
AWS中为您提供的灾难恢复策略大致可分为四种方法,从低成本和低复杂性的备份到使用多个活动区域的更复杂的策略。主动/被动策略使用主动站点(如AWS区域)来承载工作负载和服务流量。被动站点(如不同的AWS区域)用于恢复。在触发故障切换事件之前,被动站点不会主动服务流量。
定期评估和测试您的灾难恢复策略至关重要,这样您就有信心在必要时调用它。使用AWS弹性中心持续验证和跟踪AWS工作负载的弹性,包括您是否可能达到RTO和RPO目标。

图6-灾难恢复策略
对于基于一个物理数据中心中断或丢失的灾难事件,对于架构良好、高可用的工作负载,您可能只需要一种备份和恢复方法来进行灾难恢复。如果您对灾难的定义超出了物理数据中心的中断或丢失范围,或者您受到了法规要求,那么您应该考虑Pilot Light、Warm Standby或Multi-Site Active/Active。
在选择您的策略和AWS资源来实现它时,请记住,在AWS中,我们通常将服务分为数据平面和控制平面。数据平面负责提供实时服务,而控制平面用于配置环境。为了实现最大的恢复能力,您应该在故障切换操作中仅使用数据平面操作。这是因为数据平面通常具有比控制平面更高的可用性设计目标。
备份和恢复
备份和恢复是防止数据丢失或损坏的合适方法。该方法还可用于通过将数据复制到其他AWS区域来减轻区域灾难,或减轻部署到单个可用性区域的工作负载的冗余。除了数据,您还必须在恢复区域中重新部署基础结构、配置和应用程序代码。为了使基础设施能够快速无误地重新部署,您应该始终使用AWS CloudFormation或AWS云开发工具包(AWS CDK)等服务,使用基础设施代码(IaC)进行部署。如果没有IaC,在恢复区域恢复工作负载可能会很复杂,这将导致恢复时间增加,并可能超过RTO。除了用户数据之外,请确保还备份代码和配置,包括用于创建AmazonEC2实例的AmazonMachineImages(AMI)。您可以使用AWS CodePipeline自动重新部署应用程序代码和配置。
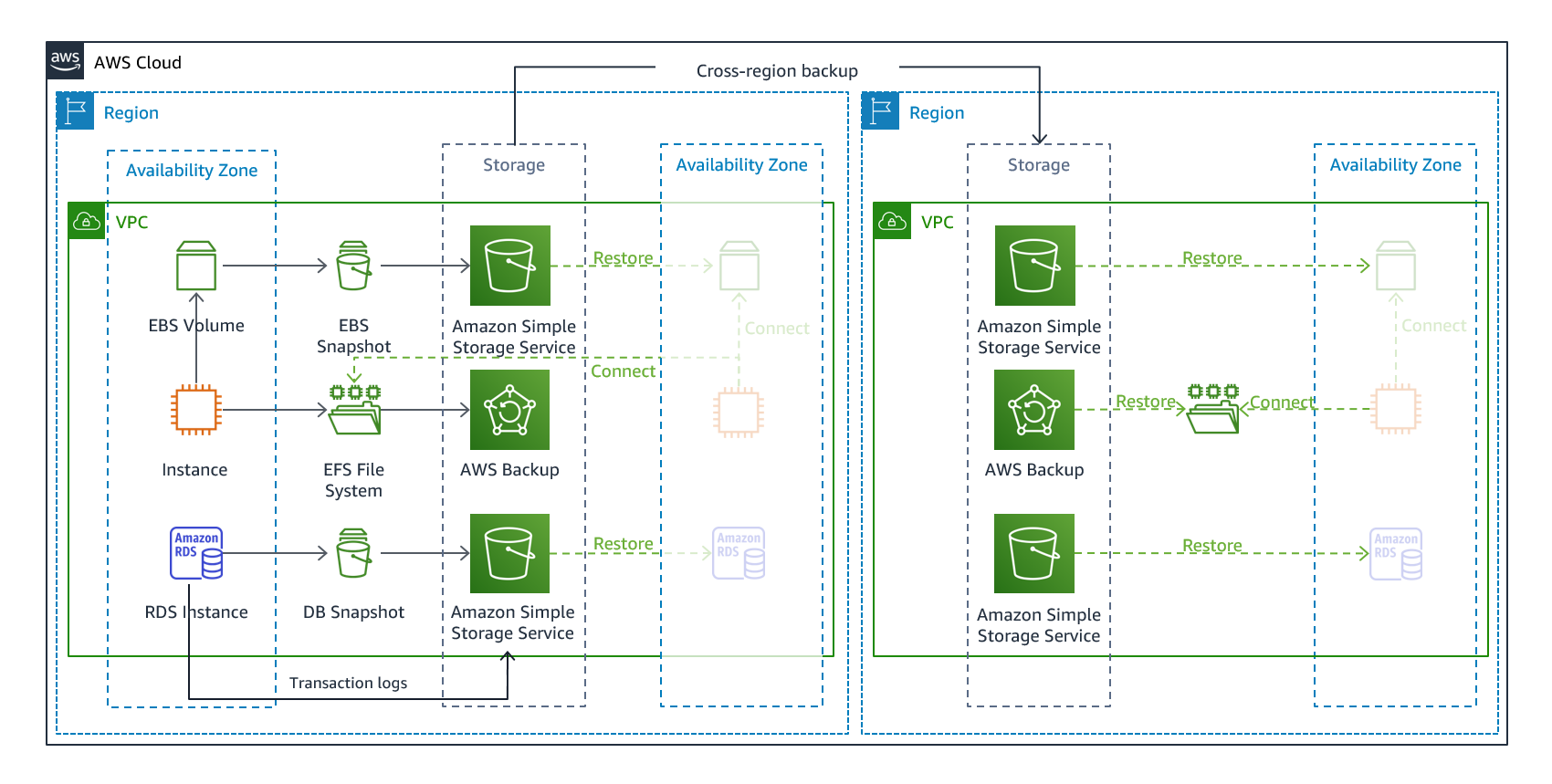
图7—备份和恢复架构
AWS服务
您的工作负载数据将需要定期或连续运行的备份策略。您运行备份的频率将决定您可实现的恢复点(该点应与RPO一致)。备份还应提供一种将其恢复到拍摄时间点的方法。通过以下服务和资源,可以使用带有时间点恢复的备份:
-
Amazon EFS backup (when using AWS Backup)
对于Amazon Simple Storage Service(Amazon S3),您可以使用Amazon S3跨区域复制(CRR)将对象连续异步复制到DR区域中的S3存储桶,同时为存储对象提供版本控制,以便您可以选择恢复点。数据的连续复制具有备份数据的最短时间(接近零)的优点,但可能无法防止数据损坏或恶意攻击(如未经授权的数据删除)等灾难事件以及时间点备份。AWS针对Pilot Light的服务部分介绍了连续复制。
AWS Backup为以下服务和资源提供了一个集中的位置来配置、调度和监控AWS备份功能:
-
Amazon EC2 instances
-
Amazon Relational Database Service (Amazon RDS) databases (including Amazon Aurora databases)
-
Amazon DynamoDB tables
-
Amazon Elastic File System (Amazon EFS) file systems
-
AWS Storage Gateway volumes
-
Amazon FSx for Windows File Server and Amazon FSx for Lustre
AWS Backup支持跨区域复制备份,例如复制到灾难恢复区域。
作为AmazonS3数据的额外灾难恢复策略,启用S3对象版本控制。对象版本控制通过在操作之前保留原始版本来保护S3中的数据免受删除或修改操作的影响。对象版本控制可以有效缓解人为错误类型的灾难。如果您使用S3复制将数据备份到DR区域,则默认情况下,在源存储桶中删除对象时,AmazonS3仅在源存储中添加删除标记。此方法可保护DR区域中的数据免受源区域中的恶意删除。
除了数据之外,您还必须备份重新部署工作负载和实现恢复时间目标(RTO)所需的配置和基础架构。AWS CloudFormation提供基础架构即代码(IaC),使您能够定义工作负载中的所有AWS资源,以便您能够可靠地部署和重新部署到多个AWS帐户和AWS地区。您可以将工作负载使用的AmazonEC2实例备份为AmazonMachineImages(AMI)。AMI是从实例的根卷和附加到实例的任何其他EBS卷的快照创建的。您可以使用此AMI启动EC2实例的恢复版本。AMI可以在区域内或跨区域复制。或者,您可以使用AWS Backup跨帐户和其他AWS地区复制备份。跨帐户备份功能有助于防止发生包括内部威胁或帐户泄露在内的灾难事件。除了实例的单独EBS卷之外,AWS Backup还为EC2备份添加了其他功能。AWS Backup还存储和跟踪以下元数据:实例类型、配置的虚拟私有云(VPC)、安全组、IAM角色、监控配置和标记。但是,此附加元数据仅在将EC2备份恢复到同一AWS区域时使用。
在故障切换时,必须恢复作为备份存储在灾难恢复区域中的任何数据。AWS Backup提供恢复功能,但当前不支持计划或自动恢复。您可以使用AWS SDK调用AWS Backup的API来实现DR区域的自动恢复。您可以将此设置为定期重复的作业,或在备份完成时触发还原。下图显示了使用亚马逊简单通知服务(Amazon SNS)和AWS Lambda进行自动恢复的示例。实施定时定期数据恢复是一个好主意,因为从备份恢复数据是一个控制平面操作。如果此操作在灾难期间不可用,您仍然可以从最近的备份中创建可操作的数据存储。

图8-恢复和测试备份
笔记
备份策略必须包括测试备份。有关更多信息,请参阅测试灾难恢复部分。请参阅AWS良好架构实验室:测试数据备份和恢复,以获得实施的实际演示。
指示灯
使用先导式方法,您可以将数据从一个地区复制到另一个地区,并提供核心工作负载基础架构的副本。支持数据复制和备份所需的资源(如数据库和对象存储)始终处于打开状态。其他元素(如应用程序服务器)加载有应用程序代码和配置,但“关闭”,仅在测试期间或调用灾难恢复故障切换时使用。在云中,您可以灵活地在不需要资源时取消资源配置,并在需要时进行资源调配。“关闭”的最佳做法是不部署资源,然后创建配置和功能,以便在需要时部署资源(“打开”)。与备份和恢复方法不同,您的核心基础架构始终可用,您始终可以选择通过打开和扩展应用程序服务器来快速调配一个完整的生产环境。
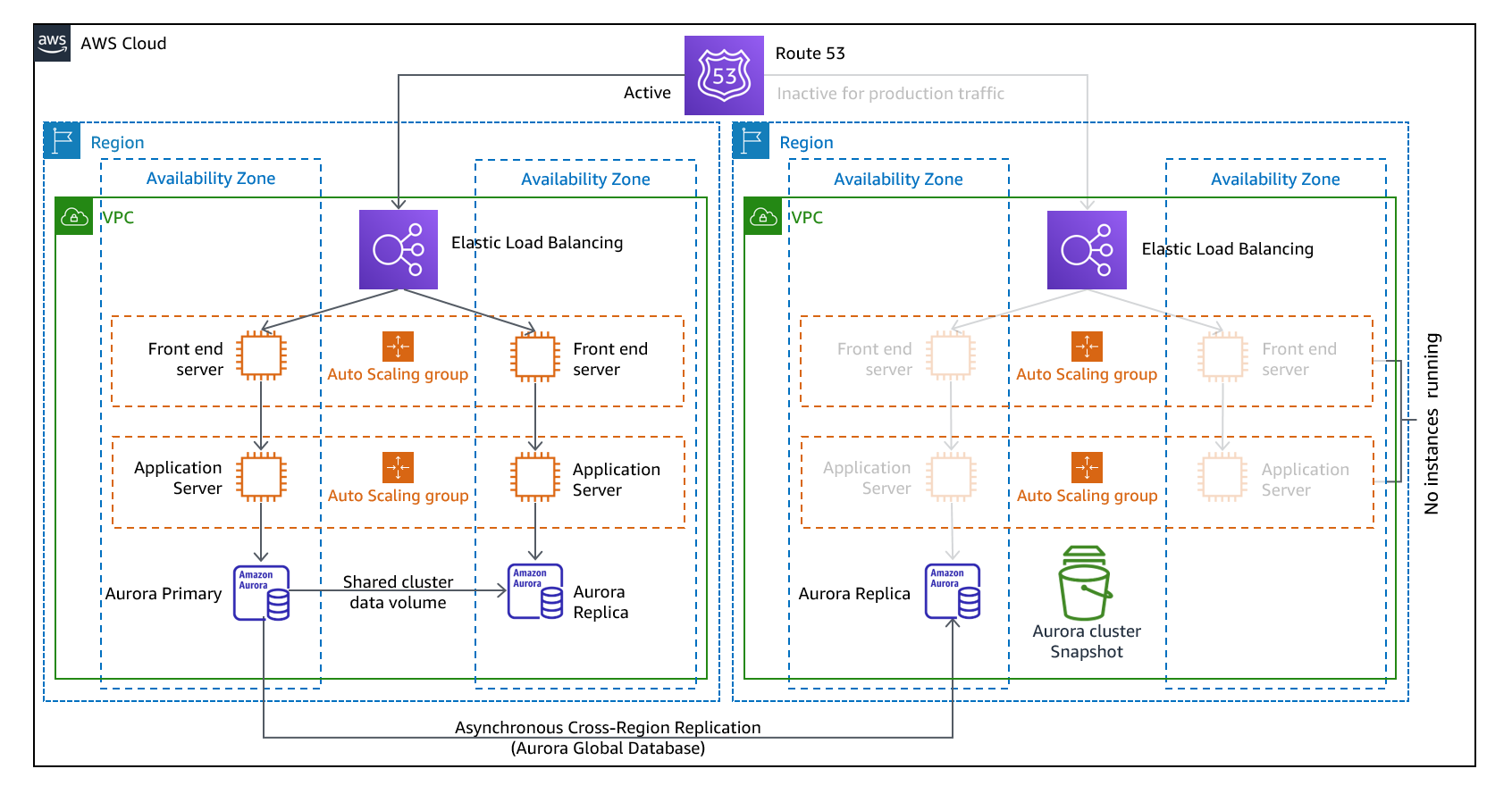
图9-指示灯架构
一种试验性的方法通过最大限度地减少活动资源,最大限度地降低了灾难恢复的持续成本,并简化了灾难发生时的恢复,因为核心基础架构要求都已到位。此恢复选项要求您更改部署方法。您需要对每个区域进行核心基础架构更改,并同时将工作负载(配置、代码)更改部署到每个区域。通过自动化部署并使用基础架构代码(IaC)跨多个客户和地区部署基础架构(将基础架构完全部署到主要地区,并将基础架构部署缩减/关闭到灾难恢复地区),可以简化此步骤。建议您为每个区域使用不同的帐户,以提供最高级别的资源和安全隔离(在这种情况下,受损的凭据也是灾难恢复计划的一部分)。
使用这种方法,您还必须减轻数据灾难。连续数据复制可保护您免受某些类型的灾难,但它可能无法保护您免受数据损坏或破坏,除非您的策略还包括存储数据的版本控制或时间点恢复选项。您可以备份灾难区域中的复制数据,以在同一区域中创建时间点备份。
AWS服务
除了使用“备份和恢复”部分中介绍的AWS服务创建时间点备份外,还应考虑以下服务用于您的试点战略。
对于试点而言,向灾难恢复区域中的实时数据库和数据存储进行连续数据复制是实现低RPO的最佳方法(当与前面讨论的时间点备份一起使用时)。AWS使用以下服务和资源为数据提供连续、跨区域、异步数据复制:
