
5实验评价
为了评估所提出的框架的有效性,我们在第3节中描述的文本语料库上进行了一系列实验。
5.1评价目标
这项实验研究的主要目的是探索如何有效地将INTREPID作为一种基于人工智能的工具来验证用意大利语编写的PA文件的GDPR合规性。为此,我们评估了如何使用SpaCy和Tint的NER模型来准确定位和分类所考虑的文本语料库中的命名实体。我们研究了基于BoW的特征和基于NER的特征对SVM准确性的影响,SVM被训练来验证文本语料库的GDPR合规性。具体而言,我们打算回答以下问题:
- 问题1:通过改变NER模型,即SpaCy模型和Tint模型,NER阶段的准确性如何变化?(第5.3.1节)
- 问题2:文本预处理操作的使用(即变位、停止语删除、小写转换)如何改变基于BoW的特征产生的GDPR合规性预测的准确性?(第5.3.2节)
- 问题3:每个基于净入学率的特征组如何对GDPR合规性预测的准确性做出贡献?(第5.3.3节)
- 问题4:INTREPID是否比其分别考虑基于BoW的功能或基于NER的功能的基线框架更强大?(第5.3.4节)
作为基线框架,我们考虑了BoW和NER,它们分别从基于BoW的特征和基于NER的特征中训练分类器。我们评估了用SVM、RF和XGBoost训练的分类器的性能。
5.2评价方法和评价标准
我们通过计算用SpaCy和Tint识别和分类的命名实体的Precision、Recall和F分数,测量了NER模型在匿名文本语料库上的性能。对于这两种NER工具,我们考虑了第4.2节中所述的经过预训练的NER模型。这三个指标用于评估NER工具对特定实体类别i的预测能力。实体类别i上的F分越高,NER工具在i上实现的精度和召回率之间的平衡就越好。相反,当一个指标以牺牲另一个指标为代价进行改进时,F分就不那么高。此外,我们通过计算MacroF来测量NER工具的总体性能,即,
MacroF=1k∑i=1kFi.
这是一个标准的多类度量,通常用于评估多类分类模型的整体预测能力。它测量每个命名实体类别i的平均F分数。注意,在MacroF的计算中,我们给每个实体类别赋予相等的权重。通过这种方式,我们避免了我们的评估抵消了实体设置不平衡可能带来的影响。
类似地,我们通过计算文档预测的F分来测量为验证公共文档的GDPR合规性而训练的分类器的性能。我们评估了通过分类算法(SVM、RF和XGBoost)训练的分类器的性能,方法是根据留一交叉验证对训练和测试文档中的匿名文本语料库进行划分(Hastie et al.,2001)。对于每个试验,我们在训练集上训练了比较方法的分类器(89次折叠),并评估了它们在测试集的文档上预测GDPR合规性的能力(保持折叠)。我们计算了所有90项测试试验得出的GDPR合规性预测的F分。
5.3结果
在本节中,我们将说明评估研究中收集的实验结果如何使我们能够解决所提出的研究问题。
5.3.1净入学率分析(Q1)
我们开始分析Tint和SpaCy在标记命名实体时的准确性性能。我们将两个NLP管道提供的输出与语料库中专家提供的注释进行比较。特别是,我们使用两种方法比较了两种NER工具的性能:
精确:如果开始偏移和结束偏移都等于注释中相应的偏移,则输出是正确的;
OVERLAP:如果其跨度与注释的跨度重叠,则输出是正确的。
表4和表5报告了精确度、召回率和F分数,分别用EXACT和OVERLAP为每个实体类别计算。使用精确匹配(表4)计算的结果非常低,特别是对于SpaCy。这些结果是意料之中的,因为NLP工具最初是在一个完全不同的领域上训练的。此外,所考虑的领域非常具体。另一方面,如果我们考虑OVERLAP方法,我们会获得更好的结果(表5)。在任何情况下,无论采用何种方法,Tint都能获得比SpaCy更好的结果。最后,查看每个实体类别的结果,我们可以注意到AMM、LOC和ORG是最难识别的类别,而这两个工具在PER、MED和OM上都实现了更好的性能。
Table 4 NER accuracy results using EXACT match
From: An AI framework to support decisions on GDPR compliance
|
Category |
Tint |
SpaCy |
||||
|---|---|---|---|---|---|---|
|
Precision |
Recall |
F |
Precision |
Recall |
F |
|
|
AMM |
0.6196 |
0.1237 |
0.2062 |
0.5892 |
0.0993 |
0.1700 |
|
LOC |
0.2368 |
0.6750 |
0.3506 |
0.0456 |
0.6000 |
0.0847 |
|
ORG |
0.2652 |
0.2085 |
0.2335 |
0.0926 |
0.0651 |
0.0765 |
|
PER |
0.6862 |
0.6450 |
0.6649 |
0.3069 |
0.3875 |
0.3425 |
|
MED |
0.7351 |
0.6793 |
0.7061 |
0.8222 |
0.6319 |
0.7146 |
|
OM |
0.9902 |
0.9712 |
0.9806 |
0.9894 |
0.8942 |
0.9394 |
|
macroF |
0.5237 |
0.3880 |
||||
- The best MacroF is underlined
Table 5 NER accuracy results using OVERLAP
From: An AI framework to support decisions on GDPR compliance
|
Category |
Tint |
SpaCy |
||||
|---|---|---|---|---|---|---|
|
Precision |
Recall |
F |
Precision |
Recall |
F |
|
|
AMM |
0.8325 |
0.1662 |
0.2771 |
0.8244 |
0.1390 |
0.2378 |
|
LOC |
0.3026 |
0.8625 |
0.4481 |
0.0598 |
0.7875 |
0.1112 |
|
ORG |
0.5226 |
0.4110 |
0.4601 |
0.2938 |
0.2065 |
0.2425 |
|
PER |
0.8191 |
0.7700 |
0.7938 |
0.4693 |
0.5925 |
0.5238 |
|
MED |
0.8480 |
0.7837 |
0.8146 |
0.9111 |
0.7002 |
0.7918 |
|
OM |
1.0000 |
0.9808 |
0.9903 |
1.0000 |
0.9038 |
0.9495 |
|
MacroF |
0.6307 |
0.4761 |
||||
- The best MacroF is underlined
根据本次评估的结果,所有后续分析都将考虑将Tint作为NER工具。
5.3.2基于工程量清单的分类分析(Q2)
我们继续探索通过考虑基于BoW的特征来训练的分类器的准确性性能。分类器采用SVM、RF和XGBoost三种分类算法进行训练。测试配置分别表示为:BoW+SVM、BoW+RF和BoW+XGBoost。在本实验中,我们通过改变分类算法,分析了引理化、停止词去除和小写变换对使用基于BoW的特征训练的分类器的准确性性能的影响。
表6中报告的结果表明,通过应用一些文本预处理操作,在每个分类算法中都实现了最高的准确性性能。然而,所采用的文本预处理操作可能会对分类算法的性能产生不同的影响。值得注意的是,在所有分类算法中,通过执行文本的小写转换来实现最佳的准确性性能。然而,在BoW+SVM中,通过降低文本语料库的大小写和去除停止词来实现最高的准确性性能。另一方面,在BoW+RF中,通过降低文本语料库的大小写、执行旅语化和去除停止词来实现最高的准确性性能。在BoW+XGBoost中,通过降低文本语料库的规模和进行引理来实现最高的准确性。最后,我们注意到,通过将SVM分类器作为亚军来训练XGBoost分类器,实现了基于BoW的特征的最高精度性能。
Table 6 F score of BoW+SVM, BoW+RF and BoW+XGBoost with respect to pre-processing operations (lemmatization, lowercase transformation and stopword removal)
From: An AI framework to support decisions on GDPR compliance
|
Conf. |
Lemm. |
Lowercase |
Stopword |
F-NC |
F-C |
MacroF |
|---|---|---|---|---|---|---|
|
BoW+SVM |
0.7692 |
0.7692 |
0.7692 |
|||
|
× |
0.8132 |
0.8132 |
0.8132 |
|||
|
× |
0.7473 |
0.7473 |
0.7473 |
|||
|
× |
× |
0.8352 |
0.8315 |
0.8333 |
||
|
× |
0.7473 |
0.7473 |
0.7473 |
|||
|
× |
× |
0.7473 |
0.7527 |
0.7500 |
||
|
× |
× |
0.7473 |
0.7473 |
0.7473 |
||
|
× |
× |
× |
0.7473 |
0.7416 |
0.7444 |
|
|
BoW+RF |
0.7363 |
0.7391 |
0.7377 |
|||
|
× |
0.7363 |
0.7447 |
0.7405 |
|||
|
× |
0.7253 |
0.7312 |
0.7282 |
|||
|
× |
× |
0.7253 |
0.7368 |
0.7311 |
||
|
× |
0.7582 |
0.7609 |
0.7596 |
|||
|
× |
× |
0.7582 |
0.7755 |
0.7669 |
||
|
× |
× |
0.7692 |
0.7742 |
0.7717 |
||
|
× |
× |
× |
0.7912 |
0.8000 |
0.7956 |
|
|
BoW+XGBoost |
0.7692 |
0.7742 |
0.7717 |
|||
|
× |
0.8022 |
0.8085 |
0.8054 |
|||
|
× |
0.7802 |
0.7826 |
0.7814 |
|||
|
× |
× |
0.7473 |
0.7473 |
0.7473 |
||
|
× |
0.7692 |
0.7692 |
0.7692 |
|||
|
× |
× |
0.6923 |
0.6889 |
0.6906 |
||
|
× |
× |
0.8462 |
0.8511 |
0.8486 |
||
|
× |
× |
× |
0.6264 |
0.6304 |
0.6284 |
- NC denotes the label “non-compliant”, C denotes the label “compliant”. The best results are underlined
5.3.3基于净入学率的分类分析(Q3)
随后,我们探讨了通过考虑基于NER的特征来训练的分类器的性能。
表7中报告的NER+SVM、NER+RF和NER+XGBoost的结果表明,使用基于NER的特征实现的精度性能随分类算法的不同而变化。在NER+SVM中,通过考虑BoNE特征组的命名实体袋来训练SVM分类器的配置实现了最高的精度性能。进一步的准确性既不能通过利用命名实体的二进制图(BoNNEG特征组)也不能通过将单词信息与命名实体相结合(BoWNe特征组)来获得。另一方面,在NER+RF中,使用与命名实体组合的单词信息(BoWNe特征组)来训练RF分类器的配置实现了最高的精度性能。最后,在NER+XGBoost中,通过分别考虑命名实体的袋(BoNE特征组)或命名实体的二进制图(BoNNEG特征组),或单词信息与命名实体的组合(BoWNe特征组)来实现最高精度。值得注意的是,通过训练具有RF分类器作为亚军的SVM分类器,实现了具有基于NER的特征的最高精度性能。
Table 7 F score of NER+SVM, NER+RF and NER+XGBoost with respect to NER-based feature groups (BoNE, BoNNEG and BoWNE)
From: An AI framework to support decisions on GDPR compliance
|
Conf. |
BoNE |
BoNNEG |
BoWNE |
F-NC |
F-C |
MacroF |
|---|---|---|---|---|---|---|
|
NER+SVM |
× |
× |
× |
0.8352 |
0.8421 |
0.8386 |
|
× |
× |
0.8352 |
0.8421 |
0.8386 |
||
|
× |
× |
0.8352 |
0.8421 |
0.8386 |
||
|
× |
0.8352 |
0.8421 |
0.8386 |
|||
|
× |
× |
0.7473 |
0.7473 |
0.7473 |
||
|
× |
0.7473 |
0.7473 |
0.7473 |
|||
|
× |
0.6593 |
0.6173 |
0.6376 |
|||
|
NER+RF |
× |
× |
× |
0.6703 |
0.6809 |
0.6755 |
|
× |
× |
0.6703 |
0.6809 |
0.6755 |
||
|
× |
× |
0.7582 |
0.7660 |
0.7621 |
||
|
× |
0.7582 |
0.7660 |
0.7621 |
|||
|
× |
× |
0.7582 |
0.7660 |
0.7621 |
||
|
× |
0.7582 |
0.7660 |
0.7621 |
|||
|
× |
0.7912 |
0.7957 |
0.7934 |
|||
|
NER+XGBoost |
× |
× |
× |
0.6374 |
0.6374 |
0.6374 |
|
× |
× |
0.6374 |
0.6374 |
0.6374 |
||
|
× |
× |
0.7582 |
0.7609 |
0.7596 |
||
|
× |
0.7692 |
0.7789 |
0.7741 |
|||
|
× |
× |
0.7692 |
0.7789 |
0.7741 |
||
|
× |
0.7692 |
0.7789 |
0.7741 |
|||
|
× |
0.7692 |
0.7789 |
0.7741 |
- NC denotes the label “non-compliant”, C denotes the label “compliant”. The best results are underlines
5.3.4 INTREPID与基线分析(第4季度)
最后,我们探讨了所提出的框架INTREPID的准确性性能,该框架通过考虑通过同时连接基于BoW的特征和基于NER的特征而获得的特征向量来训练分类器。我们再次通过改变SVM、RF和XGBoost之间的分类算法来分析INTREPID的性能。对于每种分类算法,我们运行了56种不同的INTREPID配置,这些配置是通过改变基于BoW的特征提取中文本预处理管道的设置(引理、小写和停止字去除)以及基于NER的特征提取的基于NER特征工程方案的选择来定义的。实验配置如表8所示。
Table 8 Configurations of INTREPID
From: An AI framework to support decisions on GDPR compliance
|
Feature Group |
Parameter |
Value Range |
|---|---|---|
|
BoW |
Lemmatization |
{enabled, disabled} |
|
Lowercase |
{enabled, disabled} |
|
|
Stopword |
{enabled, disabled} |
|
|
NER |
BoNE |
{enabled, disabled} |
|
BoNNEG |
{enabled, disabled} |
|
|
BoWNE |
{enabled, disabled} |
- In each configuration, both BoW-based features and NER-based features are computed, so that at least one option among BoNE, BoNNEG and BoWNE is enabled
图4显示了为“不符合”(F-NC)和“符合”(F-3)两类计算的F分数的方框图,以及分别为SVM、RF和XGBoost分类算法在INTREPID运行配置上计算的MacroF度量。这些结果表明,XGBoost的性能最高,支持向量机排名第二。
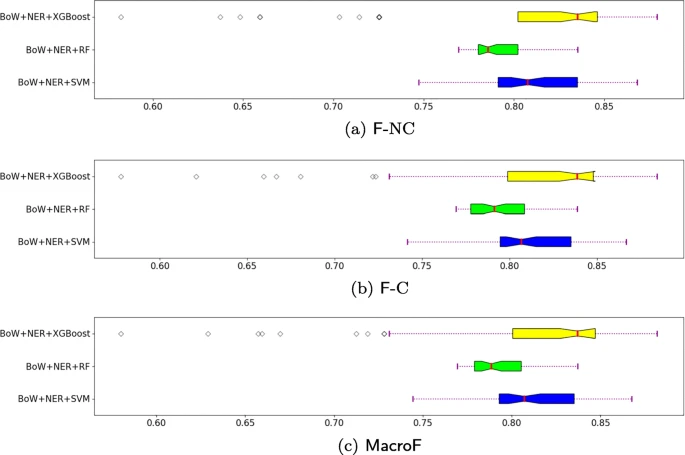
F-NC (Fig. 4a), F-C (Fig. 4b) and MacroF (Fig. 4c) of INTREPID (Bow+NER) with SVM, RF and XGBoost as classification algorithms
我们通过分别考虑基于BoW的特征或基于NER的特征,将INTREPID的准确性性能与训练分类器的基线的准确性性能进行了比较。表9显示了使用这三种方法获得的最高精度性能。这些结果证实,用于构建基于BoW的特征和基于NER的特征的最佳集合随着分类算法的变化而变化。此外,他们还表明,基于NER的特征通常与SVM和RF的基于BoW的特征表现得很接近,而它们的表现比SVM的基于BoW的特征差。无论如何,在同一分类阶段(INTREPID)中利用基于BoW的特征和基于NER的特征,我们可以学习一种分类器,该分类器能够在验证用意大利语编写的PA文件的GDPR合规性时获得准确性。这一结论可以独立于分类算法得出,尽管当分类器使用XGBoost训练时,INTREPID实现了最高的准确性性能。
Table 9 MacroF metric of INTREPID vs. BoW-based and NER-based classifiers trained with SVM, RF and XGBoost
From: An AI framework to support decisions on GDPR compliance
|
Classif. |
Method |
MacroF |
Configuration set-up |
|||||
|---|---|---|---|---|---|---|---|---|
|
BoW-based features |
NER-based features |
|||||||
|
Le. |
Lo. |
St. |
BoNE |
BoNNEG |
BoWNE |
|||
|
SVM |
INTREPID |
0.8673 |
× |
× |
||||
|
BoW |
0.8333 |
× |
× |
|||||
|
NER |
0.8386 |
× |
||||||
|
RF |
INTREPID |
0.8369 |
× |
× |
||||
|
BoW |
0.7956 |
× |
× |
× |
||||
|
NER |
0.7934 |
× |
||||||
|
XGBoost |
INTREPID |
0.8816 |
× |
× |
× |
|||
|
BoW |
0.8486 |
× |
× |
|||||
|
NER |
0.7741 |
× |
||||||
- “Le” denotes “Lemmatization”, “Lo” denotes “Lowercase” and “St” denotes “Stopword”. The best results are underlined
最新内容
- 1 week 6 days ago
- 3 weeks ago
- 3 weeks 4 days ago
- 2 months 1 week ago
- 6 months 1 week ago
- 6 months 1 week ago
- 6 months 1 week ago
- 6 months 1 week ago
- 6 months 1 week ago
- 6 months 1 week ago