
Chinese, Simplified
category
本文描述了许多使用机器学习和计算集群的模型的体系结构。它为需要复杂设置的情况提供了极大的通用性。
另一篇文章《许多模型在Azure中使用Spark进行大规模机器学习》在Azure Databricks或Azure Synapse Analytics中使用了Apache Spark。
架构
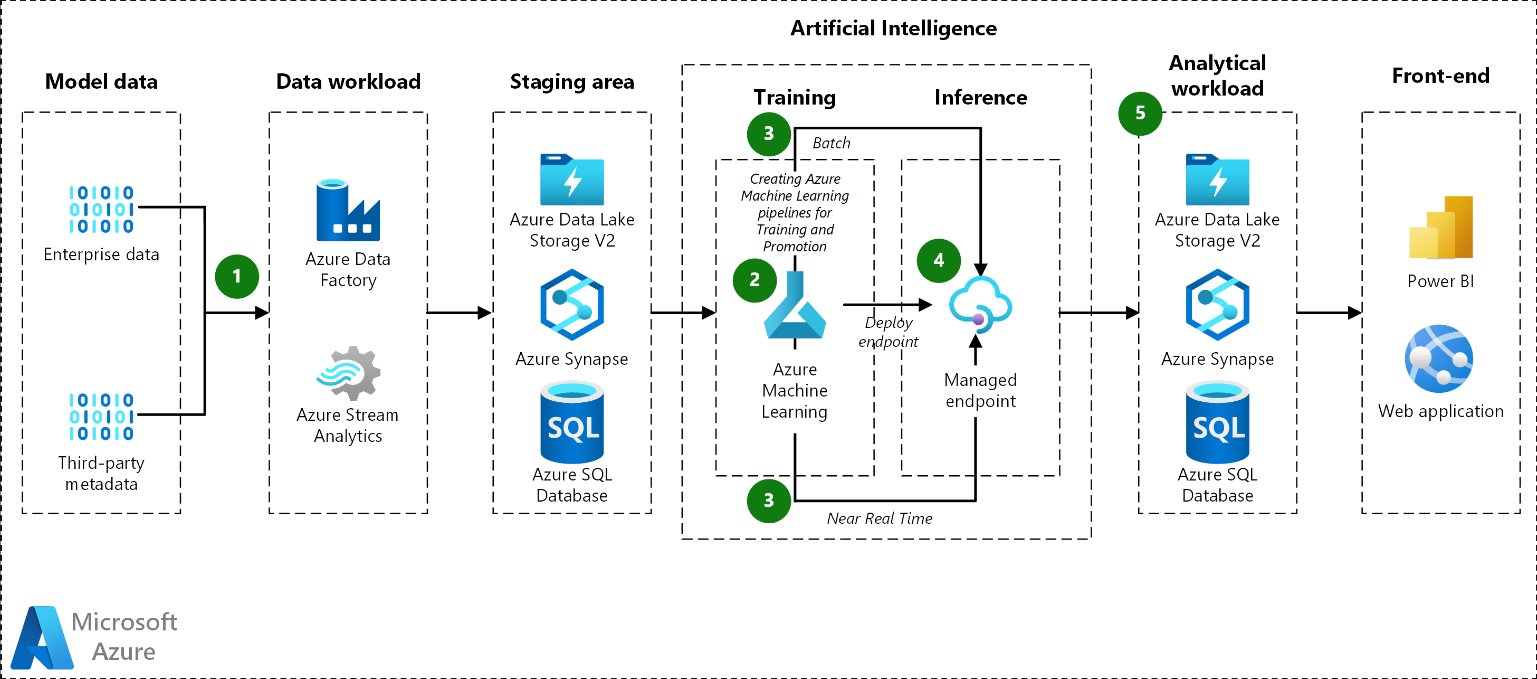
使用Azure机器学习在Azure上进行大规模机器学习的许多模型的体系结构图。
下载此体系结构的Visio文件。
工作流
- 数据摄取:Azure数据工厂从源数据库提取数据,并将其复制到Azure Data Lake Storage。然后,它将其作为表格数据集存储在机器学习数据存储中。
- 模型培训管道:
- 准备数据:训练管道从数据存储中提取数据,并根据需要对其进行进一步转换。它还将数据分组到用于训练模型的数据集中。
- 训练模型:管道为数据准备过程中创建的所有数据集训练模型。它使用ParallelRunStep类来并行训练多个模型。在对模型进行训练后,流水线将其与测试指标一起注册到机器学习中。
- 模型推广管道:
- 评估模型:推广渠道在将经过培训的模型投入生产之前对其进行评估。DevOps管道应用业务逻辑来确定模型是否符合部署标准。例如,它可以检查测试数据的准确性是否超过80%。
- 注册模型:推广管道注册符合生产机器学习工作空间条件的模型。
- 模型批量评分管道:
- 准备数据:批处理评分管道从数据存储中提取数据,并根据需要进一步转换每个文件。它还将数据分组到数据集中进行评分。
- 评分模型:管道使用ParallelRunStep类对多个数据集进行并行评分。它通过搜索模型标签为机器学习中的每个数据集找到合适的模型。然后,它下载模型并使用它对数据集进行评分。它使用DataTransferStep类将结果写回Azure数据湖,然后将预测从Azure数据湖传递给Synapse SQL进行服务。
- 实时评分:如果需要,Azure Kubernetes Service(AKS)可以进行实时评分。由于型号众多,因此应按需加载,而不是预加载。
- 结果
- 预测:批量评分管道将预测保存到Synapse SQL。
- 度量:Power BI连接到模型预测,以检索和汇总结果以供演示。
组件
- Azure机器学习是一种企业级的机器学习服务,用于快速构建和部署模型。它为所有技能级别的用户提供了低代码设计器、自动化ML(AutoML)和支持各种IDE的Jupyter笔记本电脑托管环境。
- Azure Databricks是一个基于Apache Spark的基于云的数据工程工具。它可以处理和转换大量数据,并通过使用机器学习模型进行探索。您可以用R、Python、Java、Scala和Spark SQL编写作业。
- Azure Synapse Analytics是一种统一数据集成、企业数据仓库和大数据分析的分析服务。
Synapse SQL是一个用于T-SQL的分布式查询系统,它支持数据仓库和数据虚拟化场景,并将T-SQL扩展到流和机器学习场景。它提供了无服务器和专用资源模型。 - Azure Data Lake Storage是一种可大规模扩展且安全的存储服务,用于高性能分析工作负载。
- Azure Kubernetes服务(AKS)是一种完全托管的Kubernets服务,用于部署和管理容器化应用程序。AKS通过将操作开销卸载到Azure,简化了托管AKS集群在Azure中的部署。
- Azure DevOps是一组提供全面应用程序和基础设施生命周期管理的开发人员服务。DevOps包括工作跟踪、源代码控制、构建和CI/CD、包管理和测试解决方案。
- Microsoft Power BI是一个软件服务、应用程序和连接器的集合,它们协同工作,将不相关的数据源转化为连贯、视觉沉浸式和交互式的见解。
选择
- 源数据可以来自任何数据库。
- 您可以使用托管在线端点或AKS来部署实时推理。
场景详细信息
许多机器学习问题过于复杂,单个机器学习模型无法解决。无论是预测每家商店的每一件商品的销售额,还是为数百口油井的维护建模,为每个实例建立一个模型都可能改善许多机器学习问题的结果。这种多模型模式在各种行业中都很常见,并且有许多真实的用例。通过使用Azure机器学习,端到端的多模型管道可以包括模型训练、批量推理部署和实时部署。
多模型解决方案需要在训练和评分过程中为每个模型提供不同的数据集。例如,如果任务是预测每个商店的每个商品的销售额,则每个数据集都将用于唯一的商品-商店组合。
潜在用例
- 零售:杂货连锁店需要为每家商店和商品创建一个单独的收入预测模型,每家商店总共有1000多个模型。
- 供应链:对于仓库和产品的每一种组合,分销公司都需要优化库存。
- 餐馆:拥有数千家特许经营权的连锁店需要预测每一家的需求。
注意事项
这些注意事项实现了Azure架构良好的框架的支柱,这是一套可用于提高工作负载质量的指导原则。有关详细信息,请参阅Microsoft Azure架构良好的框架。
- 数据分区对数据进行分区是实现多模型模式的关键。如果每个存储需要一个模型,则数据集包括一个存储的所有数据,并且数据集的数量与存储的数量一样多。如果你想按商店对产品进行建模,那么产品和商店的每一个组合都会有一个数据集。根据源数据格式的不同,可能很容易对数据进行分区,也可能需要大量的数据混洗和转换。Spark和Synapse SQL可以很好地扩展此类任务,而Python-panda则不然,因为它只在一个节点和进程上运行。
- 模型管理:训练和评分管道为每个数据集识别并调用正确的模型。为此,他们计算表征数据集的标签,然后使用这些标签来找到匹配的模型。标签标识数据分区键和模型版本,还可能提供其他信息。
- 选择正确的体系结构:
- 当您的培训管道具有复杂的数据转换和分组需求时,Spark是合适的。它提供了灵活的拆分和分组技术,可以根据产品商店或定位产品等特征组合对数据进行分组。可以将结果放置在Spark DataFrame中,以便在后续步骤中使用。
- 当你的机器学习训练和评分算法很简单时,你可能能够用scikit-learn等库来划分数据。在这种情况下,您可能不需要Spark,因此可以避免安装Azure Synapse或Azure Databricks时可能出现的复杂性。
- 当训练数据集已经创建时——例如,它们位于单独的文件中或单独的行或列中——您不需要Spark来进行复杂的数据转换。
- 机器学习和计算集群解决方案为需要复杂设置的情况提供了强大的通用性。例如,您可以使用自定义Docker容器,或者下载文件,或者下载预先训练的模型。计算机视觉和自然语言处理(NLP)深度学习是可能需要这种多功能性的应用程序的例子。
- Spark训练和评分:使用Spark架构时,可以使用Spark pandas函数API进行并行训练和评分。
- 单独的模型存储库:为了保护已部署的模型,可以考虑将它们存储在自己的存储库中,而训练和测试管道不会触及这些存储库。
- ParallelRunStep类:Python ParallelRun Step类是运行许多模型训练和推理的强大选项。它可以以多种方式对数据进行分区,然后将机器学习脚本并行应用于分区的元素。与其他形式的机器学习培训一样,您可以指定一个可访问Python包索引(PyPI)包的自定义培训环境,或者为需要超过标准PyPI的配置指定更高级的自定义Docker环境。有许多CPU和GPU可供选择。
- 在线推理:如果管道在开始时加载并缓存所有模型,则这些模型可能会耗尽容器的内存。因此,在run方法中按需加载模型,即使这可能会略微增加延迟。
成本优化
成本优化是指寻找减少不必要费用和提高运营效率的方法。有关更多信息,请参阅成本优化支柱概述。
要更好地了解在Azure上运行此场景的成本,请使用定价计算器。良好的开端假设是:
- 每天都会对服务模特进行培训,使其保持最新状态。
- 对于一个包含4000万行、包含10000个存储和产品组合的数据集,使用配备有12个使用Ls16_v2实例的VM的集群在Azure Databricks上进行培训大约需要30分钟。
- 使用同一组数据进行批量评分大约需要20分钟。
- 您可以使用机器学习来部署实时推理。根据您的请求量,选择适当的VM类型和群集大小。
- AKS集群根据需要自动缩放,平均每月有两个节点处于活动状态。
- 要查看定价在您的用例中的差异,请更改变量以匹配您的预期数据大小和服务负载要求。对于较大或较小的训练数据大小,请增大或减小Azure Databricks集群的大小。为了在模型服务期间处理更多并发用户,请增加AKS集群的大小。
贡献者
本文由Microsoft维护。它最初是由以下贡献者撰写的。
主要作者:
- James Nguyen |首席云解决方案架构师
接下来的步骤
- Configure a Kubernetes cluster for Azure Machine Learning
- Many Models Solution Accelerator
- ParallelRunStep Class
- DataTransferStep Class
- Connect to storage services on Azure
- What is Azure Synapse Analytics?
- Deploy a model to an Azure Kubernetes Service cluster
Related resources
- 登录 发表评论
- 56 次浏览
发布日期
星期四, 七月 4, 2024 - 18:40
最后修改
星期三, 一月 21, 2026 - 09:41
Article
最新内容
- 1 week 5 days ago
- 2 weeks 6 days ago
- 3 weeks 3 days ago
- 2 months 1 week ago
- 6 months ago
- 6 months ago
- 6 months ago
- 6 months ago
- 6 months ago
- 6 months ago