
category
本文描述了三种用于机器学习操作的Azure架构。它们都具有端到端的连续集成(CI)、连续交付(CD)和再培训管道。这些架构适用于这些人工智能应用程序:
- 经典机器学习
- 计算机视觉(CV)
- 自然语言处理
这些体系结构是MLOps v2项目的产物。它们融合了解决方案架构师在创建多个机器学习解决方案的过程中发现的最佳实践。其结果是可部署、可重复和可维护的模式,如本文所述。
所有架构都使用Azure机器学习服务。
有关MLOps v2的示例部署模板的实现,请参阅GitHub上的Azure MLOps(v2)解决方案加速器。
潜在用例
- 经典的机器学习:对表格结构数据的时间序列预测、回归和分类是这一类别中最常见的用例。例如:
- 二分和多标签分类
- 线性、多项式、岭、套索、分位数和贝叶斯回归
- ARIMA、自回归(AR)、SARIMA、VAR、SES、LSTM
- CV:这里介绍的MLOps框架主要关注分割和图像分类的CV用例。
- NLP:这个MLOps框架可以实现这些用例中的任何一个,以及其他未列出的用例:
- 命名实体识别
- 文本分类
- 文本生成
- 情绪分析
- 翻译
- 问题回答
- 概述
- 句子检测
- 语言检测
- 词性标注
模拟、深度强化学习和其他形式的人工智能不在本文中涵盖。
架构
MLOps v2体系结构模式由四个主要模块化元素组成,这些元素表示MLOps生命周期的这些阶段:
- 数据属性
- 管理和设置
- 模型开发(内环)
- 模型部署(外循环)
这些元素、它们之间的关系以及通常与它们相关联的人物角色对于所有MLOpsv2场景架构都是通用的。根据场景的不同,每个细节可能会有所不同。
MLOps v2 for Machine Learning的基本架构是基于表格数据的经典机器学习场景。CV和NLP体系结构建立在这个基础体系结构之上并对其进行了修改。
当前架构
MLOps v2目前涵盖的架构以及本文中讨论的架构是:
- 经典的机器学习架构
- 机器学习CV架构
- 机器学习NLP架构
经典的机器学习架构
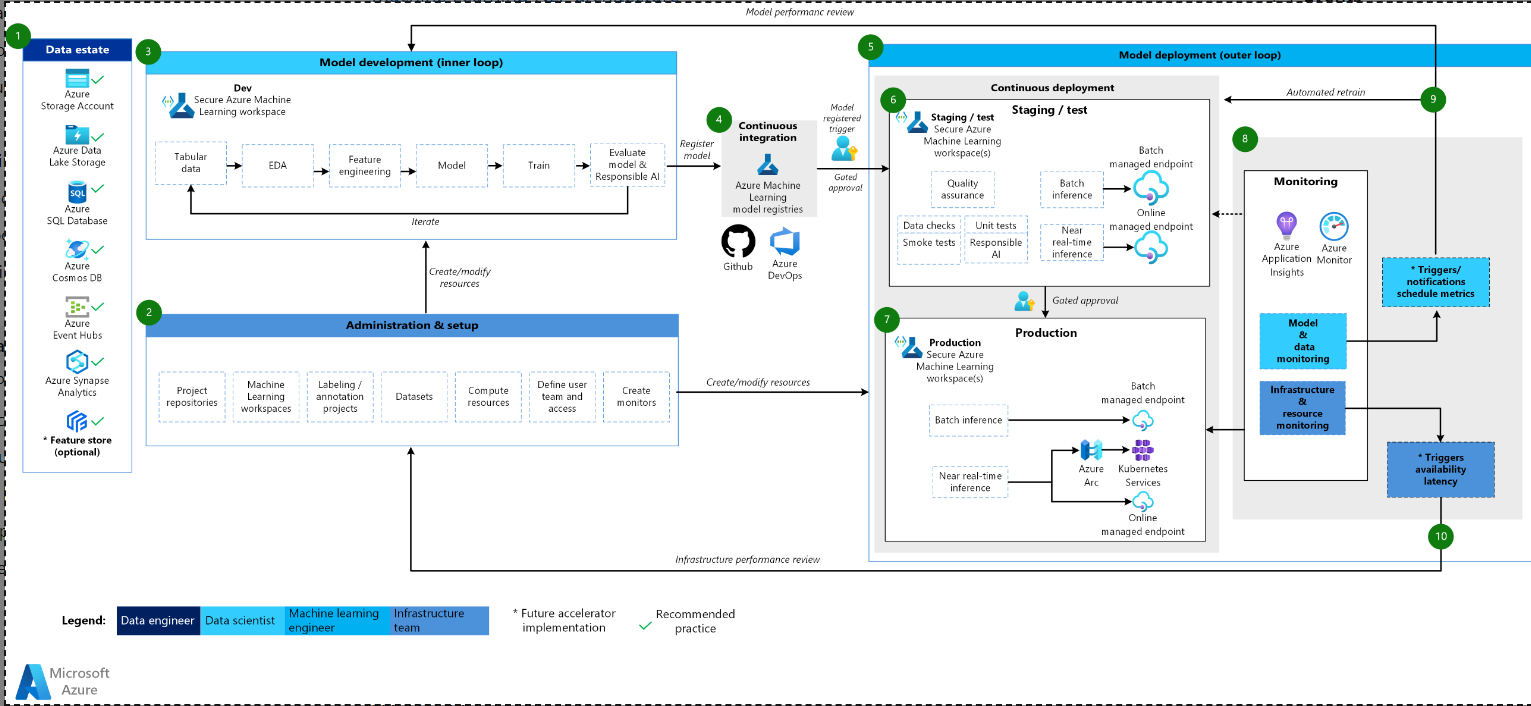
经典机器学习架构的示意图。
下载此体系结构的Visio文件。
经典机器学习架构的工作流
数据属性
此元素说明了组织的数据属性,以及数据科学项目的潜在数据源和目标。数据工程师是MLOps v2生命周期中这一元素的主要所有者。此图中的Azure数据平台既不是详尽的,也不是规定性的。代表基于客户用例的推荐最佳实践的数据源和目标由绿色复选标记表示。
管理和设置
此元素是MLOps v2加速器部署的第一步。它包括与创建和管理与项目相关的资源和角色相关的所有任务。这些任务可能包括以下任务,也可能包括其他任务:
- 创建项目源代码存储库
- 使用Bicep或Terraform创建机器学习工作空间
- 创建或修改用于模型开发和部署的数据集和计算资源
- 项目团队用户的定义、他们的角色以及对其他资源的访问控制
- 创建CI/CD管道
- 创建监控器,用于收集和通知模型和基础设施指标
与此阶段相关的主要角色是基础设施团队,但也可以有数据工程师、机器学习工程师和数据科学家。
模型开发(内环)
内部循环元素由迭代数据科学工作流组成,该工作流在专用、安全的机器学习工作区内运行。一个典型的工作流程如图所示。它从数据获取、探索性数据分析、实验、模型开发和评估,到生产候选模型的注册。MLOps v2加速器中实现的这个模块化元素是不可知的,适用于数据科学团队用于开发模型的过程。
与这一阶段相关的人物包括数据科学家和机器学习工程师。
机器学习注册表
在数据科学团队开发出一个可用于部署到生产中的模型后,该模型可以在机器学习工作空间注册表中注册。通过模型注册或封闭式人工在环审批自动触发的CI管道将模型和任何其他模型依赖关系提升到模型部署阶段。
与这个阶段相关的人物通常是机器学习工程师。
模型部署(外循环)
模型部署或外循环阶段包括预生产阶段和测试、生产部署以及对模型、数据和基础设施的监控。CD管道通过生产、监控和潜在的再培训来管理模型和相关资产的推广,只要满足适合您的组织和用例的标准。
与这一阶段相关的人物主要是机器学习工程师。
阶段和测试
阶段和测试阶段可能因客户实践而异,但通常包括对生产数据的候选模型进行再培训和测试、端点性能的测试部署、数据质量检查、单元测试以及对模型和数据偏差的负责任人工智能检查等操作。此阶段在一个或多个专用的、安全的机器学习工作区中进行。
生产部署
在模型通过阶段和测试阶段后,可以通过使用人工循环门控审批将其提升到生产阶段。模型部署选项包括用于批处理场景的托管批处理端点,或者对于在线、接近实时的场景,包括托管在线端点或使用Azure Arc进行的Kubernetes部署。生产通常在一个或多个专用、安全的机器学习工作区中进行。
监控
通过在阶段、测试和生产中进行监控,您可以收集模型、数据和基础架构性能变化的指标并对其采取行动。模型和数据监控可以包括检查模型和数据漂移、新数据的模型性能以及负责任的人工智能问题。基础设施监控可以监视端点响应缓慢、计算容量不足或网络问题。
数据和模型监控:事件和操作
基于模型和数据问题的标准,如度量阈值或时间表,自动触发器和通知可以实施适当的操作。这可以定期安排在较新的生产数据上对模型进行自动再培训,并返回到阶段和测试,以进行生产前评估。或者,这可能是由于模型或数据问题的触发因素,需要返回到模型开发阶段,数据科学家可以在该阶段进行调查并可能开发新的模型。
