
category
检索增强生成(RAG)是一种架构方法,可以通过利用自定义数据来提高大型语言模型(LLM)应用程序的效率。这是通过检索与问题或任务相关的数据/文档并将其作为LLM的上下文来完成的。RAG在支持需要维护最新信息或访问特定领域知识的聊天机器人和问答系统方面取得了成功。
检索增强生成方法解决了哪些挑战?
问题1:LLM模型不知道您的数据
LLM使用深度学习模型,并在海量数据集上进行训练,以理解、总结和生成新颖的内容。大多数LLM都是在广泛的公共数据上进行训练的,因此一个模型可以响应多种类型的任务或问题。一旦经过训练,许多LLM就无法访问超出其训练数据截止点的数据。这使得LLM是静态的,可能会导致他们在被问及有关未经训练的数据的问题时做出错误的回答、给出过时的答案或产生幻觉。
问题2:人工智能应用程序必须利用自定义数据才能有效
为了让LLM给出相关和具体的回应,组织需要模型来理解他们的领域,并从他们的数据中提供答案,而不是给出广泛和概括的回应。例如,组织使用LLM构建客户支持机器人,这些解决方案必须为客户问题提供特定于公司的答案。其他人正在构建内部问答机器人,回答员工关于内部人力资源数据的问题。公司如何在不重新培训这些模型的情况下构建此类解决方案?
解决方案:检索增强现在已成为行业标准
使用自己的数据的一种简单而流行的方法是将其作为查询LLM模型的提示的一部分提供。这被称为检索增强生成(RAG),因为您将检索相关数据并将其用作LLM的增强上下文。RAG工作流提取相关信息,并将静态LLM与实时数据检索联系起来,而不是仅仅依赖于从训练数据中获得的知识。
使用RAG体系结构,组织可以部署任何LLM模型,并通过向其提供少量数据来对其进行扩充,从而为其组织返回相关结果,而无需对模型进行微调或预训练的成本和时间。
RAG的用例是什么?
RAG有许多不同的用例。最常见的有:
- 问答聊天机器人:将LLM与聊天机器人相结合,可以自动从公司文档和知识库中获得更准确的答案。聊天机器人用于自动化客户支持和网站领导跟进,以快速回答问题和解决问题。
- 搜索增强:将LLM与搜索引擎相结合,用LLM生成的答案来增强搜索结果,可以更好地回答信息查询,并使用户更容易找到工作所需的信息。
- 知识引擎——就您的数据(例如,人力资源、合规文档)提出问题:公司数据可以用作LLM的上下文,并允许员工轻松获得问题的答案,包括与福利和政策相关的人力资源问题以及安全和合规问题。
RAG的好处是什么?
RAG方法具有许多关键优点,包括:
- 提供最新和准确的响应:RAG确保LLM的响应不仅仅基于静态、陈旧的训练数据。相反,该模型使用最新的外部数据源来提供响应。
- 减少不准确的反应或幻觉:通过将LLM模型的输出建立在相关的外部知识基础上,RAG试图降低用不正确或捏造的信息(也称为幻觉)做出反应的风险。输出可以包括对原始来源的引用,允许人工验证。
- 提供特定领域的相关响应:使用RAG,LLM将能够根据组织的专有或特定领域的数据提供上下文相关的响应。
- 高效且经济高效:与其他使用特定领域数据定制LLM的方法相比,RAG简单且经济高效。组织可以部署RAG,而无需自定义模型。当模型需要使用新数据频繁更新时,这尤其有益。
我什么时候应该使用RAG,什么时候应该微调模型?
RAG是一个正确的起点,对于某些用例来说,它很容易而且可能完全足够。微调在不同的情况下最合适,当人们希望LLM的行为发生变化,或者学习不同的“语言”时。这两者并不相互排斥。作为未来的一步,可以考虑微调模型,以更好地理解领域语言和所需的输出形式,还可以使用RAG来提高响应的质量和相关性。
当我想用数据自定义LLM时,所有的选项都是什么,哪种方法是最好的(即时工程与RAG、微调与预训练)?
使用组织的数据自定义LLM应用程序时,需要考虑四种体系结构模式。这些技术概述如下,并不相互排斥。相反,它们可以(也应该)结合起来,以利用各自的优势。
| Method | Definition | Primary use case | Data requirements | Advantages | Considerations |
|---|---|---|---|---|---|
|
Prompt engineering |
Crafting specialized prompts to guide LLM behavior | Quick, on-the-fly model guidance | None | Fast, cost-effective, no training required | Less control than fine-tuning |
|
Retrieval augmented generation (RAG) |
Combining an LLM with external knowledge retrieval | Dynamic datasets and external knowledge | External knowledge base or database (e.g., vector database) | Dynamically updated context, enhanced accuracy | Increases prompt length and inference computation |
|
Fine-tuning |
Adapting a pretrained LLM to specific datasets or domains | Domain or task specialization | Thousands of domain-specific or instruction examples | Granular control, high specialization | Requires labeled data, computational cost |
|
Pretraining |
Training an LLM from scratch | Unique tasks or domain-specific corpora | Large datasets (billions to trillions of tokens) | Maximum control, tailored for specific needs | Extremely resource-intensive |

无论选择哪种技术,以结构良好、模块化的方式构建解决方案都能确保组织做好迭代和适应的准备。在《MLOps大书》中了解更多关于这种方法的信息。

什么是RAG应用程序的参考体系结构?
根据特定的需求和数据的细微差别,有很多方法可以实现检索增强生成系统。以下是一个常用的工作流,用于提供对流程的基本理解。
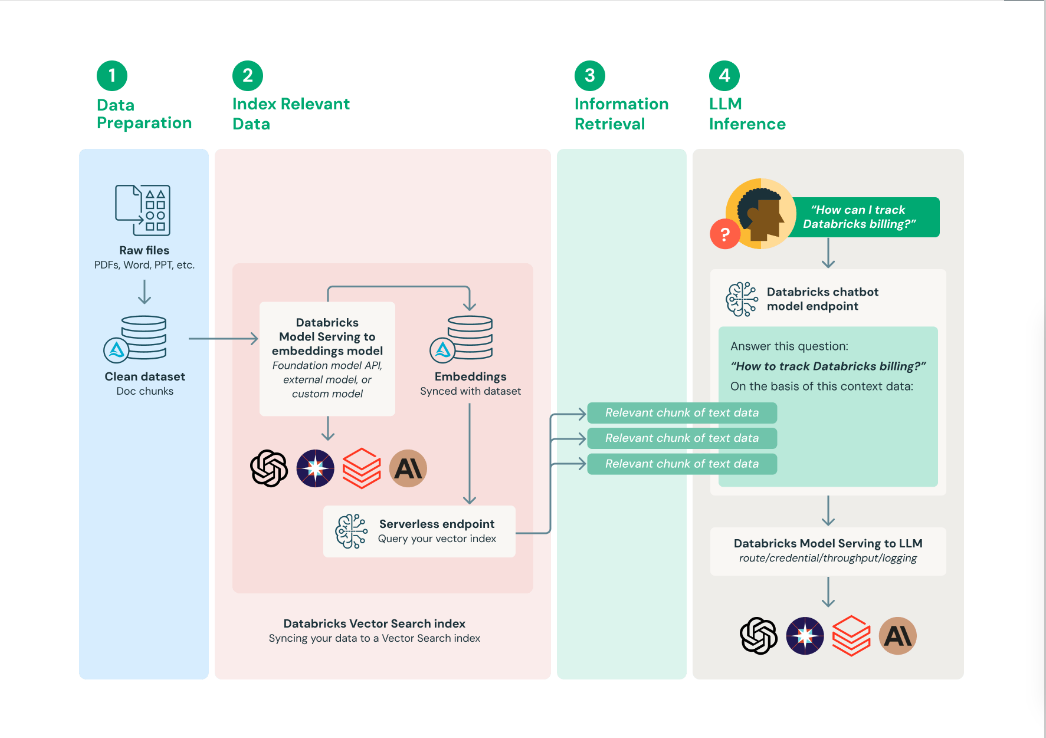
- 准备数据:文档数据与元数据一起收集,并进行初始预处理——例如,PII处理(检测、过滤、编辑、替换)。要在RAG应用程序中使用,需要根据嵌入模型和使用这些文档作为上下文的下游LLM应用程序的选择,将文档分块为适当的长度。
- 索引相关数据:生成文档嵌入并使用这些数据生成矢量搜索索引。
- 检索相关数据:检索与用户查询相关的部分数据。然后提供该文本数据作为LLM所使用的提示的一部分。
构建LLM应用程序:将提示增强的组件打包,并将LLM查询到端点中。然后可以通过简单的REST API将该端点暴露给问答聊天机器人等应用程序。
Databricks还推荐了RAG体系结构的一些关键体系结构元素:
- 矢量数据库:一些(但不是全部)LLM应用程序使用矢量数据库进行快速相似性搜索,最常见的是在LLM查询中提供上下文或领域知识。为了确保部署的语言模型能够访问最新信息,可以将定期矢量数据库更新安排为作业。请注意,可以使用MLflow LangChain或PyFunc模型风格将从矢量数据库检索并将信息注入LLM上下文的逻辑打包在记录到MLflow的模型工件中。
- MLflow LLM部署或模型服务:在使用第三方LLM API的基于LLM的应用程序中,对外部模型的MLflow LLM部署和模型服务支持可以用作标准化接口,以路由来自OpenAI和Anthropic等供应商的请求。除了提供企业级API网关外,MLflow LLM部署或模型服务还集中了API密钥管理,并提供了实施成本控制的能力。
- 模型服务:在RAG使用第三方API的情况下,一个关键的架构变化是LLM管道将进行外部API调用,从模型服务端点到内部或第三方LLM API。需要注意的是,这增加了复杂性、潜在的延迟和另一层凭据管理。相比之下,在微调的模型示例中,将部署模型及其模型环境。
资源
Databricks blog posts
- Using MLflow AI Gateway and Llama 2 to Build Generative AI Apps
- Best Practices for LLM Evaluation of RAG Applications
- Databricks Demo
- Databricks eBook — The Big Book of MLOps
在哪里可以找到有关检索增强生成的更多信息?
有许多资源可用于查找有关RAG的更多信息,包括:
Blogs
- Creating High-Quality RAG Applications With Databricks
- Databricks Vector Search Public Preview
- Improve RAG Application Response Quality With Real-Time Structured Data
- Build Gen AI Apps Faster With New Foundation Model Capabilities
- Best Practices for LLM Evaluation of RAG Applications
- Using MLflow AI Gateway and Llama 2 to Build Generative AI Apps (Achieve greater accuracy using retrieval augmented generation (RAG) with your own data)
E-books
Demos
- 登录 发表评论
- 171 次浏览
最新内容
- 1 week 5 days ago
- 2 weeks 6 days ago
- 3 weeks 3 days ago
- 2 months 1 week ago
- 6 months ago
- 6 months ago
- 6 months ago
- 6 months ago
- 6 months ago
- 6 months ago