
category
解决方案思路
本文描述了一个解决方案的想法。您的云架构师可以使用此指南来帮助可视化此体系结构的典型实现的主要组件。将本文作为设计一个架构良好的解决方案的起点,该解决方案与您的工作负载的特定需求相一致。
本文提供了一个使用Azure Databricks的机器学习操作(MLOps)体系结构和流程。该过程定义了将机器学习模型和管道从开发转移到生产的标准化方式,包括自动化和手动过程。
架构
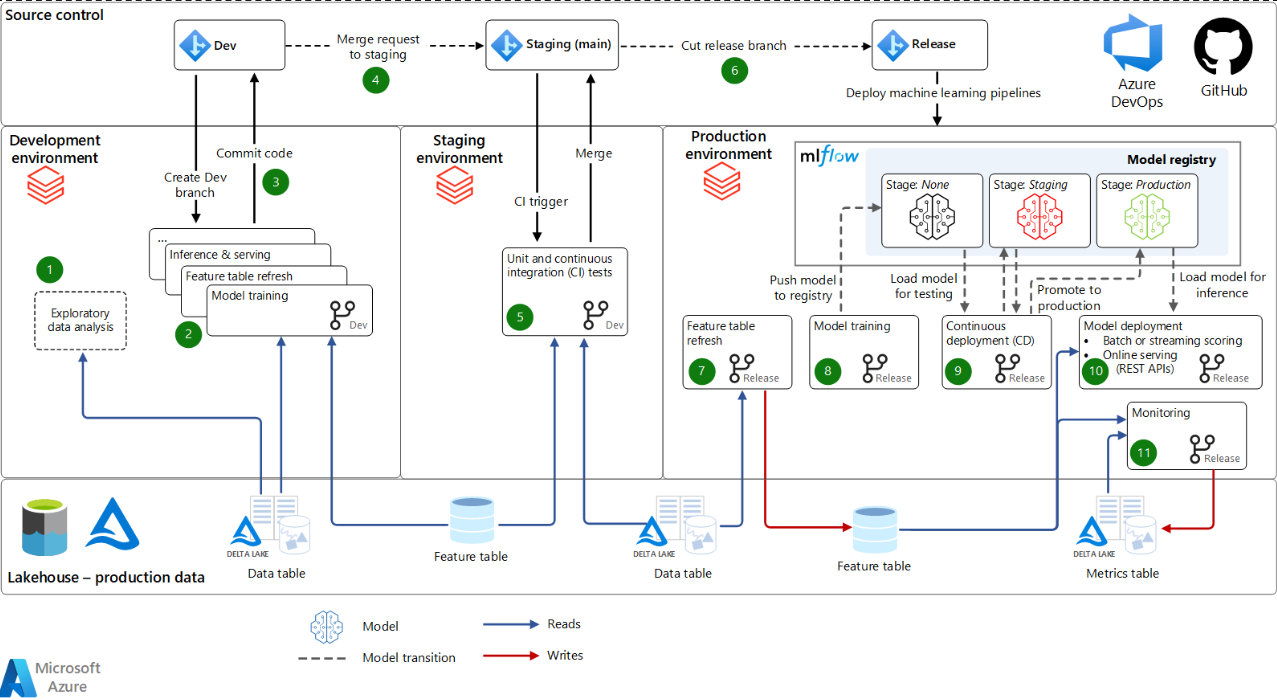
显示使用Azure Databricks进行MLOps的解决方案的图表。
下载此体系结构的Visio文件。
工作流
此解决方案提供了一个使用Azure Databricks的强大MLOps流程。体系结构中的所有元素都是可插入的,因此您可以根据需要在整个体系结构中集成其他Azure和第三方服务。该架构和描述改编自电子书《MLOps的大书》。这本电子书更详细地探讨了这里描述的体系结构。
- 源代码管理:该项目的代码存储库组织笔记本、模块和管道。数据科学家创建开发分支来测试更新和新模型。代码是在笔记本电脑或IDE中开发的,由Git支持,与Databricks Repos集成,用于与您的Azure数据砖工作区同步。源代码管理促进了从开发到阶段(用于测试)再到生产(用于部署)的机器学习管道。
- Lakehouse-生产数据:数据科学家在开发环境中工作,在那里他们可以只读访问生产数据。(或者,可以镜像或编辑数据。)他们还可以对开发存储环境进行读/写访问,用于开发和实验。我们建议数据采用Lakehouse架构,其中数据以Delta Lake格式存储在Azure data Lake Storage中。访问控制是用Microsoft Entra凭据传递或表访问控制定义的。
开发
在开发环境中,数据科学家和工程师开发机器学习管道。
- 探索性数据分析(EDA):数据科学家在交互式迭代过程中探索数据。此临时工作可能不会部署到暂存或生产中。工具可能包括Databricks SQL、dbutils.data.summarize和AutoML。
- 模型训练和其他机器学习管道:机器学习管道在笔记本电脑或IDE中作为模块化代码开发。例如,模型训练管道从Feature Store和其他Lakehouse表中读取数据。将日志模型参数和度量训练和调整到MLflow跟踪服务器。功能存储API记录最终模型。这些日志链接了模型、模型的输入和训练代码。
- 提交代码:为了将机器学习工作流程推向生产,数据科学家将用于验证、培训和其他管道的代码提交给源代码管理。
暂存
在阶段环境中,CI基础设施测试在模拟生产的环境中对机器学习管道的更改。
- 合并请求:当在源代码管理中针对项目的暂存(主)分支提交合并(或拉取)请求时,像Azure DevOps这样的连续集成和连续交付(CI/CD)工具会运行测试。
- 单元和CI测试:单元测试在CI基础设施中运行,集成测试在Azure Databricks上运行端到端工作流。如果测试通过,代码更改将合并。
- 构建发布分支:当机器学习工程师准备好将更新的机器学习管道部署到生产中时,他们可以构建新的发布。CI/CD工具中的部署管道将更新后的管道重新部署为新的工作流。
生产
机器学习工程师管理生产环境,机器学习管道直接为最终应用程序服务。生产中的关键管道刷新特征表,训练和部署新模型,运行推理或服务,并监控模型性能。
- 特征表刷新:此管道读取数据、计算要素并写入要素存储表。它在流模式下连续运行、按时间表运行或被触发。
- 模型训练:在生产中,触发或计划模型训练或再训练管道,以根据最新的生产数据训练新的模型。模型已注册到MLflow模型注册表中。
- 持续部署:注册新的模型版本会触发CD管道,该管道运行测试以确保模型在生产中表现良好。当模型通过测试时,通过模型阶段转换在模型注册表中跟踪其进度。注册表webhook可以用于自动化。测试可以包括合规性检查、将新模型与当前生产模型进行比较的A/B测试以及基础设施测试。测试结果和指标记录在Lakehouse表格中。在将模型转换为生产之前,您可以选择要求手动签署。
- 模型部署:当模型进入生产时,它被部署用于评分或服务。最常见的部署模式有:
- 批量或流式评分:对于几分钟或更长的延迟,批量和流式是最具成本效益的选择。评分管道从Feature Store读取最新数据,从model Registry加载最新的生产模型版本,并在Databricks作业中执行推理。它可以将预测发布到Lakehouse表、Java数据库连接(JDBC)连接、平面文件、消息队列或其他下游系统。