基础设施监测:事件和行动
基于基础设施问题的标准,如端点响应滞后或部署计算不足,自动触发器和通知可以实现适当的操作。它们触发了到设置和管理阶段的环回,在该阶段,基础设施团队可以调查并可能重新配置计算和网络资源。
机器学习CV架构
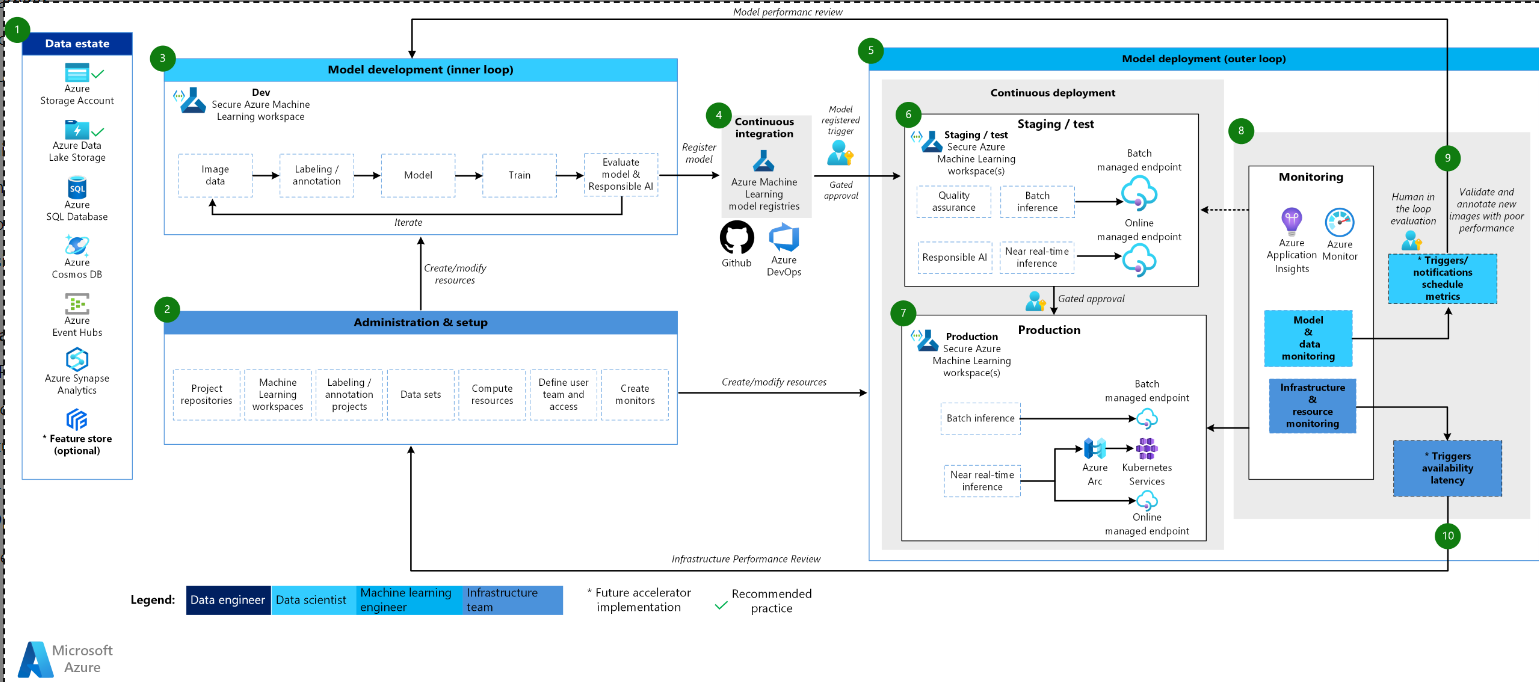
计算机视觉体系结构图。
下载此体系结构的Visio文件。
CV体系结构的工作流
机器学习CV架构基于经典的机器学习架构,但它有针对监督CV场景的修改。
数据属性
此元素说明了组织的数据属性以及数据科学项目的潜在数据源和目标。数据工程师是MLOps v2生命周期中这一元素的主要所有者。此图中的Azure数据平台既不是详尽的,也不是规定性的。CV场景的图像可以来自许多不同的数据源。为了提高使用机器学习开发和部署CV模型的效率,建议使用Azure Blob Storage和Azure data Lake Storage作为图像的Azure数据源。
管理和设置
此元素是MLOps v2加速器部署的第一步。它包括与创建和管理与项目相关的资源和角色相关的所有任务。对于CV场景,MLOps v2环境的管理和设置与经典机器学习基本相同,但有一个额外的步骤:使用机器学习的标记功能或其他工具创建图像标记和注释项目。
模型开发(内环)
内环元素由在专用、安全的机器学习工作空间内执行的迭代数据科学工作流组成。该工作流程与经典机器学习场景的主要区别在于,图像标记和注释是该开发循环的关键元素。
机器学习注册表
在数据科学团队开发出一个可用于部署到生产中的模型后,该模型可以在机器学习工作空间注册表中注册。由模型注册自动触发或由封闭式人工在环审批自动触发的CI管道将模型和任何其他模型依赖关系提升到模型部署阶段。
模型部署(外循环)
模型部署或外循环阶段包括预生产阶段和测试、生产部署以及对模型、数据和基础设施的监控。CD管道通过生产、监控和潜在的再培训来管理模型和相关资产的推广,前提是满足适合您的组织和用例的标准。
分段和测试
阶段和测试阶段可能因客户实践而异,但通常包括端点性能的测试部署、数据质量检查、单元测试以及模型和数据偏差的负责任人工智能检查等操作。对于CV场景,由于资源和时间限制,可以省略对生产数据上的候选模型的再训练。相反,数据科学团队可以使用生产数据进行模型开发,从开发循环中注册的候选模型就是为生产评估的模型。此阶段在一个或多个专用的、安全的机器学习工作区中进行。
生产部署
模型通过阶段和测试阶段后,可以通过人工在环门控审批将其推广到生产中。模型部署选项包括用于批处理场景的托管批处理端点,或者对于在线、接近实时的场景,包括托管在线端点或使用Azure Arc进行的Kubernetes部署。生产通常在一个或多个专用、安全的机器学习工作区中进行。