通过连续复制,您的数据版本几乎可以立即在您的灾难恢复地区获得。可以使用S3对象的S3复制时间控制(S3 RTC)等服务功能和Amazon Aurora全局数据库的管理功能来监控实际复制时间。
在故障转移以从灾难恢复区域运行读/写工作负载时,必须将RDS读副本升级为主实例。对于Aurora以外的DB实例,该过程需要几分钟才能完成,重新启动是该过程的一部分。对于跨区域复制(CRR)和RDS故障切换,使用Amazon Aurora全局数据库提供了几个优点。全局数据库使用专用基础设施,使您的数据库完全可用于服务您的应用程序,并且可以复制到辅助区域,典型的延迟不到一秒(在AWS区域内的延迟远小于100毫秒)。使用AmazonAurora全球数据库,如果您的主要区域出现性能下降或中断,即使在完全区域中断的情况下,您也可以在不到一分钟的时间内促使其中一个次要区域承担读/写责任。您还可以将Aurora配置为监视所有辅助群集的RPO延迟时间,以确保至少有一个辅助群集保持在目标RPO窗口内。
必须在灾难恢复地区部署资源更少或更少的核心工作负载基础架构的缩减版本。使用AWS CloudFormation,您可以定义您的基础架构,并在AWS客户和AWS地区一致地部署它。AWS CloudFormation使用预定义的伪参数来识别AWS帐户及其部署的AWS区域。因此,您可以在CloudFormation模板中实现条件逻辑,以便在DR Region中仅部署缩减版本的基础设施。对于EC2实例部署,AmazonMachineImage(AMI)提供硬件配置和已安装软件等信息。您可以实施Image Builder管道来创建所需的AMI,并将其复制到主区域和备份区域。这有助于确保这些黄金AMI具备在发生灾难事件时在新区域重新部署或扩展工作负载所需的一切。AmazonEC2实例以缩减配置部署(比您的主要区域中的实例更少)。要扩展基础设施以支持生产流量,请参阅“热待机”部分的AWS自动缩放。
对于主动/被动配置(如指示灯),所有流量最初都会流向主区域,如果主区域不再可用,则会切换到灾难恢复区域。此故障切换操作可以自动或手动启动。应谨慎使用基于运行状况检查或警报的自动启动故障切换。即使使用这里讨论的最佳做法,恢复时间和恢复点也将大于零,从而导致一些可用性和数据损失。如果你在不需要的时候失败了(虚惊一场),那么你就会遭受这些损失。因此,通常使用手动启动的故障切换。在这种情况下,您仍然应该自动执行故障切换步骤,这样手动启动就像按下按钮一样。
在使用AWS服务时,需要考虑几个流量管理选项。
一种选择是使用亚马逊路线53。使用Amazon Route 53,您可以将一个或多个AWS区域中的多个IP端点与Route 53域名相关联。然后,您可以将流量路由到该域名下的适当端点。在故障切换时,您需要将流量切换到恢复端点,而不是主端点。Amazon Route 53健康检查监控这些端点。使用这些健康检查,您可以配置自动启动的DNS故障切换,以确保流量仅发送到健康的端点,这是在数据平面上执行的高度可靠的操作。要使用手动启动的故障切换实现这一点,您可以使用Amazon Route 53 Application Recovery Controller。使用路线53 ARC,您可以创建路线53健康检查,这些检查实际上不检查健康状况,而是充当您完全控制的开关。使用AWS CLI或AWS SDK,可以使用此高度可用的数据平面API编写故障切换脚本。脚本切换这些开关(路由53健康检查),告诉路由53将流量发送到恢复区域而不是主区域。一些人使用的手动启动故障切换的另一个选项是使用加权路由策略,并更改主区域和恢复区域的权重,以便所有流量都流向恢复区域。然而,请注意,这是一种控制平面操作,因此不如使用Amazon Route 53 Application Recovery Controller的数据平面方法具有弹性。
另一种选择是使用AWS全球加速器。使用AnyCast IP,您可以将一个或多个AWS区域中的多个端点与相同的静态公共IP地址相关联。AWS Global Accelerator然后将流量路由到与该地址相关联的适当端点。全局加速器运行状况检查监视终结点。使用这些健康检查,AWS Global Accelerator可以检查应用程序的健康状况,并将用户流量自动路由到健康的应用程序端点。对于手动启动的故障切换,您可以使用流量拨号调整哪个端点接收流量,但请注意,这是一个控制平面操作。Global Accelerator为应用程序端点提供了较低的延迟,因为它利用了广泛的AWS边缘网络尽快将流量传输到AWS网络主干。Global Accelerator还避免了DNS系统(如路由53)可能出现的缓存问题。
AmazonCloudFront提供源故障切换,如果向主要端点发出的给定请求失败,CloudFront会将请求路由到次要端点。与前面描述的故障切换操作不同,所有后续请求仍将转到主端点,并且每个请求都会执行故障切换。
AWS弹性灾难恢复
AWS弹性灾难恢复(DRS)使用底层服务器的块级复制将服务器托管的应用程序和服务器托管的数据库从任何源连续复制到AWS中。弹性灾难恢复使您能够将AWS云中的某个区域用作托管在本地或其他云提供商及其环境中的工作负载的灾难恢复目标。如果AWS托管的工作负载仅包含托管在EC2上的应用程序和数据库(即,不是RDS),那么它也可以用于AWS托管工作负载的灾难恢复。弹性灾难恢复使用Pilot Light策略,在用作中转区域的Amazon虚拟私有云(Amazon VPC)中维护数据副本和“关闭”资源。当触发故障切换事件时,将使用分段资源在用作恢复位置的目标Amazon VPC中自动创建全容量部署。
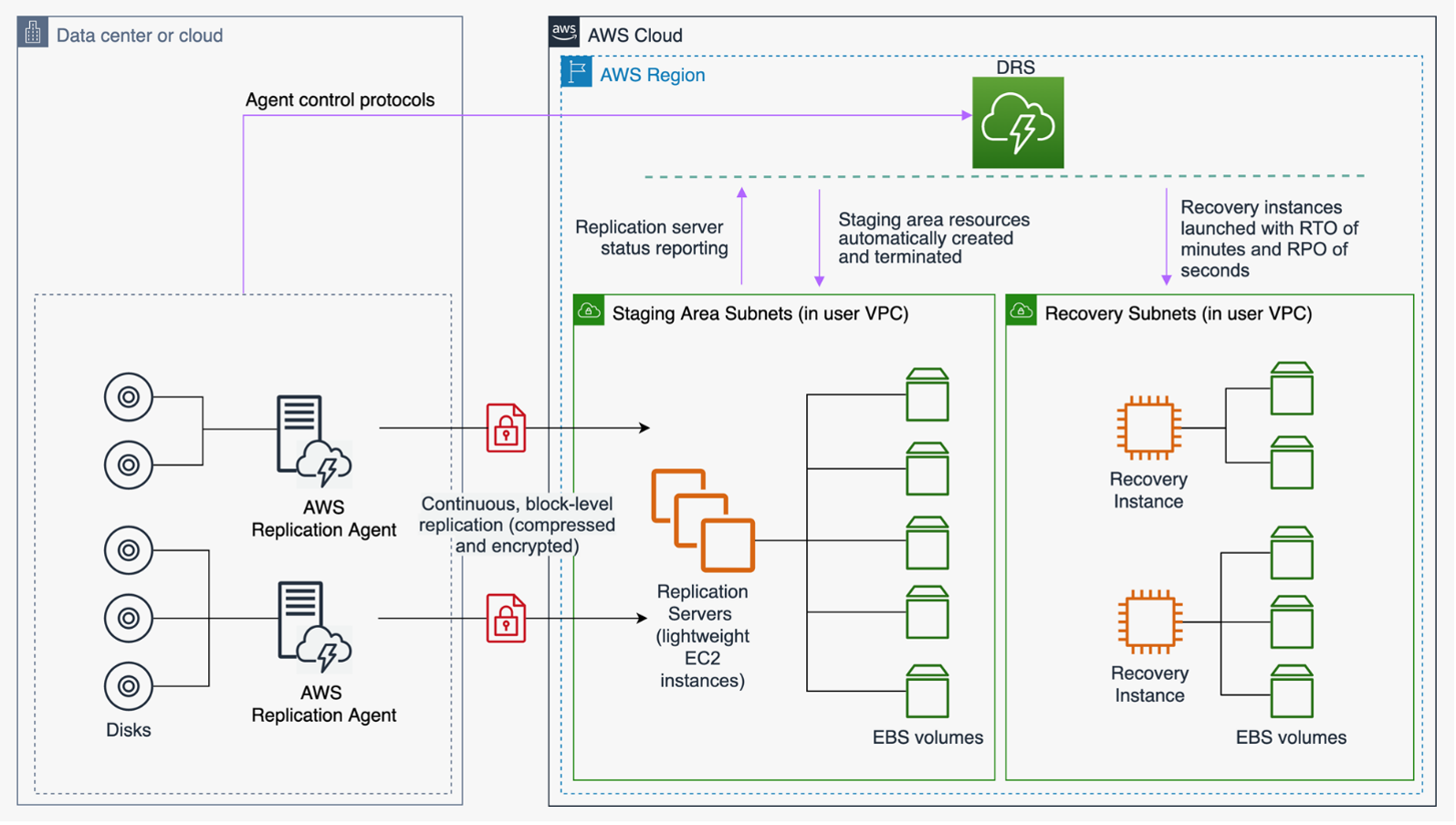
图10-AWS弹性灾难恢复架构
热备用
热备用方法包括确保在另一个地区有一个规模缩小但功能齐全的生产环境副本。这种方法扩展了先导灯的概念,并减少了恢复时间,因为您的工作负载总是在另一个区域运行。这种方法还允许您更轻松地执行测试或实施连续测试,以增强对灾难恢复能力的信心。
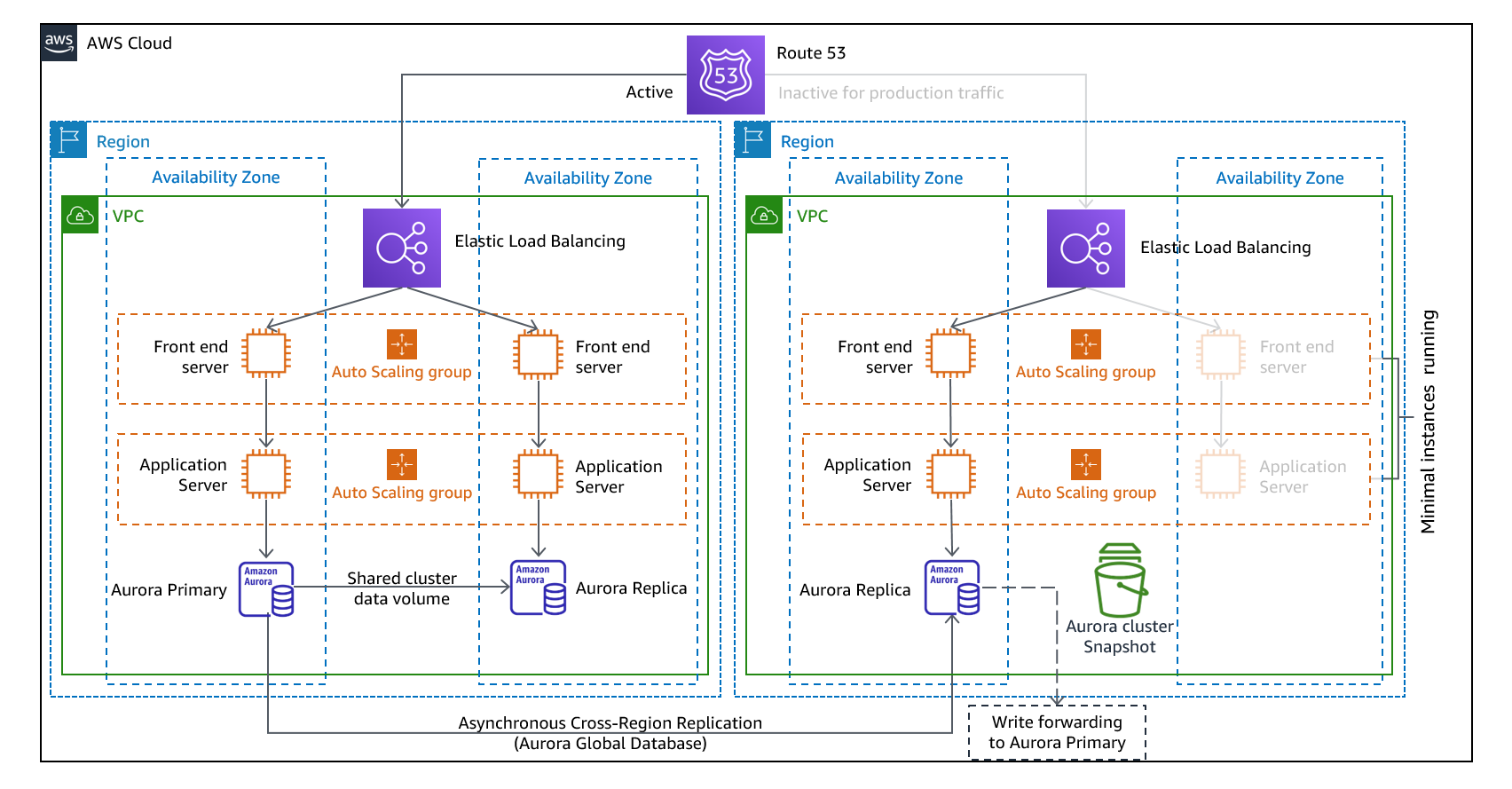
图11-热备用架构
注意:有时很难理解指示灯和热备用灯之间的区别。两者都包括DR区域中的一个环境,其中包含主要区域资产的副本。区别在于,如果不首先采取额外的行动,引导灯无法处理请求,而热待机可以立即处理流量(在容量降低的情况下)。轻试点方法要求您“打开”服务器,可能部署额外的(非核心)基础设施,并进行扩展,而热备份只要求您进行扩展(所有内容都已部署并运行)。使用您的RTO和RPO需求帮助您在这些方法之间进行选择。
AWS服务
备份和恢复以及指示灯下涵盖的所有AWS服务也用于数据备份、数据复制、主动/被动流量路由以及包括EC2实例在内的基础设施部署的热备份。
AWS自动缩放用于缩放AWS区域内的资源,包括Amazon EC2实例、Amazon ECS任务、Amazon DynamoDB吞吐量和Amazon Aurora副本。Amazon EC2 Auto Scaling可在AWS区域内的可用性区域内扩展EC2实例的部署,从而在该区域内提供弹性。使用Auto Scaling(自动缩放)将DR Region(灾难恢复区域)扩展到完全生产能力,作为试点轻待机或热待机策略的一部分。例如,对于EC2,增加自动缩放组上的所需容量设置。您可以通过AWS管理控制台手动调整此设置,也可以通过AWS SDK自动调整,或者使用新的所需容量值重新部署AWS CloudFormation模板。您可以使用AWS CloudFormation参数来简化CloudFormation模板的重新部署。确保DR地区的服务配额设置得足够高,以免限制您扩展到生产能力。
因为自动缩放是一种控制平面活动,因此依赖它会降低整体恢复策略的弹性。这是一种权衡。您可以选择调配足够的容量,以便恢复区域能够处理部署的全部生产负载。这种静态稳定的配置称为热备用(见下一节)。或者,您可以选择提供更少的资源,这将降低成本,但依赖于自动缩放。一些灾难恢复实施将部署足够的资源来处理初始流量,确保较低的RTO,然后依靠自动缩放来提高后续流量。
多站点活动/活动
作为多站点主动/主动(multi-site active/active )或热备用主动/被动(hot standby active/passive )策略的一部分,您可以在多个区域同时运行工作负载。多站点活动/活动服务于来自其部署到的所有区域的流量,而热备用服务仅服务于单个区域的流量。其他区域仅用于灾难恢复。通过多站点主动/主动方法,用户可以访问部署工作负载的任何地区的工作负载。这种方法是灾难恢复中最复杂、成本最高的方法,但它可以通过正确的技术选择和实施将大多数灾难的恢复时间缩短到接近零(但是数据损坏可能需要依赖备份,这通常会导致非零恢复点)。热备用使用主动/被动配置,其中用户仅定向到单个区域,灾难恢复区域不占用流量。大多数客户发现,如果他们要在第二个地区建立一个完整的环境,那么使用它是有意义的。或者,如果您不想同时使用这两个区域来处理用户流量,那么“热备用”提供了一种更经济、操作更简单的方法。
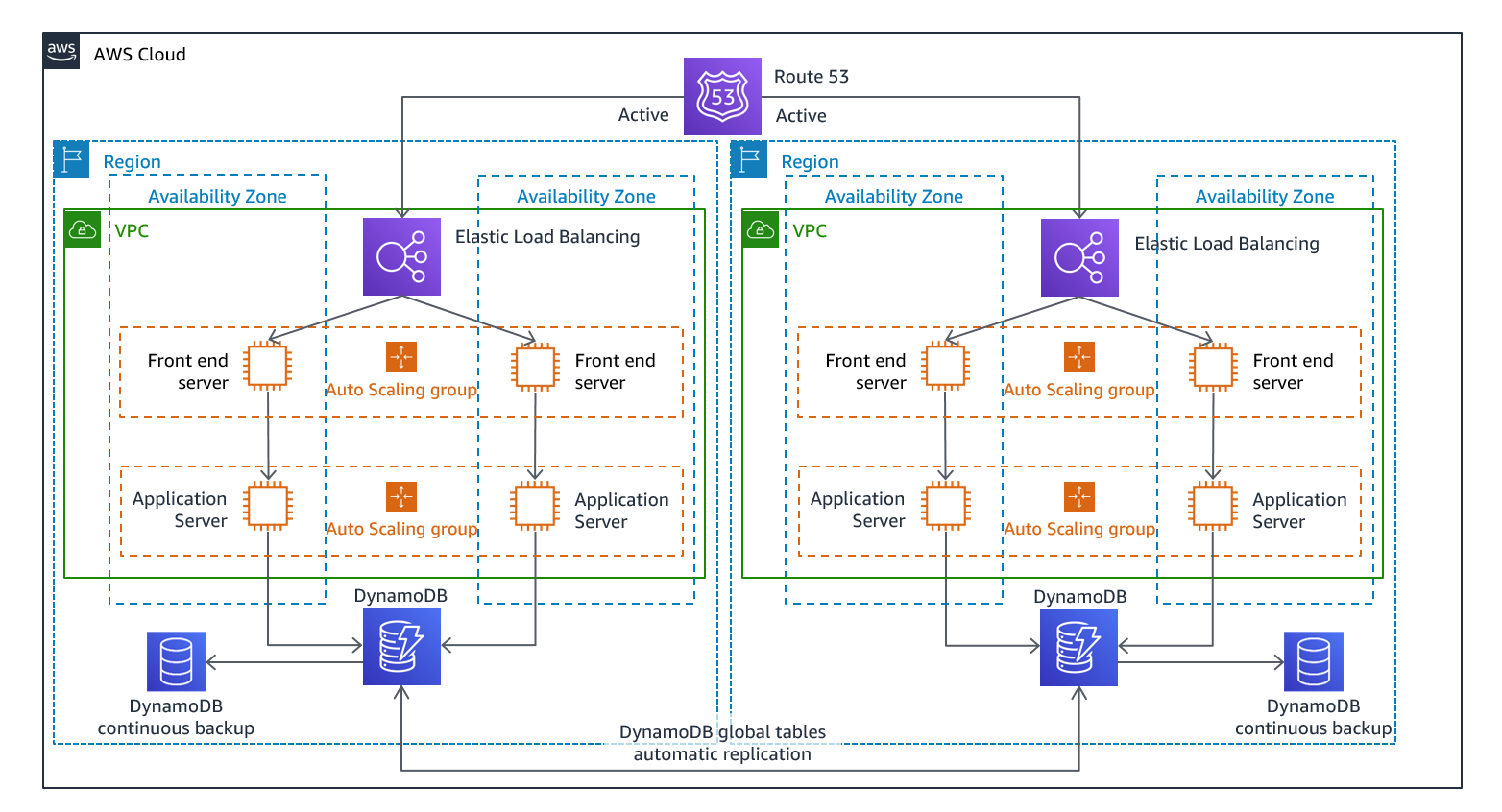
图12-多站点主动/主动架构(将一个主动路径更改为非主动以实现热备用)
对于多站点活动/活动,因为工作负载在多个区域中运行,所以在这种情况下不存在故障切换。在这种情况下,灾难恢复测试将重点关注工作负载对区域丢失的反应:流量是否从故障区域转移?其他地区能否处理所有交通?还需要测试数据灾难。备份和恢复仍然是必需的,应定期进行测试。还应注意,涉及数据损坏、删除或混淆的数据灾难的恢复时间始终大于零,并且恢复点始终位于发现灾难之前的某个点。如果需要多站点主动/主动(或热备用)方法的额外复杂性和成本来保持接近零的恢复时间,则应进一步努力维护安全并防止人为错误,以减轻人为灾难。
AWS服务
备份和恢复、指示灯和热备份中涵盖的所有AWS服务也在这里用于时间点数据备份、数据复制、主动/主动流量路由以及基础架构(包括EC2实例)的部署和扩展。
对于前面讨论的主动/被动场景(引燃灯和热备用),Amazon Route 53和AWS Global Accelerator均可用于将网络流量路由到主动区域。对于这里的主动/主动策略,这两个服务还支持定义策略,以确定哪些用户将转到哪个活动区域端点。使用AWS Global Accelerator,您可以设置流量拨号,以控制指向每个应用程序端点的流量百分比。Amazon Route 53支持这种百分比方法,也支持多种其他可用策略,包括地理接近和基于延迟的策略。Global Accelerator自动利用AWS边缘服务器的广泛网络,尽快向AWS网络主干传输流量,从而降低请求延迟。
使用此策略的异步数据复制实现了接近零的RPO。AWS服务(如Amazon Aurora全球数据库)使用专用基础设施,使您的数据库完全可用于服务您的应用程序,并且可以复制到多达五个辅助区域,典型的延迟不到一秒钟。对于主动/被动策略,写入仅发生在主区域。活动/活动的区别在于设计如何处理写入每个活动区域的数据一致性。通常将用户阅读设计为从Region壁橱提供给他们,称为本地阅读。对于写入,您有几个选项:
写入全局策略将所有写入路由到单个区域。如果该区域失败,将提升另一个区域接受写入。Aurora全局数据库非常适合写入全局数据库,因为它支持跨区域的读副本同步,并且您可以在不到一分钟的时间内将其中一个辅助区域提升为承担读/写职责。Aurora还支持写转发,这允许Aurora全局数据库中的辅助集群将执行写操作的SQL语句转发到主集群。
写入本地策略将写入路由到最近的区域(就像读取一样)。AmazonDynamoDB全局表支持这样一种策略,允许从部署全局表的每个区域进行读写。AmazonDynamo DB全局表使用最后一个写入器,从而在并发更新之间实现协调。
写分区策略根据分区键(如用户ID)向特定区域分配写操作,以避免写冲突。双向配置的AmazonS3复制可用于这种情况,目前支持两个区域之间的复制。在实现此方法时,请确保在存储桶A和B上启用复制副本修改同步,以复制复制副本元数据更改,如复制对象上的对象访问控制列表(ACL)、对象标记或对象锁。您还可以配置是否在活动区域中的存储桶之间复制删除标记。除了复制,您的策略还必须包括时间点备份,以防止数据损坏或破坏事件。
AWS CloudFormation是一个强大的工具,可以在多个AWS地区的AWS客户之间实施一致部署的基础设施。AWS CloudFormation StackSet扩展了此功能,使您能够通过单个操作跨多个帐户和地区创建、更新或删除CloudFormation堆栈。尽管AWS CloudFormation使用YAML或JSON将基础设施定义为代码,但AWS云开发工具包(AWS CDK)允许您使用熟悉的编程语言将基础设施界定为代码。您的代码被转换为CloudFormation,然后用于在AWS中部署资源。
- 登录 发表评论
- 206 次浏览
最新内容
- 1 week ago
- 2 weeks 1 day ago
- 2 weeks 5 days ago
- 2 months ago
- 6 months ago
- 6 months ago
- 6 months ago
- 6 months ago
- 6 months ago
- 6 months ago