
随着生成人工智能进入企业,一家由前谷歌员工创立的公司旨在超越微软支持的OpenAI。
OpenAI刚刚宣布了其流行的生成型人工智能产品ChatGPT的企业版。但在这种情况下,OpenAI是一个快速的追随者,而不是第一个进入市场的人。Cohere是一家总部位于多伦多的公司,与谷歌关系密切,已经在为企业带来生成性人工智能。
我与Cohere的总裁兼首席运营官Martin Kon就其机器学习模型如何在企业公司中使用进行了交谈。
Cohere只有几岁,但它有着令人印象深刻的血统。Cohere的两位创始人最近曾在谷歌大脑工作,这引发了当前围绕生成人工智能的热潮。2017年,谷歌大脑推出了自然语言处理(NLP)的“转换器”模型,即ChatGPT中的“T”。Cohere的首席执行官和首席技术官Aidan Gomez和Nick Frosst随后与Ivan Zhang合作,在Cohere将这种形式的NLP商业化。
Martin Kon上个月刚开始工作,对公司来说是全新的。但和创始人一样,他也与谷歌有联系,在加入Cohere之前,他在YouTube工作了六年。他被任命为Cohere的商业运营部门负责人,业务似乎正在蓬勃发展。
据Kon称,Cohere“在过去一年中,API调用量月环比增长了65%,开发人员数量也大致相同。”

现在,Cohere已经将重点转移到将其大型语言模型和相关工具引入企业。
Kon说:“我们正在与组织中的开发人员,即AI/ML团队合作,将这些能力引入他们的组织。”。他声称,它的方法与OpenAI的方法有根本不同。
“OpenAI希望您将您的数据带到他们的模型中,这是Azure独有的。Cohere希望在您感到舒适的任何环境中,将我们的模型带到您的数据中。”
Cohere与OpenAI的技术比较
Cohere有两种类型的LLM(大型语言模型):生成和表示。前者是ChatGPT所做的,后者是为了理解语言(例如,做情感分析)。每种类型都有不同的尺寸:小、中、大和超大。模型的大小和工作速度之间存在各种权衡。
Cohere的基础模型有520亿个参数,基于斯坦福HELM排名(语言模型的整体评估)。斯坦福大学的HELM网站指出,这是Cohere模型的“xlarge”版本,是最大的版本。OpenAI的GPT-3 davinci模型是其最大的模型,被斯坦福大学列为具有175B个参数。
斯坦福HELM目录中的Cohere模型列表
 The primary models of OpenAI
The primary models of OpenAI
在我们的谈话中,Kon说Cohere的模型被证明可以更好地对抗GPT-3。我要求该公司对此进行验证,该公司向我指出了斯坦福大学的准确性测量结果。根据Cohere的说法,“研究表明,Cohere-xlarge模型比许多大3倍的知名模型实现了更高的精度,包括GPT-3、Jurasci-1 Jumbo和BLOOM(每个模型都有大约175B的参数)。”
然而,需要注意的是,Cohere的模型仅领先于GPT-3模型。OpenAI最新的GPT-3.5模型text-davinci-002和text-davicini-003的准确度都高于Cohere。事实上,根据HELM精度测量,这些模型目前在所有模型中排名最高(见下文)。
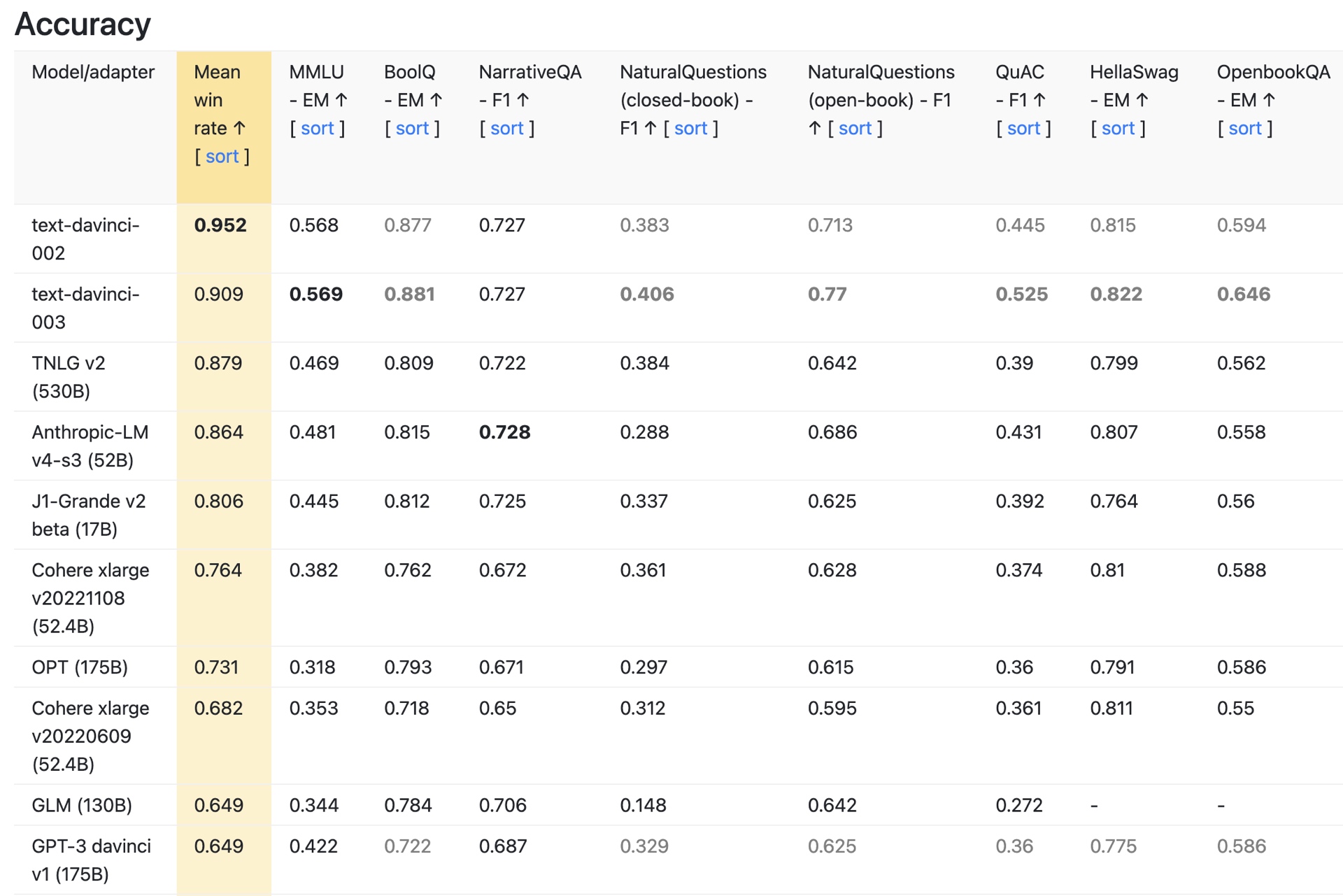 Stanford HELM tests for accuracy of ML models
Stanford HELM tests for accuracy of ML models
Kon告诉我,Cohere的最新型号Command(目前处于测试版)每周都会重新调整。他说:“这意味着,每周你都可以期待指挥性能的提高。”。
根据文件,Command是“一个生成模型,可以很好地响应类似指令的提示。”作为比较点,Davinci被OpenAI描述为擅长“复杂的意图、因果关系、对受众的总结”
企业使用案例
生成人工智能最早的用例是基于内容生成和摘要的——Stable Diffusion的图像生成器、ChatGPT的会话搜索引擎、GitHub的Copilot代码生成器等等。但我问Kon,它的技术还有哪些其他用例,尤其是对企业公司来说。
语义搜索引擎
他说,首先,公司正在使用它为自己的私人数据创建一种语义搜索引擎。
Kon说:“将语义搜索(上下文搜索)引入私人环境,比如组织内部的信息,这与我们习惯于谷歌搜索的方式类似。”。“因此,这使公司,尤其是跨国公司,能够在其内部拥有的每一份材料中搜索、分类或寻找情感——每一份文件、每一份客户通话记录、每一段视频聊天记录、电子邮件、文件等。”
他解释说,一个组织通常会将自己的数据添加到Cohere的一个基本模型中。他说,这将是“数量少得多、质量高得多的数据,通常是人类注释的强化学习”(这里的“较小”只是指与基础模型中的数十亿个参数相比)。除此之外,还有一个“对话”层,或者像ChatGPT这样的对话层。Cohere的对话模式处于内部测试阶段,他补充道。
数据分析
我早些时候问过大型零售商的示例用例是什么,Kon在这里回答了这个问题。
“假设你是一名零售商,你想[问]我们在玻利维亚的业务进展如何?然后[人工智能]可以说,这是从西班牙语或其他语言中提取的最新销售结果。不,[你说],我指的是批发业务。好吧,[它回答]让我从其他地方提取一些不同的东西。所以你基本上是在进行对话。你正在访问以一种非常安全的方式[这些数据],因为外部没有人能看到它——你没有把它输入ChatGPT,这是每个人都在做的事情。”
客服对话
他给我举了几个其他的例子,其中一个是从零售商客户的角度来看的。假设你买了一台电视,想退货;你可以与零售商的人工智能进行对话,实时查看当前的退货政策。
谷歌合作伙伴
运行机器学习工作负载,尤其是那些具有数十亿参数的工作负载,是极其耗费硬件的。所以我问Kon Cohere是如何处理的——他们主要是内部硬件,还是与任何平台公司合作?
毫不奇怪,考虑到创始人和孔本人的背景,Cohere与谷歌在硬件方面进行了合作。
“我们现在与谷歌有着战略关系,”孔说。“所以我相信我们是TPU(Tensor处理单元)的第一个消费者,也是最大的消费者除了谷歌本身。因此,我们有机会获得并能够负担得起这些巨大的计算资源,这些资源是我们需要预先培训的。这些模型需要四到六周的时间来训练——基本模型。我们的命令模型,我们可以每晚都做,因为这是一个小得多的数据量——但实际上是特定的数据——所以我们每周都做这些,但训练大约需要一个晚上。”
当然,谷歌本身也参与了人工智能的生成游戏。它有几个命名模糊的ML型号:T5、UL2、Flan-T5和PaLM。因此,就像云计算平台一样,企业人工智能市场正在转变为“马换课程”的局面。一些企业客户将是微软商店,因此可能倾向于OpenAI。其他将是谷歌云的客户。但许多人不想被束缚在一个单一的云平台上,而这正是Cohere最吸引人的地方。
显然,企业公司有巨大的机会通过生成人工智能技术超越竞争对手。至于生成人工智能的提供商,包括Cohere和OpenAI,我想不出今年有什么比这更令人兴奋的企业IT类别了。游戏开始了!