
Chinese, Simplified
数据挖掘是指从已经收集的数据中检测和提取新的模式。数据挖掘是统计学和计算机科学领域的融合,旨在发现超大数据集中的模式,然后将其转换为可理解的结构以供日后使用。
数据挖掘的体系结构:
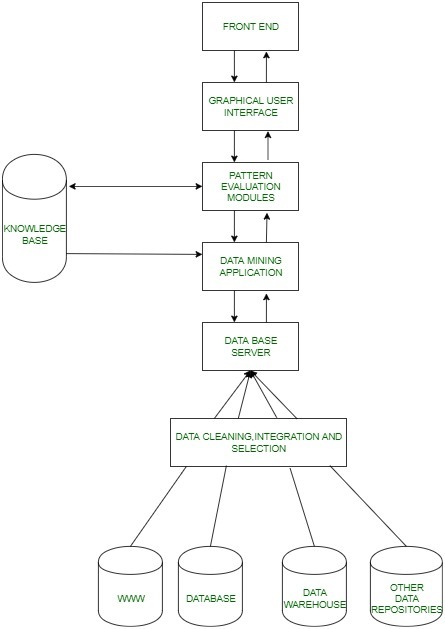
基本工作:
- 这一切都始于用户提出某些数据挖掘请求,然后这些请求被发送到数据挖掘引擎进行模式评估。
- 这些应用程序试图使用已存在的数据库来查找查询的解决方案。
- 然后提取的元数据被发送到数据挖掘引擎以进行适当的分析,数据挖掘引擎有时与模式评估模块交互以确定结果。
- 然后,使用合适的接口以易于理解的方式将该结果发送到前端。
数据挖掘架构各部分的详细描述如下:
- 数据源:数据库、万维网(WWW)和数据仓库是数据源的组成部分。这些来源中的数据可以是纯文本、电子表格或其他形式的媒体,如照片或视频。WWW是最大的数据来源之一。
- 数据库服务器:数据库服务器包含准备处理的实际数据。它根据用户的请求执行处理数据检索的任务。
- 数据挖掘引擎:它是数据挖掘架构的核心组件之一,可以执行各种数据挖掘技术,如关联、分类、特征化、聚类、预测等。
- 模式评估模块:他们负责在数据中找到有趣的模式,有时他们还与数据库服务器交互,以产生用户请求的结果。
- 图形用户界面:由于用户无法完全理解数据挖掘过程的复杂性,因此图形用户界面有助于用户与数据挖掘系统进行有效沟通。
- 知识库:知识库是数据挖掘引擎的重要组成部分,在指导搜索结果模式方面非常有益。数据挖掘引擎有时也可以从知识库中获取输入。该知识库可以包含来自用户体验的数据。知识库的目的是使结果更加准确和可靠。
数据挖掘体系结构的类型:
- 无耦合:无耦合数据挖掘体系结构从特定数据源检索数据。它不使用数据库来检索数据,否则这是一种非常有效和准确的方法。数据挖掘的无耦合架构很差,仅用于执行非常简单的数据挖掘过程。
- 松散耦合:在松散耦合体系结构中,数据挖掘系统从数据库中检索数据并将数据存储在这些系统中。此挖掘适用于基于内存的数据挖掘体系结构。
- 半紧密耦合:它倾向于使用数据仓库系统的各种有利特性。它包括排序、索引和聚合。在这种体系结构中,可以将中间结果存储在数据库中以获得更好的性能。
- 紧密耦合:在该体系结构中,数据仓库被认为是其最重要的组件之一,其功能用于执行数据挖掘任务。此体系结构提供了可扩展性、性能和集成信息
数据挖掘的优势:
- 通过准确预测未来趋势,帮助预防未来的对手。
- 有助于做出重要决策。
- 将数据压缩为有价值的信息。
- 提供新的趋势和意想不到的模式。
- 帮助分析庞大的数据集。
- 帮助公司寻找、吸引和留住客户。
- 帮助公司改善与客户的关系。
- 协助公司根据某一产品的喜爱程度优化生产,从而为公司节省成本。
数据挖掘的缺点:
- 过度的工作强度需要高绩效的团队和员工培训。
- 大量投资的需求也可能被认为是一个问题,因为有时数据收集会消耗许多资源,而这些资源的成本很高。
- 缺乏安全性也可能使数据面临巨大风险,因为数据可能包含私人客户详细信息。
- 不准确的数据可能导致错误的输出。
- 庞大的数据库很难管理。
发布日期
星期六, 八月 5, 2023 - 21:28
最后修改
星期六, 八月 5, 2023 - 21:34
Article
最新内容
- 1 day 23 hours ago
- 2 weeks 1 day ago
- 3 weeks 2 days ago
- 3 weeks 6 days ago
- 2 months 2 weeks ago
- 6 months 1 week ago
- 6 months 1 week ago
- 6 months 1 week ago
- 6 months 1 week ago
- 6 months 1 week ago