
category
大型语言模型(LLM)是一类使用转换器网络构建的生成性人工智能模型,可以使用非常大的数据集识别、总结、翻译、预测和生成语言。LLM有望改变我们所知的社会,但培训这些基础模型极具挑战性。
本博客阐述了LLM背后的基本原理,LLM是使用变压器网络、跨模型架构、注意力机制、嵌入技术和基础模型训练策略构建的。
模型架构
模型体系结构定义了变压器网络的主干,广泛地规定了模型的功能和限制。LLM的体系结构通常被称为编码器、解码器或编码器-解码器模型。
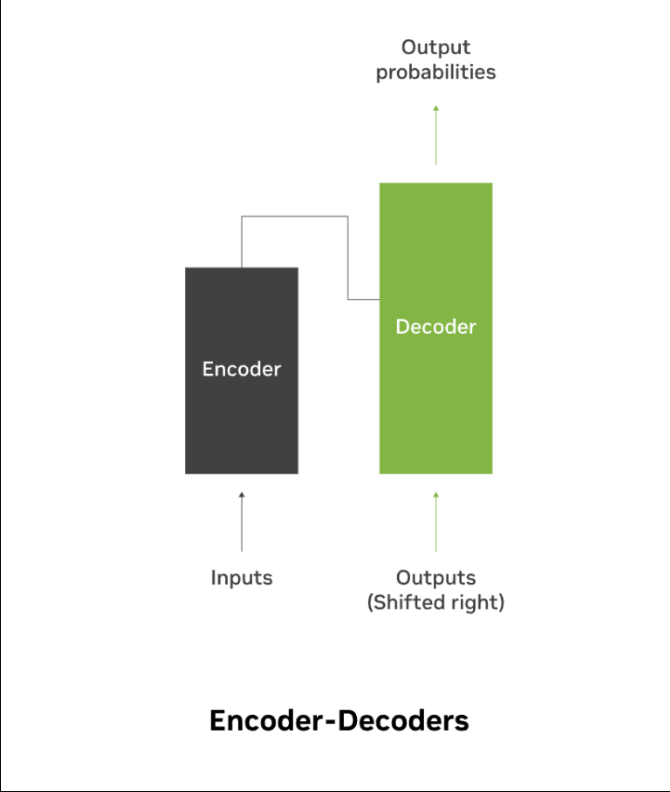
Some popular architectures include:
| Architecture | Description | Suitable for |
| 来自变压器的双向编码器表示(BERT) | Encoder-only architecture, best suited for tasks that can understand language. | Classification and sentiment analysis |
| 生成预训练变压器(GPT) | Decoder-only architecture suited for generative tasks and fine-tuned with labeled data on discriminative tasks. Given the unidirectional architecture, context only flows forward. The GPT framework helps achieve strong natural language understanding using a single-task-agnostic model through generative pre-training and discriminative fine-tuning. |
Textual entailment, sentence similarity, question answering. |
| 文本到文本转换器(序列到序列模型) | Encoder-decoder architecture. It leverages the transfer learning approach to convert every text-based language problem into a text-to-text format, that is taking text as input and producing the next text as output. With a bidirectional architecture, context flows in both directions. | Translation, Question & Answering, Summarization. |
| 混合专家(MoE) | Model architecture decisions that can be applied to any of the architectures. Designed to scale up model capacity substantially while adding minimal computation overhead, converting dense models into sparse models. The MoE layer consists of many expert models and a sparse gating function. The gates route each input to the top-K (K>=2 or K=1) best experts during inference. | Generalize well across tasks for computational efficiency during inference, with low latency |
另一个流行的架构决策是扩展到多模式模型,该模型将来自文本、图像、音频和视频等多种模态或数据形式的信息组合在一起。尽管训练起来很有挑战性,但多模式模型提供了来自不同模式的补充信息的关键好处,就像人类通过分析来自多个感官的数据所理解的那样。
这些模型包含用于每个模态的独立编码器,如用于图像的CNN和用于文本的转换器,以从各自的输入数据中提取高级特征表示。从多种模态提取的特征的组合可能是一个挑战。它可以通过融合从每个模态中提取的特征来解决,或者通过使用注意力机制来衡量每个模态相对于任务的贡献。
联合表示捕捉模式之间的相互作用。模型架构可以包含用于生成任务特定输出的附加解码器,例如分类、字幕生成、翻译、给定提示文本的图像生成、给定提示文字的图像编辑等等。
Delving into transformer networks
在转换器网络领域内,标记化过程在将文本分割成称为标记的较小单元方面发挥着关键作用。
Tokenizers
标记化是构建模型的第一步,包括将文本拆分为更小的单元,称为标记,这些单元成为LLM的基本构建块。这些提取的标记用于构建将标记映射到数字ID的词汇索引,以数字表示适用于深度学习计算的文本。在编码过程中,这些数字标记被编码为表示每个标记含义的向量。在解码过程中,当LLM执行生成时,标记器将数字矢量解码回可读文本序列。
这个过程从规范化开始,处理小写字母、修剪标点符号和空格、词干、旅名化、处理缩写和删除重音。一旦文本被清理干净,下一步就是通过识别单词和句子的边界来分割文本。根据边界的不同,标记化器可以是单词、子单词或字符级别的粒度。
尽管基于单词和字符的标记器很普遍,但它们也存在挑战。基于单词的标记器会导致较大的词汇量,而在标记器训练过程中看不到的单词会导致许多词汇表外的标记。基于字符的标记器会导致长序列和意义较小的单个标记。
由于这些缺点,基于子词的标记器已经流行起来。子词标记化算法的重点是根据常见字符的n-gram和模式,将稀有单词分割成更小、有意义的子词。因为这项技术能够通过已知的子词来表示稀有和看不见的单词,从而减少词汇量。在推理过程中,它还有效地处理了词汇表外的单词,减少了词汇量,同时在推理中优雅地处理了单词表外的词。
流行的子词标记化算法包括字节对编码(BPE)、WordPiece、Unigram和PencePiece。
- BPE从字符词汇开始,迭代地将频繁的相邻字符对合并到新的词汇术语中,通过用单个标记替换最常见的单词,在解码时以更快的推理实现文本压缩。
- WordPiece在进行合并操作时与BPE类似,但这利用了语言的概率性来合并字符,以最大限度地提高训练数据的可能性。
- Unigram从一个大的词汇表开始,计算代币的概率,并根据损失函数删除代币,直到达到所需的词汇表大小。
- 基于语言建模目标,句子片段从原始文本中学习子单词单元,并使用Unigram或BPE标记化算法来构建词汇。
Attention Mechanisms
由于像递归神经网络(RNNs)这样的传统seq-2-seq编码器-解码器语言模型不能很好地随输入序列的长度缩放,因此引入了注意力的概念,并被证明是开创性的。注意力机制使解码器能够使用由编码的输入序列加权的输入序列的最相关部分,其中最相关的令牌被分配最高的权重。这个概念通过按重要性仔细选择标记来改进输入序列长度的缩放。
这一想法在自我关注下得到了进一步发展,并于2017年引入了变压器模型架构,消除了对RNN的需求。自注意机制依赖于同一序列中不同单词之间的关系来创建输入序列的表示。通过包含输入上下文来增强输入嵌入的信息内容,自注意机制在转换器架构中发挥着至关重要的作用。
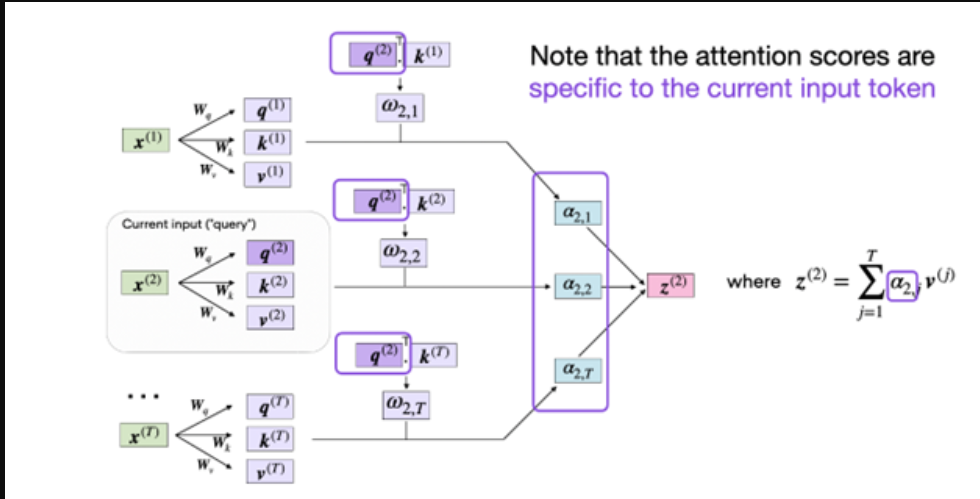
自注意被称为缩放点积注意,因为它是如何实现上下文感知输入表示的。输入序列中的每个标记用于使用其各自的权重矩阵将其自身投影到Query(Q)、Key(K)和Value(V)序列中。目标是在给定所有其他输入令牌作为其上下文的情况下,计算每个输入令牌的注意力加权版本。通过计算Q和K矩阵的缩放点管道,其中由V矩阵确定的相关对获得更高的权重,自注意机制为每个输入令牌(Q)找到合适的向量,给定所有键值对,它们是序列中的其他令牌。
自我注意力进一步演变为多头注意力。前面描述的三个矩阵(Q,K,V)可以被认为是单个头。多头自我注意是指使用多个这样的头。这些头的功能类似于细胞神经网络中的多个内核,关注序列的不同部分,与短期依赖性相比,关注长期依赖性。

And finally, the concept of cross-attention came about, where instead of a single input sequence as in the case of self-attention, this involves two different input sequences. In the transformer model architecture, that’s one input sequence from the encoder and another processed by the decoder.
FlashAttention
较大尺寸的变压器受到注意力层的内存要求的限制,注意力层的存储要求与序列的长度成比例地增加。这种增长是二次型的。为了加快注意力层计算并减少其内存占用,FlashAttention优化了因从较慢的GPU高带宽内存(HBM)重复读写而受到瓶颈的幼稚实现。
FlashAttention使用经典的平铺将查询、键和值块从GPU HBM(其主存储器)加载到SRAM(其快速缓存)进行注意力计算,然后将输出写回HBM。它还通过不存储前向传递的大型注意力矩阵来提高内存使用率;相反,FlashAttention依赖于在SRAM中的反向运算过程中重新计算注意力矩阵。通过这些优化,Flash注意力为更长的序列带来了显著的加速(2-4x)。
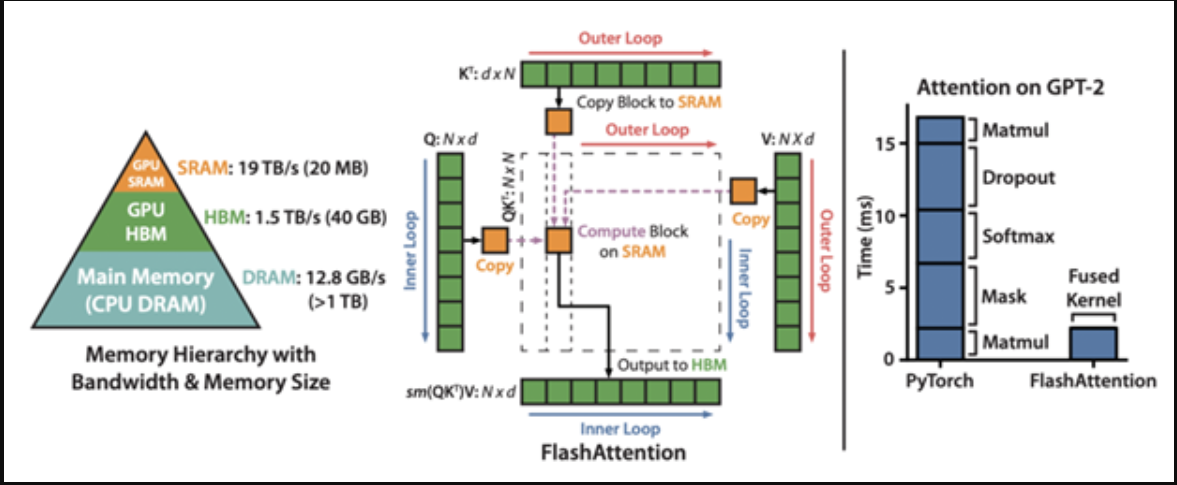
进一步改进的FlashAttention-2比FlashAttention快2倍,增加了序列并行的进一步优化、更好的工作分区和减少非matmul FLOP。这个更新的版本还支持多查询注意力以及我们接下来描述的分组查询注意力。
多查询注意力(MQA)
一种注意力的变体,其中多个查询头关注同一个键和值投影头。这减少了KV高速缓存的大小,从而减少了增量解码的存储器带宽要求。与基线多头注意力架构相比,所得到的模型在推断过程中支持更快的自回归解码,质量下降较小。
组查询注意(GQA)
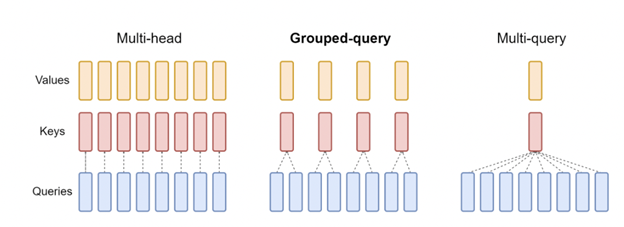
组查询注意力(GQA)是对MQA的改进,以克服质量下降问题,同时保持推理时的加速。此外,使用多头注意力训练的模型不必从头开始重新训练。他们可以在推理过程中使用GQA,只使用原始训练计算的5%来对现有的模型检查点进行上训练。此外,这是使用中间数量(多于一个,少于查询头数量)的键值头对MQA的概括。GQA以与MQA相当的速度实现了接近基线多头注意力的质量。
嵌入技术
单词在句子中出现的顺序很重要。通过将每个输入标记的出现顺序分配给2D位置编码矩阵,在LLM中使用位置编码对该信息进行编码。矩阵的每一行表示与其位置信息相加的序列的编码标记。这允许模型区分具有相似含义但在句子中位置不同的单词,并允许对单词的相对位置进行编码。
原始的transformer架构将绝对位置编码与使用正弦函数的单词嵌入相结合。然而,这种方法不允许在推理时外推到比训练时更长的序列。相对位置编码解决了这一挑战。在这种情况下,查询和关键字向量的内容表示与可训练的位置表示相结合,相对于查询和被剪裁超过一定距离的关键字之间的距离。
RoPE
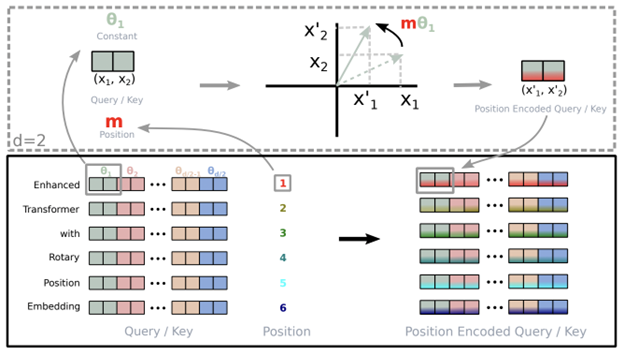
Source:
旋转位置嵌入(RoPE)结合了绝对位置嵌入和相对位置嵌入的概念。使用旋转矩阵对绝对位置进行编码。相对位置相关性被纳入自注意公式中,并以乘法方式添加到上下文表示中。该技术保留了变换器正弦位置嵌入中引入的序列长度灵活性的优点,同时为线性自注意提供了相对位置编码。它还引入了随着相对距离的增加而衰减的令牌间依赖性,从而能够在推理时外推到更长的序列。
AliBi
基于Transformer的LLM不能很好地扩展到较长的序列,这是由于自注意的二次代价,这限制了上下文的令牌数量。此外,在原始变压器架构中引入的正弦位置方法不会外推到比训练过程中看到的更长的序列。这限制了可以应用LLM的真实世界用例集。为了克服这一问题,引入了具有线性偏差的注意力(ALiBi)。该技术不向单词嵌入添加位置嵌入;相反,它使用与距离成比例的惩罚来偏置查询关键注意力得分。
为了便于对比训练时长得多的序列进行有效的外推,ALiBi以与相关关键字和查询之间的距离成比例的线性递减惩罚对注意力得分产生负偏差。与正弦模型相比,该方法不需要额外的运行时或参数,并且内存增加可忽略不计(0–0.7%)。ALiBi在正弦嵌入上的优势很大程度上可以解释为它改进了对早期代币诅咒的避免。这种方法还可以通过更有效地利用更长的上下文历史来实现进一步的收益。
Training transformer networks
在训练LLM时,有几种技术可以提高效率并优化底层硬件配置的资源使用。用数十亿个参数和数万亿个代币来扩展这些大型人工智能模型需要巨大的内存容量。
为了缓解这一需求,一些方法,如模型并行和激活重新计算是流行的。模型并行性在多个GPU上划分模型参数和优化器状态,使得每个GPU存储模型参数的子集。它进一步分为张量并行和流水线并行。
- 张量并行性在GPU之间拆分运算,通常称为层内并行性,专注于在矩阵矩阵乘法等运算中并行化计算。这种技术需要额外的沟通来确保结果是正确的。
- 流水线并行在GPU之间划分模型层,也称为层间并行,专注于将模型逐层划分为块。每个设备计算其块,并将中间激活传递到下一阶段。这可能会导致泡沫时间,一些设备正在进行计算,而另一些设备正在等待,从而导致计算资源的浪费。
- 序列并行性扩展了张量级模型的并行性,注意到转换器层的区域以前没有被并行化,并且沿着序列维度是独立的。沿着序列维度拆分这些层使得计算以及这些区域的激活存储器能够分布在张量并行设备上。由于激活是分布式的,并且内存占用较小,因此可以为向后传递保存更多的激活。
