
Chinese, Simplified
category
由于其先进的功能和功能,诸如Iceberg、Delta Lake和Hudi等开放式表格格式的受欢迎程度和采用率不断上升。Randstad Groep Nederland的数据和分析平台团队已将数据湖从Apache Hive Metastore管理的镶木地板文件迁移到Apache Iceberg表格式。
这个博客解释了迁移背后的动机。还描述了过去设置的缺点和当前设置的优点。
过去-Hive
数据湖以前是基于存储在S3上的镶木地板文件和Apache Hive兼容的AWS Glue数据目录。设置依赖于类似于Hive文件夹的目录结构,如图1所示。然而,我们使用这种格式的经验揭示了几个缺点,即:
- Trino是数据湖查询引擎。为了让Trino查询发现所需的文件,需要在运行时列出分区。特别是对于具有多个分区的表,这不仅耗时(O(n)),而且成本高昂,因为列出对象所需的S3 API调用带来了成本。
- 表元数据存储在与配置单元兼容的AWS Glue Data Catalog元存储中。为了跟踪分区并使元存储保持最新,我们使用了AWS Glue Crawlers,这是数据管道中的一个额外组件,它也会产生成本,并由于运行时间而导致接收过程延迟。
- 数据湖的当前区域存储数据的最新状态,例如记录的最后更新。为了在Hive结构中构建它,将上一个快照加载到内存中,计算当前状态,并将快照写回S3。这导致了大量的S3 I/O,并增加了我们运行Spark作业的EMR集群的负载。
- 配置单元表不支持ACID事务,如果多个写入程序试图同时更新数据,这可能会导致数据不一致,甚至数据丢失。
- 修改分区粒度需要进行完整的数据迁移。例如,如果现有分区是/年/月/日/小时/分钟,则将其修改为/年/月/日需要对数据进行完全重写,这是资源密集型的,也是耗时的。
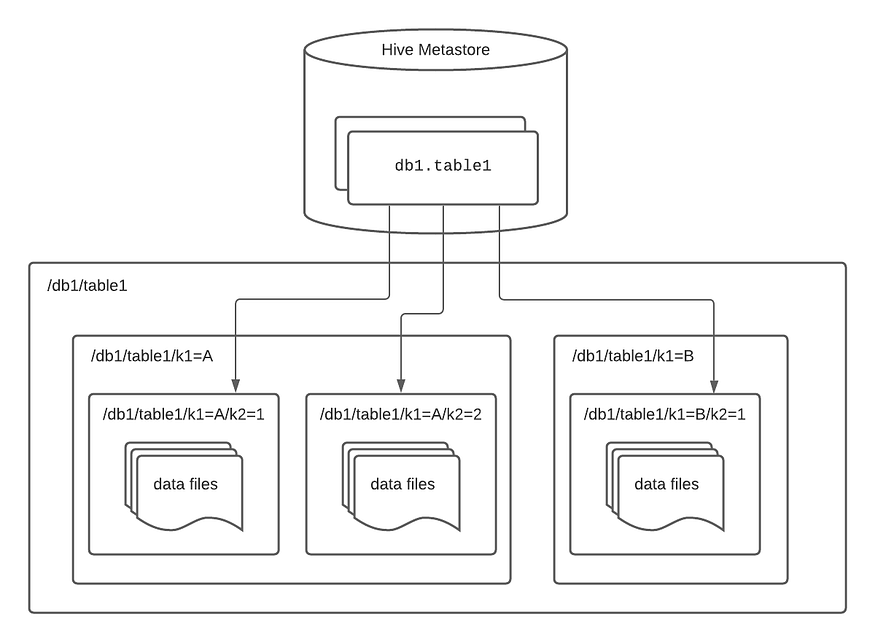
Figure 1. Hive table structure [1]
现在-Iceberg 进行救援
由于上述原因,我们决定研究Apache Iceberg,这是一种由Netflix创建的开放表格式,旨在解决Apache Hive的许多缺点。简而言之,Iceberg体系结构的魔力(见图2)依赖于元数据层,它保存了所有表文件的元数据,也保存了每个文件的信息,以及列级元数据。
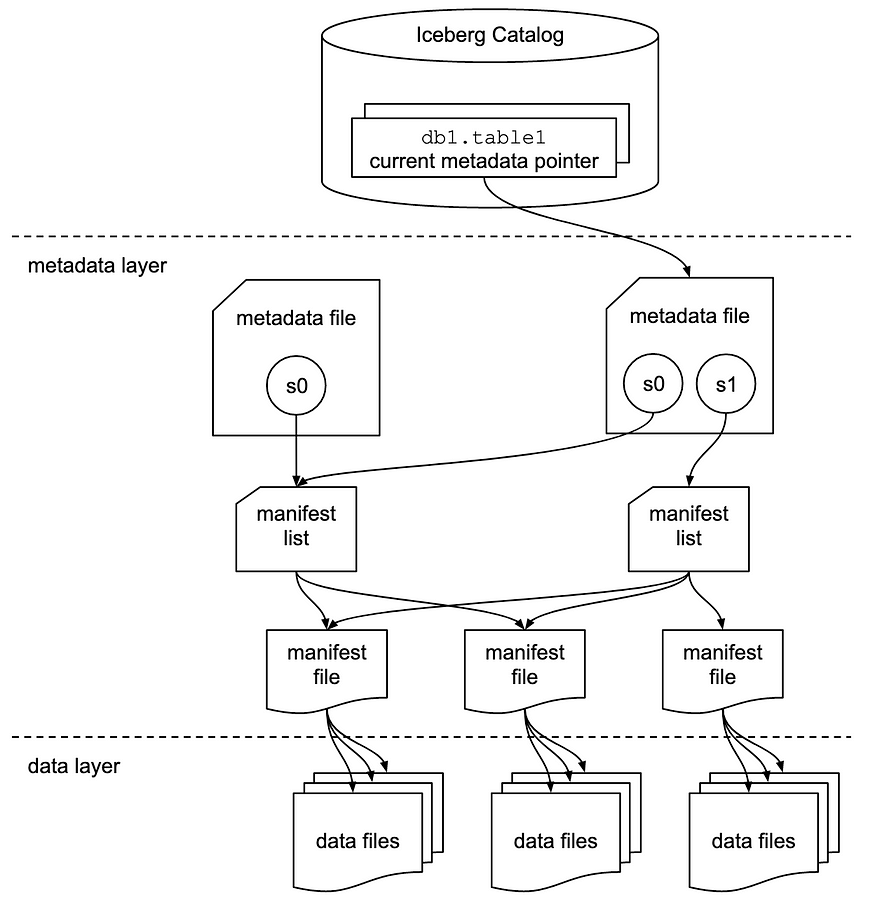
Figure 2. Iceberg Architecture [2]
最重要的是,Iceberg改善了用户体验,降低了成本。确定的一些主要优势如下所示:
- 不需要全目录扫描,因此S3 API成本更低,查询规划更快。我们注意到Trino查询运行时平均提高了35%。
- Iceberg使用ACID事务。许多进程可以同时更新数据,我们可以放心,所有事务都是原子的、一致的和孤立的。
- 表达型Spark SQL MERGE INTO语句可用于执行UPSERT并创建数据的当前快照。所需的I/O更少,这意味着成本降低。
- 用户可以很容易地进行时间旅行,并在更早的时间点检查数据。
- 可以进行表回滚以恢复表状态,例如在错误的数据摄取的情况下。
- 架构进化是无缝的,“HIVE PARTITION Schema MISMATCH ERROR”有人吗?
- 不需要运行Glue Crawlers,也不需要创建指向数据当前状态的配置单元视图。
- 分区进化可以用于动态修改分区布局,避免昂贵的操作。
结论
Apache Iceberg是一个很好的工具,用于管理数据湖中的大型数据集。它极大地提高了我们数据平台的一致性、可扩展性、性能和可维护性。如果你的数据湖目前是基于蜂巢的,可以考虑采用冰山!
参考文献:
发布日期
星期六, 五月 13, 2023 - 14:51
最后修改
星期六, 三月 23, 2024 - 09:12
Article
最新内容
- 1 week 3 days ago
- 2 weeks 4 days ago
- 3 weeks 1 day ago
- 2 months 1 week ago
- 6 months ago
- 6 months ago
- 6 months ago
- 6 months ago
- 6 months ago
- 6 months ago