监控
通过在阶段、测试和生产中进行监控,您可以收集模型、数据和基础架构性能变化的指标并对其采取行动。模型和数据监视可以包括检查新图像上的模型性能。基础设施监控可以监视端点响应缓慢、计算容量不足或网络问题。
数据和模型监控:事件和操作
NLP的MLOps的数据和模型监控以及事件和动作阶段是与经典机器学习的关键区别。当检测到新图像上的模型性能下降时,通常不会在CV场景中进行自动再训练。在这种情况下,模型表现不佳的新图像必须由人工在循环过程中进行审查和注释,并且通常下一个动作会返回到模型开发循环,以便用新图像更新模型。
基础设施监测:事件和行动
基于基础设施问题的标准,如端点响应滞后或部署计算不足,自动触发器和通知可以实现适当的操作。这会触发到设置和管理阶段的环回,在该阶段,基础设施团队可以调查并可能重新配置环境、计算和网络资源。
机器学习NLP架构
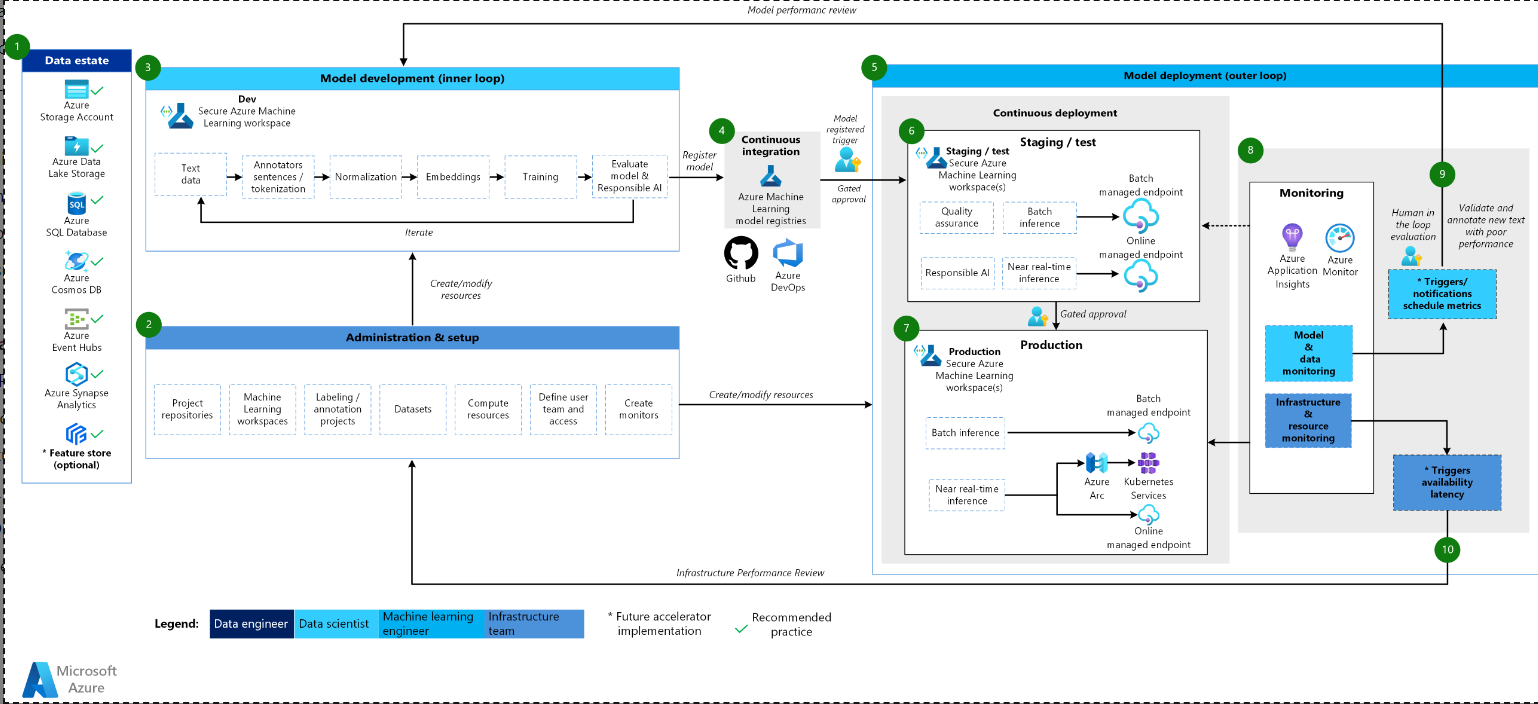
NLP体系结构图。
下载此体系结构的Visio文件。
NLP体系结构的工作流
机器学习NLP架构基于经典的机器学习架构,但它有一些针对NLP场景的修改。
数据属性
此元素说明了组织数据属性以及数据科学项目的潜在数据源和目标。数据工程师是MLOps v2生命周期中这一元素的主要所有者。此图中的Azure数据平台既不是详尽的,也不是规定性的。代表基于客户用例的推荐最佳实践的数据源和目标由绿色复选标记表示。
管理和设置
此元素是MLOps v2加速器部署的第一步。它包括与创建和管理与项目相关的资源和角色相关的所有任务。对于NLP场景,MLOps v2环境的管理和设置与经典机器学习基本相同,但有一个额外的步骤:通过使用机器学习的标记功能或其他工具创建图像标记和注释项目。
模型开发(内环)
内环元素由在专用、安全的机器学习工作空间内执行的迭代数据科学工作流组成。典型的NLP模型开发循环可能与经典的机器学习场景有很大不同,因为句子的注释器和文本数据的标记化、规范化和嵌入是该场景的典型开发步骤。
机器学习注册表
在数据科学团队开发出一个可用于部署到生产中的模型后,该模型可以在机器学习工作空间注册表中注册。由模型注册自动触发或由封闭式人工在环审批自动触发的CI管道将模型和任何其他模型依赖关系提升到模型部署阶段。
模型部署(外循环)
模型部署或外循环阶段包括预生产阶段和测试、生产部署以及对模型、数据和基础设施的监控。CD管道通过生产、监控和潜在的再培训来管理模型和相关资产的推广,以满足您的组织和用例的标准。
分段和测试
阶段和测试阶段可能因客户实践而异,但通常包括对生产数据的候选模型进行再培训和测试、端点性能的测试部署、数据质量检查、单元测试以及对模型和数据偏差的负责任人工智能检查等操作。此阶段在一个或多个专用的、安全的机器学习工作区中进行。
生产部署
在一个模型通过阶段和测试阶段后,它可以由人工在环门控审批提升到生产阶段。模型部署选项包括用于批处理场景的托管批处理端点,或者对于在线、接近实时的场景,包括托管在线端点或使用Azure Arc进行的Kubernetes部署。生产通常在一个或多个专用、安全的机器学习工作区中进行。
监控
通过在阶段、测试和生产中进行监控,您可以收集模型、数据和基础架构的性能变化并对其采取行动。模型和数据监控可以包括检查模型和数据漂移、新文本数据的模型性能以及负责任的人工智能问题。基础设施监控可以监视诸如端点响应缓慢、计算容量不足和网络问题等问题。
数据和模型监控:事件和操作
与CV架构一样,NLP的MLOps的数据和模型监控以及事件和动作阶段是与经典机器学习的关键区别。当检测到新文本的模型性能下降时,在NLP场景中通常不会进行自动再训练。在这种情况下,模型表现不佳的新文本数据必须由人工在循环过程进行审查和注释。通常下一个操作是返回到模型开发循环,用新的文本数据更新模型。
基础设施监测:事件和行动
基于基础设施问题的标准,如端点响应滞后或部署计算不足,自动触发器和通知可以实现适当的操作。它们触发了到设置和管理阶段的环回,在该阶段,基础设施团队可以调查并可能重新配置计算和网络资源。
组件
- 机器学习:用于大规模训练、评分、部署和管理机器学习模型的云服务。
- Azure管道:此构建和测试系统基于Azure DevOps,用于构建和发布管道。Azure管道将这些管道拆分为称为任务的逻辑步骤。
- GitHub:一个用于版本控制、协作和CI/CD工作流的代码托管平台。
- Azure Arc:通过使用Azure资源管理器管理Azure和内部部署资源的平台。这些资源可以包括虚拟机、Kubernetes集群和数据库。
- Kubernetes:一个用于自动化容器化应用程序的部署、扩展和管理的开源系统。
- Azure Data Lake:一个Hadoop兼容的文件系统。它具有集成的分层命名空间以及Blob存储的巨大规模和经济性。
- Azure Synapse Analytics:一种无限的分析服务,将数据集成、企业数据仓库和大数据分析结合在一起。
- Azure事件中心。一种接收客户端应用程序生成的数据流的服务。然后,它接收并存储流数据,保留接收到的事件序列。消费者可以连接到集线器端点以检索消息进行处理。在这里,我们正在利用与Data Lake Storage的集成。
贡献者
本文由Microsoft维护。它最初是由以下贡献者撰写的。
主要作者:
- Scott Donohoo |高级云解决方案架构师
- Moritz Steller |高级云解决方案架构师
接下来的步骤
- What is Azure Pipelines?
- Azure Arc overview
- What is Azure Machine Learning?
- Data in Azure Machine Learning
- Azure MLOps (v2) solution accelerator
- End-to-end machine learning operations (MLOps) with Azure Machine Learning
- Introduction to Azure Data Lake Storage Gen2
- Azure DevOps documentation
- GitHub Docs
- Azure Synapse Analytics documentation
- Azure Event Hubs documentation
相关资源
- Choose a Microsoft Azure AI services technology
- Natural language processing technology
- Compare the machine learning products and technologies from Microsoft
- How Azure Machine Learning works: resources and assets (v2)
- What are Azure Machine Learning pipelines?
- Machine learning operations (MLOps) framework to upscale machine learning lifecycle with Azure Machine Learning
- What is the Team Data Science Process?
- 登录 发表评论
- 56 次浏览
最新内容
- 1 day 6 hours ago
- 2 weeks ago
- 3 weeks 1 day ago
- 3 weeks 5 days ago
- 2 months 1 week ago
- 6 months 1 week ago
- 6 months 1 week ago
- 6 months 1 week ago
- 6 months 1 week ago
- 6 months 1 week ago