
category
大型语言模型(LLM)能够动态学习新任务,而不需要任何明确的训练或参数更新。这种使用LLM的模式称为上下文学习。它依赖于为模型提供一个合适的输入提示,其中包含所需任务的指令和/或示例。输入提示作为一种调节形式,指导模型的输出,但模型不会改变其权重。文本内学习可以应用于不同的设置,如零样本、一次或少速学习。这取决于输入提示中需要包含的信息量。

情境学习
为特定任务设计和调整自然语言提示的过程,以提高LLM的性能为目标,称为提示工程。
有效的快速工程可以显著提高LLM在特定任务上的表现。它是通过提供有助于指导模型输出的指令和上下文信息来完成的。通过精心设计提示,研究人员可以将LLM的注意力引向给定任务的最相关信息,从而获得更准确可靠的输出。
快速工程还可以帮助缓解“灾难性遗忘”的问题,即LLM在为新任务进行微调时可能会忘记以前学到的信息。通过使用精心设计的提示,该模型可以保留相关知识,同时仍能适应新任务。
提示组件
虽然它被认为是一个新领域,但已经有了丰富的文献,包括关于快速工程技术的文章、博客、研究论文、repo等。
一种常见的技术是从一组定义良好的组件构建提示,如下图所示。

提示组件
指令和其他静态上下文
静态上下文描述是指向LLM提供固定信息。此信息可以包括内容和格式指令、数据库模式信息或与任务相关的任何其他上下文信息。以下是一些广泛使用的方法,演示了在提示工程中使用静态上下文示例:
用系统消息建立对话或功能风格
系统消息可用于向LLM通知上下文。上下文可能是它正在进行的对话类型,也可能是它应该执行的功能。它有助于LLM生成更合适的回应。例如,如果LLM预计将执行客户服务功能,则提示可能包括系统消息,例如:
文本
You are a friendly AI agent who can provide assistance to the customer regarding their recent order.
同样,如果LLM士正在进行一次随意的谈话,提示可能会包括以下信息
文本
Let's have a friendly chat about your favorite hobbies.
使用输入文本指导完成格式设置
通过以特定的方式格式化输入文本,我们可以引导LLM生成更相关的响应。例如,如果LLM被训练为生成配方指令,则输入文本的格式可以设置为“首先,[动作],然后[动作]和最后[动作]”。这种格式引导LLM以顺序方式生成指令。同样,如果LLM被训练为生成新闻文章的摘要,则输入文本的格式可以设置为“文章谈论[主题]。它讨论[点1]、[点2]和[点3]。”这种格式引导LLM生成涵盖文章要点的摘要。在这里,我们可以看到为要生成的语言使用正确注释字符的重要性。
提示:/* Create a javascript dictionary with 5 cities and their location */ 完成:
JavaScript
var cities = {
'Los Angeles': [34.0522, -118.2437],
'New York': [40.7128, -74.0059],
'San Francisco': [37.7749, -122.4194],
'Chicago': [41.8781, -87.6298],
'Houston': [29.7604, -95.3698]
};
在这种情况下,我们会得到一个格式正确的JavaScript字典,其中包含所请求的信息。现在,如果你将“JavaScript”更改为python,并保持注释字符不变:提示:/* Create a python dictionary with 5 cities and their location */完成:
C
PyObject *pDict = PyDict_New();
PyDict_SetItemString(pDict, "San Francisco", Py_BuildValue("(f,f)", 37.77493, -122.419416));
PyDict_SetItemString(pDict, "New York", Py_BuildValue("(f,f)", 40.7127, -74.0059));
PyDict_SetItemString(pDict, "London", Py_BuildValue("(f,f)", 51.507351, -0.127758));
PyDict_SetItemString(pDict, "Paris", Py_BuildValue("(f,f)", 48.856614, 2.352222));
PyDict_SetItemString(pDict, "Tokyo", Py_BuildValue("(f
f)", 35.689487, 139.691706));
在这里,我们得到了制作python字典的C++代码,因为注释字符是/*而不是#。
添加支持信息
在提示中添加支持信息可以为LLM提供更多上下文,从而提高其响应的准确性。例如,如果提示要求LLM生成对特定问题的响应,提供其他信息可以帮助LLM生成更相关的响应。一个很好的例子是:
文本
Please explain transformer language model to a 15-year-old student.
同样,如果要求LLM生成产品描述,当提供额外信息时,LLM会生成更准确、更有说服力的描述。一个很好的例子是:
文本
Write a witty product description in a conversational style so young adult shoppers understand
what this product does and how it benefits them.
Use the following product details to summarize your description:
Title: {{shopify.title}}
Type: {{shopify.type}}
Vendor: {{shopify.vendor}}
Tags: {{shopify.tags}}
特定任务的知识丰富
通过任务特定知识丰富进行提示工程涉及从大型文本语料库中检索相关知识,并将其整合到提示中,以提高语言模型的性能。这种富集也被称为数据增强生成。实现这种丰富的一种方法是通过知识检索策略。这种策略涉及对大量知识上下文进行分块和索引,然后嵌入相似性上下文选择。以下是这种方法的工作原理:
- 将知识数据导入文档存储。可以使用多个数据源来构建知识文档存储。例如,您可以导入以下数据:
- Edmunds和《消费者报告》等网站的汽车评论
- 汽车制造商提供的.pdf格式的技术手册
- 路透社和美国有线电视新闻网等来源的新闻文章
这些数据源中的每一个都将在文档存储中表示为单独的文档。
- 将文本分为更小、可能重叠且更易于管理的部分。该块可以通过令牌的静态大小(例如1000)来实现。块大小是通过考虑LLM模型推理的令牌大小限制来定义的。它还可以使用知识数据中的嵌入式标题、主题或自然段落样式来实现。
- 嵌入生成/索引以实现高效检索。最后一步是生成嵌入并对分割后的文本进行索引,以实现高效检索。这一代涉及将每个片段表示为一个向量或一组捕获其关键语义属性的特征。例如,您可以使用预训练的语言模型(如BERT,text_embedding-ada-002)生成嵌入,并将其另存为向量存储。接下来,创建一个索引,将每个嵌入映射到其相应的文档。此索引允许您根据与查询嵌入的相似性快速检索包含相关信息的所有文档。
- 检索相关上下文(例如,块)。一旦知识库被分块和索引,下一步就是选择最相关的信息片段以纳入提示。一种方法是语义搜索。具体而言,将索引知识段的嵌入与输入提示的嵌入进行比较,以识别最相似的信息。
这种通过任务特定知识丰富进行快速工程的方法可以非常有效地提高LLM响应的准确性和相关性。通过将相关知识融入提示中,法学硕士可以产生更明智和准确的回应。这些响应可以增强用户体验,提高系统的有效性。下图提供了一个特定于任务的知识丰富架构设计示例。
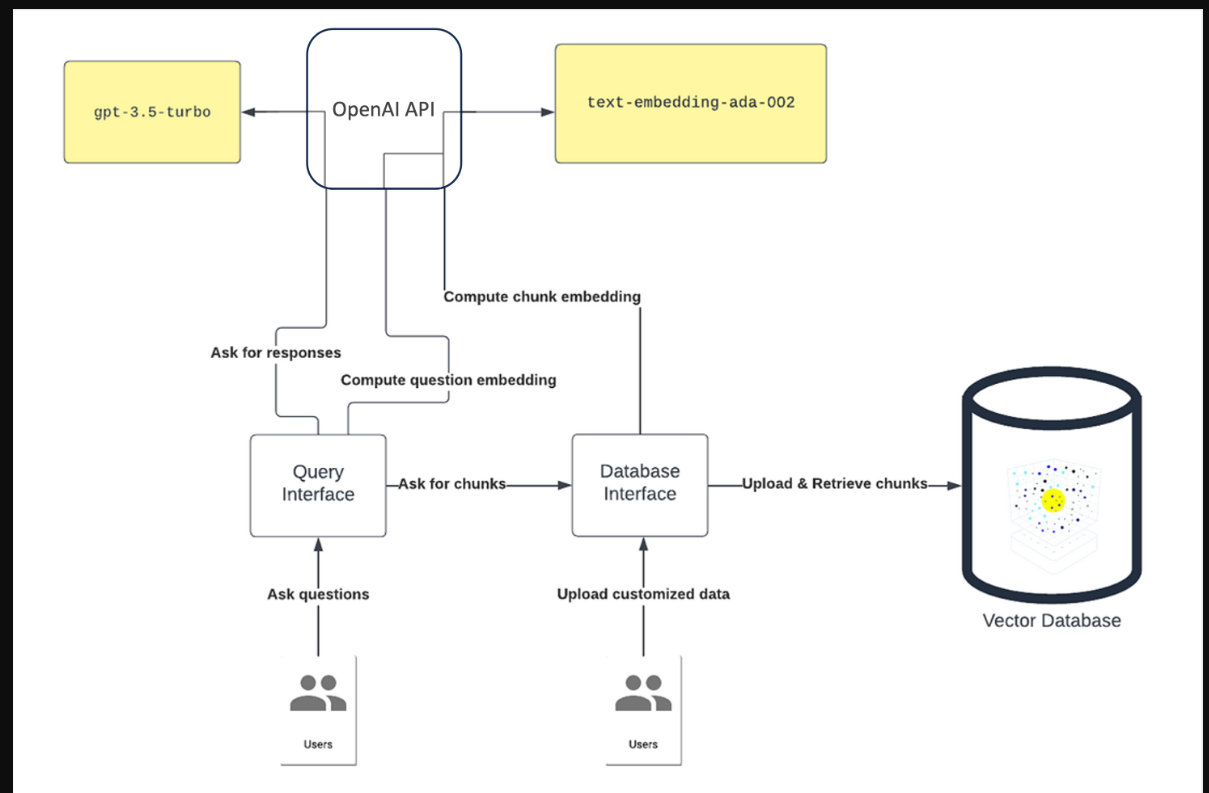
上下文检索
少样本示例
很少有镜头示例涉及在LLM中包含一些输入和输出示例(输入输出对),以指导其在内容和格式上的完成。以下示例是一个简单的几个镜头分类:
文本
apple: fruit
orange: fruit
zucchini: vegetable
现在,如果我们想知道番茄是水果还是蔬菜,我们可以在输入之前包含以下几个例子:
文本
apple: fruit
orange: fruit
zucchini: vegetable
tomato:
Complete this list
GPT-3.5以“"tomato: fruit (botanically), vegetable (culinarily)”作为回应。
前面的例子是一个静态的少镜头例子。无论我们试图对什么对象进行分类,都会使用相同的示例。然而,在某些情况下,我们可能希望根据输入提示动态选择不同的少数镜头示例。为此,手动创建了一个包含少量镜头示例的库/库。每个示例都在特征空间中表示(例如,使用预训练模型的嵌入)。然后,当出现新的提示时,选择该特征空间中最相似的少数镜头示例来指导语言模型。当以下语句为真时,此方法很有用:
- 为数不多的样本库数据庞大而多样
- 这些示例共享一个共同的底层模式
