
模型评估是机器学习和预测建模的基本步骤。它使我们能够评估模型的性能、可靠性和泛化能力,从而做出明智的决策并改善业务成果。有几种模型评估技术,如下所示:
A.坚持方法(Hold-out Approach):

保持方法,也称为简单的训练测试分割(simple train-test split),是评估机器学习模型性能的一种基本技术。它包括将数据集分为两部分:训练集和测试集。
坚持方法通常遵循以下步骤:
- 原始数据集被随机分为训练集和测试集。常见的分割比为70–30或80–20,但它可能因数据集的大小和具体问题而异。
- 训练集用于训练模型。该模型基于输入特征和相应的目标变量来学习数据中的模式和关系。
- 一旦训练了模型,就使用测试集来评估其性能。根据问题类型,将模型的预测与测试集中的实际目标变量进行比较,以计算性能指标,如准确性、精确度、召回率或其他指标。
- 从测试集获得的性能指标提供了对模型在看不见的数据上可能表现的评估。
训练试验拆分代码为:
from sklearn.model_selection import train_test_split
x_train,x_test,y_train,y_test=train_test_split(X,Y,test_size=0.2,random_state=2)坚持方法的问题:
虽然保持方法是一种简单且常用的模型评估技术,但它确实存在一些潜在的问题和局限性:
可变性(Variability ):
模型的性能对数据如何划分为训练集和测试集非常敏感。不同的划分可能会导致不同的评估结果,从而导致不太可靠的性能估计。

让我们假设我们有一个1000个样本的数据集,我们想使用80-20的比例将其分为训练集和测试集。我们将在测试集上评估分类模型的性能。
如果我们将随机状态设置为特定值,例如42,则数据将以一致的方式进行拆分。我们在训练集上训练模型,并在测试集上评估其性能。让我们假设我们获得85%的准确率。
现在,如果我们将随机状态更改为不同的值,比如说100,并重复相同的过程,我们可能会得到不同的精度,比如82%。这种差异是由于为具有不同随机状态的训练和测试集随机选择的不同样本而产生的。
x_train,x_test,y_train,y_test=train_test_split(X,Y,test_size=0.2,random_state=2)#所以,如果我们改变随机状态值,模型的精度每次都会发生变化。
#这被称为可变性,并造成了如何选择最佳部署模型的混乱。
通过用各种随机状态值重复这个过程,我们将观察到模型性能的波动。例如,使用随机状态42可能产生85%的准确率,而随机状态100可能产生82%的准确率和随机状态123可能给我们84%的准确率。这些变化突出了随机化对保持方法的影响,并证明了评估结果的可变性。
2.数据效率低下:
拒发方法只使用一部分数据进行训练,另一部分数据用于测试。这意味着模型不能从所有可用的数据中学习,如果数据集很小,这可能会特别有问题。
3.性能评估中的偏差:
-让我们考虑一个现实生活中的例子,了解偏差如何影响绩效评估。
假设我们正在构建一个垃圾邮件分类器,并收集了10000封电子邮件的数据集。其中,9000封电子邮件是合法的,1000封是垃圾邮件。类别分布不平衡,与垃圾邮件相比,合法电子邮件的数量要高得多。
现在,假设我们使用保持方法来评估我们的垃圾邮件分类器,方法是将数据随机划分为训练集(80%的数据)和测试集(20%的数据)。我们在训练集上训练模型,并使用性能指标(如准确性)在测试集上评估其性能。
在这种情况下,由于不平衡的类分布,存在性能估计有偏差的可能性。该模型可以简单地通过正确地对大多数类别(合法电子邮件)进行分类来实现高精度,而对少数类别(垃圾邮件)表现不佳。
让我们假设该模型在测试集上实现了95%的准确性。乍一看,这可能表明性能卓越。然而,经过仔细检查,我们发现该模型对50%的垃圾邮件进行了错误分类,而对98%的合法电子邮件进行了正确分类。
性能估计中出现这种偏差是因为评估度量(准确性)没有考虑到不平衡的类分布。大多数类别(合法电子邮件)严重影响准确性,导致价值过高。事实上,该模型在少数类别(垃圾邮件)上的性能明显低于总体准确性。
因此,如果由于随机分裂,某些类或模式在训练集或测试集中被过度或不足地表示,则可能导致有偏差的性能估计。
4.超参数调整的可靠性较低:
-如果使用保持方法进行超参数调整,则存在过度拟合测试集的风险,因为信息可能会从测试集泄漏到模型中。这意味着该模型在测试集上的性能可能过于乐观,不能代表其对未知数据的性能。
当这些都是坚持方法中的问题时,我们为什么要使用这种方法?
简单:
-简单易懂。
计算效率:
由于使用这种方法,您只训练一次模型,因此与您在本文中研究的其他技术相比,它在计算上成本较低,因为它们训练模型多次。
大型数据集:
-对于非常大的数据集,即使是很小比例的数据也可能足以形成一个具有代表性的测试集。在这些情况下,保持方法可以很好地工作,如果你多次改变随机状态值,模型精度将变化非常非常小,这对于模型评估来说是可以的。
B.交叉验证(Cross Validation):(基于重新采样技术)
交叉验证的思想是将数据划分为几个子集或“折叠”。然后在其中一些子集上训练模型,并在其余子集上进行测试。该过程重复多次,每次使用不同的子集进行训练和验证。通常对每一轮的结果进行平均,以估计模型的总体性能。
机器学习中常用的交叉验证方法有几种。以下是一些最广泛使用的技术:
留一交叉验证(LOOCV):Leave-One-Out Cross-Validation
(n rows-> n models ->(n-1) for training -> 1 for testing)
让我们用一个更简单的解释和一个真实的例子来理解Leave One Out Cross Validation(LOOCV)。

Leave one-out cross validation
想象一下,你是一名为考试而学习的学生。你有一系列练习题,你想用它们来评估你的知识,并预测你在实际考试中的表现。但是,你要确保你的预测尽可能准确。
在LOOCV中,您模拟一种情况,通过一次省略一个练习问题来测试您的知识,并使用剩余的问题来评估您的理解。
以下是它的工作原理:
- 假设你有20道练习题,编号从1到20。
- 对于第一轮LOOCV,您决定省略问题1,将问题2至20作为您的训练集。你研究这些问题,并根据你对其他问题的理解来预测问题1的答案。
- 在对问题1做出预测后,将其与实际答案进行比较。这让你知道,如果这是训练的一部分,你在这个特定问题上的表现会有多好。
- 你对每个问题重复这个过程,一次漏掉一个问题,并根据其余问题预测答案。每次,你都要对照实际答案来评估你的预测。
- 最后,你将完成所有20个问题,去掉每一个,并评估你的预测。您可以通过将所有预测与实际答案进行比较来计算总体准确性(平均准确性)或任何其他性能指标。
在本例中,LOOCV模拟了一种情况,即通过一次省略一个问题并评估您的表现来评估您的知识。通过对所有问题进行这个过程,你可以更准确地估计你对材料的理解程度以及你在实际考试中的表现。
要实现LOOCV技术,请参阅我的github上的Jupyter笔记本。点击这里!
LOOCV的优点:-
数据的使用:
LOOCV使用几乎所有的数据进行训练,这在数据集很小、每个数据点都很有价值的情况下是有益的。
偏差较小:
由于每次迭代验证仅在一个数据点上进行,LOOCV的偏差小于其他方法,如k倍验证。
无随机性:
列车/试验分裂不存在随机性,因此评估是稳定的,不会因不同的随机分裂而导致结果变化。
LOOCV的缺点:-
- 计算费用与时间消耗
- 不适合不平衡的数据集
何时使用LOOCV:
- 小型数据集
- 平衡的数据集
需要较少偏差的性能估计:由于LOOCV使用了几乎所有的数据进行训练,因此与k倍交叉验证等其他方法相比,它对模型性能的估计较少偏差。
2.K-Fold交叉验证(K-Fold Cross-Validation:):
- 在k折叠交叉验证中,数据集被划分为k个大小相等的折叠或子集。
- 该模型被训练和评估了k次,每次都使用不同的折叠作为验证集,而剩余的折叠用于训练。
- 对从每次迭代中获得的性能度量进行平均以获得总体性能估计。
让我们通过一个例子来理解k折叠交叉验证:
假设您有一个包含100个图像的数据集,并且您想要构建一个图像分类器。为了评估分类器的性能,您决定使用5倍的交叉验证。
以下是它的工作原理:
数据集准备:
- 您将100幅图像的数据集划分为5个大小相等的折叠,每个折叠包含20幅图像。
- 每个折叠表示将用于训练和验证的数据的子集。
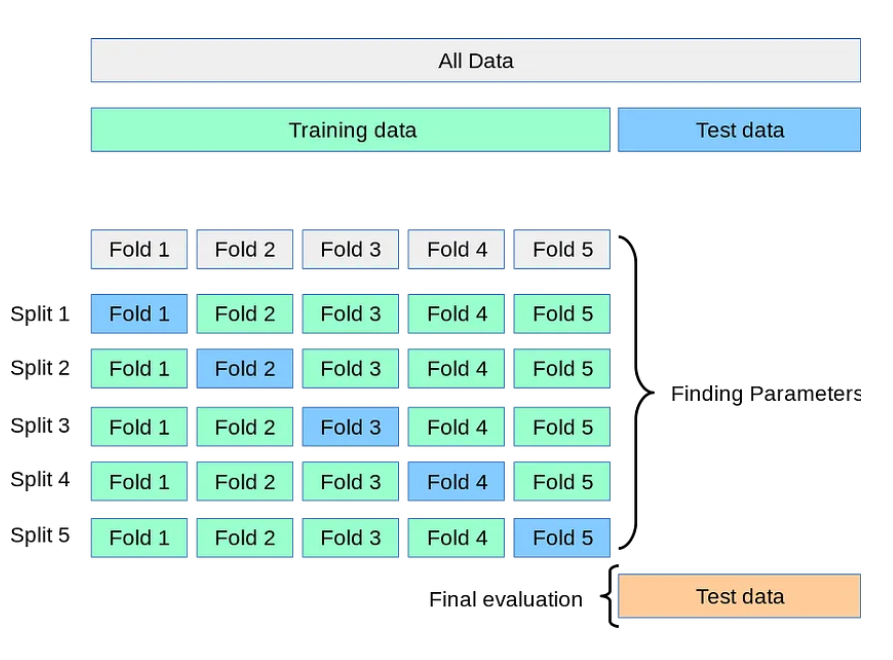
2.迭代1:
- 在第一次迭代中,使用折叠1作为验证集,其余的折叠2到5作为训练集。
- 您在Folds 2到5上使用80个图像训练图像分类器,并在Fold 1上评估其性能,Fold 1有20个图像。
- 您记录所获得的性能指标,如准确性、精密度、召回率或任何其他相关指标。
3.迭代2:
- 在第二次迭代中,将折叠2用作验证集,将折叠1、3、4和5用作训练集。
- 使用80个图像在折叠1、3、4和5上训练图像分类器,并在具有20个图像的折叠2上评估其性能。
- 再次记录所获得的性能指标。
4.迭代3、4和5:
- 对折叠3、4和5重复相同的过程,将它们用作验证集,而其余折叠用作训练集。
- 每次,您都要在训练集上训练模型,并在各自的验证折叠中评估其性能。
- 记录每次迭代的性能指标。
5.性能评估:
- 完成所有5次迭代后,您就可以获得每个折叠的性能指标。
- 为了获得总体性能估计,您对从5次迭代中获得的性能指标取平均值。
- 这个平均值代表了图像分类器在所有折叠中的性能,并提供了其有效性的可靠估计。
要实现K-fold交叉验证技术,请参阅我的GitHub上的Jupyter笔记本。点击这里!
K折叠交叉验证的优点:-
- 方差减少:LOOCV具有更高的方差,因为由于训练数据的差异最小,模型高度相关。在k倍交叉验证中,验证集之间的较大差异会降低模型之间的相关性,从而导致较低的方差。
- 与LOOCV相比,计算成本低廉。
K折叠交叉验证的缺点:-
- 可能无法很好地处理不平衡类:如果数据集具有不平衡类,则在分区时,一些折叠可能不包含少数类的任何样本,这可能导致误导性的性能指标。
- 高偏置的可能性
何时使用K折叠交叉验证:
- 当您拥有足够大的数据集时
- 当数据均匀分布时
3.分层K-fold交叉验证(Stratified K-fold cross validation ):
分层k倍交叉验证是k倍交叉校验的一种变体,它解决了数据集中类分布不平衡的问题。它通常用于目标变量或感兴趣的类分布不均的情况。
在标准的k折叠交叉验证中,数据集被随机划分为k个大小相等的折叠。然而,这种随机划分可能会导致一些折叠具有显著不平衡的类分布,特别是当原始数据集存在类不平衡问题时。
分层k折叠交叉验证旨在保持不同折叠之间的类别分布。它确保每个折叠都与原始数据集保持相同的类分布,从而提供更可靠的模型性能估计,特别是对于不平衡的数据集。

分层k次交叉验证过程包括以下步骤:
- 首先,通常使用随机采样将数据集划分为k个折叠。
- 接下来,对于每个折叠,分析目标变量的类别分布。
- 然后以这样的方式构建折叠,即每个折叠包含与原始数据集大致相同比例的每个类。这确保了每个折叠都代表了整个类别的分布。
- 使用k次迭代对模型进行训练和评估,其中在每次迭代中,一个折叠用作验证集,其余k-1个折叠用作训练集。
- 计算每个折叠的性能指标,如准确性或F1分数,并对结果进行平均,以获得模型的总体性能估计。
要实现分层K折叠交叉验证技术,请参阅我的GitHub上的Jupyter笔记本。点击这里!
我希望这将提高您对机器学习中的模型评估技术的了解。感谢您阅读这篇文章!