- 在线服务(RESTAPI):对于低延迟的用例,通常需要在线服务。MLflow可以将模型部署到Azure Databricks上的MLflow模型服务、云提供商服务系统和其他系统。在所有情况下,服务系统都使用模型注册表中的最新生产模型进行初始化。对于每个请求,它都会从在线功能存储中获取功能并进行预测。
- 监控:连续或定期的工作流程监控输入数据和漂移、性能和其他指标的模型预测。DeltaLiveTables可以简化监控管道的自动化,将指标存储在Lakehouse表中。Databricks SQL、Power BI和其他工具可以从这些表中读取数据,以创建仪表板和警报。
- 再培训:此体系结构支持手动和自动再培训。有计划的再培训工作是保持模特新鲜感的最简单方法。
组件
- Data Lakehouse。Lakehouse架构将数据湖和数据仓库的最佳元素统一起来,通过数据湖提供的低成本、灵活的对象存储提供数据仓库中常见的数据管理和性能。
- Delta Lake是湖屋开源数据格式的推荐选择。Azure Databricks将数据存储在data Lake Storage中,并提供高性能查询引擎。
- MLflow是一个用于管理端到端机器学习生命周期的开源项目。这些是它的主要组成部分:
- 跟踪【Tracking 】。允许您跟踪实验,以记录和比较参数、指标和模型工件。
- Databricks Autologging扩展了MLflow自动日志记录,以跟踪机器学习实验,自动记录模型参数、指标、文件和沿袭信息。
- MLflow模型允许您将任何机器学习库中的模型存储并部署到各种模型服务和推理平台。
- Model Registry提供了一个集中的模型存储,用于管理从开发到生产的模型生命周期阶段转换。
- Model Serving使您能够将MLflow模型作为REST端点承载。
- 跟踪【Tracking 】。允许您跟踪实验,以记录和比较参数、指标和模型工件。
- Azure Databricks。Azure Databricks提供了一种具有企业安全功能、高可用性以及与其他Azure Databricks工作区功能集成的托管MLflow服务。
- 用于机器学习的Databricks Runtime自动化了为机器学习优化的集群的创建,除了用于AutoML和Feature Store客户端等机器学习工具的Azure Databrickss外,还预装了TensorFlow、PyTorch和XGBoost等流行的机器学习库。
- Feature Store是一个集中的功能存储库。它实现了特征共享和发现,并有助于避免模型训练和推理之间的数据偏斜。
- Databricks SQL。Databricks SQL为Lakehouse数据上的SQL查询以及可视化、仪表板和警报提供了简单的体验。
- Databricks Repos在Azure Databrickss工作区中提供与Git提供商的集成,简化了笔记本电脑或代码的协同开发和IDE集成。
- 工作流和作业提供了一种在Azure Databricks集群中运行非交互式代码的方法。对于机器学习,作业提供了数据准备、特征化、训练、推理和监控的自动化。
选择
您可以根据Azure基础架构定制此解决方案。常见的自定义包括:
- 共享一个通用生产工作区的多个开发工作区。
- 正在为现有基础架构交换一个或多个体系结构组件。例如,您可以使用Azure数据工厂来编排Databricks作业。
- 通过Git和Azure Databricks REST API与现有的CI/CD工具集成。
场景详细信息
MLOps有助于降低机器学习和人工智能系统的故障风险,并提高协作和工具的效率。有关MLOps的介绍和该体系结构的概述,请参阅在Lakehouse上构建MLOps。
通过使用此体系结构,您可以:
- 将您的业务利益相关者与机器学习和数据科学团队联系起来。这种体系结构允许数据科学家使用笔记本电脑和IDE进行开发。它使业务利益相关者能够在Databricks SQL中查看指标和仪表板,所有这些都在同一个Lakehouse架构中。
- 使您的机器学习基础设施以数据为中心。该体系结构将机器学习数据(来自特征工程、训练、推理和监控的数据)与其他数据一样对待。它将工具重新用于生产流水线、仪表板和其他用于机器学习数据处理的通用数据处理。
- 在模块和管道中实现MLOps。与任何软件应用程序一样,该体系结构中的模块化管道和代码能够测试单个组件,并降低未来重构的成本。
- 根据需要自动化MLOps流程。在这个体系结构中,您可以自动化步骤以提高生产力并降低人为错误的风险,但并非每个步骤都需要自动化。除了用于自动化的API之外,Azure Databricks还允许UI和手动流程。
潜在用例
该架构适用于所有类型的机器学习、深度学习和高级分析。该架构中使用的常见机器学习/AI技术包括:
- 经典的机器学习,如线性模型、基于树的模型和boosting。
- 现代深度学习,如TensorFlow和PyTorch。
- 自定义分析,如统计学、贝叶斯方法和图形分析。
该架构同时支持小数据(单机)和大数据(分布式计算和GPU加速)。在体系结构的每个阶段,您都可以选择计算资源和库来适应您的数据和问题维度。
该体系结构适用于所有类型的行业和业务用例。使用此架构和类似架构的Azure Databricks客户包括以下行业的小型和大型组织:
- 消费品和零售服务
- 金融服务
- 医疗保健和生命科学
- 信息技术
有关示例,请参阅Databricks网站。
贡献者
本文由Microsoft维护。它最初是由以下贡献者撰写的。
主要作者:
Brandon Cowen |高级云解决方案架构师
其他贡献者:
Mick Alberts |技术作家
接下来的步骤
The Big Book of MLOps- Need for Data-centric machine learning Platforms (introduction to MLOps)
- Databricks Machine Learning in-product quickstart
- 10-minute tutorials: Get started with machine learning on Azure Databricks
- Databricks Machine Learning documentation
- Databricks Machine Learning product page and resources
- MLOps on Databricks: A How-To Guide
- Automating the machine learning lifecycle with Databricks machine learning
- MLOps on Azure Databricks with MLflow
- Machine Learning Engineering for the Real World
- Automate Your Machine Learning Pipeline
- Databricks Academy
- Databricks Academy GitHub project
- MLOps glossary
- Three Principles for Selecting Machine Learning Platforms
- What is a Lakehouse?
- Delta Lake home page
- Ingest data into the Azure Databricks Lakehouse
- Clusters
- Libraries
- MLflow Documentation
- Azure Databricks MLflow guide
- Share models across workspaces
- Notebooks
- Developer tools and guidance
- Deploy MLflow models to online endpoints in Azure Machine Learning
- Deploy to Azure Kubernetes Service (AKS)
Related resources
- 登录 发表评论
- 120 次浏览
Tags
最新内容
- 1 day 6 hours ago
- 2 weeks ago
- 3 weeks 1 day ago
- 3 weeks 5 days ago
- 2 months 1 week ago
- 6 months 1 week ago
- 6 months 1 week ago
- 6 months 1 week ago
- 6 months 1 week ago
- 6 months 1 week ago