- 选择性激活重新计算与序列并行性密切相关。它通过注意到不同的激活需要不同数量的操作来重新计算,从而改进了内存约束强制重新计算某些但不是全部激活的情况。与检查点和重新计算整个转换器层不同,可以只检查和重新计算每个转换器层的占用大量内存但重新计算成本不高的部分。
所有技术都增加了通信或计算开销。因此,找到实现最大性能的配置,然后使用数据并行度进行扩展训练,对于有效的LLM训练至关重要。
在数据并行训练中,数据集被划分为多个碎片,每个碎片被分配给一个设备。这相当于沿着批处理维度并行化训练过程。每个设备都将保存模型副本的完整副本,并在分配的数据集碎片上进行训练。反向传播后,模型的梯度将全部减小,以便不同设备上的模型参数可以保持同步。
这种技术的一种变体称为完全分片数据并行(FSDP)技术。它在数据并行工作者之间统一地分割模型参数和训练数据,其中每个微批数据的计算是每个GPU工作者的本地计算。
FSDP提供了可配置的分片策略,这些策略可以定制为与集群的物理互连拓扑相匹配,以处理硬件异构性。它可以通过操作重新排序和参数预取,最大限度地减少气泡与计算的重叠。最后,FSDP通过限制为机上未排序参数分配的块数来优化内存使用。由于这些优化,FSDP在TFLOPS方面为具有接近线性可扩展性的更大模型提供了支持。
量化意识培训
量化是深度学习模型以与全精度(浮点)值相比更低的精度执行全部或部分计算的过程。这项技术能够以最小的精度损失加速推理,节省内存,并降低使用深度学习模型的成本。
量化感知训练(QAT)是一种在训练过程中考虑量化影响的方法。使用模拟训练期间的量化过程的量化感知操作来训练模型。模型学习如何在量化表示中表现良好,与训练后的量化相比,提高了精度。前向传递将权重和激活量化为低精度表示。反向传递使用全精度权重和激活来计算梯度。这使模型能够学习对前向传递中引入的量化误差具有鲁棒性的参数。结果是训练后的模型可以在对精度影响最小的情况下进行量化。
今天培训LLM
这篇文章介绍了各种模型训练技术以及何时使用它们。查看关于掌握LLM技术:定制的帖子,继续学习LLM工作流程。
NVIDIA NeMo支持许多训练方法,它为使用3D并行技术进行训练提供了加速的工作流程。它还提供了多种定制技术的选择。它针对语言和图像工作负载的大规模模型的大规模推理进行了优化,具有多GPU和多节点配置。立即下载NeMo框架,并在您喜欢的内部部署和云平台上培训LLM。
Related resources
- GTC session: What's New in Transformer Engine and FP8 Training
- GTC session: Checkmate on Checkpoints in LLM Development (Presented by Weka)
- GTC session: Training Optimization for LLM with NVIDIA NeMo and AWS
- NGC Containers: genai-llm-playground
- Webinar: Implementing Large Language Models
- Webinar: Harness the Power of Cloud-Ready AI Inference Solutions and Experience a Step-By-Step Demo of LLM Inference Deployment in the Cloud
- 登录 发表评论
- 19 次浏览
Tags
最新内容
- 1 week ago
- 1 week 4 days ago
- 1 month 4 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago