
category
大家好,在这篇文章中,我将讨论如何从大型语言模型(LLM)进行推理,以及如何部署Trendyol LLM v1.0模型,作为Trendyol NLP团队,我们使用TensorRT LLM框架在Triton推理服务器上为开源社区做出了贡献。已经开发了各种框架,如vLLM、TGI和TensorRTLLM,用于从LLM执行推理。在这些工具中,TensorRTLLM是一个重要的框架,可以在生产环境中有效地使用模型。
Triton推理服务器是Nvidia开发的一种推理工具,支持各种机器学习框架的基础设施。此服务器专门为需要大规模模型部署和处理的应用程序设计。通过支持各种深度学习框架,如TensorFlow、PyTorch、ONNX Runtime等,Triton推理服务器能够在生产环境中快速高效地运行这些模型。此外,Triton能够在GPU上进行并行计算,有助于快速高效地处理大型模型。因此,开发人员可以在Triton推理服务器上轻松管理和部署复杂的模型体系结构和大型数据集。
Triton推理服务器还支持带有tensorrtllm_backend后端的TensorRT LLM框架。得益于tensorrtllm_backend,我们可以在Triton推理服务器上部署运行在tensorrtllm框架上的模型。如下图所示,很明显,tensorrtllm_backend后端构建在tensorrtllm框架和TensorRT环境之上。
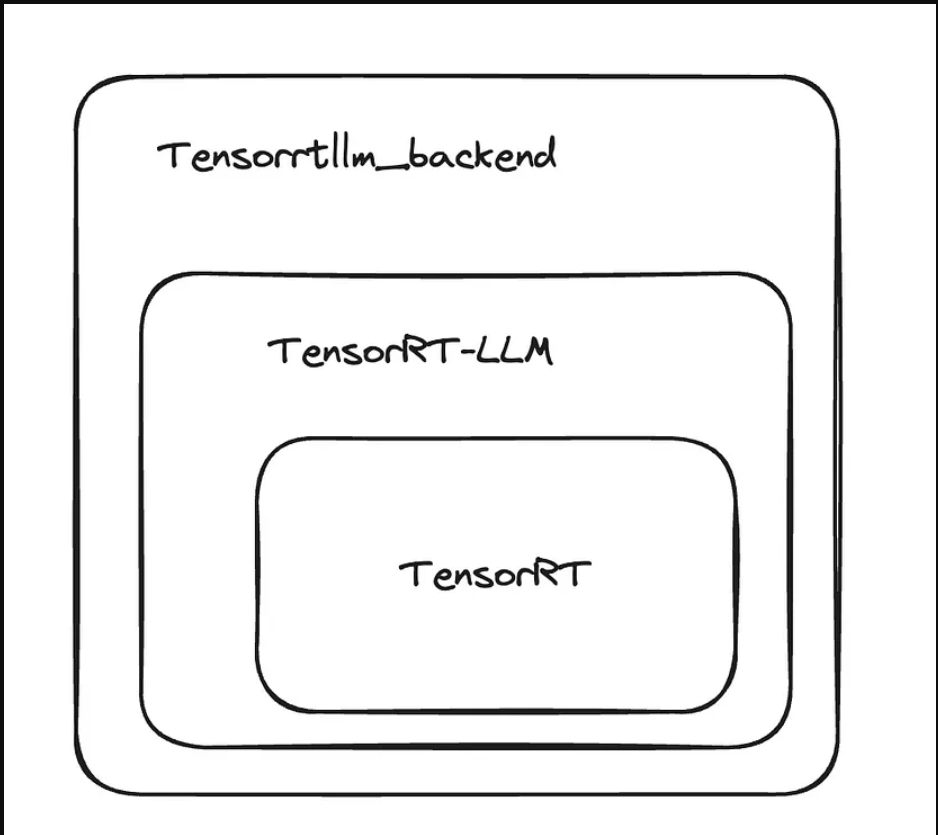
Tensorrtllm_backend backend’s dependencies
在TensorRT LLM中,模型不是以原始形式使用的。为了使用模型,需要专门针对相应的GPU进行编译,从而生成一个称为引擎的模型文件。在从原始模型创建引擎的过程中,可以应用GPU支持的各种优化和量化技术。此外,如果需要模型的并行化,则在该编译阶段指定该并行化,并且在该阶段还必须指定将在其上部署模型的GPU的数量。由于每个GPU模型都需要特定的编译过程,因此应该在相同模型的GPU上编译相同的模型进行推理。这就是TensorRT LLM的速度来源。编译模型的步骤如下面的流程所示。如流程所示,首先,在GPU环境中编译将与TensorRT-LLM框架一起使用的模型,以创建TensorRTLLM检查点。然后,使用该检查点创建TensorRT引擎文件。
生成的TensorRT引擎文件存储在Triton推理服务器上,用于与TensorRT LLM ModelRunner或tensorrtllm_backend后端进行推理,我将在本文中对此进行讨论。
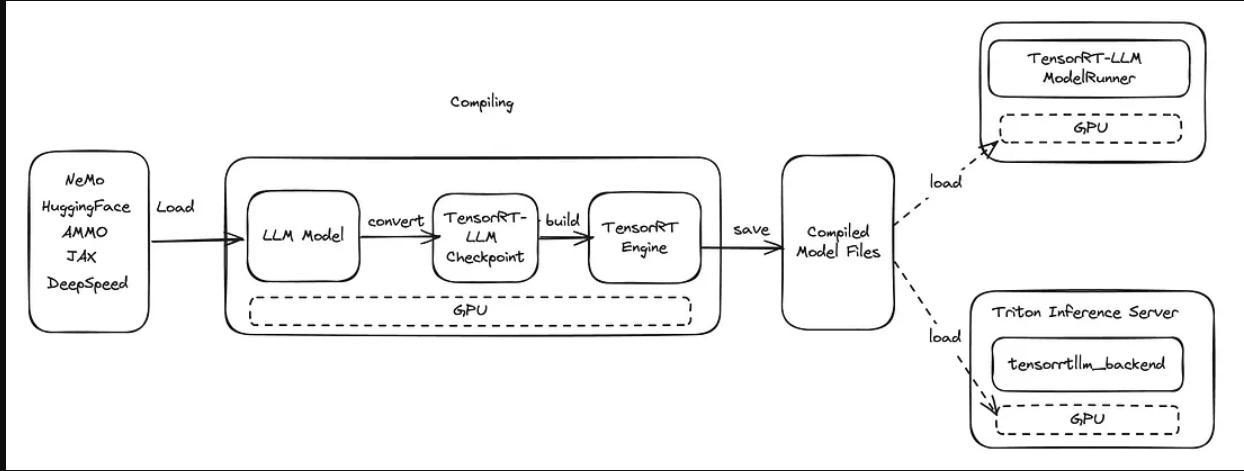
现在,让我们根据这些信息,继续使用Triton推理服务器上的tensorrtllm_backend后端对Trendyol LLM模型执行推理的步骤。
创建TensorRT引擎
- 步骤1确定将安装Triton推理服务器进行推理的GPU模型。我们将使用A100 GPU。
- 步骤2确定要安装的Triton推断服务器的版本。我们将使用“nvcr.io/nvidia/tritonserver:24.02-trtllm-python-py3”映像,因此版本为24.02。
- 步骤3审查“24.02”版本Triton推断服务器的支持矩阵。确定tensorrtllm_backend和tensorrtllm的兼容版本。由于24.02版本与TensorRT LLM v0.8.0兼容,我们将使用tensorrtllm_backend v0.8.0版本。
- 步骤4我们有一个配备A100 GPU的服务器,它需要为A100安装必要的驱动程序和兼容的CUDA版本。如果你要继续使用Docker,你需要在Docker环境中为GPU的使用设置必要的安装。如果你不确定如何做到这一点,你可以参考这篇文章。
nvidia smi
- 步骤5在Docker或Kubernetes环境中,从“nvcr.io/nvidia/tritonserver:24.02-trtllm-python-py3”映像创建一个容器。我们利用这个镜像并创建了一个Dockerfile来在其中安装JupyterLab。由于我们的GPU资源在Kubernetes上,我们用这个Dockerfile构建了一个镜像,并通过定义必要的服务配置通过相关服务运行JupyterLab。如果您可以通过SSH连接到中的服务器,则可以使用以下Dockerfile创建映像,根据您的喜好使用JupyterLab或终端。
Dockerfile
FROM nvcr.io/nvidia/tritonserver:24.02-trtllm-python-py3
WORKDIR /
COPY . .
RUN pip install protobuf SentencePiece torch
RUN pip install jupyterlab
EXPOSE 8888
EXPOSE 8000
EXPOSE 8001
EXPOSE 8002
CMD ["/bin/sh", "-c", "jupyter lab --LabApp.token='password' --LabApp.ip='0.0.0.0' --LabApp.allow_root=True"]-
步骤6从Dockerfile创建容器并通过JupyterLab打开终端或使用“docker exec-it container name sh”命令连接到容器外壳后,我们将安装Git,因为我们将使用Git提取我们的模型和tensorrtllm_backend。为此,在根目录中创建了一个名为/tensorrt的文件夹。我们将在此文件夹下收集所有必要的文件。
mkdir /tensorrt
cd /tensorrt创建/tensorrt目录并导航到该目录后,将创建以下文件:
“1.install_git_and_lfs.sh”:如果尚未执行git和git lfs安装,我们将使用此文件执行这些安装。
#!/bin/bash
# Author: Murat Tezgider
# Date: 2024-03-18
# Description: This script automates the check for Git and Git LFS installations, installing them if not already installed.
set -e
# Function to check if Git is installed
is_git_installed() {
if command -v git &>/dev/null; then
return 0
else
return 1
fi
}
# Function to check if Git LFS is installed
is_git_lfs_installed() {
if command -v git-lfs &>/dev/null; then
return 0
else
return 1
fi
}
# Check if Git is already installed
if is_git_installed; then
echo "Git is already installed."
git --version
# Check if Git LFS is installed
if is_git_lfs_installed; then
echo "Git LFS is already installed."
git-lfs --version
else
echo "Installing Git LFS..."
apt-get update && apt-get install git-lfs -y || { echo "Failed to install Git LFS"; exit 1; }
echo "Git LFS has been installed successfully."
fi
else
# Update package lists and install Git
apt-get update && apt-get install git -y || { echo "Failed to install Git"; exit 1; }
# Install Git LFS
apt-get install git-lfs -y || { echo "Failed to install Git LFS"; exit 1; }
echo "Git and Git LFS have been installed successfully."
fi“2.install_tensort_llm.sh”:我们提取tensorrtllm_backend项目及其子模块(如tensorrt_llm等),通过该文件确保与Triton的兼容性。由于与我们使用的Triton版本兼容的tensorrtllm_backend版本为v0.8.0,因此我们在文件中指定了TENSORRT_backend_LLM_version=v0.8.0。
#!/bin/bash
# Author: Murat Tezgider
# Date: 2024-03-18
# Description: This script automates the installation process for TensorRT-LLM. Prior to running this script,
#ensure that Git and Git LFS ('apt-get install git-lfs') are installed.
# Step 1: Defining folder path and version
echo "Step 1: Defining folder path and version"
TENSORRT_BACKEND_LLM_VERSION=v0.8.0
TENSORRT_DIR="/tensorrt/$TENSORRT_BACKEND_LLM_VERSION"
# Step 2: Enter the installation folder and clone
echo "Step 2: Enter the installation folder and clone"
[ ! -d "$TENSORRT_DIR" ] && mkdir -p "$TENSORRT_DIR"
cd "$TENSORRT_DIR" || { echo "Failed to change directory to $TENSORRT_DIR"; exit 1; }
git clone -b "$TENSORRT_BACKEND_LLM_VERSION" https://github.com/triton-inference-server/tensorrtllm_backend.git --progress
--verbose || { echo "Failed to clone repository"; exit 1; }
cd "$TENSORRT_DIR"/tensorrtllm_backend || { echo "Failed to change directory to $TENSORRT_DIR/tensorrtllm_backend"; exit 1; }
git submodule update --init --recursive || { echo "Failed to update submodules"; exit 1; }
git lfs install || { echo "Failed to install Git LFS"; exit 1; }
git lfs pull || { echo "Failed to pull Git LFS files"; exit 1; }
# Step 3: Enter the backend folder and Install backend related dependencies
echo "Step 3: Enter the backend folder and Install backend related dependencies"
cd "$TENSORRT_DIR"/tensorrtllm_backend || { echo "Failed to change directory to $TENSORRT_DIR/tensorrtllm_backend"; exit 1; }
apt-get update && apt-get install -y --no-install-recommends rapidjson-dev python-is-python3 ||
{ echo "Failed to install dependencies"; exit 1; }
pip3 install -r requirements.txt --extra-index-url https://pypi.ngc.nvidia.com || { echo "Failed to install Python dependencies"; exit 1; }
# Step 4: Install tensorrt-llm library
echo "Step 4: Install tensorrt-llm library"
pip install tensorrt_llm=="$TENSORRT_BACKEND_LLM_VERSION" -U --pre --extra-index-url https://pypi.nvidia.com
|| { echo "Failed to install tensorrt-llm library"; exit 1; }“3.trendyol_lm_tensort_engine_build_and_test.sh”:通过运行此文件,我们从Hugging Face下载trendyol/trendyol-LM-7b-chat-v1.0模型,并将其转换为tensorrt llm检查点。然后,我们从这个检查点创建一个TensorRTLLM引擎。最后,我们通过运行创建的引擎来测试它。
#!/bin/bash
# Author: Murat Tezgider
# Date: 2024-03-18
# Description: This script automates the installation and inference process for a Hugging Face model using
# TensorRT-LLM. Ensure that Git and Git LFS ('apt-get install git-lfs') are installed before running this script.
#Before running this script, run the following scripts sequentially: 1. install_git_and_lfs.sh 2. install_tensorrt_llm.sh
HF_MODEL_NAME="Trendyol-LLM-7b-chat-v1.0"
HF_MODEL_PATH="Trendyol/Trendyol-LLM-7b-chat-v1.0"
# Clone the Hugging Face model repository
mkdir -p /tensorrt/models && cd /tensorrt/models && git clone https://huggingface.co/$HF_MODEL_PATH
# Convert the model checkpoint to TensorRT format
python /tensorrt/v0.8.0/tensorrtllm_backend/tensorrt_llm/examples/llama/convert_checkpoint.py \
--model_dir /tensorrt/models/$HF_MODEL_NAME \
--output_dir /tensorrt/tensorrt-models/$HF_MODEL_NAME/v0.8.0/trt-checkpoints/fp16/1-gpu/ \
--dtype float16
# Build TensorRT engine
trtllm-build --checkpoint_dir /tensorrt/tensorrt-models/$HF_MODEL_NAME/v0.8.0/trt-checkpoints/fp16/1-gpu/ \
--output_dir /tensorrt/tensorrt-models/$HF_MODEL_NAME/v0.8.0/trt-engines/fp16/1-gpu/ \
--remove_input_padding enable \
--context_fmha enable \
--gemm_plugin float16 \
--max_input_len 32768 \
--strongly_typed
# Run inference with the TensorRT engine
python3 /tensorrt/v0.8.0/tensorrtllm_backend/tensorrt_llm/examples/run.py \
--max_output_len=250 \
--tokenizer_dir /tensorrt/models/$HF_MODEL_NAME \
--engine_dir=/tensorrt/tensorrt-models/$HF_MODEL_NAME/v0.8.0/trt-engines/fp16/1-gpu/ \
--max_attention_window_size=4096 \
--temperature=0.3 \
--top_k=50 \
--top_p=0.9 \
--repetition_penalty=1.2 \
--input_text="[INST] Sen yardımsever bir asistansın ve sana verilen talimatlar doğrultusunda en
iyi cevabı üretmeye çalışacaksın.\n\nTürkiye'nin doğusunda ne var? [/INST]"- 步骤7创建文件后,我们按如下方式授予它们执行权限。
chmod +x 1.install_git_and_lfs.sh 2.install_tensorrt_llm.sh 3.trendyol_llm_tensorrt_engine_build_and_test.sh- 步骤8现在,我们可以分别运行名为“1.install_git_and_lfs.sh”、“2.install_tensort_llm.sh”和“3.trendyol_llm_sensort_engine_build_and_test.sh”的bash文件。
./1.install_git_and_lfs.sh && ./2.install_tensorrt_llm.sh && ./3.trendyol_llm_tensorrt_engine_build_and_test.sh在执行完文件中的所有步骤后,您应该会在终端屏幕的末尾看到如下LLM结果输出。
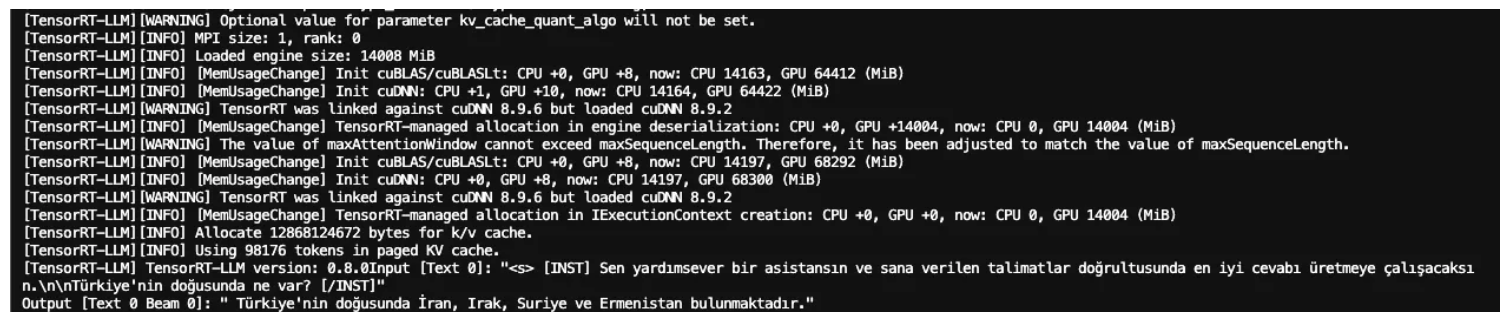
当所有脚本都成功执行后,您应该会在/tensorrt目录下看到一个文件夹结构,如下所示。
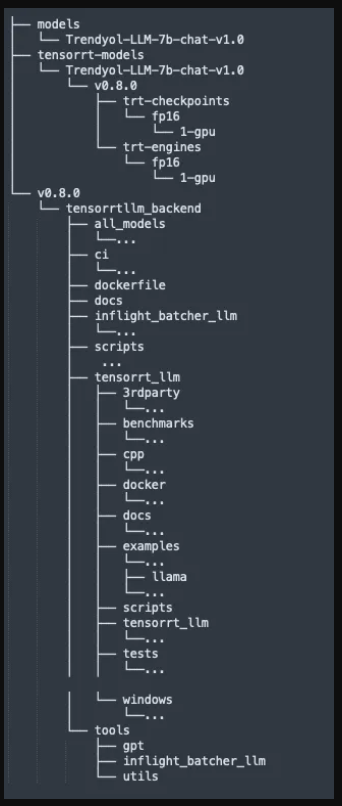
既然我们已经成功地编译了模型并创建并运行了TensorRT LLM引擎文件,我们就可以继续将这些TensorRT LLC引擎文件部署到Triton推理服务器上。
使用Triton推理服务器进行模型部署的步骤
Triton推断服务器将模型存储在一个名为“存储库”的目录中。在该目录下,每个模型都位于以该模型命名的文件夹中,还有一个名为“config.pbtxt”的配置文件。示例模型已在目录“tensorrtllm_backend/all_models/inflight_batcher_llm”下创建。在这些示例模型定义中,我们需要根据需要更新“config.pbtxt”文件中的一些变量。为了方便地更新这些参数,使用了“tensorrtllm_backend/tools/fill_template.py”python工具。我们使用此工具更新了“config.pbtxt”文件。
- 步骤1我们创建一个目录来存储我们的模型定义,然后将位于'/tensorrt/v0.8.0/tensortrrtllm_backend/all_models/inflight_batcher_llm'下的示例模型定义复制到新创建的目录'/tenssorrt/triton repos/trtibf-Trendyol-LM-7b-chat-v1.0/'中。
mkdir -p /tensorrt/triton-repos/trtibf-Trendyol-LLM-7b-chat-v1.0/
cp /tensorrt/v0.8.0/tensorrtllm_backend/all_models/inflight_batcher_llm/*
/tensorrt/triton-repos/trtibf-Trendyol-LLM-7b-chat-v1.0/ -rtriton-repos
└── trtibf-Trendyol-LLM-7b-chat-v1.0
├── ensemble
│ ├── 1
│ └── config.pbtxt
├── postprocessing
│ ├── 1
│ │ └── model.py
│ └── config.pbtxt
├── preprocessing
│ ├── 1
│ │ └── model.py
│ └── config.pbtxt
├── tensorrt_llm
│ ├── 1
│ └── config.pbtxt
└── tensorrt_llm_bls
├── 1
│ └── model.py
└── config.pbtxt- 步骤2随后,在“config.pbtxt”文件中,我们用以下值更新模型正常运行所需的参数,如“tokenizer”和“engine_dir”。
python3 /tensorrt/v0.8.0/tensorrtllm_backend/tools/fill_template.py -i
/tensorrt/triton-repos/trtibf-Trendyol-LLM-7b-chat-v1.0/preprocessing/config.pbtxt tokenizer_dir
:/tensorrt/models/Trendyol-LLM-7b-chat-v1.0,tokenizer_type:llama,triton_max_batch_size:64,preprocessing_instance_count:1
python3 /tensorrt/v0.8.0/tensorrtllm_backend/tools/fill_template.py
-i /tensorrt/triton-repos/trtibf-Trendyol-LLM-7b-chat-v1.0/postprocessing/config.pbtxt tokenizer_dir:
/tensorrt/models/Trendyol-LLM-7b-chat-v1.0,tokenizer_type:llama,triton_max_batch_size:64,postprocessing_instance_count:1
python3 /tensorrt/v0.8.0/tensorrtllm_backend/tools/fill_template.py
-i /tensorrt/triton-repos/trtibf-Trendyol-LLM-7b-chat-v1.0/tensorrt_llm_bls/config.pbtxt
triton_max_batch_size:64,decoupled_mode:False,bls_instance_count:1,accumulate_tokens:False
python3 /tensorrt/v0.8.0/tensorrtllm_backend/tools/fill_template.py
-i /tensorrt/triton-repos/trtibf-Trendyol-LLM-7b-chat-v1.0/ensemble/config.pbtxt triton_max_batch_size:64
python3 /tensorrt/v0.8.0/tensorrtllm_backend/tools/fill_template.py
-i /tensorrt/triton-repos/trtibf-Trendyol-LLM-7b-chat-v1.0/tensorrt_llm/config.pbtxt triton_max_batch_size:64,decoupled_mode
:False,max_beam_width:1,engine_dir:/tensorrt/tensorrt-models/Trendyol-LLM-7b-chat-v1.0/v0.8.0/trt-engines/fp16/1-gpu/,
max_tokens_in_paged_kv_cache:2560,max_attention_window_size:2560,kv_cache_free_gpu_mem_fraction:0.9,exclude_input_in_output
:True,enable_kv_cache_reuse:False,batching_strategy:inflight_batching,max_queue_delay_microseconds:600- 步骤3现在,我们的Triton存储库已经准备就绪,我们运行Triton服务器从该存储库中读取模型。
tritonserver --model-repository=/tensorrt/triton-repos/trtibf-Trendyol-LLM-7b-chat-v1.0
--model-control-mode=explicit
--load-model=preprocessing --load-model=postprocessing
--load-model=tensorrt_llm --load-model=tensorrt_llm_bls --load-model=ensemble --log-verbose=2 --log-info=1
--log-warning=1 --log-error=1
为了使Triton服务器在没有任何问题的情况下启动,所有型号都需要处于“就绪”状态。当您看到如下所示的输出时,Triton服务器已经顺利启动。
I0320 11:44:44.456547 15296 model_lifecycle.cc:273] ModelStates()
I0320 11:44:44.456580 15296 server.cc:677]
+------------------+---------+--------+
| Model | Version | Status |
+------------------+---------+--------+
| ensemble | 1 | READY |
| postprocessing | 1 | READY |
| preprocessing | 1 | READY |
| tensorrt_llm | 1 | READY |
| tensorrt_llm_bls | 1 | READY |
+------------------+---------+--------+
I0320 11:44:44.474142 15296 metrics.cc:877] Collecting metrics for GPU 0: GRID A100D-80C
I0320 11:44:44.475350 15296 metrics.cc:770] Collecting CPU metrics
I0320 11:44:44.475507 15296 tritonserver.cc:2508]
+----------------------------------+----------------------------------------------------------------------------------------------------------------+
| Option | Value |
+----------------------------------+----------------------------------------------------------------------------------------------------------------+
| server_id | triton |
| server_version | 2.43.0 |
| server_extensions | classification sequence model_repository model_repository(unload_dependents)
schedule_policy model_configurati |
| | on system_shared_memory cuda_shared_memory binary_tensor_data parameters statistics
trace logging |
| model_repository_path[0] | /tensorrt/triton-repos/trtibf-Trendyol-LLM-7b-chat-v1.0 |
| model_control_mode | MODE_EXPLICIT |
| startup_models_0 | ensemble |
| startup_models_1 | postprocessing |
| startup_models_2 | preprocessing |
| startup_models_3 | tensorrt_llm |
| startup_models_4 | tensorrt_llm_bls |
| strict_model_config | 0 |
| rate_limit | OFF |
| pinned_memory_pool_byte_size | 268435456 |
| cuda_memory_pool_byte_size{0} | 67108864 |
| min_supported_compute_capability | 6.0 |
| strict_readiness | 1 |
| exit_timeout | 30 |
| cache_enabled | 0 |
+----------------------------------+----------------------------------------------------------------------------------------------------------------+
I0320 11:44:44.476247 15296 grpc_server.cc:2426]
+----------------------------------------------+---------+
| GRPC KeepAlive Option | Value |
+----------------------------------------------+---------+
| keepalive_time_ms | 7200000 |
| keepalive_timeout_ms | 20000 |
| keepalive_permit_without_calls | 0 |
| http2_max_pings_without_data | 2 |
| http2_min_recv_ping_interval_without_data_ms | 300000 |
| http2_max_ping_strikes | 2 |
+----------------------------------------------+---------+
I0320 11:44:44.476757 15296 grpc_server.cc:102] Ready for RPC 'Check', 0
I0320 11:44:44.476795 15296 grpc_server.cc:102] Ready for RPC 'ServerLive', 0
I0320 11:44:44.476810 15296 grpc_server.cc:102] Ready for RPC 'ServerReady', 0
I0320 11:44:44.476824 15296 grpc_server.cc:102] Ready for RPC 'ModelReady', 0
I0320 11:44:44.476838 15296 grpc_server.cc:102] Ready for RPC 'ServerMetadata', 0
I0320 11:44:44.476851 15296 grpc_server.cc:102] Ready for RPC 'ModelMetadata', 0
I0320 11:44:44.476865 15296 grpc_server.cc:102] Ready for RPC 'ModelConfig', 0
I0320 11:44:44.476881 15296 grpc_server.cc:102] Ready for RPC 'SystemSharedMemoryStatus', 0
I0320 11:44:44.476895 15296 grpc_server.cc:102] Ready for RPC 'SystemSharedMemoryRegister', 0
I0320 11:44:44.476910 15296 grpc_server.cc:102] Ready for RPC 'SystemSharedMemoryUnregister', 0
I0320 11:44:44.476923 15296 grpc_server.cc:102] Ready for RPC 'CudaSharedMemoryStatus', 0
I0320 11:44:44.476936 15296 grpc_server.cc:102] Ready for RPC 'CudaSharedMemoryRegister', 0
I0320 11:44:44.476949 15296 grpc_server.cc:102] Ready for RPC 'CudaSharedMemoryUnregister', 0
I0320 11:44:44.476963 15296 grpc_server.cc:102] Ready for RPC 'RepositoryIndex', 0
I0320 11:44:44.476977 15296 grpc_server.cc:102] Ready for RPC 'RepositoryModelLoad', 0
I0320 11:44:44.476989 15296 grpc_server.cc:102] Ready for RPC 'RepositoryModelUnload', 0
I0320 11:44:44.477003 15296 grpc_server.cc:102] Ready for RPC 'ModelStatistics', 0
I0320 11:44:44.477018 15296 grpc_server.cc:102] Ready for RPC 'Trace', 0
I0320 11:44:44.477031 15296 grpc_server.cc:102] Ready for RPC 'Logging', 0
I0320 11:44:44.477060 15296 grpc_server.cc:359] Thread started for CommonHandler
I0320 11:44:44.477204 15296 infer_handler.h:1188] StateNew, 0 Step START
I0320 11:44:44.477245 15296 infer_handler.cc:680] New request handler for ModelInferHandler, 0
I0320 11:44:44.477276 15296 infer_handler.h:1312] Thread started for ModelInferHandler
I0320 11:44:44.477385 15296 infer_handler.h:1188] StateNew, 0 Step START
I0320 11:44:44.477418 15296 infer_handler.cc:680] New request handler for ModelInferHandler, 0
I0320 11:44:44.477443 15296 infer_handler.h:1312] Thread started for ModelInferHandler
I0320 11:44:44.477550 15296 infer_handler.h:1188] StateNew, 0 Step START
I0320 11:44:44.477582 15296 stream_infer_handler.cc:128] New request handler for ModelStreamInferHandler, 0
I0320 11:44:44.477608 15296 infer_handler.h:1312] Thread started for ModelStreamInferHandler
I0320 11:44:44.477622 15296 grpc_server.cc:2519] Started GRPCInferenceService at 0.0.0.0:8001
I0320 11:44:44.477845 15296 http_server.cc:4637] Started HTTPService at 0.0.0.0:8000
I0320 11:44:44.518903 15296 http_server.cc:320] Started Metrics Service at 0.0.0.0:8002- 步骤4现在,您可以打开一个新的终端,并使用curl向我们的模型发送请求。
curl -X POST localhost:8000/v2/models/ensemble/generate -d
'{"text_input": "Türkiye nin doğusunda ne var?", "max_tokens": 200, "bad_words": "", "stop_words": ""}'结果
{"context_logits":0.0,"cum_log_probs":0.0,"generation_logits":0.0,"model_name":"ensemble","model_version":"1",
"output_log_probs":[0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0],
"sequence_end":false,"sequence_id":0,"sequence_start":false,"text_output":"\nYani, Türkiye'nin doğusunda İran, Irak ve Suriye var."}
如果您已经顺利完成了LLM模型的部署,这意味着您已经一步一步地成功完成了使用Triton的LLM模型部署。在下一步中,仍然需要将引擎、标记器和Triton存储库模型定义文件移动到存储区域,以使Triton能够从此源读取。为了防止这篇文章太长,我将在这里结束它。我希望你觉得它有帮助!
我计划在未来的一篇文章中讨论如何将这些文件传输到存储区域,并提供如何使用它们的详细信息。保持健康和快乐!
您可以访问这个GitHub存储库,其中列出了迄今为止执行的逐步过程。
结论
在本文中,我们概述了使用Triton推理服务器的LLM模型的简化部署过程。通过准备模型、创建TensorRT LLM引擎文件并将其部署到Triton上,我们展示了一种在生产中为LLM模型提供服务的有效方法。未来的工作可能集中在将这些文件传输到存储器并详细说明它们的使用情况。总体而言,Triton为有效部署LLM模型提供了一个强大的平台。
- 登录 发表评论
- 161 次浏览
Tags
最新内容
- 1 day 6 hours ago
- 2 weeks ago
- 3 weeks 1 day ago
- 3 weeks 5 days ago
- 2 months 1 week ago
- 6 months 1 week ago
- 6 months 1 week ago
- 6 months 1 week ago
- 6 months 1 week ago
- 6 months 1 week ago