例如,如果少数镜头库数据由餐厅评论的各种示例组成,嵌入可以捕捉到用于描述食物、服务和氛围质量的语言的相似之处。最相似的例子可用于优化语言模型推理。
有不同的技术可以进一步改进/优化动态少镜头选择。一种方法是对少数镜头中的示例进行过滤或分类,以便更快地检索到更相关的示例。为了做到这一点,少数镜头库示例使用意图或任务进行标记。可以训练自定义模型来对这些示例进行分类(例如,体育、娱乐、政治等)。当出现新的提示时,分类器用于预测提示的任务或意图。然后,选择与预测任务最相关的少数镜头示例来指导语言模型推理。下图说明了动态少镜头示例检索的架构设计。该检索使用嵌入相似性或意图预测分类器方法。

小样本学习
使用会话历史记录
使用会话历史的提示工程涉及跟踪用户和语言模型之间的对话历史。这种方法可以通过考虑对话的上下文来帮助语言模型生成更准确的响应。以下是LLM如何跟踪对话历史以帮助生成准确回复的示例:
文本
User: The capital of India?
LLM: The capital of India is New Delhi.
User: What is the population of this city?
LLM: As of 2021, the estimated population of New Delhi is around 31.8 million people.
在这种情况下,法学硕士能够利用对话的历史来理解“这座城市”是指“新德里”。
另一个例子是以下多回合NL2Code交互,其中用户的请求遵循#注释字符,模型的代码遵循。
python
# Add a cube named "myCube"
cube(name="myCube")
# Move it up three units
move(0, 5, 0, "myCube")
对于第二个请求(“向上移动三个单位”),模型只能得到正确的完成,因为包含了之前的交互。
决定是否需要会话历史记录的一个有用技巧是将自己置于模型的位置,并问自己“我是否拥有完成用户想要的操作所需的所有信息?”
快速工程的挑战和局限性
虽然快速工程对于提高LLM推理结果的准确性和有效性很有用,但它也有很大的挑战和局限性。
在这里,我们总结了使用快速工程时的一些主要挑战。
- 提示输入的令牌大小限制:大多数LLM对可用作生成完成的输入的令牌数量有限制。这个限制可以低至几十个代币。此限制可以限制可用于生成准确补全的上下文数量。
- 提示工程的数据并不总是可用的:例如,提示可能需要特定领域的知识或日常交流中不常用的语言。在这种情况下,很难找到合适的数据用于快速工程。此外,用于快速工程的数据的质量会影响提示的质量。
- 随着提示量的增加,评估变得极其复杂:随着提示数量的增加,跟踪各种实验并隔离提示对最终输出的影响变得更加困难。这种跟踪困难可能会导致混淆,并使从实验中得出有意义的结论更具挑战性。
- 复杂的提示会增加延迟和成本:LLM需要时间和资源来处理和响应复杂的提示。它还增加了延迟,这可能会减缓模型开发和部署的整个过程。更复杂的提示也会增加每次LLM调用中的提示令牌大小,从而增加运行实验的成本。
- 小的提示更改可能会产生很大的影响:即使是小的提示变化,也很难预测模型的行为。这可能会导致意想不到的结果。这在准确性和一致性至关重要的应用中会出现问题,例如在自动化客户服务或医疗诊断中。
- 登录 发表评论
- 113 次浏览
最新内容
- 1 week ago
- 1 week 4 days ago
- 1 month 4 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago