
实现多租户的最佳方法取决于SaaS应用程序的需求。以下部分演示了在PostgreSQL中成功实现多租户的分区模型。
笔记
本节讨论的模型适用于Amazon RDS for PostgreSQL和Aurora PostgreSQL Compatible。本节中对PostgreSQL的引用适用于这两种服务。
PostgreSQL中有三种高级模型可用于SaaS分区:简仓、网桥和池。下图总结了简仓和池模型之间的权衡。桥梁模型是筒仓和水池模型的混合。
| 分区模型 | 优势 | 缺点 |
|---|---|---|
| Silo |
|
|
| Pool |
|
|
| Bridge |
|
|
The following sections discuss each model in more detail.
Partitioning models:
PostgreSQL 简仓模型
筒仓模型是通过为应用程序中的每个租户提供PostgreSQL实例来实现的。筒仓模型擅长租户性能和安全隔离,并完全消除了噪音邻居现象。当一个租户对系统的使用影响到另一个租户的性能时,就会出现噪声邻居现象。思洛存储器模型允许您专门为每个租户定制性能,并可能限制特定租户思洛存储器的中断。然而,通常推动筒仓模型采用的是严格的安全和监管约束。SaaS客户可以激发这些约束。例如,SaaS客户可能会因为内部限制而要求隔离他们的数据,SaaS提供商可能会额外收费提供此类服务。
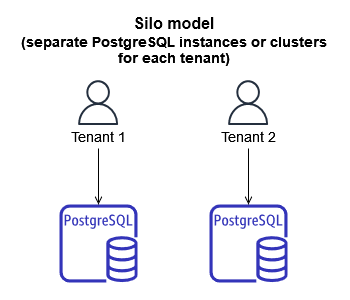
尽管筒仓模型在某些情况下可能是必要的,但它有许多缺点。通常很难以经济高效的方式使用思洛存储器模型,因为跨多个PostgreSQL实例管理资源消耗可能很复杂。此外,该模型中数据库工作负载的分布式特性使得维护租户活动的集中视图变得更加困难。管理如此多独立操作的工作负载会增加操作和管理开销。筒仓模型还使租户注册变得更加复杂和耗时,因为您必须提供特定于租户的资源。此外,整个SaaS系统可能更难扩展,因为不断增加的租户特定PostgreSQL实例将需要更多的操作时间来管理。最后一个考虑是,应用程序或数据访问层必须维护租户到其关联PostgreSQL实例的映射,这增加了实现该模型的复杂性。
PostgreSQL池模型
池模型是通过提供单个PostgreSQL实例(Amazon RDS或Aurora)并使用行级安全性(RLS)来维护租户数据隔离来实现的。RLS策略限制SELECT查询返回表中的哪些行,或INSERT、UPDATE和DELETE命令影响哪些行。池模型将所有租户数据集中在一个PostgreSQL模式中,因此它更具成本效益,维护所需的操作开销也更少。由于其集中化,监控此解决方案也明显更简单。然而,在池模型中监视租户特定的影响通常需要在应用程序中使用一些附加的工具。这是因为PostgreSQL默认情况下不知道哪个租户正在消耗资源。由于不需要新的基础设施,因此简化了租户注册。这种灵活性使实现快速、自动化的租户入职工作流变得更加容易。
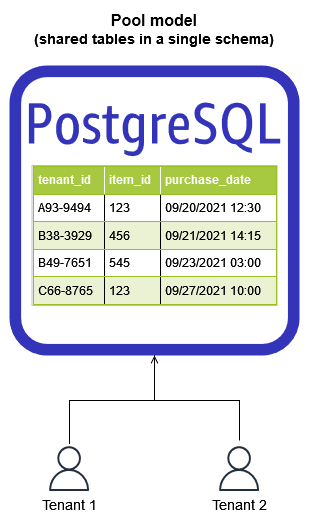
尽管池模型通常更具成本效益且更易于管理,但它确实存在一些缺点。在池模型中,噪声邻居现象不能完全消除。然而,可以通过确保PostgreSQL实例上有适当的资源以及使用减少PostgreSQL中负载的策略(例如将查询卸载到读取副本或AmazonElastiCache)来减轻这种情况。有效的监控在响应租户性能隔离问题方面也发挥着作用,因为应用程序检测可以记录和监控租户特定的活动。最后,一些SaaS客户可能觉得RLS提供的逻辑分离不够,可能会要求额外的隔离措施。
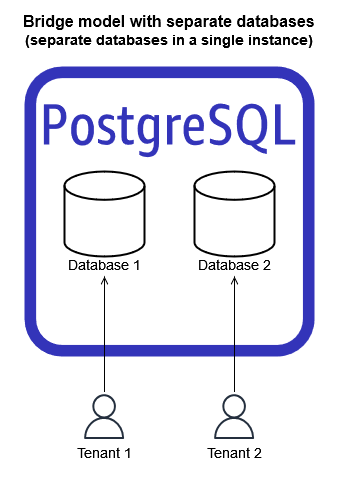
PostgreSQL桥模型
PostgreSQL桥模型是集合方法和孤立方法的组合。与池模型一样,您为每个租户提供一个PostgreSQL实例。为了维护租户数据隔离,您使用PostgreSQL逻辑结构。在下图中,PostgreSQL数据库用于逻辑分离数据。
笔记
PostgreSQL数据库不指单独的Amazon RDS for PostgreSQL或Aurora PostgreSQL Compatible DB实例。相反,它引用PostgreSQL数据库管理系统的逻辑结构来分离数据。
您还可以通过使用单个PostgreSQL数据库实现网桥模型,每个数据库中都有租户特定的模式,如下图所示。
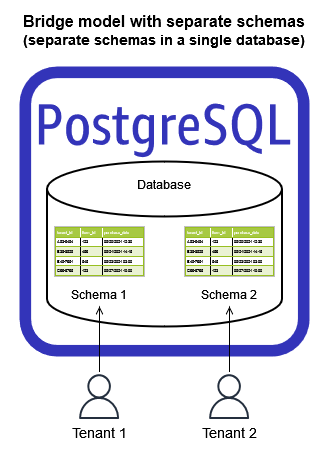
网桥模型与池模型一样受到邻居和租户性能隔离问题的困扰。它还需要在每个租户的基础上配置单独的数据库或模式,从而导致一些额外的操作和配置开销。它需要有效的监控,以快速响应租户的性能问题。它还需要应用程序检测来监视租户特定的使用情况。总体而言,网桥模型可以被视为RLS的替代方案,它通过需要新的PostgreSQL数据库或模式来略微增加租户的入职工作。与思洛存储器模型一样,应用程序或数据访问层必须维护租户到其关联PostgreSQL数据库或模式的映射。
决策矩阵
要决定应使用PostgreSQL的多租户SaaS分区模型,请参阅以下决策矩阵。该矩阵分析了这四个分区选项:
- 简仓–每个租户的单独PostgreSQL实例或集群。
- 桥与独立的数据库–单个PostgreSQL实例或集群中每个租户的独立数据库。
- 桥与独立的模式–单个PostgreSQL数据库、单个PostgreQL实例或集群中每个租户的独立模式。
- Pool–单个实例和模式中租户的共享表。
| 筒仓 | 具有独立数据库的桥 | 具有独立Schema的桥 | 池 | |
|---|---|---|---|---|
| 用例 | 隔离数据并完全控制资源使用是一项关键要求,或者您有非常大且对性能非常敏感的租户。 | 数据隔离是一项关键要求,租户数据的交叉引用是有限的或不需要的。 | 租户数量适中,数据量适中。如果必须交叉引用租户数据,这是首选模型。 | 大量租户,每个租户的数据较少。 |
| 新租户入职灵活性 | 非常慢。(每个租户都需要一个新的实例或集群。) | 适度缓慢。(需要为每个租户创建一个新数据库来存储架构对象。) | 适度缓慢。(需要为每个租户创建一个新的模式来存储对象。) | 最快的选项。(需要最少的设置。) |
| Database connection pool configuration effort and efficiency |
需要大量努力。(每个租户一个连接池。) 效率较低。(租户之间没有数据库连接共享。) |
需要大量努力。(每个租户一个连接池配置,除非您使用Amazon RDS Proxy。) 效率较低。(租户之间没有数据库连接共享和连接总数。基于DB实例类,所有租户之间的使用受到限制。) |
所需的工作量更少。(一个连接池配置适用于所有租户。) 效率适中。(仅在会话池模式下通过SET ROLE或SET SCHEMA命令重新使用连接。使用Amazon RDS Proxy时,SET命令也会导致会话锁定,但可以消除客户端连接池,并为每个请求建立直接连接以提高效率。) |
所需的工作量最少。 效率最高。(为所有租户提供一个连接池,并在所有租户之间高效地重用连接。数据库连接限制基于DB实例类。) |
| 数据库维护(真空管理)和资源使用 | 更简单的管理。 | 中等复杂性。(可能会导致高资源消耗,因为必须在vacuum_aptime之后为每个数据库启动一个真空工作程序,这会导致自动真空启动程序CPU的使用率很高。还可能会有额外的开销与为每个数据库清空PostgreSQL系统目录表相关。) | 大型PostgreSQL系统目录表。(pg_catalog的总大小为几十GB,取决于租户数量和关系。可能需要修改抽真空相关参数以控制表膨胀。) | 表可能很大,这取决于租户的数量和每个租户的数据。(可能需要修改抽真空相关参数以控制表膨胀。) |
| 扩展管理工作 | 巨大的努力(针对不同实例中的每个数据库)。 | 巨大的努力(在每个数据库级别)。 | 最小的工作量(在公共数据库中一次)。 | 最小的工作量(在公共数据库中一次)。 |
