
category
让我们深入了解并比较一下目前可用的一些领先的开源大型语言模型(LLM)。
从Meta令人敬畏的700亿参数Llama 2到微软灵活的27亿参数Phi 2,这些模型代表了生成人工智能能力的前沿。
我们的分析侧重于开源LLM的体系结构、培训数据、基准测试、许可证、社区参与和专业能力。
此精简概述旨在指导用户为各种应用程序(从生产聊天机器人到自定义助理)选择最合适的LLM。
鉴于这些模型的快速发展,我们的景观分析为评估基础模型潜力的人提供了当前的视角。
| Model | Style | Community Engagement |
|---|---|---|
| Mixtral 8x7B | MoE transformer model based on Mistral 7B | 1.07k likes |
| Mistral 7B | Transformer model with Grouped-Query Attention, Sliding-Window Attention, and Byte-fallback BPE tokenizer | 1.96k likes |
| LlaMA 2 | Transformer, 70B Parameters, Instruct & Chat | 3,500+ likes and 1.5M+ downloads |
| Phi 2 | Transformer-based model with next-word prediction objective, 2.7B Parameters | 2k likes |
| Vicuna | Transformer, 33B Parameters, Instruct | 900+ likes and 500k+ downloads |
| Falcon | Casual decoder-only, 180B, Task-specific Instruct | 900+ likes and 30k+ downloads |
| MPT | Transformer, 30B, Instruct & Completion | 1k+ likes and 20k+ downloads |
| StableLM | Decoder-only, 7B, Instruct | 354+ likes and 10k+ downloads |
| Yi 34B | Bilingual base model, 34B Parameters | 1k likes |
| Falcon 180B | Super-powerful language model, 180B Parameters | 931 likes |
| MPT-7B | Decoder-style transformer model, 7B Parameters | 1.1k likes |
Zephyr 7B
Zephyr-7B是Hugging Face开发的一个大型语言模型。这是Mistral-7B模型的微调版本,使用直接偏好优化(DPO)在公开可用和合成数据集的混合上进行训练。该模型主要用于充当有用的助手,主要用于英语任务。
西风-7B有两个版本:阿尔法和贝塔。Alpha版本是该系列的第一个版本,之后不久又推出了Beta版本,性能有所提高。
该模型的训练涉及一个称为知识提取的过程,这允许较小的模型(在本例中为70亿参数的Zephyr-7B)从较大的模型中学习。这种方法使Zephyr-7B能够平衡性能和效率,使其适用于计算资源有限的环境,而不会牺牲交互和理解的质量。
Zephyr-7B已经通过各种基准进行了评估,这些基准评估了模型在单回合和多回合环境中的会话能力。它在MT Bench和AlpacaEval上为7B车型建立了新的基准,并显示出与大型车型相比的竞争性能。
但是,需要注意的是,模型的性能因具体任务而异。例如,它在编码和数学等任务上落后。因此,用户应该根据他们的具体需求选择型号,因为Zephyr-7B可能不是最适合所有任务的。
Zephyr-7B型号的一个独特之处在于其未经审查的特性。虽然它在一定程度上不受审查,但它的设计目的是在收到提示时对非法活动提出建议,确保其在应对措施中遵守道德准则。
您可以使用LMStudio或UABA文本生成WebUI在本地使用Zephyr-7B,从而提供在首选环境中使用该模型的灵活性。如果使用Python,则可以使用“拥抱面变换器”库加载模型。
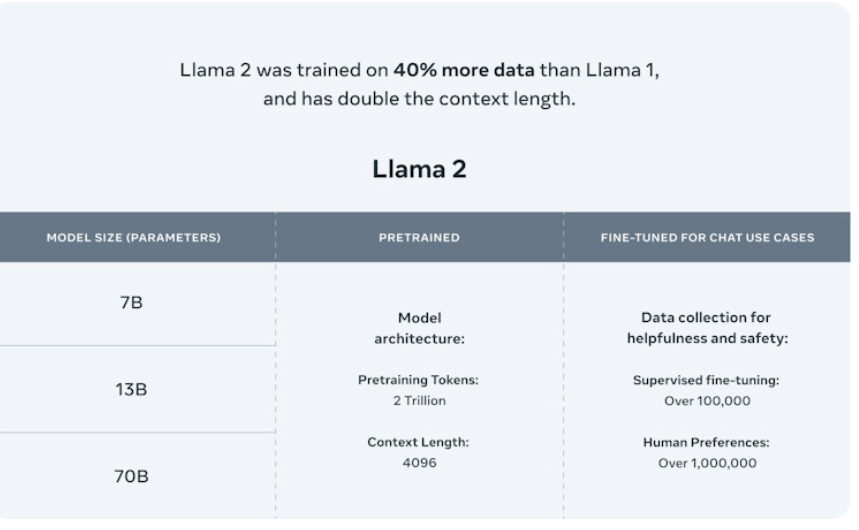
Llama 2
Llama 2由Meta AI开发,是一款开源LLM,预训练模型的参数范围从7B到70B。它在各种基准测试上都优于其他开源LLM,包括推理、编码、熟练度和知识测试。Llama 2还提供了经过微调的模型,如Llama Chat和Code Llama,它们支持通用编程语言。
模型卡
- 开发者:Meta AI
- 参数:7B至70B
- 预训练时间:公开的在线数据源
- 微调模型:Llama聊天,代码Llama
- 基准:在推理、编码、熟练程度和知识测试方面优于其他开源LLM
- 许可证:开源,免费供研究和商业使用
- 值得注意的特点:将Llama 1的上下文长度增加了一倍,从人类反馈中强化学习以确保安全和有用
Llama 2是一个开放源码的大型语言模型(LLM),其参数大小从7B到65B不等。虽然它的性能与GPT-3.5相当,但并没有在很大程度上优于GPT-3。该体系结构基于转换器模型,结合了SwiGLU激活函数、旋转位置嵌入和均方根分层归一化等功能。
Klu Meta Llama 2模型卡
Llama 2模型是其前身的改进版,提供了对话和聊天的微调功能,包括处理多任务和复杂的对话场景。Llama 2受益于监督微调和拒绝采样等技术,然后是近端策略优化(PPO),使其能够生成连贯且与上下文相关的文本。拒绝采样(RS)包括从语言模型策略中采样一批K个补全,并在奖励模型中对其进行评估,返回最佳补全。PPO是一种流行的在线强化学习算法。
虽然在Llama 2的上下文中没有明确提到人类学论文,但这两种方法在使用来自人类反馈的强化学习(RLHF)来提高其模型的性能方面都有相似之处。在Llama 2中,拒绝采样和PPO的结合有助于完善模型的输出,使其与人类的期望相一致,例如聊天或安全功能。

Klu Meta Llama 2 RLHF
Llama 2是通过与行业领导者的合作伙伴关系提供的,如与微软、AWS、拥抱脸和雪花的战略合作伙伴关系,促进了生成人工智能工具的开发和部署,并扩大了开发者的可访问性。
Llama 2-chat变体专门针对对话进行了微调,有27540对即时响应对,使其能够进行动态的、上下文丰富的对话。该模型使用来自公开数据源的2万亿个代币进行训练,不包括网站上的个人数据。
尽管Llama 2取得了进步,但它也有一些局限性。在训练和推理过程中,其大量的计算资源需求可能会限制小型企业和开发人员的访问。此外,其深度神经网络架构使其难以解释决策过程,限制了其在关键应用中的可用性。
就性能而言,一款经过微调的LLaMa车型Upstage在Open LLM排行榜上以72.95的成绩跻身前两名。此外,Open LLM排行榜上目前的领先者是Llama模型与两个经过微调的Llama型号(Upstage和Platypus2)的合并,这两个型号展示了Llama模式的广泛性和性能。
你可以通过模型的下载页面或他们的GitHub访问Llama 2,对于技术人员,可以在他们的论文中了解更多关于模型的信息。
Mistral 7B
Mistral 7B是由Mistral AI开发的70亿参数LLM。它在所有基准测试中都优于Llama 2 13B,并使用滑动窗口注意力(SWA)来优化模型的注意力过程,从而显著提高了速度。
模型卡
- 开发者:Mistral AI
- 参数:70亿
- 模型架构:具有分组查询注意力、滑动窗口注意力和字节回退BPE标记器的Transformer模型
- 基准:在所有测试基准上的表现均超过Llama 2 13B
- 许可证:Apache 2.0
Yi 34B
Yi 34B是由01.AI开发的一个具有340亿参数的双语(英文和中文)基础模型。在拥抱脸的排名中,它优于Falcon-180B和Meta-LaMa2-70B等大型开放模型。
模型卡
- 开发者:01.AI
- 参数:340亿
- 语言:英语和汉语
- 模型类型:双语基础模型
- 排名:在拥抱脸的排名中超过Falcon-180B和Meta LlaMa2-70B
Falcon 180B
Falcon 180B是由技术创新研究所(TII)开发的一个超级强大的语言模型。它有1800亿个参数,并在3.5万亿个代币上进行了训练。Falcon 180B目前在经过预训练的开放式大型语言模型的拥抱脸排行榜上名列前茅,可用于研究和商业用途。
该模型在推理、编码、熟练度和知识测试等各种任务中表现异常出色,甚至击败了Meta的Llama 2等竞争对手。在开源模型中,它的排名仅次于OpenAI的GPT 4,与谷歌的PaLM 2 Large不相上下,后者为Bard提供了动力,尽管只有该模型的一半大小。
模型卡
- 开发商:技术创新研究所
- 参数:1800亿
- 模型体系结构:未指定
- 预训练:3.5万亿代币
- 基准:预先训练的开放式大型语言模型在拥抱脸排行榜上名列前茅。性能超过Meta的Llama 2,与谷歌的PaLM 2 Large不相上下
- 许可证:可用于研究和商业用途
- 显著特点:在推理、编码、熟练程度和知识测试方面表现优异。
Falcon 180B的下载受TII的条款和条件以及可接受使用政策的约束。
Falcon LLM由技术创新研究所根据Apache 2.0许可证开发,是另一个强大的开源LLM,在创新和精度方面带来了很大的希望。Falcon在AWS上使用384个GPU对400亿个参数和惊人的1万亿个代币进行了训练,使用了自回归解码器架构类型。
与众不同的是,Falcon采取了一条非传统的路线,将数据质量置于绝对数量之上。利用专门的数据管道和自定义编码,它利用了RefinedWeb数据集,该数据集源于经过精心过滤和消除重复的公开可用web数据。此外,它还利用旋转位置嵌入(类似于LLaMa)、Multiquery和FlashAttention来引起注意。
凭借其7B和40B参数的指导模型,Falcon为各种用例提供了适应性,包括对话和聊天。使用EleutherAI评估框架,基于40B参数的最具性能的猎鹰模型得分为63.47。此外,在Chatbot Arena排行榜上,Falcon 40B Instruction在MT Bench基准上的成绩为5.17分(满分10分)。
然而,猎鹰LLM和任何LLM一样有其局限性。它仅限于几种语言——英语、德语、西班牙语和法语。此外,其培训数据来源引入了网络上潜在的陈规定型观念和偏见。此外,由于缺乏详细的技术文件来显示可靠性、风险和偏差评估,因此必须谨慎使用,尤其是在生产或关键环境中。
通过拥抱脸访问、微调和部署猎鹰40B型号。
MPT-7B
MPT-7B是MosaicML开发的一种解码器风格的转换器模型。它是在一万亿个英文文本和代码标记上从头开始进行预训练的。MPT-7B是MosaicPretrainedTransformer(MPT)家族的一部分,该家族使用了经过优化的改进变压器架构,以实现高效的训练和推理。这些体系结构的变化包括性能优化的层实现,以及通过将位置嵌入替换为具有线性偏差的注意力(ALiBi)来消除上下文长度限制。
模型卡
- 开发者:MosaicML
- 参数:67亿
- 模型架构:解码器式转换器
- 预训练:1万亿个英文文本和代码代币
- 许可证:Apache 2.0
- 值得注意的功能:ALiBi用于处理超长输入(最多84k个代币),FlashAttention用于快速训练和推理,通过llm铸造库高效开源训练代码
MPT-7B已经被证明优于其他开源7B-20B模型,并且与LLaMa-7B的质量相匹配。MPT系列包括其他型号,如MPT-7B-Directive、MPT-7B-Chat和MPT-7B-StoryWriter-65k+,它们针对特定任务进行了微调。
MPT,或MosaicML Performance Transformer,是一种差分开源LLM,可以突破LLM所能实现的极限。这个Apache 2.0授权的模型不仅在性能方面达到了令人印象深刻的高度,而且还强调了商业可用性。
经过Oracle Cloud的A100-40Gb和A100-80GB GPU的培训,MPT通过独特的数据管道方法脱颖而出。与其他模型不同,MosiacML使用了数据管道和EleutherAI的GPT-NeoX以及20B标记器的混合。重量可通过GitHub免费向公众提供。
MPT有一个转换器模型,它使用了1万亿个包含文本和代码的令牌。它的体系结构由三个经过微调的变体组成;MPT-7B-指令、MPT-7B-Chat和MPT-7B-StoryWriter-65k+。每种变体都适合不同的应用程序,从指令跟随到类似聊天机器人的对话生成。
MosiacML在模型开发方面的能力通过其用于微调MPT的工具集Composter、LLM Foundry、LION Optimizer和PyTorch FSDP而大放异彩。MPT模型的架构经过优化,通过将注意力与线性偏差(ALiBi)相结合来消除上下文长度限制。
您可以通过Hugging Face使用其他转换器和数据管道微调模型,并使用MosiacML平台进行训练。此外,要访问MosiacML基础模型(MPT-7B和MPT-30B及其变体)的训练代码,请使用它们的GitHub。您可以通过langchain配置和微调MPT-7B,并使用谷歌Colab等典型笔记本电脑轻松配置。
就与其他型号的性能而言,在对话和聊天方面表现最出色的MPT-30B-chat模式在Arena Elo评分和MT替补席评分中分别为1046分和6.39分,落后于Vicuna-33B,但领先于Llama-2-13b-chat(Arena Elon评分)。此外,Open LLM排行榜上的MPT-30B LLM模型的平均得分为61.21,落后于Falcon模型。然而,MPT不适合在没有任何微调的情况下进行部署,开发人员应该确保放置定义良好的护栏。此外,与所有LLM模型一样,该模型有时会产生事实上不正确的输出。
Phi 2
Phi-2由微软开发,参数为27亿,是一种基于Transformer的LLM,使用GPT-3.5-turbo的1.4万亿个合成数据代币进行训练。尽管Phi-2的规模很大,但它与大25倍的模型竞争,包括在推理、语言理解和编码基准方面优于700亿参数的Llama-2。它在96个A100 GPU的集群上进行了为期两周的培训,重点关注Python和常见库,如“打字、数学、随机、集合、日期时间、迭代工具”。用户应使用其他包或语言验证生成的任何代码。
虽然Phi-2没有根据以下说明进行微调,但它可能在训练数据中表现出社会偏见。微软通过Azure AI Studio提供Phi-2用于研究,但未针对生产任务进行验证。当使用变压器版本4.36.0或更高版本时,用户应加载trust_remote_code=True的模型,并将输出视为建议。Phi-2的培训具有成本效益,但它需要精确的提示来遵守指示,强调了提示驱动LLM的细微差别。
模型卡
- 开发人员:Microsoft Research
- 参数:27亿
- 模型架构:基于Transformer的模型,具有下一个单词的预测目标
- 预训练:StackOverflow的Python代码子集、代码竞赛的竞赛代码、合成Python教科书、GPT-3.5-turbo-0301生成的练习以及各种NLP合成文本
- 基准:根据测试常识、语言理解和逻辑推理的基准进行评估时,在具有1.4万亿参数的模型中,性能几乎是最先进的。在AGIEval得分上超过Meta的Llama2-7B,在GPT4ALL的LM Eval Harness基准套件中几乎达到Llama2-7B。
- 许可证:开源,免费供研究使用
- 显著的特点:擅长复杂的推理任务,在高质量的合成数据上进行训练,并展示了类似人类的编码能力,而不需要大量的参数。
- 登录 发表评论
- 203 次浏览
最新内容
- 22 hours ago
- 1 week 1 day ago
- 1 week 5 days ago
- 2 months ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago