
提到https://en.wikipedia.org/wiki/Software_design_pattern详细概述了什么是设计模式,并参考了几种软件设计模式。本故事旨在回顾与云环境中的弹性和可用性相关的一些流行设计模式。
本故事的参考来自以下链接,所有图片均由各自的内容所有者提供。
- https://docs.microsoft.com/en-us/azure/architecture/patterns/
- http://en.clouddesignpattern.org/index.php/Main_Page
可用性模式
可用性表示系统运行和工作的时间。它可能会受到系统维护、软件更新、基础架构问题、恶意攻击、系统负载和与第三方提供商的依赖关系的影响。可用性通常通过SLA和9来衡量。例如,“五个9”意味着99.999%的可用性,这意味着系统在一年内可以停机约5分钟。检查https://uptime.is/查找特定SLA的可用性
运行状况终结点监视
在云中,应用程序可能会受到几个因素的影响,如延迟、提供商问题、攻击者和应用程序问题。有必要定期监视应用程序是否正常工作。
解决方案大纲
- 创建运行状况检查终结点
- 端点必须进行有用的健康检查,包括存储、数据库和第三方依赖关系等子系统
- 使用状态代码内容返回应用程序可用性
- 以适当的时间间隔监控终点,以及距离客户较近的地点的延迟
- 保护端点以防止攻击
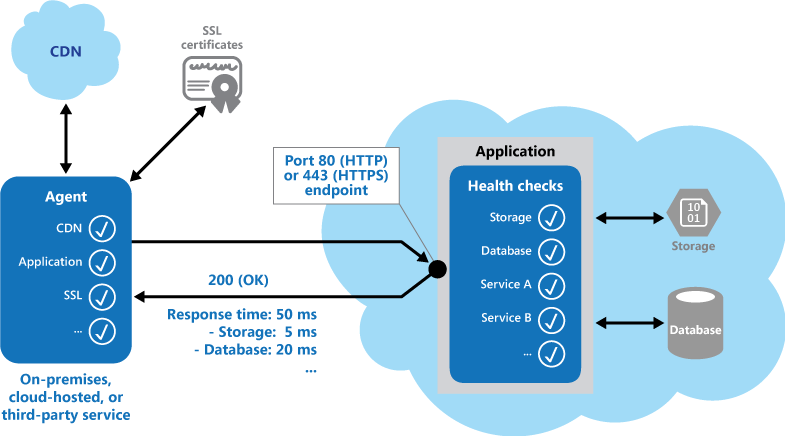
有关完整概述,请参阅Microsoft链接
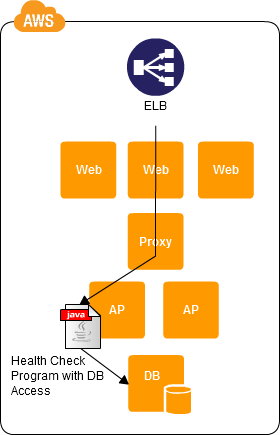
下图描述了AWS特定实现中的相同模式。这解释了健康检查应该有多深,而不是前面的静态页面。
有关详细信息,请参阅链接。
Other references
- http://microservices.io/patterns/observability/health-check-api.html
- https://docs.aws.amazon.com/elasticloadbalancing/latest/application/target-group-health-checks.html
- https://docs.aws.amazon.com/Route53/latest/DeveloperGuide/health-checks-creating.html
基于队列的负载调配
重载/频繁请求可能会使服务过载,从而影响可用性。通过对此类请求进行排队并异步处理,将有助于提高系统的稳定性。

解决方案大纲
- 在任务和服务之间引入队列
- 任务放置在队列中
- 服务以所需的速度处理任务。在一些高级实现中,服务可能会根据队列大小自动缩放。
- 如果需要响应,服务必须提供适当的实现,但是,这种模式不适合低延迟响应需求
有关完整概述,请参阅链接
其他参考资料
- https://msdn.microsoft.com/library/dn589781.aspx
- http://soapatterns.org/design_patterns/asynchronous_queuing
节流
限制服务或其组件或客户端使用的资源数量,以便即使在极端负载期间,服务也能继续运行,满足SLA要求
解决方案大纲
- 设置单个用户访问的限制,监控指标并在超过限制时拒绝
- 禁用或降级不重要的服务,以便关键服务能够正常工作,例如,视频通话只能在带宽问题期间切换到音频
- 确定某些用户的优先级,并使用负载均衡来满足高影响客户的需求
有关完整概述,请查看链接
其他参考资料
弹性模式
弹性是系统从故障中优雅地恢复的能力。检测故障并快速高效地恢复是关键。
隔板(Bulk Head)
隔离应用程序组件,使其中一个组件的故障不会影响其他组件。隔板表示船舶的分段隔板。如果一个隔板受损,水只会在该隔板中,从而避免船舶沉没
解决方案大纲
- 将服务实例划分为多个组并单独分配资源,以便故障不会消耗此池之外的资源
- 根据业务和技术需求定义分区,例如,高优先级客户可能获得更多资源
- 利用Polly/Histrix等框架,并使用Containers等技术提供隔离。例如,容器可以为CPU/内存消耗设置硬限制,以便容器的故障不会耗尽资源。
有关完整概述,请参阅链接
其他资源
断路器
当一个服务被认为已经失败,并且如果它继续运行可能会对其他应用程序产生负面影响时,它应该抛出异常,并且可以稍后在问题似乎已修复时恢复,可以恢复该服务
解决方案大纲
下图显示了使用状态机实现断路器
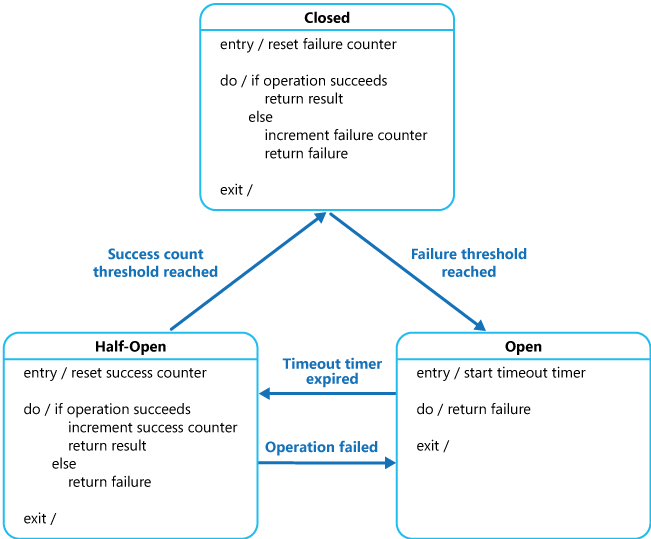
有关完整概述,请查看链接
其他参考文献
- http://microservices.io/patterns/reliability/circuit-breaker.html
- https://spring.io/guides/gs/circuit-breaker/
补偿事务处理
在分布式系统中,强一致性并不总是最佳的。最终的一致性会产生更好的性能和组件集成。当发生故障时,必须撤消前面的步骤。
解决方案大纲
- 补偿事务将记录工作流的所有步骤,并在出现故障时开始撤消操作
下图描述了一个具有顺序步骤的示例用例。
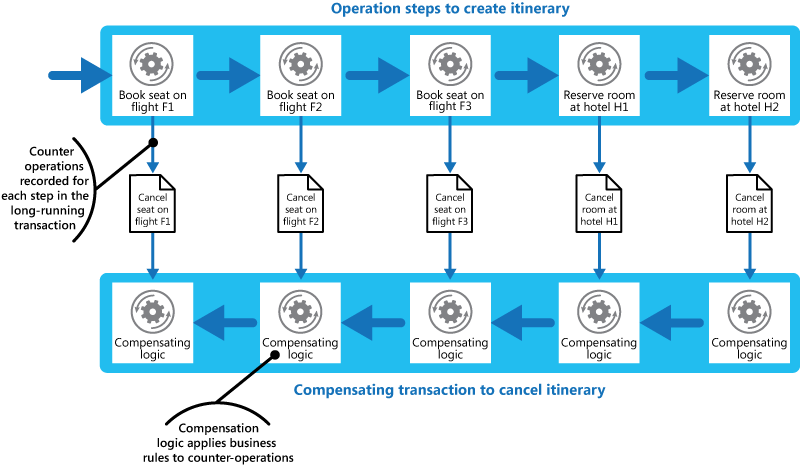
补偿事务不必撤消完全相同的顺序,可以执行并行调用。
有关详细概述,请查看链接
其他参考文献
领导人选举
协调多个类似实例执行的操作。例如,多个实例可能正在执行类似的任务,可能需要协调,也可能避免对共享资源的争用。在其他一些情况下,可能需要汇总几个类似实例的工作结果。
解决方案大纲
单个任务实例应被选为领导者。这将与其他从属实例协调操作。由于所有事例都是相似的,并且是同行的,因此必须有一个强有力的领导人选举过程
领导人选举过程可以使用以下几种策略
- 选择排名最低的实例或进程ID
- 获取Mutex-当领导者断开连接或失败时,应小心释放Mutex
- 实现常见的领导人选举算法,如Bully或Ring
此外,利用任何第三方解决方案,如Zookeeper,避免开发复杂的内部解决方案
有关详细概述,请查看链接
其他参考文献
重试
通过重试失败的操作来启用应用程序处理瞬时故障,以提高应用程序的稳定性
解决方案大纲
各种方法包括
- 如果故障被视为非瞬时故障且不太可能修复,则取消
- 如果故障看似异常,则立即重试,并且立即重试可能会成功
- 如果故障看起来是临时问题,并且可能在短时间间隔后修复,例如API速率限制问题,请在延迟后重试。
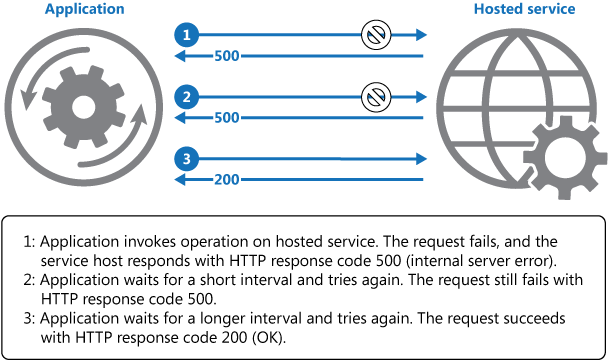
重试尝试应谨慎,不应使已加载的应用程序紧张。此外,请考虑要重试的操作的安全性(Idemptent)
有关完整参考,请查看链接
其他参考文献
调度程序代理主管
协调更大的操作。当事情失败时,尝试恢复,例如使用重试模式并成功,但如果系统无法恢复,则撤消工作,以使整个操作以一致的方式失败或成功。
解决方案大纲
解决方案涉及3个参与者
- 调度器-安排工作流中各个步骤的执行并协调操作。调度器还记录每个步骤的状态。调度器与代理通信以执行步骤。调度器/代理通信通常使用队列/消息传递平台异步进行
- 代理-通过一个步骤封装调用远程服务引用的逻辑。每个步骤可能使用不同的代理
- 主管-监视调度程序执行的任务中的每个步骤。在发生故障时,它请求由代理执行或由调度程序协调的适当恢复
下图显示了一个典型的实现
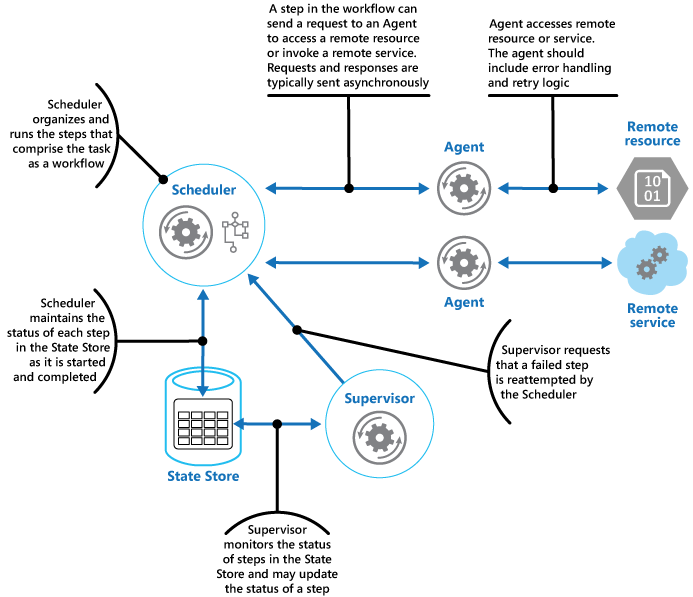
有关完整参考,请查看链接
其他参考文献
- Microsoft Azure Scheduler
- Process Manager pattern
- Cloud Architecture: The Scheduler-Agent-Supervisor Pattern
AWS特定模式
以下部分描述了一些显示特定AWS实现的模式。其中一些比较简单,但值得一看。
多服务器模式
在这种方法中,您可以在负载平衡器后面配置其他服务器,以提高数据中心/可用性区域内的可用性
您需要注意共享数据和粘性会话。利用其他数据访问模式解决此类问题
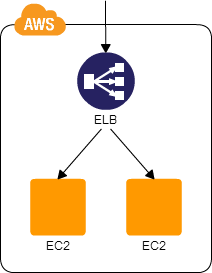
有关详细概述,请查看链接
多数据中心模式
这扩展了多服务器模式,通过在多个数据中心/可用性区域中创建服务器来解决数据中心故障
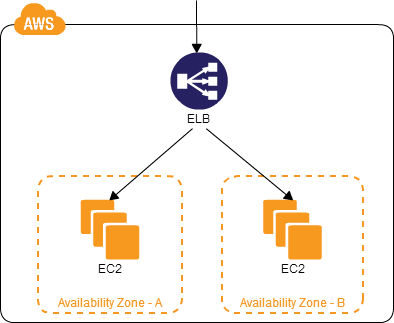
数据共享问题仍然如前一节所述。
有关完整概述,请查看链接
浮动IP模式
在这种情况下,应用程序会为服务器分配一个浮动IP,在发生故障时,该IP可以重新分配给另一个工作服务器。虽然这个想法是原始的,并且依赖于弹性IP特性,但是可以扩展该模式以实现高级架构。
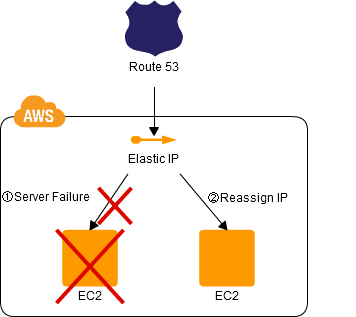
有关完整概述,请查看链接
最新内容
- 6 days 12 hours ago
- 2 weeks ago
- 2 weeks 4 days ago
- 2 months ago
- 6 months ago
- 6 months ago
- 6 months ago
- 6 months ago
- 6 months ago
- 6 months ago