| 更改部署工作 | 重大努力。(连接到每个单独的实例并展开更改。) | 重大努力。(连接到每个数据库和schema,并展开更改。) | 适度努力。(连接到公共数据库,并对每个模式进行更改。) | 最小的努力。(连接到公共数据库并展开更改。) |
| 变更部署–影响范围 | 最小的(受影响的单个租户。) | 最小的(受影响的单个租户。) | 最小的(受影响的单个租户。) | Very large. (All tenants affected.) |
| 查询性能管理和工作 | 可管理的查询性能。 | 可管理的查询性能。 | 可管理的查询性能。 | 维护查询性能可能需要大量努力。(随着时间的推移,由于表的大小增加,查询可能运行得更慢。您可以使用表分区和数据库分片来保持性能。) |
| 跨租户资源影响 | 无影响。(租户之间没有资源共享。) | 中等影响。(租户共享公共资源,例如实例CPU和内存。) | 中等影响。(租户共享公共资源,例如实例CPU和内存。) | 严重冲击。(租户在资源、锁冲突等方面相互影响。) |
| 租户级别调整(例如,为每个租户创建额外索引或为特定租户调整DB参数) | 可能的 | 有些可能。(可以对每个租户进行架构级别的更改,但数据库参数在所有租户中都是全局的。) | 有些可能。(可以对每个租户进行架构级别的更改,但数据库参数在所有租户中都是全局的。) | 不可能。(所有租户共享表。) |
| 重新平衡对性能敏感的租户的工作 | 最小的(无需重新平衡。扩展服务器和I/O资源以处理此情况。) | 适度的(使用逻辑复制或pg_dump导出数据库,但停机时间可能会很长,这取决于数据大小。您可以使用Amazon RDS for PostgreSQL中的可移植数据库功能,以更快地在实例之间复制数据库。) | 中等程度,但可能需要较长的停机时间。(使用逻辑复制或pg_dump导出模式,但停机时间可能会很长,具体取决于数据大小。) |
重要,因为所有租户共享同一张桌子。(共享数据库需要将所有内容复制到另一个实例,以及清理租户数据的额外步骤。) 很可能需要更改应用程序逻辑。 |
| 主要版本升级的数据库停机 | 标准停机时间。(取决于PostgreSQL系统目录大小。) | 停机时间可能更长。(根据系统目录的大小,时间会有所不同。PostgreSQL系统目录表也会在数据库中复制) | 停机时间可能更长。(根据PostgreSQL系统目录大小,时间会有所不同。) | 标准停机时间。(取决于PostgreSQL系统目录大小。) |
| 管理开销(例如,用于数据库日志分析或备份作业监视) | 重大努力 | 最小的努力。 | 最小的努力。 | 最小的努力。 |
| 租户级别可用性 | 最高。(每个租户都会出现故障并独立恢复。) | 影响范围更大。(如果出现硬件或资源问题,所有租户都会失败并一起恢复。) | 影响范围更大。(如果出现硬件或资源问题,所有租户都会失败并一起恢复。) | 影响范围更大。(如果出现硬件或资源问题,所有租户都会失败并一起恢复。) |
| 租户级别的备份和恢复工作 | 最少的努力。(每个租户都可以独立备份和恢复。) | 适度努力。(对每个租户使用逻辑导出和导入。需要一些编码和自动化。) | 适度努力。(对每个租户使用逻辑导出和导入。需要一些编码和自动化。) | 重大努力。(所有租户共享同一张表。) |
| 租户级别的时间点恢复工作 | 最小的努力。(使用快照进行时间点恢复,或在Amazon Aurora中使用回溯。) | 适度努力。(使用快照还原,然后导出/导入。但是,这将是一个缓慢的操作。) | 适度努力。(使用快照还原,然后导出/导入。但是,这将是一个缓慢的操作。) | 巨大的努力和复杂性。 |
| 统一的schema 名称 | 每个租户的schema 名称相同。 | 每个租户的schema 名称相同。 | 每个租户的Schema不同。 | 公共Schema。 |
| 每个租户自定义(例如,特定租户的附加表列) | 可能的. | 可能的. | 可能的. | 复杂(因为所有租户共享同一张表). |
| 对象关系映射(ORM)层的目录管理效率(例如Ruby) | 高效(因为客户端连接特定于租户)。 | 高效(因为客户端连接特定于数据库)。 | 效率适中。(根据所使用的ORM、用户/角色安全模型和search_path配置,客户端有时会缓存所有租户的元数据,从而导致数据库连接内存使用率高。) | 高效(因为所有租户共享同一张桌子)。 |
| 整合租户报告工作 | 重大努力。(您必须使用外部数据包装器[FDWs]来合并所有租户中的数据,或者提取、转换和加载[ETL]到另一个报告数据库。) | 重大努力。(您必须使用FDW将所有租户或ETL中的数据合并到另一个报告数据库中。) | 适度努力。(可以使用联合来聚合所有模式中的数据。) | 最小的努力。(所有租户数据都在同一个表中,因此报告很简单。) |
| 用于报告的租户特定只读实例(例如,基于订阅) | 最少的努力。(创建读取副本。) | 适度努力。(您可以使用逻辑复制或AWS数据库迁移服务[AWS DMS]进行配置。) | (您可以使用逻辑复制或AWS DMS进行配置。) | 复杂(因为所有租户共享同一张桌子)。 |
| 数据隔离 | 最好的 | 较好的(您可以使用PostgreSQL角色管理数据库级权限。) | 较好的(您可以使用PostgreSQL角色来管理模式级权限。) | 更糟的(因为所有租户共享相同的表,所以必须实现行级安全[RLS]等功能以隔离租户。) |
| 租户特定的存储加密密钥 | 可能的(每个PostgreSQL集群都可以有自己的AWS密钥管理服务[AWS KMS]密钥用于存储加密) | 不可能。(所有租户共享相同的KMS密钥进行存储加密。) | 不可能。(所有租户共享相同的KMS密钥进行存储加密。) | 不可能。(所有租户共享相同的KMS密钥进行存储加密。) |
| 使用AWS身份和访问管理(IAM)对每个租户进行数据库身份验证 | 可能的 | 可能的 | 可能(通过为每个模式设置单独的PostgreSQL用户)。 | 不可能(因为所有租户共享表)。 |
| 基础设施成本 | 最高(因为没有共享)。 | 适度的 | 适度的 | 最低的。 |
| 数据复制和存储使用 | 所有租户的最高聚合。(PostgreSQL系统目录表和应用程序的静态和公共数据在所有租户之间重复。) | 所有租户的最高聚合。(PostgreSQL系统目录表和应用程序的静态和公共数据在所有租户之间重复。) | 适度的(应用程序的静态和公共数据可以在公共模式中,并由其他租户访问。) | 最小的(没有重复数据。应用程序的静态数据和公共数据可以位于同一架构中。) |
| 以租户为中心的监控(快速找出导致问题的租户) | 最少的努力。(因为每个租户都被单独监控,所以很容易检查特定租户的活动。) | 适度努力。(因为所有租户共享相同的物理资源,您必须应用额外的筛选来检查特定租户的活动。) | 适度努力。(因为所有租户共享相同的物理资源,您必须应用额外的筛选来检查特定租户的活动。) | 重大努力。(因为所有租户共享所有资源,包括表,所以必须使用绑定变量捕获来检查特定SQL查询属于哪个租户。) |
| 集中管理和健康/活动监测 | 重大努力(建立中央监控和中央指挥中心)。 | 适度努力(因为所有租户共享同一实例)。 | 适度努力(因为所有租户共享同一实例)。 | 最小的工作量(因为所有租户共享相同的资源,包括模式)。 |
| 对象标识符(OID)和事务ID(XID)包装的可能性 | 最小的. | 高的(因为OID,XID是一个PostgreSQL集群范围的计数器,所以在物理数据库之间进行有效的抽真空可能会出现问题)。 | 适度的(因为OID,XID是单个PostgreSQL集群范围计数器)。 | 高的(例如,一个表可以达到40亿的TOAST OID限制,这取决于行外列的数量。) |
Tags
最新内容
- 2 days 13 hours ago
- 1 week 3 days ago
- 2 weeks ago
- 2 months ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago