
Chinese, Simplified
可用性目标场景
在本节中,我们将回顾一个示例应用程序,并阐述部署架构如何因不同的可用性目标而变化。示例应用程序是一个典型的web应用程序,它具有反向代理、S3中的静态内容、应用程序服务器和SQL数据库。无论我们在容器还是虚拟机中部署它们,可用性设计都保持不变。
服务选择
我们将使用EC2进行计算,使用Amazon RDS进行关系数据库,并利用Multi-AZ部署。将使用路由53进行DNS,使用ELB分配负载,使用S3进行备份和静态内容。
99%(2个9)方案
应用特点
- 根据可用性图表,这些应用程序每年的停机时间约为3天15小时。
- 这些应用程序通常对业务有帮助,如果不可用,可能会带来不便(不是关键任务)。
- 大多数内部系统都属于这一类别,并具有实验性的客户功能。
部署设计
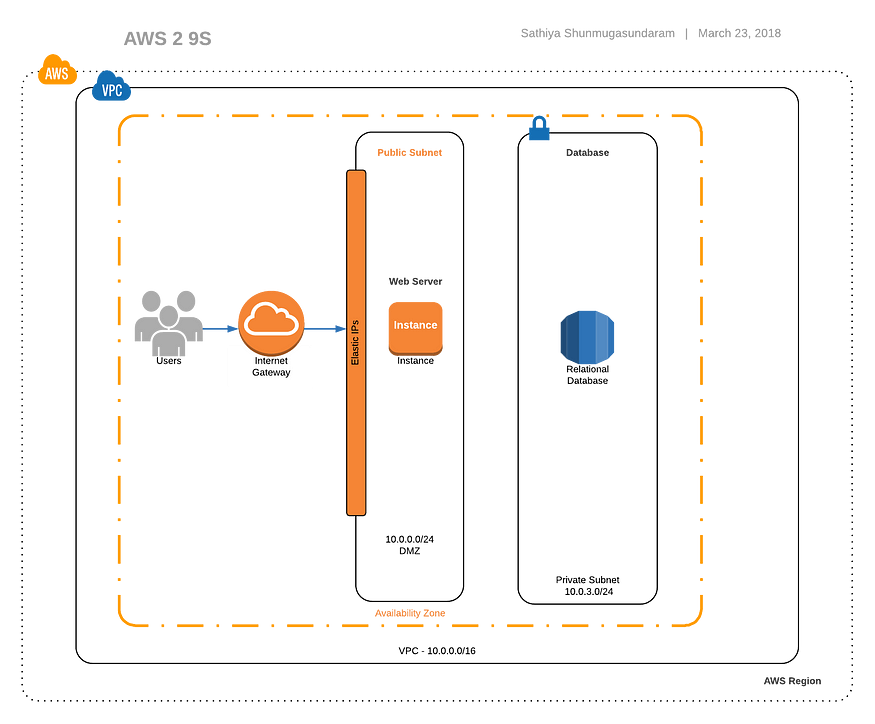
- 单个区域
- 一个可用区域
- 单个实例
- 将备份数据发送到S3进行恢复,对对象启用版本控制,对备份禁用删除,存档/删除旧数据的生命周期策略
- Cloudformation将基础设施定义为一个代码,并将用于在出现故障时加快整个基础设施的重建。
- 故障期间,使用DNS更改,将流量路由到静态网站
- 部署管道计划有基本单元/黑盒/白盒测试
- 软件更新是手动的,需要停机
- 监控查找主页的200 OK状态
可用性计算
在这种设计中,每次故障恢复大约需要70分钟。每次部署/软件更新需要4小时。估计大约有4次故障和6次其他更改,可用性达到99%。
99.9%(3个9)方案
应用特点
- 根据可用性图表,这些应用程序每年的停机时间约为8小时45分钟。
- 这些应用程序的高可用性很重要,但可以承受短暂的不可用时间。
- 例如,关键的内部应用程序和低收入的面向客户的应用程序。
部署设计
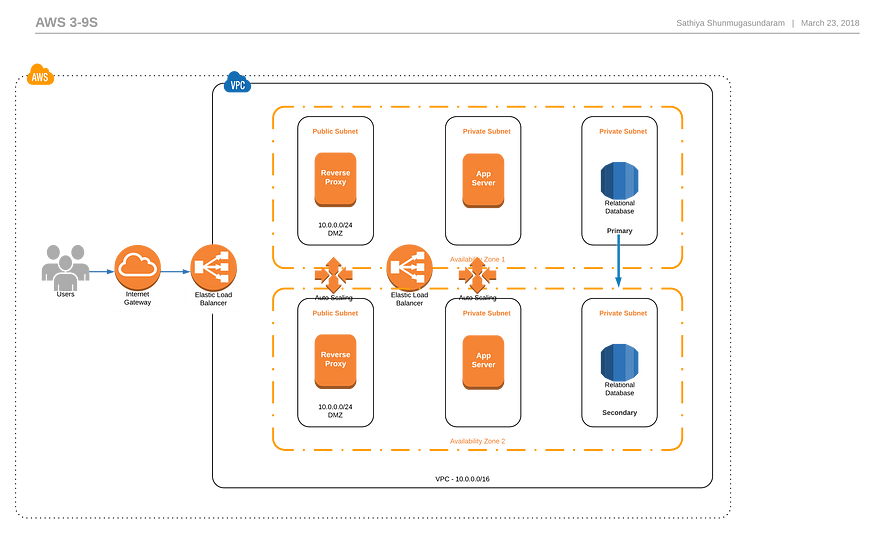
- 我们将利用利用多个可用区域的AWS服务。(ELB/ASG/RDS MultiAZ)
- 负载平衡器将配置应用程序健康检查,该检查实际上描述了每个实例中应用程序的健康状况
- ASG将替换运行状况检查失败的实例,RDS将故障转移到第二个AZ以处理主要AZ故障
- 应用程序将分为不同的层(反向代理/应用程序服务器),以提高可用性。应用程序恢复模式将确保在AZ故障切换期间短暂的数据库不可用不会影响应用程序可用性
- 使用就地方法自动更新软件,并在出现故障时记录回滚过程
- 每2-4周按固定计划交付软件
- 监控将检查主页上的200 OK状态、web服务器的更换、数据库故障切换和S3中的静态内容可用性
- 将汇总日志以进行根本原因分析
- 存在用于恢复和报告的Runbook
- 行动手册适用于常见的数据库相关问题、安全相关事件、失败部署以及根本原因分析。
可用性计算
假设2次故障需要人工干预,每次事故60分钟,则影响将为2小时。假设自动软件更新需要每次停机15分钟,并且需要10个这样的实例,我们将需要150分钟的停机时间。这为我们提供了99.9%的可用性
99.99%(4个9)方案
应用特点
- 根据可用性图表,这些应用程序的停机时间约为52分钟/年。
- 这些应用程序必须具有高可用性,能够容忍部件故障,并且能够吸收故障而无需获取部件故障。
- 例如电子商务应用程序和b2b web服务。
- 我们应该通过在一个区域内保持静态稳定来进行设计。这意味着我们需要能够容忍一个AZ的丢失,而不需要提供新的容量或更改DNS等。。
部署设计
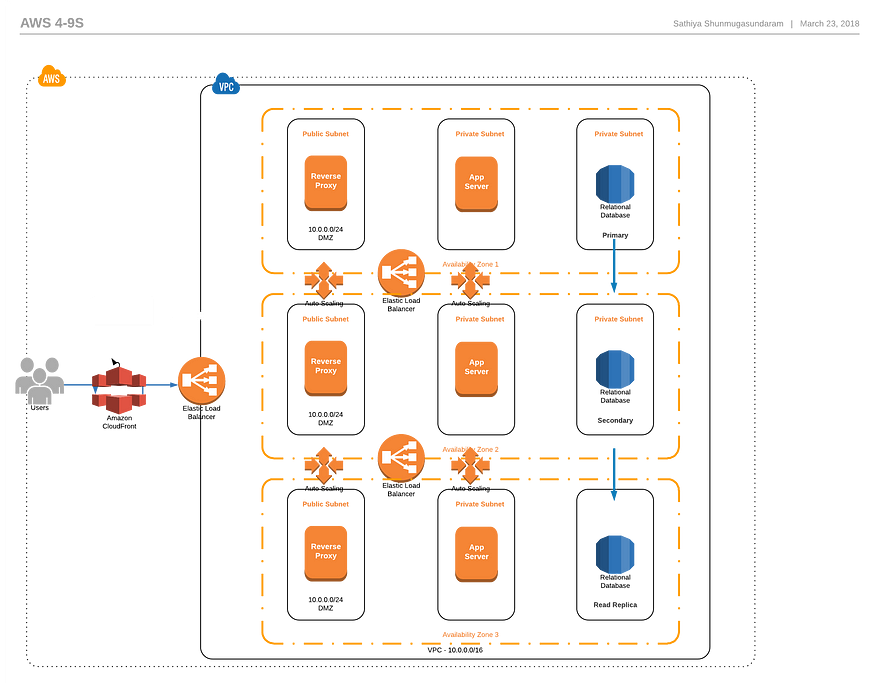
- 在3个AZ中部署应用程序,每个AZ的容量为50%
- 对于可以缓存的内容,请添加CloudFront以减少系统负载
- 在所有层中实施软件/应用程序恢复模式
- 设计主内容的读可用性而非写可用性
- 利用故障隔离区部署策略
- 部署管道还必须包括性能、负载和故障注入测试
- 如果不满足KPI,部署应完全自动化并自动回滚
- 监控应报告成功情况,并在出现问题时发出警报
- 必须存在未发现问题和安全事件的行动手册
- 使用游戏日测试失败程序
可用性计算
假设2次故障需要人工干预,每次事故15分钟,则影响将为30分钟。自动软件更新不需要停机。这为我们提供了99.99%的可用性
多区域部署
使用多个地理区域将以增加支出为代价对恢复时间提供更大的控制。区域提供了非常强的隔离边界。
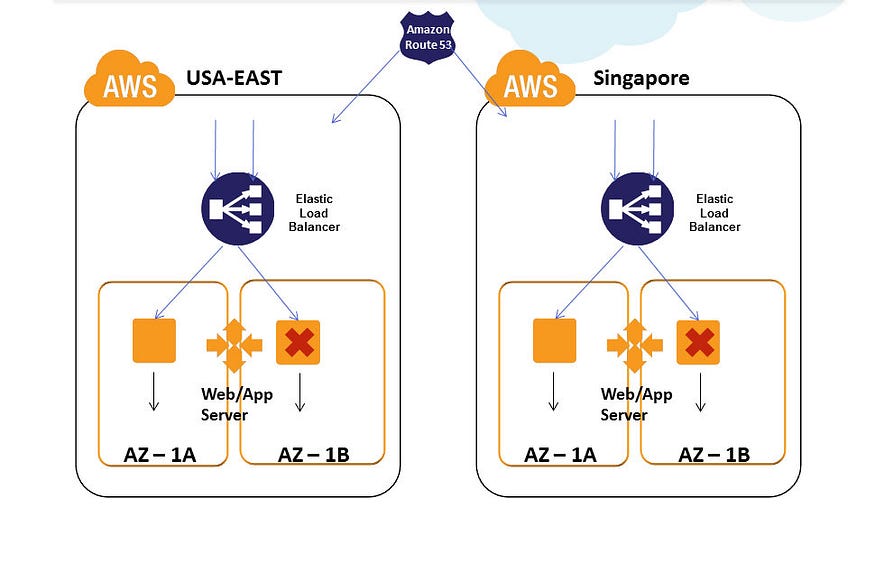
Multi-Region Deployment Courtesy of http://harish11g.blogspot.com
使用多区域部署的99.95%(3.5个9)场景
应用特点
- 根据可用性图表,这些应用程序每年的停机时间约为4小时。
- 这些应用程序必须高度可用,需要非常短的停机时间和很少的数据丢失
- 例如银行、投资和应急服务
部署设计
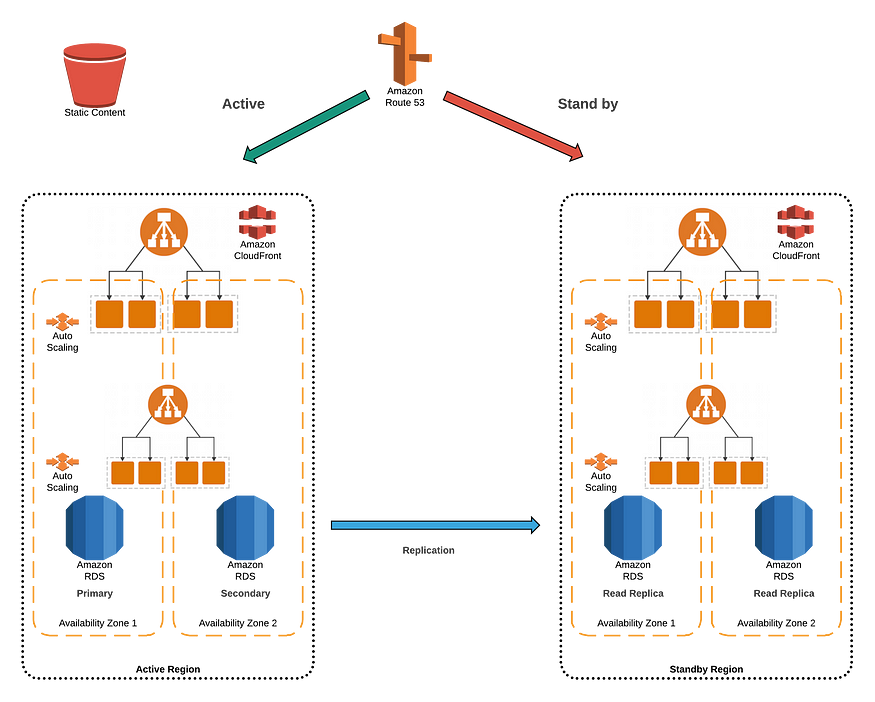
- 99.95 % SLA
- 跨两个区域使用热备用
- 被动站点扩展并最终保持一致,以接收与主动站点相同的流量
- 即使在1个AZ故障期间,两个区域也应保持静态稳定,以处理所有容量需求
- 在所有层中实施软件/应用程序恢复模式
- 将需要一个轻量级的路由组件来监控应用程序运行状况和区域依赖性。路由组件将自动化故障,停止复制
- 故障切换期间,请求将被路由到静态网站
- 软件更新将使用蓝绿/金丝雀部署方法
- 部署管道还必须包括性能、负载和故障注入测试
- 监视服务器/db/静态内容和区域故障并发出警报
- 通过游戏日使用Runbook验证体系结构
可用性计算
假设2次故障需要人工干预,每次事故30分钟,则影响将为60分钟。自动软件更新不需要停机。这为我们提供了最高99.95%的可用性
99.999%(5个9)或更高的方案
应用特点
- 根据可用性图表,这些应用程序每年的停机时间约为5分钟
- 这些应用程序必须高度可用,并且不允许停机和数据丢失
- 例如高收入银行、投资和关键政府职能
部署设计
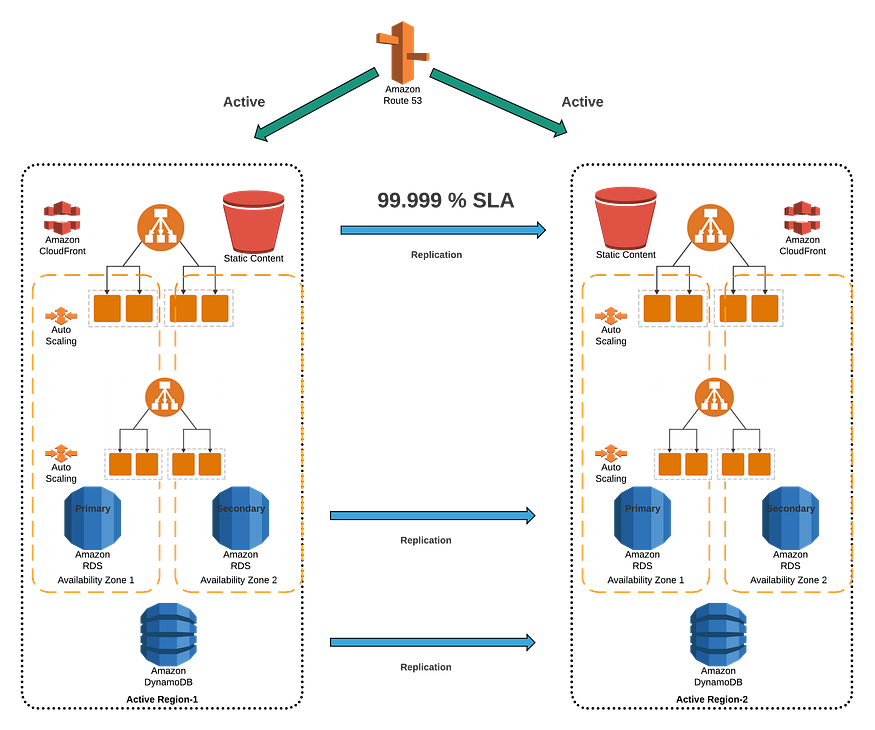
- 强一致性数据存储
- 所有层完全冗余
- 尽可能使用NoSQL数据库来改进分区策略
- 利用主动/主动多区域方法。每个区域必须是静态稳定的
- 路由层将向正常站点发送流量,并在故障期间停止复制
- 在所有层中实施软件/应用程序恢复模式
- 部署管道还必须包括性能、负载和故障注入测试
- 软件更新将使用蓝绿/金丝雀部署方法
- 如果不满足KPI,部署应完全自动化并自动回滚
- 数据存储复制技术应自动解决冲突
可用性计算
假设所有恢复过程都是自动化的,并且具有冗余性,则影响将小于一分钟,预计将发生4次此类事件。自动软件更新不需要任何停机时间。这为我们提供了99.999%的可用性
发布日期
星期六, 十二月 10, 2022 - 14:53
最后修改
星期四, 一月 5, 2023 - 21:58
Article
最新内容
- 9 hours ago
- 1 week 6 days ago
- 3 weeks ago
- 3 weeks 4 days ago
- 2 months 1 week ago
- 6 months 1 week ago
- 6 months 1 week ago
- 6 months 1 week ago
- 6 months 1 week ago
- 6 months 1 week ago