawler
const pages = (await crawler.start()) as Pages[];
在爬行过程结束时,我们创建了一个页面数组,每个页面都包含页面的标记内容、URL和标题。
处理利率限制
这个过程分为两个步骤:嵌入和索引,这两个步骤在某些方面都受到速率限制。让我们看看如何确保我们的嵌入器和索引器能够很好地处理这些速率限制。
嵌入
我们希望我们的聊天机器人能够使用自然语言查询松果,并获取语义相关的信息。要做到这一点,我们需要做四件事:
- 把我们爬来的页面分成小块
- 将每个区块与其原始文本相关联。一旦我们“命中”了这个区块,我们就希望能够使用整个文本来构建我们的最终答案。
- 为分块文本创建矢量嵌入。
- 由于Pinecone允许我们在元数据对象中保存多达40k的数据,因此如果原始文本太大,我们需要截断它。
首先,我们使用gpt-3.5-turbo模型实例化一个OpenAIEmbedding实例。然后,我们使用Langchain的RecursiveCharacterTextSplitter将页面分割成块。
const embedder = new OpenAIEmbeddings({
modelName: "gpt-3.5-turbo",
});
const documents = await Promise.all(
pages.map((row) => {
const splitter = new RecursiveCharacterTextSplitter({
chunkSize: 300,
chunkOverlap: 20,
});
const docs = splitter.splitDocuments([
new Document({
pageContent: row.text,
metadata: {
url: row.url,
text: truncateStringByBytes(row.text, 35000),
},
}),
]);
return docs;
})
);
OpenAI API嵌入端点限制为每分钟3000个请求。为了确保我们不会超过限制,我们使用瓶颈库,它允许我们控制请求的速度。
const limiter = new Bottleneck({
minTime: 50,
});
const rateLimitedGetEmbedding = limiter.wrap(getEmbedding);
vectors = (await Promise.all(
documents.flat().map((doc) => rateLimitedGetEmbedding(doc))
)) as unknown as Vector[];
minTime参数定义了每个请求将花费的最短时间(以毫秒为单位)。通过包装getEmbedding函数,我们现在可以确保限制器控制其发射的速率。
上翻(Upserting)
既然我们有了嵌入,是时候把它们重新组装到松果中了。此操作也是速率限制的-我们每次追加操作最多可以发送2MB的矢量。考虑到我们在每个向量中打包了大量元数据,我们应该在追加之前对向量数组进行分组。
const sliceIntoChunks = (arr: Vector[], chunkSize: number) => {
const res = [];
for (let i = 0; i < arr.length; i += chunkSize) {
const chunk = arr.slice(i, i + chunkSize);
res.push(chunk);
}
return res;
};
const chunks = sliceIntoChunks(vectors, 10);
await Promise.all(
chunks.map(async (chunk) => {
await index!.upsert({
upsertRequest: {
vectors: chunk as Vector[],
},
});
})
);
就这样!我们的履带已经准备好了。要运行爬网程序,并假设我们创建了松果索引,我们只需要启动服务器并发出以下请求:
GET https://localhost:3000/api/crawl?urls=url1,url2&limit=10&indexName=yourIndexName
当请求完成时,我们的新嵌入将被打乱到Pinecone。
聊天机器人
我们希望我们的聊天机器人能够根据我们嵌入并保存在Pinecone中的文档中的信息回答问题。在帖子的这一部分,我们将看到如何利用Langchain来构建一个“链”集合,每个“链”都能提高我们聊天机器人的性能。
我们在这里要做的很大一部分是所谓的“即时工程”,即我们微调发送到聊天机器人的确切提示,以便对我们的情况做出最佳反应。在这一点上,即时工程更像是一门艺术,而不是一门科学,不存在“正确”大部分答案。我们有很多好的做法,也有很多技巧和窍门可以应用,但最重要的是,在找到适合你情况的具体提示时,你必须自己动手。
正如您在聊天机器人的架构布局中所看到的,我们有以下步骤:
- 查询生成器-接受用户提示,注入对话上下文,并构建考虑上下文的最终查询
- 语义文档检索-我们嵌入查询并使用它来查询Pinecone中索引的文档
- 摘要链(可选)-在我们的特定情况下,我们从Pinecone检索到的文档太长,无法发送到OpenAI来制定最终答案(它们很可能超过4000个字符长)。为了克服这一点,我们对这些长文档进行分组和汇总,同时保留对我们来说很重要的内容。例如,重要的是要使用文档中的代码样本保持完整,所以我们要告诉汇总器,即使在汇总了它们的原始文本后,也要保持它们不变。也就是说,这一步骤并不总是必需的,而且我们可能能够在不总结文档的完整版本的情况下看到良好的结果,而只依赖于索引块。
- 最终QnA链-我们提供摘要、会话历史和对模型的查询,以产生最终结果。
基于用户的会话历史
正如我们之前提到的,我们希望确保用户与聊天机器人的对话尽可能自然。为了让聊天机器人“理解”已经讨论过的内容,我们需要为它提供对话上下文。我们使用一个简单的SQL表(托管在蟑螂数据库上)来存储每个对话条目:
public async addEntry({ entry, speaker }: { entry: string, speaker: string }) {
try {
await sequelize.query(`INSERT INTO conversations (user_id, entry, speaker) VALUES (?, ?, ?) ON CONFLICT (created_at) DO NOTHING`, {
replacements: [this.userId, entry, speaker],
});
} catch (e) {
console.log(`Error adding entry: ${e}`)
}
}
为了检索对话历史,我们使用以下函数,该函数获取最近的对话(基于限制),并将其作为字符串数组返回:
public async getConversation({ limit }: { limit: number }): Promise<string[]> {
const conversation = await sequelize.query(`SELECT entry, speaker, created_at FROM conversations WHERE user_id = '${this.userId}' ORDER By created_at DESC LIMIT ${limit}`);
const history = conversation[0] as ConversationLogEntry[]
return history.map((entry) => {
return `${entry.speaker.toUpperCase()}: ${entry.entry}`
}).reverse()
}
我们现在可以使用这个对话历史记录作为聊天机器人使用的各种链的上下文的一部分。
对查询进行罚款
用户可以使用他们想要的任何提示,正如我们之前所说,因为我们希望保持对话尽可能自然,所以我们采用用户的原始提示,将其与对话历史记录相结合,最终生成一个查询,该查询将集中在我们创建的知识库上。
为了构建查询链,我们首先需要一个模板。下面是一个可能看起来像什么的例子:
`Given the following user prompt and conversation log, formulate a question that would be the most relevant to provide the user with an answer from a knowledge base.
You should follow the following rules when generating and answer:
- Always prioritize the user prompt over the conversation log.
- Ignore any conversation log that is not directly related to the user prompt.
- Only attempt to answer if a question was posed.
- The question should be a single sentence.
- You should remove any punctuation from the question.
- You should remove any words that are not relevant to the question.
- If you are unable to formulate a question, respond with the same USER PROMPT you got.
USER PROMPT: {userPrompt}
CONVERSATION LOG: {conversationHistory}
Final answer:`;
这就是我们对链条的调用:
const inquiryChain = new LLMChain({
llm,
prompt: new PromptTemplate({
template: templates.inquirerTemplate,
inputVariables: ["userPrompt", "conversationHistory"],
}),
});
const inquirerChainResult = await inquiryChain.call({
userPrompt: prompt,
conversationHistory,
});
const inquiry = inquirerChainResult.text;
旁白:Prompt Engineering
既然我们已经看到了一个使用提示的例子,那么让我们来谈谈提示工程——这本身就是一种新兴的技能。
即时工程是一个精心制作输入查询或任务的过程,以从LLM中获得最准确、最有用的响应。虽然这些模型功能强大且用途广泛,但它们需要一些指导才能真正正确地完成任务。
即时工程包括三个主要组成部分:
- 短语:我们需要尝试不同的方式来显示我们的输入查询。我们的目标是在清晰度和特异性之间找到完美的平衡,确保LLM“准确地掌握”我们正在寻找的东西。
- 上下文:我们需要在提示中添加上下文,以帮助LLM“理解”更广泛的情况。这可能包括提供背景信息,为所需的反应奠定基础,甚至轻轻地将模型推向特定的思路。正如我们之前所看到的,这就是我们所做的,以生成与用户之前的提示相关的查询。
- 说明:我们需要给LLM清晰简洁的说明。我们需要指定您希望响应采用的格式,或者突出显示您希望模型考虑的任何关键点。正如您之前所看到的,我们通过定义一系列指令来实现这一点,这些指令定义给LLM——确切地说,如何格式化查询,以及如何将其与用户收到的提示相结合。
即时工程就是试错,是迭代和优化的舞蹈。当我们微调iyr提示时,我们对如何与LLM进行有效沟通有了更深入的理解,将其转化为一种更可靠、更高效的解决问题的工具。
嵌入查询和查询松果
接下来,我们嵌入查询:
const embedder = new OpenAIEmbeddings({
modelName: "text-embedding-ada-002",
});
const embeddings = await embedder.embedQuery(inquiry);
接下来,我们查询Pinecone以检索用于嵌入式查询的文档。在这里,我们使查询传递includeMetadata:true参数,然后映射到结果上,并将元数据强制转换为元数据类型。
type Metadata = {
url: string;
text: string;
};
const getMatchesFromEmbeddings = async (
embeddings: number[],
pinecone: PineconeClient,
topK: number
): Promise<ScoredVector[]> => {
const index = pinecone!.Index("crawler");
const queryRequest = {
vector: embeddings,
topK,
includeMetadata: true,
};
try {
const queryResult = await index.query({
queryRequest,
});
return (
queryResult.matches?.map((match) => ({
...match,
metadata: match.metadata as Metadata,
})) || []
);
} catch (e) {
console.log("Error querying embeddings: ", e);
throw new Error(`Error querying embeddings: ${e}`);
}
};
我们从这个函数中得到的是一个ScoredVectors数组。我们将从每个匹配的元数据中提取url和文档文本,并将它们传递给汇总器。
概述
目前,OpenAI的每个请求的上限为4000个代币(这将随着GPT-4的发布而改变,OpenAI一些产品的上限为8000和32000个)。因此,我们有点棘手:一方面,我们希望聊天机器人生成最终答案所使用的上下文尽可能详细,但我们无法传递在松果查询中找到的所有原始文档。解决方案是总结原始文档,同时保留我们总结的每个文档中的重要信息。
要做到这一点,我们首先将从Pinecone检索到的所有文档组合在一起,然后将它们分成大小均匀的块,最多4000个令牌。我们对每个区块进行汇总,并将它们组合在一起。如果得到的汇总文档仍然太长,我们将继续递归地对其进行汇总。
const summarizeLongDocument = async (
document: string,
inquiry: string,
onSummaryDone: Function
): Promise<string> => {
// Chunk document into 4000 character chunks
try {
if (document.length > 3000) {
const chunks = chunkSubstr(document, 4000);
let summarizedChunks: string[] = [];
for (const chunk of chunks) {
const result = await summarize(chunk, inquiry, onSummaryDone);
summarizedChunks.push(result);
}
const result = summarizedChunks.join("\n");
if (result.length > 4000) {
return await summarizeLongDocument(result, inquiry, onSummaryDone);
} else return result;
} else {
return document;
}
} catch (e) {
throw new Error(e as string);
}
};
为了总结每个区块,我们创建了一个新的“链”,并应用它:
const summarize = async (
document: string,
inquiry: string,
onSummaryDone: Function
) => {
const chain = new LLMChain({
prompt: promptTemplate,
llm,
});
try {
const result = await chain.call({
prompt: promptTemplate,
document,
inquiry,
});
onSummaryDone(result.text);
return result.text;
} catch (e) {
console.log(e);
}
};
下面是告诉我们的LLM保留对我们重要的信息的提示(在本例中,它是代码):
`Shorten the text in the CONTENT, attempting to answer the INQUIRY. You should follow the following rules when generating the summary:
- Any code found in the CONTENT should ALWAYS be preserved in the summary, unchanged.
- Code will be surrounded by backticks (\`) or triple backticks (\`\`\`).
- Summary should include code examples that are relevant to the INQUIRY, based on the content. Do not make up any code examples on your own.
- If the INQUIRY cannot be answered, the final answer should be empty.
- The summary should be under 4000 characters.
INQUIRY: {inquiry}
CONTENT: {document}
Final answer:
`;
应答施工提示
在总结过程结束时,我们将使用以下成分来构建最终答案:
- 调查
- 对话历史记录
- 检索到的文档的原始URL
- 摘要文档
我们已经准备好构建我们的最后一条链了。我们不希望等待收到整个答案,而是希望我们的响应逐个令牌地流式传输到用户,因此我们将使用ChatOpenAI类——它允许我们定义一个处理流式事件的CallbackManager。
const chat = new ChatOpenAI({
streaming: true,
verbose: true,
modelName: "gpt-3.5-turbo",
callbackManager: CallbackManager.fromHandlers({
async handleLLMNewToken(token) {
// stream the token to the user
},
}),
});
每当收到新的令牌时,我们都希望将其流式传输回用户。为此,我们将使用Ably。
旁白:为什么是Ably?
Ably是一个实时数据交付平台,为开发人员提供基础设施和API,以构建可扩展和可靠的实时应用程序。它可以用于处理各种平台和设备之间的实时通信、数据同步和消息传递。
随着我们的聊天机器人获得更多的用户,机器人和用户之间交换的消息数量也会增加。Ably的构建是为了在不降低任何性能的情况下处理流量的增长。
Ably还确保消息传递并提供消息历史记录,即使在临时断开连接或网络问题的情况下也是如此。仅使用WebSocket实现这种级别的可靠性可能具有挑战性且耗时。
最后,Ably提供了内置的安全功能,如基于令牌的身份验证和细粒度的访问控制,简化了保护聊天机器人实时通信的过程。
设置Ably
在API端设置Ably非常简单:
const client = new Ably.Realtime({ key: process.env.ABLY_API_KEY });
Whenever we stream the token to the user, we’ll publish a message on the channel we assign to the user:
const channel = ably.channels.get(userId);
channel.publish({
data: {
event: "response",
token: token,
...
}
})
应用程序
幸运的是,我们不必从头开始构建聊天机器人界面。相反,我们可以使用精心制作的Chat UI React Kit,它提供了构建生产级聊天应用程序所需的所有组件。它看起来像这样:

完整的代码列表可以在这里找到。正如您所看到的,我们有一个消息框,用户可以在其中键入消息。当他们按下回车键时,就会发送消息。在聊天机器人的名称下,我们有一个状态框,每当聊天机器人想要更新其活动的用户时,它就会更新。
处理传入消息
为了在客户端上接收消息,我们首先设置了Ably提供的useChannel效果:
import { useChannel } from "@ably-labs/react-hooks";
useChannel(visitorData?.visitorId! || "default", (message) => {
switch (message.data.event) {
case "response":
setConversation((state) => updateChatbotMessage(state, message));
break;
case "status":
setStatusMessage(message.data.message);
break;
case "responseEnd":
default:
setBotIsTyping(false);
setStatusMessage("Waiting for query...");
}
});
每当机器人向我们发送状态消息时,我们都会更新状态面板。
也就是说,每当我们的机器人做出响应时,我们仍然需要做一些工作来处理传入的流媒体数据。正如您所看到的,我们将对话保存在一个状态对象中,该对象具有一个ConversationEntry数组:
type ConversationEntry = {
message: string,
speaker: "bot" | "user",
date: Date,
id?: string,
};
每当聊天机器人返回新消息时,我们都需要适当地更新对话列表。我们基本上必须从国家“提取”最后一条信息,并不断添加。
const updateChatbotMessage = (
conversation: ConversationEntry[],
message: Types.Message
): ConversationEntry[] => {
const interactionId = message.data.interactionId;
const updatedConversation = conversation.reduce(
(acc: ConversationEntry[], e: ConversationEntry) => [
...acc,
e.id === interactionId
? { ...e, message: e.message + message.data.token }
: e,
],
[]
);
return conversation.some((e) => e.id === interactionId)
? updatedConversation
: [
...updatedConversation,
{
id: interactionId,
message: message.data.token,
speaker: "bot",
date: new Date(),
},
];
};
我们要做的最后一件事是将用户的请求发送到我们的机器人。当调用submit函数时(当按下回车键时),我们会将用户的消息添加到对话状态对象中,并将用户的信息以及我们从Fingerprint获得的用户的唯一标识符发送到机器人。
const submit = async () => {
setConversation((state) => [
...state,
{
message: text,
speaker: "user",
date: new Date(),
},
]);
try {
setBotIsTyping(true);
const response = await fetch("/api/chat", {
method: "POST",
headers: {
"Content-Type": "application/json",
},
body: JSON.stringify({ prompt: text, userId: visitorData?.visitorId }),
});
await response.json();
} catch (error) {
console.error("Error submitting message:", error);
} finally {
setBotIsTyping(false);
}
setText("");
};
有了这些,我们的应用程序就可以开始了!
演示
为了测试聊天机器人,我选择在Pinecone自己的文档上运行它。我第一次爬行https://docs.pinecone.io,对于我的问题得到了以下结果:
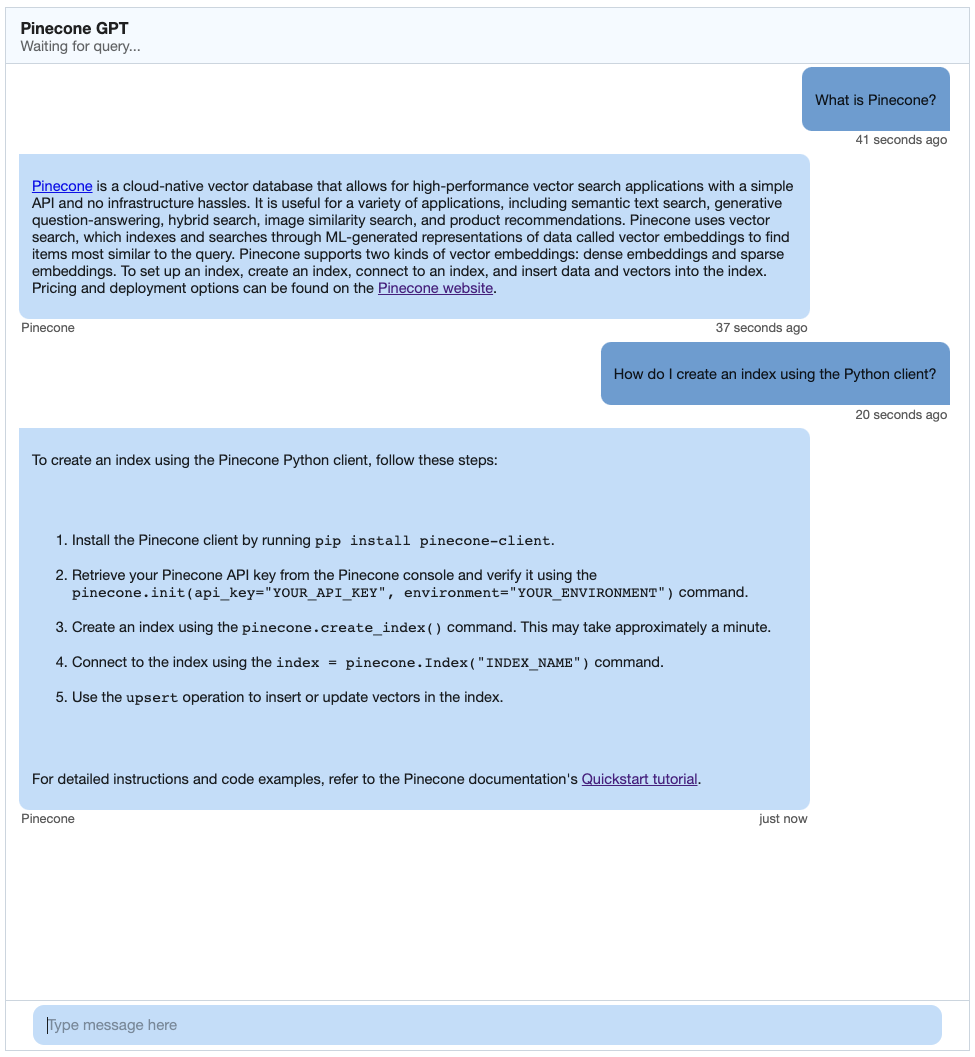
起来不错!
最后的想法
聊天机器人和LLM领域正在迅速变化。OpenAI刚刚宣布了GPT-4及其新的限制,这可能会改变该应用程序和其他应用程序处理摘要和其他任务的方式。Langchain的JS/TS版本正在不断改进和添加新功能,这些功能将简化我们必须手动完成的许多任务。
话虽如此,像这样的对话应用程序的总体架构大致相同:我们总是需要抓取、嵌入和索引我们的真实数据源,为聊天机器人提供基础。我们总是需要创建提示,帮助聊天机器人了解用户的意图,并以我们希望提供给用户的方式制定答案。
我们鼓励您使用Pinecone和Langchain等工具,充分利用这一领域正在取得的进步。以这篇文章为起点,创建对话式应用程序,吸引用户并让他们不断回来获取更多!
最新内容
- 1 week ago
- 2 weeks 1 day ago
- 2 weeks 5 days ago
- 2 months 1 week ago
- 6 months ago
- 6 months ago
- 6 months ago
- 6 months ago
- 6 months ago
- 6 months ago