
数据去识别是用于防止数据库中的个人身份或私人信息被泄露的过程。过程包括屏蔽个人标识符或用临时数据替换真实信息。通常,取消识别的数据会经过重新识别的过程以供进一步使用。
去标识是防丢失和数据控制总体实践的一部分,几乎每个行业都使用它来保护消费者数据,并提供对受保护健康信息的遵守,如HIPAA(健康保险便携性和责任法案)和许多其他隐私法案或用例。
去识别过程与云
企业数据持续呈指数级增长,向云数据湖的迁移已成为一大趋势,使大数据环境能够灵活无限制地扩展。随着越来越多的组织将云数据湖用于商业分析、机器学习和人工智能,特定的数据隐私保护挑战正在出现。
数据的爆炸导致了另一种趋势——在一些基于云的环境中,数据元素会被无意中暴露或配置错误。显然需要去识别云数据湖中的底层数据或原始数据,同时仍允许企业利用分析和人工智能建模等大数据技术。
在云提供商的“共享责任模式”中,提供商负责提供底层基础设施和数据中心的安全,而客户则负责将数据放入云中。因此,去标识意味着去标识实际的数据值或保护正在放入的底层数据值。
不幸的是,许多去标识技术需要额外的开发或更改数据管道,因此要么减缓基于云的分析的使用,要么让去标识的数据集暴露在外。此外,去标识只是挑战的一部分,因为访问和仓库数据的新方法可能会限制可能需要授权重新标识或分析数据的情况。
数据去标识的常用方法
- 以数据为中心的加密(Data-centric encryption),包括字段级别的加密/记录级别的加密-实际上通过某些形式的加密来保护特定的数据值。
- 数据标记化(Data tokenization),使用标记化库,或标记化,或所谓的无螺栓标记化,或者某种类型的代码簿方法,例如,用另一个值替换账号的方法。
- 格式保留加密(Format-preserving encryption)-数据类型和长度保留加密模式的另一种变体。社会保险号码、医疗记录号码、信用卡号码或电子邮件地址等数据将从格式化的角度进行保存,但根据实际的基础数据值进行随机化。
- 数据屏蔽(Data masking)-用于控制表示层,因此您可能只看到最后四位数字,而不是看到某人的完整信用卡号,或者值可能会完全混淆。
- 基于角色的数据屏蔽(Role-based data masking )–允许组织内的某些角色、处于更特权状态的某些方或可能是外部的第三方,但基本上,可以根据您的组成员身份动态呈现不同的数据视图。
- 高级加密方案(Advanced Encryption schemes)——包括基于飞地的加密,数据的安全性与移动设备上的指纹或人脸ID非常相似,扩展到服务器级计算模式、同态加密和多方计算。
Baffle的数据保护服务允许在飞行中轻松地取消数据识别,并通过无代码模型基于授权角色选择性地重新识别数据。
对象加密与以数据为中心的加密的优势
- 对对象和文件内部的数据进行去标识、标记化或加密。
- 安全港,防止关键隐私和合规法规的意外数据泄露。
- 通过解决关键的安全和隐私问题,加快基于云的数据分析程序。
Baffle允许您不断地将数据推送到云端,动态地对其进行去识别,然后允许组织成员运行他们需要在相应数据集上运行的分析类型,以最大限度地降低重新识别风险:
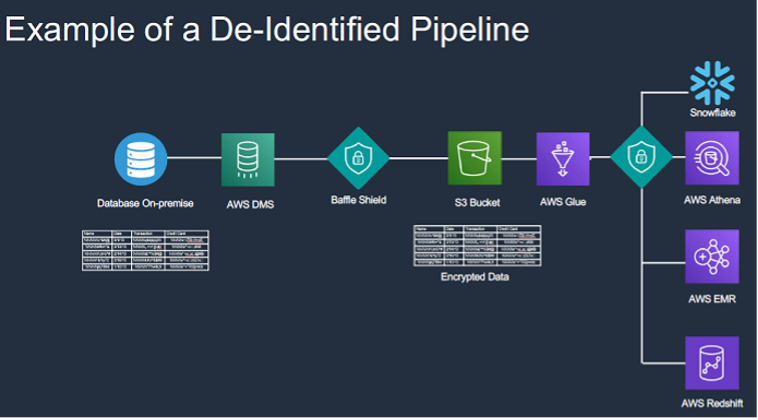
云数据湖为组织提供了更大的灵活性,以适应未来的大规模数据增长。数据泄露的风险仍然存在,但公司可以利用以数据为中心的保护方法和Baffle的解决方案来降低您的风险,释放数据的价值,并帮助将其货币化。
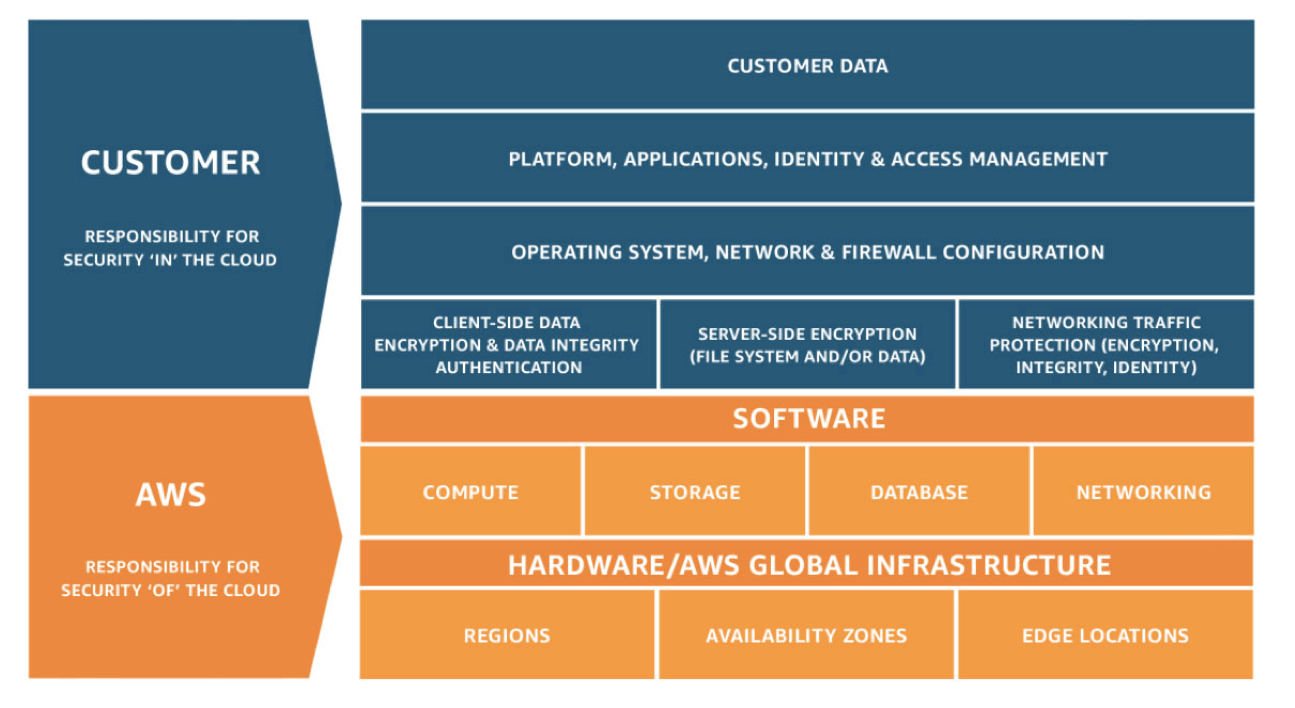
Shared Responsibility Model
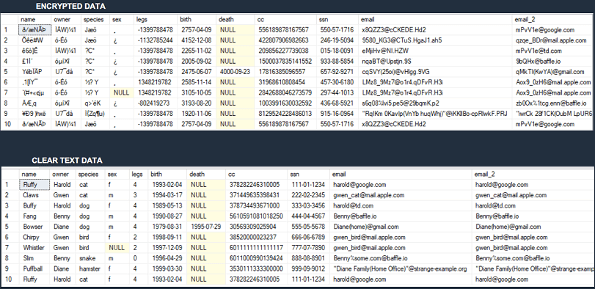
Sample De-Identification of Data vs Clear Text
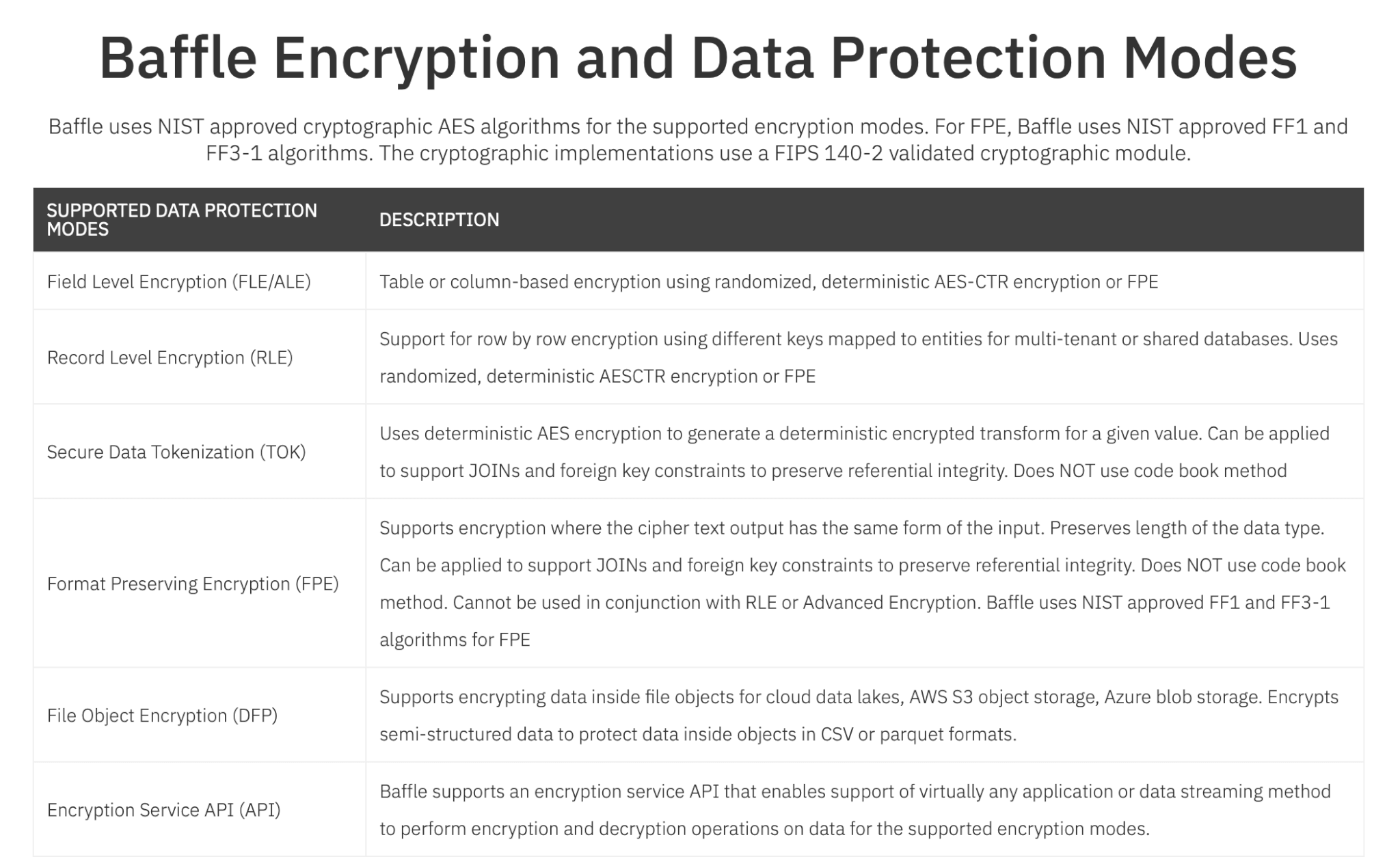
Baffle支持多种数据库和文件加密模式,包括NIST认证和FIPS验证的AES模式。
最新内容
- 1 week ago
- 1 week 4 days ago
- 1 month 4 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago